使用机器学习算法预测航班价格
一、前言
机票价格的预测一直是航空业和旅行者关注的重要问题之一。随着航空业的快速发展和市场竞争的加剧,正确预测机票价格对于航空公司的利润最大化和旅行者的预算规划至关重要。在过去,人们通常依靠经验和市场趋势来预测机票价格,但这种方法往往存在不准确和不稳定的问题。
为了解决这个问题,本项目旨在利用机器学习算法来预测机票价格。机器学习是一种强大的技术,可以自动从历史数据中学习规律和模式,并根据这些模式做出准确的预测。通过分析航班的相关数据,如起飞时间、航空公司、航线、季节性和市场需求等因素,我们可以构建一个机票价格预测模型。本实验在jupyter notebook中执行,本文将给出代码的详细介绍,供初学者更好的学习数据预处理、特征工程、数据划分、模型选择和训练、模型评估等过程。
二、实验所需的库及介绍
本实验所需的库与介绍如下,进行本实现请先在conda pip install以下库:
1. pandas: pandas`是一个强大的数据处理和分析库。它提供了高性能、易于使用的数据结构,如DataFrame,用于处理和操作结构化数据。pandas`可以读取和写入各种数据格式,如 CSV、Excel、SQL 数据库等。它还提供了许多数据处理和转换函数,使数据清洗、转换和整理变得更加简单。
2. seaborn: seaborn 是一个基于 matplotlib`的数据可视化库。它提供了一组高级的统计图形和绘图函数,使得创建各种统计图形变得更加简单。seaborn的设计目标是使可视化过程更加简洁、美观,并提供了一些默认的样式和颜色调色板,使得图形的生成和修改更加容易。
3. numpy: numpy 是一个用于科学计算的库。它提供了高性能的多维数组对象(ndarray)以及用于操作数组的各种函数。numpy的数组操作功能非常强大,可以进行向量化操作、广播等。它还提供了许多数学函数,如线性代数运算、傅里叶变换、随机数生成等。
4. matplotlib.pyplot: matplotlib.pyplot 是 matplotlib库的一个子模块,它提供了一组简单而有效的函数,用于创建各种类型的图形和可视化。通过 pyplot,可以创建线图、散点图、条形图、饼图等,并对图形进行自定义设置,如添加标题、标签、图例等。
5. datetime: datetime 是 Python 的一个内置模块,提供了处理日期和时间的函数和类。它可以用于创建、操作和格式化日期和时间,计算时间差、转换时间表示等。
6. scikit-learn: scikit-learn(简称为 sklearn)是一个流行的机器学习库,提供了许多常用的机器学习算法和工具。它包含了用于分类、回归、聚类、降维、模型选择和评估等任务的函数和类。train_test_split 用于划分训练集和测试集的工具函数,RandomizedSearchCV 是用于进行随机搜索交叉验证的类,RandomForestRegressor 和 ExtraTreesRegressor 是随机森林和极端随机森林回归器的类。
7. pickle: pickle 是 Python 的内置模块,用于序列化和反序列化 Python 对象。它可以将对象转换为字节流表示,从而可以将对象保存到文件或通过网络传输。pickle 在机器学习中常用于保存训练好的模型,以便以后重用。可以使用 pickle 将训练好的模型保存到文件,然后在需要时加载回来并进行预测或其他操作。
三、数据集简介
我们采用网上搜集到的国外的一个航班信息数据集用于我们的预测实验,数据集包含了航班的出发点、到达地、出发时间、到达时间、票价等航班信息。你可以通过下面链接下载该数据集:
链接:链接:https://pan.baidu.com/s/1ukycDJvkn55B-gE022rpVw?pwd=zu8l
提取码:zu8l
四、实现代码
1.导入航班价格预测所需的库
import pandas as pd
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
import datetime as dt
from sklearn.model_selection import train_test_split, RandomizedSearchCV
from sklearn.ensemble import RandomForestRegressor, ExtraTreesRegressor
import pickle
from sklearn import metrics2.读取训练数据
train_data = pd.read_excel('Data_Train.xlsx')
train_data.head() 这段代码使用了Pandas库来读取一个在程序同目录下名为"Data_Train.xlsx"的Excel文件,并将其内容加载到一个名为train_data的DataFrame中,显示DataFrame的前几行数据,运行结果如下:

3.检查目标列中的值
train_data['Destination'].value_counts() 这段代码对train_data DataFrame中的"Destination"列执行了value_counts()方法。它返回了一个包含每个唯一值的计数的Series对象,该Series对象按计数值降序排列。运行结果如下:
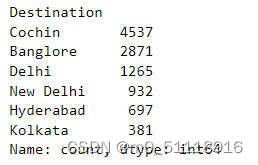
• 在我们的数据集中,最多的人前往科钦,其次是班加罗尔,然后是德里。
下面我们将"Destination"列中的'New Delhi'值替换为'Delhi',以便在数据中统一表示目的地:
def newd(x):
if x=='New Delhi':
return 'Delhi'
else:
return x
train_data['Destination'] = train_data['Destination'].apply(newd)
4.检查我们的列车数据信息
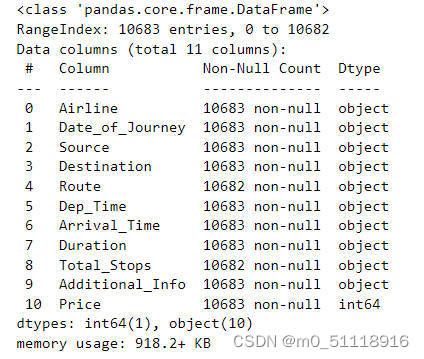
train_data.info()`train_data.info()`是一个用于查看DataFrame的基本信息的方法。它提供了关于DataFrame的列名、每列的非空值数量、数据类型以及占用内存等方面的信息,这对于数据清洗、处理和分析非常有用。运行结果如下:
5.将日期和月份列转换为日期时间列
train_data['Journey_day'] = pd.to_datetime(train_data['Date_of_Journey'],format='%d/%m/%Y').dt.day
train_data['Journey_month'] = pd.to_datetime(train_data['Date_of_Journey'],format='%d/%m/%Y').dt.month
train_data.drop('Date_of_Journey',inplace=True,axis=1)
train_data.head()这段代码进行了一系列的数据处理操作,对`train_data` DataFrame进行了修改:
首先,代码使用`pd.to_datetime()`函数将"Date_of_Journey"列中的日期字符串转换为Pandas的日期时间类型。`pd.to_datetime()`函数接受两个参数:要转换的列和日期字符串的格式。在这里,日期字符串的格式是"%d/%m/%Y",表示日期格式为"日/月/年"。转换后,日期时间对象的天数部分被提取并赋值给新的"Journey_day"列,用于表示出发日期的天数。
接着,代码再次使用`pd.to_datetime()`函数将"Date_of_Journey"列中的日期字符串转换为日期时间类型,并提取出月份部分,并将其赋值给新的"Journey_month"列,用于表示出发日期的月份。
然后,使用`drop()`方法删除了原始的"Date_of_Journey"列。`drop()`方法用于从DataFrame中删除指定的列或行,其中第一个参数是要删除的列或行的标签,`inplace=True`表示对原始DataFrame进行修改,`axis=1`表示删除列。
最后,代码通过调用`head()`方法显示修改后的DataFrame的前几行数据。
运行结果如下:

6.从时间中提取小时和分钟
train_data['Dep_hour'] = pd.to_datetime(train_data['Dep_Time']).dt.hour
train_data['Dep_min'] = pd.to_datetime(train_data['Dep_Time']).dt.minute
train_data.drop('Dep_Time',axis=1,inplace=True)
train_data['Arrival_hour'] = pd.to_datetime(train_data['Arrival_Time']).dt.hour
train_data['Arrival_min'] = pd.to_datetime(train_data['Arrival_Time']).dt.minute
train_data.drop('Arrival_Time',axis=1,inplace=True)
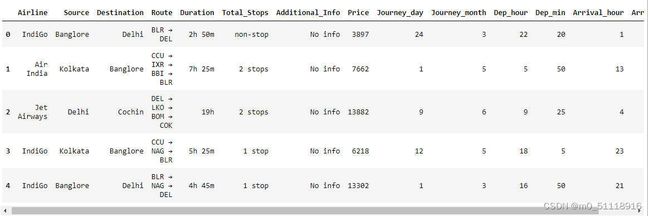
train_data.head()这段代码对`train_data` DataFrame进行了一系列的操作,包括处理出发时间和到达时间,并对DataFrame进行了修改。
首先,代码使用`pd.to_datetime()`函数将"Dep_Time"列中的时间字符串转换为Pandas的日期时间类型。然后,通过使用`.dt.hour`和`.dt.minute`属性,分别将出发时间的小时和分钟提取出来,并分别赋值给新的"Dep_hour"和"Dep_min"列,用于表示出发时间的小时和分钟。
接下来,代码使用`drop()`方法删除了原始的"Dep_Time"列。`drop()`方法用于从DataFrame中删除指定的列或行,其中第一个参数是要删除的列或行的标签,`axis=1`表示删除列。
然后,代码使用类似的方式处理"Arrival_Time"列。它将"Arrival_Time"列中的时间字符串转换为日期时间类型,并提取到达时间的小时和分钟,并将它们分别赋值给新的"Arrival_hour"和"Arrival_min"列。
最后,代码通过调用`head()`方法显示修改后的DataFrame的前几行数据。
运行结果如下:
7.统计 Duration 列中的值
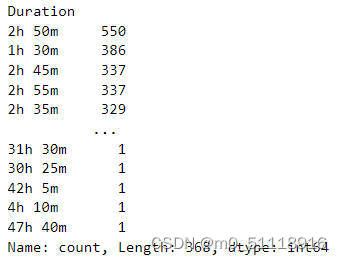
train_data['Duration'].value_counts()在这里,"Duration"列包含了飞行时间的持续时间,以字符串的形式表示,例如"2h 50m"。该方法将显示每个唯一的持续时间值出现的次数,以帮助我们了解飞行持续时间的分布情况。
运行结果如下:
8. 删除 Duration 列并从中提取重要信息
duration = list(train_data['Duration'])
for i in range(len(duration)):
if len(duration[i].split()) != 2:
if 'h' in duration[i]:
duration[i] = duration[i] + ' 0m'
else:
duration[i] = '0h ' + duration[i]
duration_hour = []
duration_min = []
for i in duration:
h,m = i.split()
duration_hour.append(int(h[:-1]))
duration_min.append(int(m[:-1]))
train_data['Duration_hours'] = duration_hour
train_data['Duration_mins'] = duration_min
train_data.drop('Duration',axis=1,inplace=True)
train_data.head()这段代码的作用是将"Duration"列中的持续时间字符串进行处理,提取出小时和分钟部分,并分别存储到"Duration_hours"和"Duration_mins"列中。然后,删除原始的"Duration"列,并显示修改后的DataFrame的前几行数据,以方便对持续时间进行分析和处理。
运行结果如下:
9.绘制航空公司与价格的箱线图
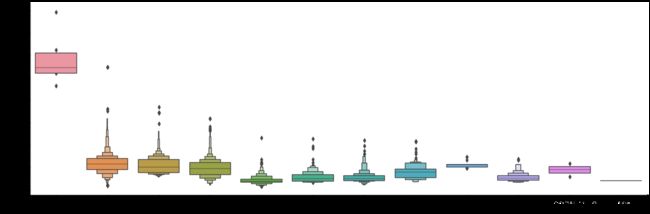
sns.catplot(x='Airline',y='Price',data=train_data.sort_values('Price',ascending=False),kind='boxen',aspect=3,height=6)这段代码使用Seaborn库绘制了一个箱线图,用于展示航空公司("Airline")与票价("Price")之间的关系。下面是代码的详细解释:
- `sns.catplot()`: 这是Seaborn库中用于绘制分类数据的函数。它可以绘制多种类型的图形,包括箱线图(boxen plot)。
- `x='Airline'`、`y='Price'`、`data=train_data.sort_values('Price',ascending=False)`: 这些参数指定了箱线图的横轴、纵轴和数据源。横轴是航空公司("Airline"),纵轴是票价("Price"),数据源是`train_data` DataFrame,并按票价降序排序。
- `kind='boxen'`: 这个参数指定了绘制的图形类型为箱线图(boxen plot)。箱线图是一种用于显示数据分布和异常值的图形。
- `aspect=3`: 这个参数指定了图形的宽高比。
- `height=6`: 这个参数指定了图形的高度。
通过绘制箱线图,我们可以观察航空公司与票价之间的关系。箱线图显示了每个航空公司的票价分布情况,包括中位数、上下四分位数、异常值等信息。这有助于比较不同航空公司的票价水平和分布范围,以及识别可能存在的异常值或离群点。运行结果如下:
10.从 Airline 列中创建虚拟列
airline = train_data[['Airline']]
airline = pd.get_dummies(airline,drop_first=True)这段代码对`train_data` DataFrame中的"Airline"列进行了独热编码(One-Hot Encoding)的处理:
首先,代码使用`train_data[['Airline']]`选择了"Airline"列,并将其赋值给新的DataFrame `airline`。这样做是为了将"Airline"列单独提取出来,以便进行独热编码的处理。
接下来,代码使用`pd.get_dummies()`函数对`airline` DataFrame进行独热编码。`pd.get_dummies()`函数将分类变量转换为二进制的独热编码表示。通过设置`drop_first=True`,代码删除了独热编码生成的第一列,以避免多重共线性问题。
最终,独热编码后的结果存储在`airline` DataFrame中,每个航空公司的名称都被转换为相应的二进制编码列。这种编码形式可以更好地表示航空公司之间的分类关系,以便于后续的分析和建模。
11.绘制来源与价格的箱线图
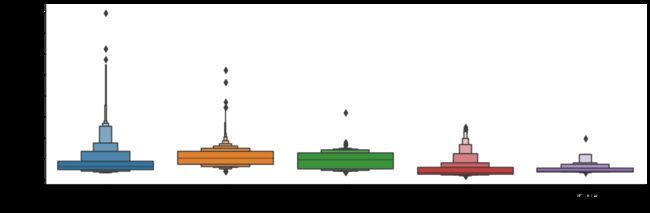
sns.catplot(x='Source',y='Price',data=train_data.sort_values('Price',ascending=False),kind='boxen',aspect=3,height=4)这段代码使用Seaborn库绘制了一个箱线图,用于比较不同出发城市("Source")的票价("Price")。运行结果如下:
12.根据"Source"列创建虚拟列
source = train_data[['Source']]
source = pd.get_dummies(source,drop_first=True)
source.head()这段代码对`train_data` DataFrame中的"Source"列进行了独热编码(One-Hot Encoding)的处理:
首先,代码使用`train_data[['Source']]`选择了"Source"列,并将其赋值给新的DataFrame `source`。这样做是为了将"Source"列单独提取出来,以便进行独热编码的处理。
接下来,代码使用`pd.get_dummies()`函数对`source` DataFrame进行独热编码。`pd.get_dummies()`函数将分类变量转换为二进制的独热编码表示。通过设置`drop_first=True`,代码删除了独热编码生成的第一列,以避免多重共线性问题。
最终,独热编码后的结果存储在`source` DataFrame中,每个出发城市的名称都被转换为相应的二进制编码列。这种编码形式可以更好地表示出发城市之间的分类关系,以便于后续的分析和建模。调用`source.head()`可以显示独热编码后的DataFrame的前几行数据。运行结果如下:

13.绘制目的地与价格之间的箱线图
sns.catplot(x='Destination',y='Price',data=train_data.sort_values('Price',ascending=False),kind='boxen',aspect=3,height=4)这段代码使用Seaborn库绘制了一个箱线图,用于比较不同目的地城市("Destination")的票价("Price"),运行结果如下:

14.从目标列中创建虚拟列
destination = train_data[['Destination']]
destination = pd.get_dummies(destination,drop_first=True)
destination.head()这段代码对`train_data` DataFrame中的"Destination"列进行了独热编码(One-Hot Encoding)的处理:
首先,代码使用`train_data[['Destination']]`选择了"Destination"列,并将其赋值给新的DataFrame `destination`。这样做是为了将"Destination"列单独提取出来,以便进行独热编码的处理。
接下来,代码使用`pd.get_dummies()`函数对`destination` DataFrame进行独热编码。`pd.get_dummies()`函数将分类变量转换为二进制的独热编码表示。通过设置`drop_first=True`,代码删除了独热编码生成的第一列,以避免多重共线性问题。
最终,独热编码后的结果存储在`destination` DataFrame中,每个目的地城市的名称都被转换为相应的二进制编码列。这种编码形式可以更好地表示目的地城市之间的分类关系,以便于后续的分析和建模。调用`destination.head()`可以显示独热编码后的DataFrame的前几行数据。
运行结果如下:

15.删除无用的列
train_data.drop(['Route','Additional_Info'],inplace=True,axis=1)这段代码对`train_data` DataFrame进行了列删除操作,删除了"Route"和"Additional_Info"两列。下面是代码的详细解释:
- `train_data.drop(['Route','Additional_Info'],inplace=True,axis=1)`: 这行代码使用`drop()`函数对`train_data` DataFrame进行列删除操作。通过指定`['Route','Additional_Info']`作为要删除的列名列表,代码删除了"Route"和"Additional_Info"两列。`inplace=True`表示在原地修改`train_data` DataFrame,`axis=1`表示删除列。
这段代码的执行将从`train_data` DataFrame中删除了"Route"和"Additional_Info"两列,使得DataFrame中只保留了与航班相关的特征列。这是因为"Route"列包含航班的具体路线信息,"Additional_Info"列包含一些额外的航班信息,而这些信息对于后续的分析和建模任务不是必需的。
16.统计"Total stops"列中的数值
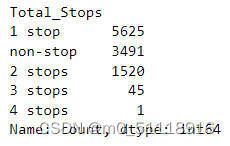
train_data['Total_Stops'].value_counts() 这段代码统计了‘train_data’ DataFrame中"Total_Stops"列的不同取值及其出现的频数。运行结果如下:
17.将"Total_stops"列中的标签转换为数字
train_data['Total_Stops'].replace({'non-stop':0,'1 stop':1,'2 stops':2,'3 stops':3,'4 stops':4},inplace=True)
train_data.head()这段代码对`train_data` DataFrame中的"Total_Stops"列进行了取值替换操作。下面是代码的解释:
- `train_data['Total_Stops'].replace({'non-stop':0,'1 stop':1,'2 stops':2,'3 stops':3,'4 stops':4},inplace=True)`: 这行代码使用`replace()`函数将"Total_Stops"列中的特定取值替换为相应的数值。通过提供一个字典作为参数,代码指定了要替换的取值及其对应的替换值。具体而言,"non-stop"被替换为0,"1 stop"被替换为1,"2 stops"被替换为2,"3 stops"被替换为3,"4 stops"被替换为4。`inplace=True`表示在原地修改`train_data` DataFrame。
执行该代码将对"Total_Stops"列中的取值进行替换操作。原先的文本值(例如"non-stop"、"1 stop")被替换为对应的数值(0、1)。这样做可以将该列的数据转换为数值形式,方便后续的分析和建模任务。调用`train_data.head()`可以显示替换后的DataFrame的前几行数据。
运行结果如下:
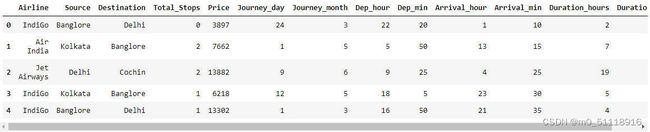
18.检查我们的4个数据框的形状
print(airline.shape)
print(source.shape)
print(destination.shape)
print(train_data.shape)运行结果如下:
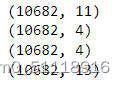
19.合并所有 4 个数据框
data_train = pd.concat([train_data,airline,source,destination],axis=1)
data_train.drop(['Airline','Source','Destination'],axis=1,inplace=True)
data_train.head()这段代码将经过独热编码后的`airline`、`source`和`destination`数据集与经过预处理后的`train_data`数据集进行合并,并生成一个新的数据集 `data_train`。运行结果如下:

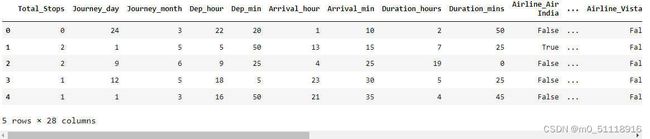
20.提取训练数据
X = data_train.drop('Price',axis=1)
X.head()这段代码将`data_train`数据集中的"Price"列删除,生成一个新的数据集 `X`,该数据集用于存储训练特征。最终,`X`数据集包含了`data_train`数据集中除了"Price"列之外的所有特征列。
运行结果如下:
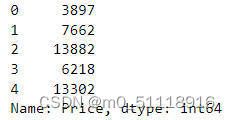
21.提取训练数据标签
y = data_train['Price']
y.head()这段代码将`data_train`数据集中的"Price"列提取出来,生成一个新的数据集 `y`,该数据集用于存储目标变量(价格)。下面是代码的解释:
- `y = data_train['Price']`: 这行代码通过索引操作,将`data_train`数据集中的"Price"列提取出来,并将结果赋值给新的数据集 `y`。
最终,`y`数据集包含了`data_train`数据集中的"Price"列,即目标变量(价格)。通过调用 `y.head()`,可以显示新数据集的前几行数据。这样做是为了准备训练数据,将目标变量存储在 `y` 中,以便进行后续的机器学习模型训练和预测任务。运行结果如下:
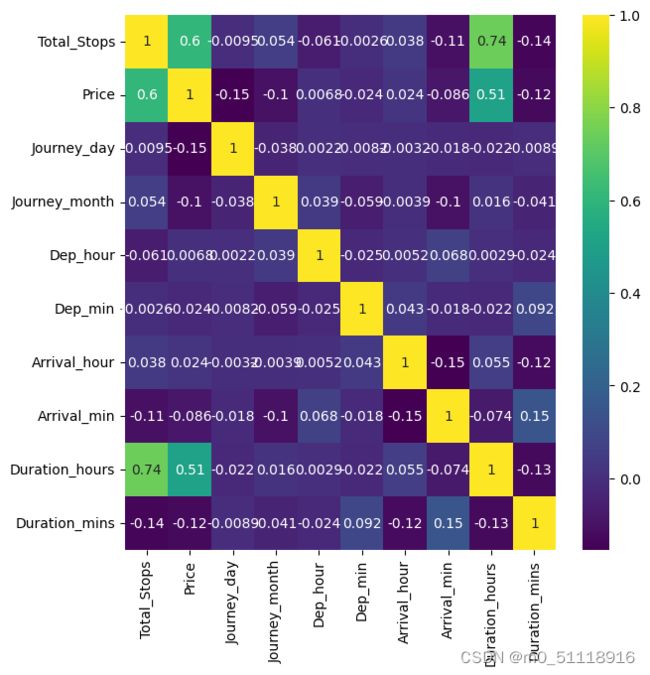
22.检查列之间的相关性
train_data_copy = train_data.copy()
string_columns = train_data_copy.select_dtypes(include=['object']).columns
train_data_copy = train_data_copy.drop(string_columns, axis=1)
plt.figure(figsize=(7,7))
sns.heatmap(train_data_copy.corr(),cmap='viridis',annot=True)以上代码会生成一个热力图,其中每个小方块的颜色表示对应特征之间的相关性。颜色越深表示相关性越强,颜色越浅表示相关性越弱。通过观察热力图,可以了解特征之间的相关性情况,有助于选择和理解数据集中的特征。运行结果如下:
23.首先尝试用于航班价格预测的 ExtraTreesRegressor 模型
ExtraTreesRegressor(极端随机森林回归器)是一种基于随机森林算法的回归模型。它是集成学习方法的一种变体,通过构建多个决策树并对它们的预测结果进行平均来进行回归任务。与传统的随机森林相比,ExtraTreesRegressor 在构建决策树时引入了更高的随机性。在每个节点上,它随机选择一个特征的子集来进行分割,而不是考虑所有的特征。此外,它还使用随机的阈值来进行特征分割。通过引入更多的随机性,ExtraTreesRegressor 增加了模型的多样性,减少了过拟合的风险。ExtraTreesRegressor 在回归问题中具有良好的性能。它能够处理数值型特征和离散型特征,并可以处理缺失数据。此外,由于它的并行化能力,它能够高效地处理大规模数据集。
reg = ExtraTreesRegressor()
reg.fit(X,y)
print(reg.feature_importances_)这段代码使用ExtraTreesRegressor模型对特征矩阵X和目标变量y进行训练,并打印出每个特征的重要性。下面是代码的解释:
- `reg = ExtraTreesRegressor()`: 这行代码创建了一个名为reg的ExtraTreesRegressor回归模型对象。
- `reg.fit(X, y)`: 这行代码使用X作为特征矩阵,y作为目标变量,对模型进行训练。模型会学习如何根据特征预测目标变量。
- `print(reg.feature_importances_)`: 这行代码打印出每个特征的重要性。`feature_importances_`是ExtraTreesRegressor模型的属性,表示各个特征对于预测目标变量的重要性。通过打印该属性,可以了解每个特征对于模型的贡献程度。
执行以上代码,会训练ExtraTreesRegressor模型并输出每个特征的重要性值。重要性值越高表示对目标变量的预测影响越大。这样的信息可以帮助我们理解数据集中的特征,识别哪些特征对于模型的预测最具有影响力。运行结果如下:

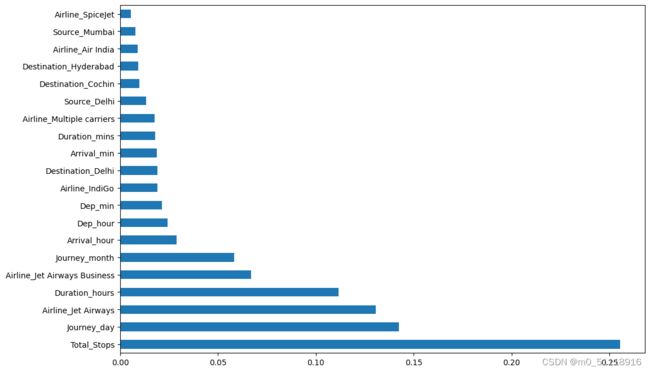
24.可视化 ExtraTreesRegressor 提供的特征重要性¶
plt.figure(figsize = (12,8))
feat_importances = pd.Series(reg.feature_importances_, index=X.columns)
feat_importances.nlargest(20).plot(kind='barh')
plt.show()这段代码用于绘制特征重要性的水平条形图,显示具有最高重要性的前20个特征。下面是代码的解释:
- `plt.figure(figsize=(12, 8))`: 这行代码创建一个大小为(12, 8)的新图形窗口,用于绘制后续的条形图。
- `feat_importances = pd.Series(reg.feature_importances_, index=X.columns)`: 这行代码创建了一个名为feat_importances的Series对象,其中包含特征重要性值,索引为X.columns,即特征的列名。
- `feat_importances.nlargest(20).plot(kind='barh')`: 这行代码选择特征重要性值中最大的20个值,并以水平条形图的形式进行绘制。`.nlargest(20)`方法用于选择最大的20个值,`kind='barh'`表示绘制水平条形图。
- `plt.show()`: 这行代码显示绘制的条形图。
执行以上代码会生成一个水平条形图,显示了具有最高重要性的前20个特征。每个特征以条形的形式表示,条形的长度表示特征的重要性值。通过观察条形图,可以快速了解哪些特征对于预测目标变量的影响最大。运行结果如下:
25.将我们的数据拆分为训练和测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)这段代码使用`train_test_split`函数将数据集`X`和目标变量`y`划分为训练集和测试集,划分比例为80%的数据用于训练,20%的数据用于测试。划分后的训练集和测试集可以用于机器学习模型的训练和评估。
26.训练随机森林回归模型以进行航班价格预测
n_estimators = [int(x) for x in np.linspace(start = 100, stop = 1200, num = 12)]
max_features = ['auto', 'sqrt']
max_depth = [int(x) for x in np.linspace(5, 30, num = 6)]
min_samples_split = [2, 5, 10, 15, 100]
min_samples_leaf = [1, 2, 5, 10]
random_grid = {'n_estimators': n_estimators,
'max_features': max_features,
'max_depth': max_depth,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf}
rf_random = RandomizedSearchCV(estimator = RandomForestRegressor(), param_distributions = random_grid,scoring='neg_mean_squared_error', n_iter = 10, cv = 5, verbose=1, random_state=42, n_jobs = 1)
rf_random.fit(X_train,y_train)这段代码用于进行随机搜索(Randomized Search)以找到随机森林模型(Random Forest)的最佳超参数组合。下面是代码的解释:
- `n_estimators`: 这是一个列表,包含了要尝试的随机森林中树的数量。在这个例子中,从100到1200之间生成了12个等间距的整数值。
- `max_features`: 这是一个列表,包含了每个决策树在拆分节点时要考虑的特征数量。'auto'表示将特征数量设置为总特征数量的平方根,'sqrt'表示与'auto'相同。
- `max_depth`: 这是一个列表,包含了决策树的最大深度。在这个例子中,从5到30之间生成了6个等间距的整数值。
- `min_samples_split`: 这是一个列表,包含了拆分内部节点所需的最小样本数。列表中的值表示要尝试的不同最小样本拆分数。
- `min_samples_leaf`: 这是一个列表,包含了每个叶子节点所需的最小样本数。列表中的值表示要尝试的不同最小叶子样本数。
- `random_grid`: 这是一个字典,包含了上述超参数的可能取值。每个超参数都有一个对应的列表作为值。
- `RandomizedSearchCV`: 这是一个用于随机搜索的交叉验证对象。在这个例子中,使用随机森林回归器(RandomForestRegressor)作为估计器(estimator),使用neg_mean_squared_error作为评分指标(scoring),进行5折交叉验证(cv),搜索100个不同的超参数组合(n_iter=10),并设置了一些其他参数。
- `rf_random.fit(X_train, y_train)`: 这行代码开始执行随机搜索过程,通过使用训练集(X_train, y_train)进行拟合。搜索过程将尝试不同的超参数组合,并根据指定的评分指标在交叉验证中评估模型的性能。
执行以上代码将执行随机搜索过程,目标是找到最佳的随机森林超参数组合,以获得更好的模型性能。搜索过程将尝试不同的超参数组合,并在交叉验证中评估每个组合的性能。一旦搜索完成,`rf_random`对象将存储找到的最佳超参数组合。
27.查看使用随机搜索交叉验证(Randomized Search CV)获得的最佳参数
rf_random.best_params_`rf_random.best_params_` 是一个属性,用于获取随机搜索过程中找到的最佳超参数组合。在这段代码中,它将返回一个字典,包含了找到的最佳超参数组合。你可以通过打印这个属性来查看最佳超参数组合的取值。例如,执行 `print(rf_random.best_params_)` 将打印出最佳超参数组合的取值。
请注意,由于每次随机搜索的结果可能不同,因此在不同的运行中,找到的最佳超参数组合可能会有所变化。运行结果如下:

28.进行预测
prediction = rf_random.predict(X_test)这行代码用于使用随机森林模型进行预测,并将预测结果存储在`prediction`变量中。其中的`rf_random`是通过随机搜索找到的具有最佳超参数的随机森林模型对象,而`X_test`则是用于预测的测试集特征矩阵。预测结果是对测试集样本的目标变量(航班价格)的预测值。
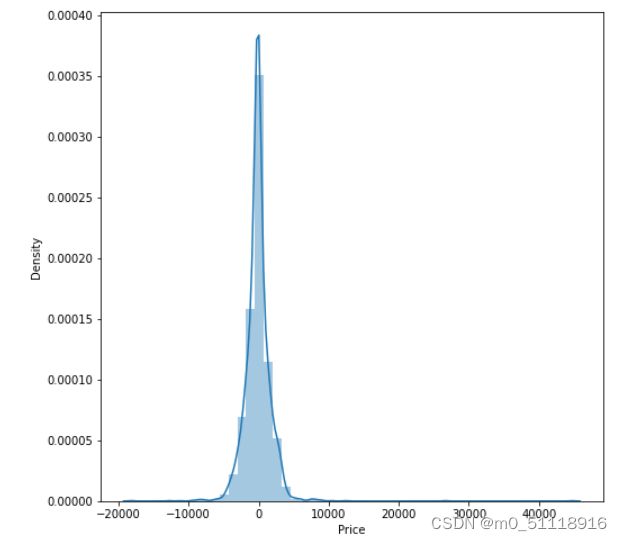
29.绘制残差图
plt.figure(figsize = (8,8))
sns.distplot(y_test-prediction)
plt.show()这段代码用于绘制预测结果与实际结果之间的误差分布图。下面是代码的解释:
- `plt.figure(figsize=(8, 8))`: 这行代码创建一个大小为(8, 8)的新图形窗口,用于绘制后续的图形。
- `sns.distplot(y_test-prediction)`: 这行代码绘制误差分布图,其中`y_test-prediction`表示实际结果与预测结果之间的差异(误差)。`sns.distplot()`函数用于绘制直方图和拟合的核密度估计曲线,展示误差的分布情况。
- `plt.show()`: 这行代码显示绘制的图形。
执行以上代码会生成一个误差分布图,展示了实际结果与预测结果之间的差异。图形中的直方图表示误差的分布情况,核密度估计曲线则表示误差的概率密度分布。通过观察误差分布图,可以评估模型的预测准确度和误差的分布情况。运行结果如下:
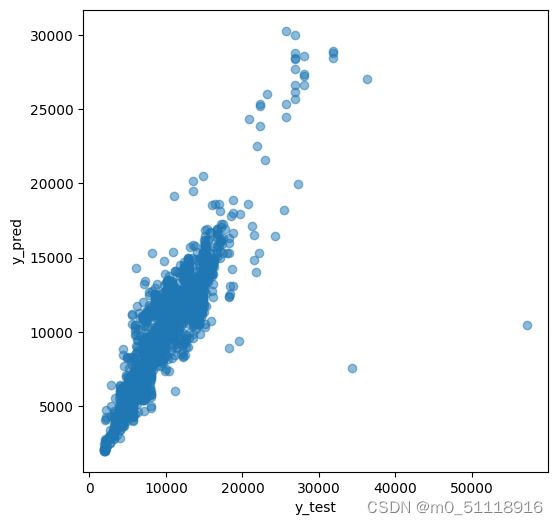
30.绘制真实值与预测值的散点图
plt.figure(figsize = (6,6))
plt.scatter(y_test, prediction, alpha = 0.5)
plt.xlabel("y_test")
plt.ylabel("y_pred")
plt.show()这段代码用于绘制实际结果与预测结果之间的散点图,用于可视化实际结果与预测结果之间的关系。每个散点代表一个样本,横坐标表示实际结果,纵坐标表示预测结果。通过观察散点图,可以评估模型的预测准确度和预测结果与实际结果之间的相关性。运行结果如下:
31.打印度量指标
print('r2 score: ', metrics.r2_score(y_test,prediction))这行代码用于计算并打印模型的 R² 分数。下面是代码的解释:
- `metrics.r2_score(y_test, prediction)`: 这行代码使用 `metrics` 模块中的 `r2_score` 函数计算预测结果 `prediction` 相对于实际结果 `y_test` 的 R² 分数。R² 分数是一种用于评估回归模型拟合优度的指标,其取值范围在 0 到 1 之间,越接近 1 表示模型对观测数据的拟合越好。
- `print('r2 score: ', metrics.r2_score(y_test, prediction))`: 这行代码将计算得到的 R² 分数打印输出。
执行以上代码将输出模型的 R² 分数,评估模型对测试集数据的拟合优度。R² 分数越接近 1,表示模型对观测数据的拟合越好。运行结果如下:
![]()
32.保存我们的模型
file = open('flight_rf.pkl', 'wb')
pickle.dump(rf_random, file)这段代码用于将训练好的随机森林模型保存到文件中。下面是代码的解释:
- `file = open('flight_rf.pkl', 'wb')`: 这行代码创建一个名为 `'flight_rf.pkl'` 的文件,并以二进制写入模式(`'wb'`)打开。`'flight_rf.pkl'` 是保存模型的文件名,可以根据需要进行修改。
- `pickle.dump(rf_random, file)`: 这行代码使用 `pickle` 模块的 `dump` 函数将随机森林模型 `rf_random` 保存到打开的文件中。`pickle.dump()` 函数将对象序列化并写入文件,以便后续可以重新加载模型。
执行以上代码将把训练好的随机森林模型保存到名为 `'flight_rf.pkl'` 的文件中。这样可以在以后的使用中加载模型,而无需重新训练。
以上就是使用机器学习算法预测航班价格的完整过程,若需要了解更多有关机器学习的实验项目,请关注博主~