见微知著: StringUtils.split
作者:明明如月学长, CSDN 博客专家,《性能优化方法论》作者、《解锁大厂思维:剖析《阿里巴巴Java开发手册》》、《再学经典:《EffectiveJava》独家解析》专栏作者。
热门文章推荐:
- (1)《AI 时代,程序员的出路在何方?》
- (2)《超全人工智能 AI工具导航网站合集》
- (3)《如何写出高质量的文章:从战略到战术》
- (4)《我的技术学习方法论》
- (5)《什么? 你还没用过 Cursor? 智能 AI 代码生成工具 Cursor 安装和使用介绍》
- (6)《我的性能方法论》
- (7)《AI 时代的学习方式: 和文档对话》
- (8)《人工智能终端来了,你还在用过时的 iterm?》
- (9)《无需魔法打开即用的 AI 工具集锦》

一、背景
前一段时间,身边有个同事使用 org.apache.commons.lang3.StringUtils#split(java.lang.String, java.lang.String)对字符串进行切割,发现完全和预期不符。
本文将对这个简单的问题进行分析,并思考通过这个问题我们可以学到什么。
二、问题分析
2.1 情景再现
下面是模拟代码
public static void main(String[] args) {
String input = "this is a demo, this \",\"is a \"demo";
String[] split = StringUtils.split(input,"\",\"");
for(String str: split){
System.out.println(str);
}
}
预期是使用 "," 切割字符串,因此应该被切割成两部分。
但是输出结果为:
this is a demo, this
is a
demo
这是怎么回事?
2.2 源码分析
org.apache.commons.lang3.StringUtils#split(java.lang.String, java.lang.String)
/**
* Splits the provided text into an array, separators specified.
* This is an alternative to using StringTokenizer.
*
* The separator is not included in the returned String array.
* Adjacent separators are treated as one separator.
* For more control over the split use the StrTokenizer class.
*
* A {@code null} input String returns {@code null}.
* A {@code null} separatorChars splits on whitespace.
*
*
* StringUtils.split(null, *) = null
* StringUtils.split("", *) = []
* StringUtils.split("abc def", null) = ["abc", "def"]
* StringUtils.split("abc def", " ") = ["abc", "def"]
* StringUtils.split("abc def", " ") = ["abc", "def"]
* StringUtils.split("ab:cd:ef", ":") = ["ab", "cd", "ef"]
*
*
* @param str the String to parse, may be null
* @param separatorChars the characters used as the delimiters,
* {@code null} splits on whitespace
* @return an array of parsed Strings, {@code null} if null String input
*/
public static String[] split(final String str, final String separatorChars) {
return splitWorker(str, separatorChars, -1, false);
}
进入源码发现和最初现象的差不多,第一个参数是字符串,第二个是分隔符。
关键函数上的示例,都是单个分隔符,并没有多分隔符的例子。
再观察一下参数名称,第二个参数名称为 separatorChars 即为分割的字符(复数)!!
因此怀疑,这里的 "," 会被分视作三个分割字符,分别为 " 和 , 和 "。
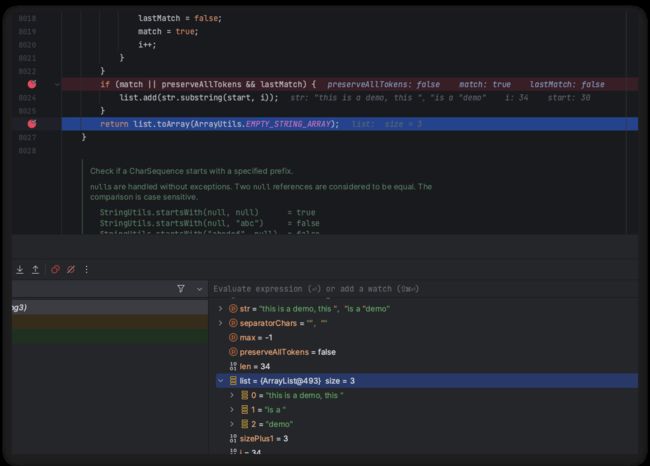
继续往底层分析,发现果然如此: org.apache.commons.lang3.StringUtils#splitWorker(java.lang.String, java.lang.String, int, boolean)。
/**
* Performs the logic for the {@code split} and
* {@code splitPreserveAllTokens} methods that return a maximum array
* length.
*
* @param str the String to parse, may be {@code null}
* @param separatorChars the separate character
* @param max the maximum number of elements to include in the
* array. A zero or negative value implies no limit.
* @param preserveAllTokens if {@code true}, adjacent separators are
* treated as empty token separators; if {@code false}, adjacent
* separators are treated as one separator.
* @return an array of parsed Strings, {@code null} if null String input
*/
private static String[] splitWorker(final String str, final String separatorChars, final int max, final boolean preserveAllTokens) {
// Performance tuned for 2.0 (JDK1.4)
// Direct code is quicker than StringTokenizer.
// Also, StringTokenizer uses isSpace() not isWhitespace()
if (str == null) {
return null;
}
final int len = str.length();
if (len == 0) {
return ArrayUtils.EMPTY_STRING_ARRAY;
}
final List<String> list = new ArrayList<>();
int sizePlus1 = 1;
int i = 0;
int start = 0;
boolean match = false;
boolean lastMatch = false;
if (separatorChars == null) {
// 省略
} else if (separatorChars.length() == 1) {
// 省略
} else {
// standard case
while (i < len) {
if (separatorChars.indexOf(str.charAt(i)) >= 0) {
if (match || preserveAllTokens) {
lastMatch = true;
if (sizePlus1++ == max) {
i = len;
lastMatch = false;
}
list.add(str.substring(start, i));
match = false;
}
start = ++i;
continue;
}
lastMatch = false;
match = true;
i++;
}
}
if (match || preserveAllTokens && lastMatch) {
list.add(str.substring(start, i));
}
return list.toArray(ArrayUtils.EMPTY_STRING_ARRAY);
}
而且通过调试发现的确走到这里。
2.3、解决办法
解决办法很简单,使用 String 的 split 方法:
public static void main(String[] args) {
String input = "this is a demo, this \",\"is a \"demo";
String[] split = input.split("\",\"");
for(String str: split){
System.out.println(str);
}
}
而且看源码可知,这里的参数是正则表达式。
/**
* Splits this string around matches of the given regular expression.
*
* This method works as if by invoking the two-argument {@link
* #split(String, int) split} method with the given expression and a limit
* argument of zero. Trailing empty strings are therefore not included in
* the resulting array.
*
*
The string {@code "boo:and:foo"}, for example, yields the following
* results with these expressions:
*
*
*
* Regex
* Result
*
* :
* {@code { "boo", "and", "foo" }} o
* {@code { "b", "", ":and:f" }}
*
*
* @param regex
* the delimiting regular expression
*
* @return the array of strings computed by splitting this string
* around matches of the given regular expression
*
* @throws PatternSyntaxException
* if the regular expression's syntax is invalid
*
* @see java.util.regex.Pattern
*
* @since 1.4
* @spec JSR-51
*/
public String[] split(String regex) {
return split(regex, 0);
}
三、启发
3.1 多看源码、多调试
当发现有些行为反直觉,不太对劲时,优先去查看底层源码,如果源码看不出来,可以进行调试。
另外,建议工作之余,在不是很忙的时候,可以主动看一些自己调用类的源码,一方面可以防止误用,另外一方面可以学习优秀源码的设计。
3.2 注释的规范性
在这个例子中大家可以看到,虽然 StringUtils.split 这个函数支持传入多个分割字符,但是并没有真正覆盖到多分割字符构成的字符串的情况,这是一大败笔。
这也给我们编写注释带来一些启发,首先工具类的测试,注释中可以给出常见调用示例和结果的对应关系,方便大家使用。但是注释中的示例要覆盖常见的输入和输出,至少不能出现令人误会的情况。
3.3 对面试的作用
如果有一天面试官问题,你对 JDK 或者你工作中用到的工具类库如 commons 和 guava 等,你能不能说一说他们有哪些不好的设计?有哪些 BUG ?
我相信大多数人是懵逼的,平时自己或者帮助身边人查问题的时候,可以适当留意一下这类问题。
3.4 及时请教
遇到问题首先自己排查,如果自己排除不出来可以优先问 AI,如果AI还是解决不了尽早问同事。
工作中遇到很多次,一些并不是很难的问题,因为“当局者迷”导致浪费很多时间,问身边的同事可能瞬间解决。
创作不易,如果本文对你有帮助,欢迎点赞、收藏加关注,你的支持和鼓励,是我创作的最大动力。
