⼤数据采集和可视化系统实现
前言
本篇博客用来记录 2022年春季大数据课程结课大作业(大三下,前8周,小组作业)
非常感谢小组同学的付出和积极配合!
文章目录
- 1. 实验目的
- 2. 实验环境
- 3. 实验要求
- 4. 实验内容
-
- 4.1 准备工作
- 4.2 数据的采集和发送
-
- 4.2.1 流程介绍
- 4.2.2 实验过程
- 4.2.3 源码解析
- 4.3 数据的消费和处理
-
- 4.3.1 流程介绍
- 4.3.2 实验过程
- 4.3.3 源码解析
- 4.3.4 程序集成
- 4.4 数据的存储
-
- 4.4.1 Hbase存储
- 4.4.2 Hive存储
- 4.4.3 Hdfs存储
- 4.4.4 Mysql存储
- 4.5 可视化展示
-
- 4.5.1 后端实现
- 4.5.2 前端实现
- 4.5.3 网站部署
- 5. 踩坑记录
- 6. 心得体会
- 7. 团队协作
1. 实验目的
了解Kafka、HDFS、MapReduce、Spark、HBase、Hive等组件在大数据体系结构中的角色,并通过本次综合实验对大数据技术在实际应用中的主要流程有初步的认识;
2. 实验环境
实验平台:基于实验一搭建的虚拟机Hadoop大数据实验平台上的Kafka、HDFS、MapReduce、Spark、HBase、Hive等集群;
编程语言:JAVA(推荐使用)、Python、C++等;
3. 实验要求
- 编程实现Kafka生产者,模拟数据采集的过程,向指定topic发送数据。
- 编写MapReduce或Spark程序,消费上述topic中的数据,并对数据进行一定的
处理,如求和、排序等。(鼓励使用流计算框架消费kafka上的数据,可以获得额外加分) - 上述程序将处理结果存储到HDFS文件系统中。(如果选用Hbase或Hive代替
HDFS,需要分别设计Hbase表或Hive表,会得到额外加分) - 将聚合后的结果通过简单的前端网页进行展示,这里可以考虑将聚合结果存储
到Mysql数据库再进行简单的展示。 - 对以上实验内容编写实验报告,并提交实验相关代码。
4. 实验内容
4.1 准备工作
同步cluster1、cluster2、cluster3的时间
// 重启时间同步服务(cluster1 上)
service ntpd restart
//同步时间(cluster2和cluster3)
ntpdate cluster1

// 切换到用户hadoop (三台)
su hadoop
//启动zookeeper (三台)
zkServer.sh start
//启动kafka (三台)
kafka-server-start.sh /usr/local/kafka_2.10-0.8.2.1/config/server.properties &
///启动HDFS (cluster1 上)
start-dfs.sh
//启动YARN (cluster1 上)
start-yarn.sh
//查看进程信息
jps

4.2 数据的采集和发送
4.2.1 流程介绍
考虑到实际待处理的数据非常大,但是在测试的过程中并不需要处理全部的数据量,因此将代码设置成用户可以自定义发送数据的条数。生产者首先从txt文件中读取数据,然后每读取一行数据就发送一条,直到发送完指定数目的条数或者到达文件末尾。kafka生产者的发送流程主要如下图所示:

具体来说,一个kafka的生产者逻辑主要包括如下4个步骤
- 配置生产者客户端参数及创建相应的生产者实例。
- 构建待发送的消息。
- 发送消息
- 关闭生产者实例
4.2.2 实验过程
编写java代码实现Kafka生产者,模拟数据采集过程,向指定的topic发送数据。
在/home/hadoop目录下创建目录lab4用来存放实验数据和代码。(kafka采集数据实验.txt重命名为kafkadata.txt,内容不变)

由于直接上传的代码xftp默认是root用户,因此需要修改用户的权限。
//改变所有者为hadoop
su root
chown -R hadoop:hadoop /home/hadoop/

cd ~/lab4
//编译
javac -cp /usrlocal/kafka_2.10-0.8.2.1/libs/* : Producer3.java
//运行
java -cp l/usr/local/kafka_2.10-0.8.2.1/lib/* : Producer3
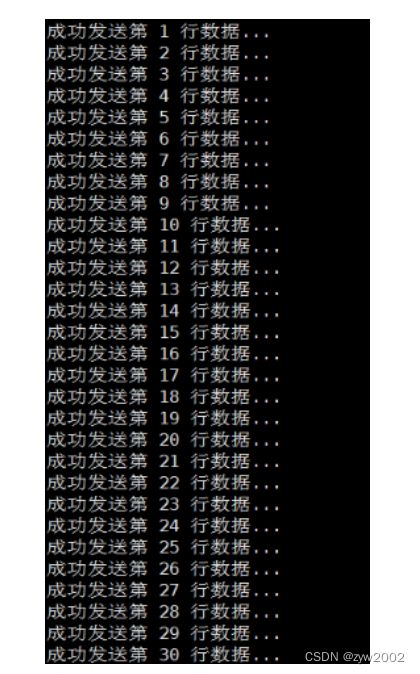
创建名称为dsj3 的topic,并先设置发送数据的行数是30条。
然后运行代码,成功的发送了前30条数据。

4.2.3 源码解析
props.put("metadata.broker.list", "cluster1:9092")用来指定生产者客户端连接Kafka集群所需的broker地址清单,具体的内容格式为host1:port1,host2:port2,可以设置一个或多个地址,中间以逗号隔开,此参数的默认值为“”。注意这里并非需要所有的broker地址,因为生产者会从给定的broker里查找到其他broker的信息。在此,我们设置生产者为cluster1。
Producer3.java代码具体实现如下:
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.Properties;
import java.util.Scanner;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class Producer3 {
public static void main(String[] args) {
// 1.配置生产者客户端参数及创建相应的生产者实例。
Scanner in = new Scanner(System.in);
Properties props = new Properties();
props.put("serializer.class", "kafka.serializer.StringEncoder"); // 序列化
props.put("metadata.broker.list", "cluster1:9092"); // broker 地址清单
Producer<Integer, String> producer = new Producer<Integer, String>(new ProducerConfig(props)); // 构建生产者
// 2. 构建待发送的消息
String topic;
System.out.print("请输入topic名称:"); // 创建topic
topic = in.next();
File file = new File("/home/hadoop/lab4/kafkadata.txt"); //文件读取路径
BufferedReader reader = null;
System.out.print("请输入发送数据行数:");
int num = in.nextInt(); // 用户自定义数据发送的行数
// 3. 生产者发动消息
try {
reader = new BufferedReader(new FileReader(file));
String tempString = null;
int line = 1;
while ((tempString = reader.readLine()) != null) { // 当没有达到文件末尾时,继续读取
producer.send(new KeyedMessage<Integer, String>(topic, tempString)); // 生产者发送数据
System.out.println("成功发送第 " + line + " 行数据...");
if (line == num) // 当发送指定条数的数据后,停止发送
break;
line++;
}
reader.close();
} catch (Exception e) { // 文件读取失败
e.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e1) {
}
}
}
// 4. 关闭生产者实例
producer.close();
}
}
4.3 数据的消费和处理
4.3.1 流程介绍
这一部分处理数据的逻辑就是kafka消费者接受来自生产者数据,然后在消费者端提交storm的topology,利用storm进行数据处理后将生成结果存储入库,再可视化展示。我们的消费者拉取数据类是Consumer_pull.java,拉取topic中的数据,支持多线程处理多个topic的分区,这里测试只采用了一个线程然后对应topic只建立了一个分区,对应消费实例是Consumer_storm,测试数据条数也只有30条。storm部分书写四个类,Topology类,Spout类,Split_Bolt类和Sum_Bolt类。Topology是提交的拓朴文件,描述storm数据流的拓朴结构,Spout是数据源,发送数据的源头,Split_Bolt和Sum_Bolt是两个数据处理类,分别用于分割数据和聚合数据。我们的结构非常简单,Spout — Split_Bolt — Sum_Bolt的线形结构,实验流程就是将消费者启动,再将生产者启动,输入topic名和数据条数,然后程序就启动成功。实现的功能是将航空公司日志聚合,统计出以一小时为时间间隔的时间段内各航空公司预定成功的数量。
4.3.2 实验过程
首先在生产者端(cluster1)要部属我的自己混合的lib文件夹以及producer_push.java和kafka.txt,三个文件;在消费者端(cluster2)要部署lib和Consumer_pull.java Consumer_storm.java Topology.java Spout.java Split_Bolt.java 和Sum_Bolt.java 七个文件。lib文件夹中是程序运行所需要的包,解决了storm和kafka运行包冲突的问题,所以在编译和运行时只需要导入lib文件中的包即可。
在编译程序之前要先启动kafka以及storm,实验流程在实验一的手册中,流程不再赘述,有一点区别是storm的nimbus端是cluster2,也就是要将cluster2和cluster1的实验一storm操作流程对换。
编译程序,在程序根文件夹下键入命令
javac -cp lib/*: *.java
编译成功
生产者端和消费者端都做如上编译处理,编译成功后,要先在生产者端利用kafka的console创建一个topic,键入命令如下,创建bighope主题名
kafka-topics.sh --create --zookeeper cluster1:2181,cluster2:2181,cluster3:2181 --replication-factor 3 --partitions 1 --topic bighope
然后先启动消费者程序,键入命令,
java -cp lib/*: Consumer_pull bighope
再启动生产者程序,键入命令,
java -cp lib/*: Producer_push
然后根据提示输入topic名以及数据条数,这里测试我们采取30条数据,topic名就是在之前创建的topic名,我们这里是bighope,结果如下
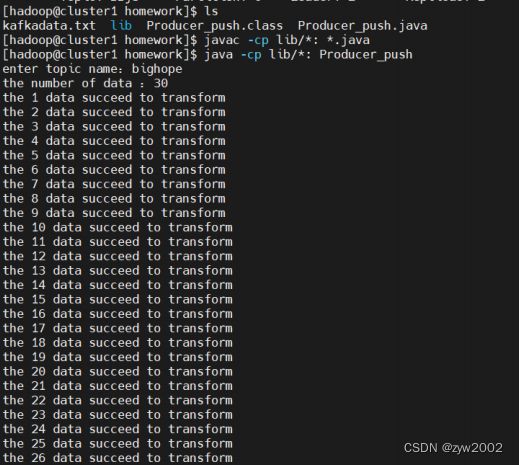
生产者端接收数据成功
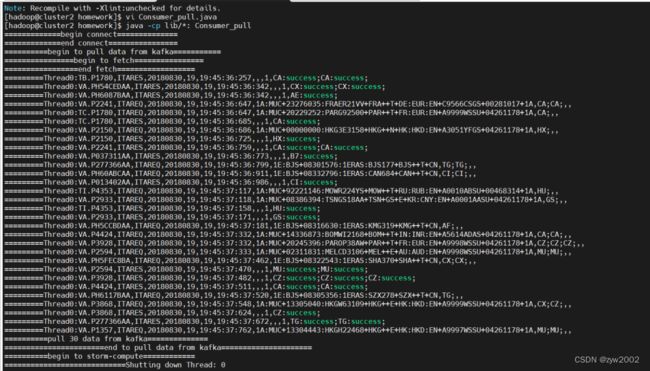
在接收数据后,kafka会进行一个消费实例,此实例可以实现不同线程处理方式不同,这里我们是单线程,使用Consumer_storm实例来利用storm消费数据,流程首先是成功提交Topology

spout开始传输数据

split_Bolt分割数据文件
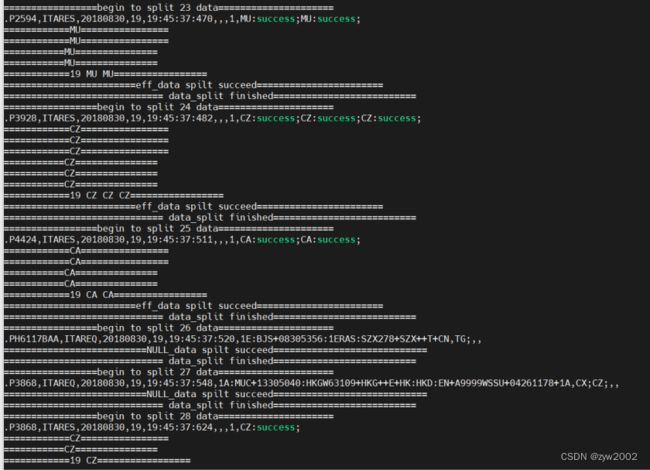
sum_Bolt聚合分割数据
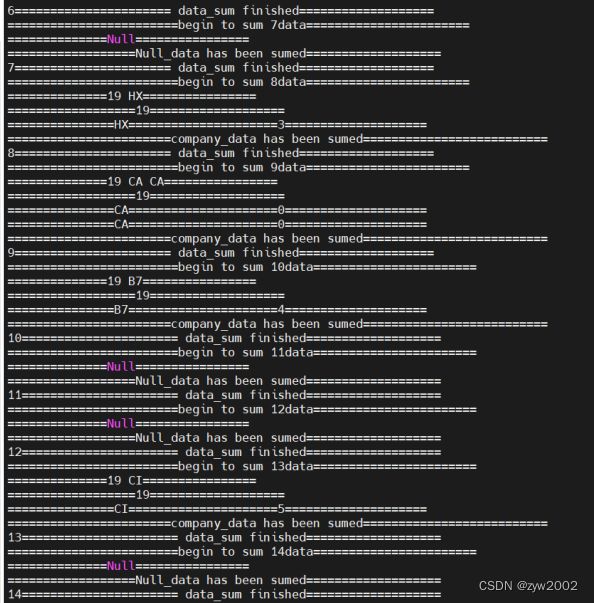
sum_Bolt写入文件
统计结果先写入fly-company_sum.txt,这里只处理了30条,数据量很少,后续会将数据写入数据存储设备

4.3.3 源码解析
接下来这部分,我会介绍消费者端以及storm的源码解析
- Consumer_pull.java
Comsumer_pull类,包含执行消费者拉取数据的主类
私有属性定义,消费者连接,topic名,线程执行对象
private final ConsumerConnector consumer;//consumer对象
private final String topic;//订阅的topic
private ExecutorService executor;//线程执行对象
初始化方法,Consumer_pull方法,连接kafka配置程序段,以及接收topic名
/**
*初始化消费者对象
*@parama_topic订阅的topic
*/
public Consumer_pull(String a_zookeeper,String a_groupId,String a_topic){
System.out.println("=============begin connect==============");
consumer= Consumer.createJavaConsumerConnector(createConsumerConfig(a_zookeeper,a_groupId));
System.out.println("=============end connect================");
this.topic=a_topic;
}
kafka消费者关闭方法,关闭线程执行以及消费者连接
/**
* kafka消费者关闭方法
*/
public void shutdown(){
if (consumer != null) consumer.shutdown();
if (executor != null) executor.shutdown();
try {
if (!executor.awaitTermination(60000, TimeUnit.MILLISECONDS)) {
System.out.println("Timed out waiting for consumer threads to shut down, exiting uncleanly");
}
} catch (InterruptedException e) {
System.out.println("Interrupted during shutdown, exiting uncleanly");
}
}
kafka消费者配置文件,这里的参数设置都是参考官网给的解释
/**
* 消费者配置文件
* @return ConsumerConfig
*/
private static ConsumerConfig createConsumerConfig(String a_zookeeper,String a_groupId) {
Properties props = new Properties();
props.put("group.id",a_groupId);//"group1"
props.put("zookeeper.connect",a_zookeeper);//"cluster1:2181,cluster2:2181,cluster3:2181"
props.put("zookeeper.session.timeout.ms", "400");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
props.put("consumer.timeout.ms","10000");
// props.put("auto.offset.reset","smallest");
// props.put(org.apache.kafka.clients.consumer.ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"range");
return new ConsumerConfig(props);
}
消费者run方法取出kafkastream这一数据流对象,然后我们进行处理将其传输到消费者实例中,使用excutor提交线程
/**
* 消费者kafkastream处理方式
* @param a_numThreads 线程总数
*/
public void run(int a_numThreads) {
System.out.println("==========begin to pull data from kafka===========");
Map<String,Integer> topicCountMap=new HashMap<String,Integer>();
topicCountMap.put(topic,new Integer(a_numThreads));
//System.out.println("================begin to fetch================");
Map<String,List<KafkaStream<byte[],byte[]>>> consumerMap=consumer.createMessageStreams(topicCountMap);
//System.out.println("=================end fetch==================");
//取出后的数据流存放在容器中,每个流对应一个线程
List<KafkaStream<byte[],byte[]>> streams=consumerMap.get(topic);
//部署所有线程
executor= Executors.newFixedThreadPool(a_numThreads);
//创建消费者对象,
int threadNumber=0;
for(final KafkaStream stream:streams){
executor.submit(new Consumer_storm(stream,threadNumber));//提交线程
threadNumber++;
}
}
消费者运行主函数,获取参数,传入方法中,并执行方法,这里只采用了单线程处理一个topic的一个分区,后续可以实现多分区处理,通过控制台控制线程数。
/**
*运行消费者端
*@paramargs控制台参数,会获取topic名
*/
public static void main(String[] args) {
/**
*执行kafka消费者端的进程,读取Consumer_pull拉取的数据
*/
String zookeeper="cluster1:2181,cluster2:2181,cluster3:2181";//zookeeper集群地址
String groupId="group1";//消费者群组名
String topic=args[0];//topic名
int threads=Integer.parseInt("1");//线程数
Consumer_pull pull=new Consumer_pull(zookeeper,groupId,topic);
pull.run(threads);//运行进程
try{
Thread.sleep(10000);
}catch (InterruptedException ie){
System.out.println("=======something interrupt=========");
}
pull.shutdown();
}
- Consumer_storm.java
在Consumer_pull里面的run方法中我们利用excutor提交了一个Consumer_storm对象,在这里会解析这一运行实例
属性定义,kafka数据流以及线程编号
private KafkaStream m_stream;//kafka数据流
private int m_threadNumber;//线程号
初始化对象
/**
* 消费类初始化
* @param a_stream kafka数据流
* @param a_threadNumber 线程号
*/
public Consumer_storm(KafkaStream a_stream,int a_threadNumber){
m_stream=a_stream;
m_threadNumber=a_threadNumber;
}
重写run函数,Consumer_storm实现Runnable接口方法,遍历kafka流,然后进行topology应用
public void run() {
ConsumerIterator<byte[], byte[]> it = m_stream.iterator();
int count = 0;
String[] str = new String[30];//存储30个数据大小
while (it.hasNext()) {
String data = new String(it.next().message());
System.out.println("=========Thread" + m_threadNumber + ":" + data);
str[count] = data;
count++;
}//数据遍历循环
System.out.println("==========pull " + count + " data from kafka ==============");
System.out.println("=======================end to pull data from kafka=====================");
System.out.println("============================Shutting down Thread: " + m_threadNumber);
Topology.Topology_arrage(new Spout(str));
}
- Topology.java
topology定义,配置topology,这里会画出你的topology结构,例如我的拓朴是split_bolt接收名为data_source的spout数据流源头的数据,sum_bolt接收名为split_data数据流源头的数据,一个简单的线形结构,后续若做出改进可以实现更复杂的topology。
public static void Topology_arrage(Spout spout){
Split_Bolt split_bolt=new Split_Bolt();
Sum_Bolt sum_bolt=new Sum_Bolt();
TopologyBuilder builder=new TopologyBuilder();//定义拓扑
builder.setSpout("data_source",spout,1);//设置spout线程
builder.setBolt("split_data",split_bolt,1).shuffleGrouping("data_source");//设置split_bolt线程
builder.setBolt("sum_data",sum_bolt,1).shuffleGrouping("split_data");//设置sum_bolt线程
利用本地提交topology,这里未向集群提交,在测试环节先实现本地处理,后续会努力实现向集群提交打包的jar包
Config conf=new Config();
//提交topology
try {
LocalCluster cluster = new LocalCluster();
System.out.println("=====================Topology local run begin=====================");
cluster.submitTopology("mytopology", conf, builder.createTopology());//提交topology
Utils.sleep(40000);
cluster.killTopology("mytopology");
cluster.shutdown();
// System.out.println("not local");
// StormSubmitter.submitTopology("mytopology",conf,builder.createTopology());
}catch (Exception e){
e.printStackTrace();
System.out.println("=============something wrong==============");
}
- Spout.java
继承BaseRichSpout,以及要重写其主要函数方法
属性定义,接收数据对象,存储数据的数组,以及定义自己发送tuple的名字
private SpoutOutputCollector collector;//定义发射tuple的对象
private int count=1;//发射数据的次数
private String[] str=new String[30];//存放数据的数组(30代表能处理数据的最大值)
private static final String field="string";//形成的tuple命名为string
初始化对象,将数据写入属性
/**
*初始化,获取数据
*@paramstr应用端输入的数据
*/
public Spout(String[] str){
this.str=str;
}
open方法,在spout开始执行时,首先进入该方法,将发射数据的collector类型写入属性
/**
* open 方法
* @param map storm的配置
* @param topologyContext topology组件信息
* @param spoutOutputCollector 发射tuple的方法
*/
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
System.out.println("======================spout start======================");
collector=spoutOutputCollector;
}
nextTuple 主要的执行方法,将数据打包成一个一个tuple发送出去,collector的emit方法就是发送数据的方法,将数据转换成tuple的value值写入tuple
/**
* nextTuple 方法
* 主要的执行方法,用于输出数据,是Spout实现的核心
*/
@Override
public void nextTuple() {
//遍历数据,进行发送
if (count<=str.length){
System.out.println("==========begin "+count+" data transform=========");
System.out.println(str[count-1]);
collector.emit(new Values(str[count-1]));
}
this.count++;
}
declareOutputFields方法,在这里定义tuple的键的名字,在属性定义时,field字段的名为“string”
/**
*声明数据格式,在输出的一个Tuple中包含几个字段
*@paramoutputFieldsDeclarer
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
System.out.println("===================combine frame...=======================");
outputFieldsDeclarer.declare(new Fields(field));
}
其余还有一些不重要的重写函数方法,有tuple处理失败以及成功时调用的方法,关闭spout数据流的方法,在这些方法里没有写入什么程序逻辑,只打印了一些标识,不再做过多赘述。
- Split_Bolt.java
Split_Bolt继承BaseRichBolt,实现数据分割,并重写多个函数
函数属性定义
private OutputCollector collector;//获取tuple的对象
private static int count=1;//数据处理条数记录
private static String field="word";//输出tuple的键值名
prepare函数,在类启动时首先执行的方法,参数传输OutputCollector对象,利用其发送tuple对象
/**
* Bolt启动前的执行代码
* @param map
* @param topologyContext
* @param outputCollector
*/
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
System.out.println("===================prepare split_Bolt begin==================");
collector=outputCollector;
}
excute函数,是Bolt的主要实现函数,在这部分将实现对数据的分割处理,我将代码分开进行分析
利用tuple获取tuple键值对中键值为string的值
public void execute(Tuple tuple) {
String str=tuple.getStringByField("string");//接收数据
然后对传入数据以‘,’分割后,对于索引为1的数据信息,判断该数据串是预定信息还是查询信息,我们期望对预定信息实现信息提取,将时间段和预定成功公司信息提取出来,利用空格连接后向后传输。list_cmp表单中保存预定成功公司信息,获取方式是将数据最后一个字段以‘;’分割,再将分割后的字段以‘:’分割,索引0就是公司名。数据字段3保存起始时间信息,我们的时间间隔是一小时,所以只记录起始时间,最后该Bolt实现数据转化的格式如下
原数据:TB.P1780,ITARES,20180830,19,19:45:36:257,1,CA:success;CA:success;
分割后数据:19 CA CA
String[] split_str=str.split(",");
if(split_str[1].equals("ITARES")){
List<String> list_cmp=new ArrayList<>();//公司列表
String[] comp_g=split_str[split_str.length-1].split(";");
for(int i=0;i<comp_g.length;i++){ //
String[] comp=comp_g[i].split(":");
//System.out.println("================="+comp[0]+"==================");//
list_cmp.add(comp[0]);//对应公司写入表单
}
String output=split_str[3];//最后输出结果,先将时间写入
//将表单中的公司名连接到结果串中
for(int i=0;i<list_cmp.size();i++){
//System.out.println("========"+list_cmp.get(i)+"==========");
output=output.concat(" ").concat(list_cmp.get(i));
}
System.out.println("============"+output+"==============");
collector.emit(new Values(output));
collector.ack(tuple);
System.out.println("==========================eff_data spilt succeed=======================");
}
当不为预定信息时,我们同样也做处理,保证前后数据大小的一致性,将该种数据转化为Null,在后续聚合时进行一个识别然后不做处理
else {
collector.emit(new Values("Null"));
collector.ack(tuple);
System.out.println("============================NULL_data spilt succeed============================");
}
declareOutputFields函数,定义发出tuple的键值名
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields(field));
}
- Sum_Bolt.java
将数据聚合,并在测试阶段先写入文件,这里只解析主要的execute函数,和释放资源写入文件的clean up函数
属性定义,时间和航空公司编号建立二维数组存储结果,利用编号查询list_camp
对应的公司名
private int sum[][]=null;//时间与航空公司关于预定成功次数的二维数组
private List list_camp=null;//航空公司序列号
private static intcount=1;//数据处理条数
excute函数,将数据分割聚合保存,同样分段解析
读取split_bolt发送的word字段的值
@Override
public void execute(Tuple tuple) {
String str=tuple.getStringByField("word");
读入字段不为Null时证明时预定信息,将其以空格分割,索引值为0的字段是时间信息,对应sum的行索引。遍历剩余字段,若在公司表单不存在该公司,将其加入公司表单,然后输出数据字段的公司名在表单中的索引,对应sum的列索引,每个数据字段代表其对应的sum要加一,全部处理成功后数据存储在sum数组中。
if(!str.equals("Null")) {
String[] data = str.split(" ");//输入数据格式是19 CV CX
int time=Integer.parseInt(data[0]);//时间索引
//System.out.println("=================="+time+"===================");
int camp_c=0;//公司索引
for(int i=1;i<data.length;i++){
if(!list_camp.contains(data[i])){
list_camp.add(data[i]);
}
camp_c=list_camp.indexOf(data[i]);
//System.out.println("==============="+data[i]+"====================="+camp_c+"====================");
sum[time][camp_c]++;//聚合统计
}
System.out.println("=======================company_data has been sumed==========================");
}
空字符,不做任何处理
else{
System.out.println("==================Null_data has been sumed===================");
}
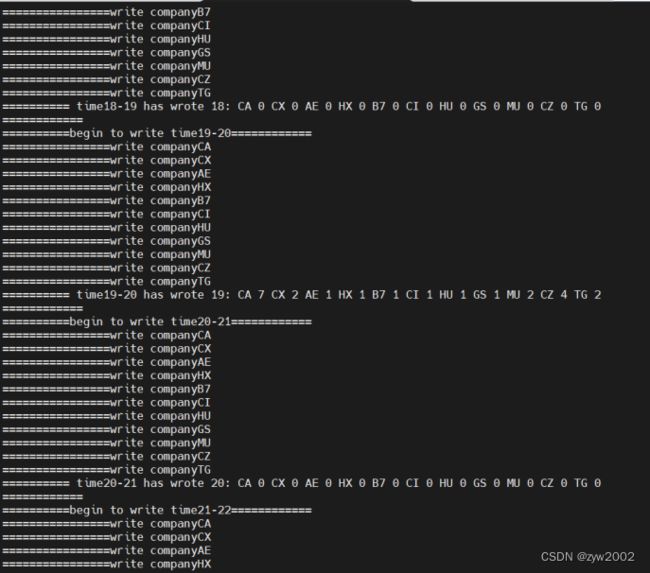
cleanup()函数,将聚合结果写入文件,与正常的文件写入流程相同,没什么逻辑,就是简单的遍历数组,得到实验流程中的文件结果。
@Override
public void cleanup(){
System.out.println("==============begin to write==============");
try {
//文件成员变量
BufferedWriter wr=new BufferedWriter(new FileWriter("fly-company_sum.txt"));
//遍历每一行数据,写入文件
for (int i = 0; i < 24; i++) {
System.out.println("==========begin to write time"+i+"-"+(i+1)+"============");
String wr_str=new String(""+i+":");
for (int j = 0; j < list_camp.size(); j++) {
wr_str=wr_str.concat(" "+list_camp.get(j) +" "+sum[i][j]);
//System.out.println("================write company"+list_camp.get(j));
}
wr_str=wr_str.concat("\n");
wr.write(wr_str);
System.out.println("========== time"+i+"-"+(i+1)+" has wrote "+wr_str+"============");
}
wr.close();
System.out.println("==============finish write file==============");
}catch (IOException e){
System.out.println("write-file failed");
}
}
至此,整个kafka storm数据消费处理的测试阶段完成,后续会将上面的cleanup方法进行一个改进将数据写入数据存储设备,不再写入文件。
4.3.4 程序集成
在实验的最后阶段,我将全部kafka数据集进行了一个处理,利用storm-kafka的集成技术,实现从topic直接拉取数据流作为Spout,进行后续的数据处理,并写入存储设备或写入文件。在测试阶段,实际上并没有将kafka和storm配合起来,只是利用kafka消费者端接收数据存储在一个数组中,然后传递给定义的Spout对象。这种方式实际上是在用流数据的框架进行批处理的任务,在实际场景中,本次实验的200MB的数据,java的堆不能容纳这么大的数据,所以让测试程序在实际场景中无法完成数据处理。
- 改进方式
将Consumer_pull以及消费者实例去掉,不再先用消费者端保存数据再处理,使用kafkaSpout这一集成对象,直接订阅kafka的topic作为Spout的数据流,代码在提交的压缩包里的src/application文件夹中。代码解析如下,
利用配置文件配置kafkaSpout,输入参数是订阅的topic,代理,以及要将Byte流的数据转化成string形式,Topology的结构和测试是相同的,提交方式依旧是本地提交,在Topology.java中设置主程序的入口。
public static void main(String[] args)throws Exception{
String zkConnString="cluster1:2181,cluster2:2181,cluster3:2181";
String topic=args[0];
BrokerHosts hosts=new ZkHosts(zkConnString);//Kafka代理
//kafka配置
SpoutConfig kafkaSpoutConfig=new SpoutConfig(hosts,topic,"/"+topic, UUID.randomUUID().toString());
kafkaSpoutConfig.bufferSizeBytes=1024*1024*300;
kafkaSpoutConfig.fetchSizeBytes=1024*1024*300;
kafkaSpoutConfig.scheme=new SchemeAsMultiScheme(new StringScheme());
//定义topology,storm直接从kafka的topic获取数据
KafkaSpout spout=new KafkaSpout(kafkaSpoutConfig);
Split_Bolt split_bolt=new Split_Bolt();
Sum_Bolt sum_bolt=new Sum_Bolt();
TopologyBuilder builder=new TopologyBuilder();//定义拓扑
builder.setSpout("data_source",spout,1);//设置spout线程
builder.setBolt("split_data",split_bolt,1).shuffleGrouping("data_source");//设置split_bolt线程
builder.setBolt("sum_data",sum_bolt,1).shuffleGrouping("split_data");//设置sum_bolt线程
- 实验结果
由于实验室的条件很不稳定,kafka总会掉线,所以只处理了一部分数据,结果如下

4.4 数据的存储
4.4.1 Hbase存储
使用HBase存储实际上就是将我们实验三的程序在这里集成一下,利用创建的连接类进行数据的插入即可,实验过程如下。
- 实验流程
首先要启动hbase,kafka,storm,启动程序都在实验一的文档中,storm的注意事项在数据消费阶段也提到了,这里不再重复。在本地创建一个lib文件夹,里面存储数据消费的集成包和hbase运行的包,在消费者端部署4.3的全部消费者源码以及HBaseUtils.java、Hbase_Store.java。
编译程序,键入
javac -cp lib/*: *.java
编译成功

按照4.3的运行流程,运行程序,利用hbase内核查看结果

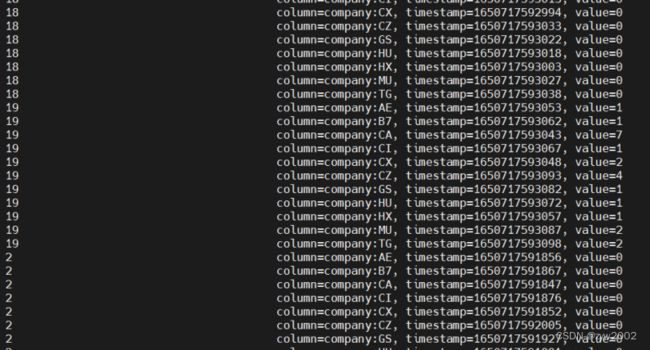
因为只有30条数据,结果在第二张图片更清晰,可以与4.3的结果文件比对一下。
- 源码解析
Sum_Bolt.cleanup
在这一部分做了一些修改,将4.3的写入文件改成了写入数据库,并打印一些标识
@Override
public void cleanup(){
System.out.println("==============begin to put data into HBase==============");
if(hbase.hbase_store(list_camp,sum)==24*list_camp.size()){
System.out.println("==================data has been put into HBase===================");
}
else {
System.out.println("==================Some data lost==================");
}
}
HBaseUtils.java
在这里我们不讲全部HBaseUtils文件做解析了,因为在实验三都使用过了,只介绍两个我们用到的方法。
第一个是创建table,没什么解析的,就调用方法就行。
/**
* 创建 HBase 表
*
* @param tableName 表名
* @param columnFamilies 列族的数组
*/
public static boolean createTable(String tableName, List<String> columnFamilies) {
try {
HBaseAdmin admin = (HBaseAdmin) connection.getAdmin();//获取admin
if (admin.tableExists(tableName)) {
return false;
}
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf(tableName));
for(String columnFamily:columnFamilies){
HColumnDescriptor columnDescriptor = new HColumnDescriptor(columnFamily);
columnDescriptor.setMaxVersions(1);
tableDescriptor.addFamily(columnDescriptor);
}
admin.createTable(tableDescriptor);
} catch (IOException e) {
e.printStackTrace();
}
return true;
}
添加行,输入参数表名,列簇名,列名,行号,值。
/**
* 插入数据
*
* @param tableName 表名
* @param rowKey 唯一标识
* @param columnFamilyName 列簇名
* @param qualifier 列标识
* @param value 数据
*/
public static boolean putRow(String tableName, String rowKey, String columnFamilyName, String qualifier,
String value) {
try {
Table table = connection.getTable(TableName.valueOf(tableName));//连接表
Put put = new Put(Bytes.toBytes(rowKey));//读入行名
put.addColumn(Bytes.toBytes(columnFamilyName), Bytes.toBytes(qualifier), Bytes.toBytes(value));//读入列簇名,列名,以及值
table.put(put);
table.close();
} catch (IOException e) {
e.printStackTrace();
}
return true;
}
Hbase_Store.java 定义了插入数据的执行方法,在第一个解析的cleanup方法中调用了。
属性定义,列名
private final List<String> column= Collections.singletonList("company");//列簇名
执行方法,参数为公司表单和聚合数据,先创建一个表名为“ITARES_SUM“的表,然后遍历数组将数据插入,每个列名为公司名,行号就是起始时间,并且将插入数据数放回到cleanup做一个判断数据是否丢失。
public int hbase_store(List<String> list_cmap, int[][] sum) {
//创建HBase表,表名为ITARES_SUM
//HBase表名
String tablename = "ITARES_SUM";
if(HBaseUtils.createTable(tablename, column)){
System.out.println("======================Successfully create hbase table=====================");
}else {
System.out.println("======================Failed to create hbase table===================");
}
//写入数据
System.out.println("==========================begin to put data========================");
int count=0;
for(int i=0;i<24;i++){
for(int j=0;j<list_cmap.size();j++){
System.out.println("=================data row "+i+" col "+j);
HBaseUtils.putRow(tablename,String.valueOf(i),"company",list_cmap.get(j),String.valueOf(sum[i][j]));
System.out.println("=================data row "+i+" col "+j+" successfully put");
count++;
}
}
return count;
}
将测试的数据消费入库的全部操作完成,
4.4.2 Hive存储
-
配置JDBC远程连接
Hive刚安装完成时不支持远程连接,因此需要事先配置好,才能够使用JDBC进行远程连接并操作Hive数据库。
-
配置hive-site.xml文件
修改或添加下列属性到/usr/local/apache-hive-1.1.0-bin/conf/hive-site.xml,3台虚拟机都要配置。
<!-- 配置metastore --> <property> <name>hive.metastore.uris</name> <value>thrift://cluster2:9083</value> <description>metastore连接的url</description> </property> <!-- 配置hiveserver2 --> <property> <name>hive.server2.thrift.bind.host</name> <value>cluster2</value> <description>hiveserver2的连接host</description> </propety> <property> <name>hive.server2.thrift.port</name> <value>10000</value> <description>hiveserver2的连接端口</description> </propety> -
初始化Hive服务
在本实验平台上,Hive使用的数据库是mysql数据库中的hive数据库,因此需要对数据库进行重新建立操作。
-
在mysql数据库中删除hive(如果存在),如何新建数据库hive
drop database if exists hive; create database hive; -
将hive数据库的全部权限赋予Hive所使用的用户hive
grant all on hive.* to hive@’%’; -
初始化Hive服务
schematool -initSchema -dbType mysql出现如下结果代表初始化Hive成功。
-

-
启动远程连接服务
-
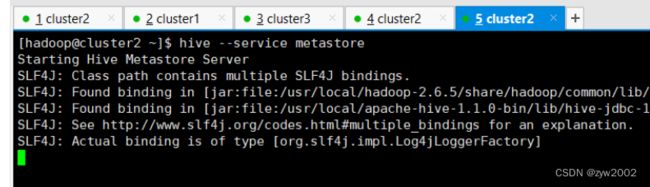
新开一个终端,切换到hadoop用户,启动metastore服务。
hive --service metastore出现如下界面即成功启动metastore服务。
-
再新开一个终端,切换到hadoop用户,启动hiveserver2服务。
hive --service hiveserver2出现如下界面即成功启动hiveserver2服务。
-
-
测试
使用beeline工具测试远程连接是否成功(最好使用apache-hive-1.1.0-bin/bin/目录下的beeline进行测试)
cd /usr/local/apache-hive-1.1.0-bin/ bin/beeline -u jdbc:hive2://cluster2:10000/default -n hadoop出现如下结果,可以远程连接对Hive进行操作。
-
-
远程操作Hive数据库文件 HiveTools.java
为了便于连接并操作Hive,书写了java代码,使用 JDBC 工具远程连接并操作Hive数据库,具体功能在HiveTools.java中集成实现
-
基础配置
包括JDBC连接Hive数据库配置,连接HDFS文件系统配置等
private final static String driverName = "org.apache.hive.jdbc.HiveDriver"; private final static String databaseName = "myTest"; // 数据库名称 数据库必须存在,否则要手动创建 private final static String tableName = "demo2"; // 数据表名称 private static String sql; private static Connection connection; private static Statement statement; private static ResultSet resultSet; private static Configuration conf; static { try { Class.forName(driverName); } catch (ClassNotFoundException e) { e.printStackTrace(); System.exit(1); } try { String user_name = "hadoop"; // 用户名 String user_password = "19281020"; // 密码 connection = DriverManager.getConnection( "jdbc:hive2://cluster2:10000/" + databaseName, user_name, user_password); statement = connection.createStatement(); System.out.println(connection); } catch (Exception e) { e.printStackTrace(); } try { // 加载HDFS文件配置项 conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://cluster1:9000"); conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem"); } catch (Exception e) { e.printStackTrace(); } } -
创建实验存放数据的表
/** * 创建内部表 * @param colName 内部表字段名称 * @param colType 内部表字段类型 */ public static void createTable(List<String> colName, List<String> colType) throws SQLException { // 若存在则先移除表 sql = "drop table if exists " + tableName; statement.execute(sql); // 表结构设计 String colStr = "("; // 内部表字段 int colLen = colName.size(); for (int i = 0; i < colLen - 1; i++) { colStr += colName.get(i) + " " + colType.get(i) + ','; } colStr += colName.get(colLen - 1) + " " + colType.get(colLen - 1) + ")"; // 创建内部表 System.out.println("====== create table " + tableName + " ======"); sql = String.format("create table %s %s row format delimited fields terminated by ','", tableName, colStr); statement.execute(sql); // 打印表结构 describeTable(); } -
上传数据操作
将实验数据上传到HDFS文件系统中,便于将实验数据存入Hive数据库
/** * 将数据上传到 HDFS 上的文件中 * @param targetPath HDFS 路径 * @param list_camp 公司名称 * @param count 成交次数 */ public static void uploadData(String targetPath, List<String> list_camp, int[][] count) throws IOException { // 创建文件系统实例 FileSystem fs = FileSystem.get(conf); // 创建文件实例 Path file = new Path(targetPath); // 重建文件 FSDataOutputStream outputStream = fs.create(file, true); System.out.println("====== upload data to HDFS ======"); long t1 = System.currentTimeMillis(); for (int i = 0; i < list_camp.size(); i++) { String name = list_camp.get(i); // 公司名称 for (int j = 0; j < count.length; j++) { int sum = count[j][i]; // 成交次数 // 写入数据到文件中 outputStream.write(String.format("%s,%d,%d\n", name, j, sum).getBytes(StandardCharsets.UTF_8)); //System.out.println(String.format("%s,%d,%d", name, j, sum)); } } long t2 = System.currentTimeMillis(); System.out.println("succeed to upload data to " + "hdfs://cluster1:9000" + targetPath ); // 打印消耗时间 System.out.printf("upload data spend time %dms%n", t2 -t1); fs.close(); } -
导入数据
将HDFS中的数据文件导入到Hive表中存放
/** * 从HDFS中导入数据到Hive表中 * @param filePath 数据文件在HDFS中的绝对路径 eg: /kunHive/data.txt */ public static void loadData(String filePath) throws SQLException, IOException { System.out.println("====== load data inpath filePath overwrite into table " + tableName + " ======"); if (!checkFile(filePath, false)) { if (!putFile("data.txt", filePath)) { return; } } // 开始导入数据 long t1 = System.currentTimeMillis(); sql = String.format("load data inpath '%s' overwrite into table %s", filePath, tableName); statement.execute(sql); long t2 = System.currentTimeMillis(); // 打印消耗时间 System.out.printf("load data spend time %dms%n", t2 -t1); } -
查看数据
查看导入到Hive表中的所有数据并返回
/** * select * from tableName; */ public static ResultSet selectAll() throws SQLException { System.out.println("====== select * from " + tableName + " ======"); long t1 = System.currentTimeMillis(); sql = String.format("select * from %s", tableName); resultSet = statement.executeQuery(sql); printResultSet(resultSet); // 打印信息 long t2 = System.currentTimeMillis(); // 打印消耗时间 System.out.printf("select data spend time %dms%n", t2 - t1); return resultSet; } -
对外接口
这个函数是对外接口,将实验得到的数据一步到位存放到Hive数据库中并展示。
/** * 此次实验的入口函数 * @param list_camp 公司名称 list_camp.get(i) * @param count 成交次数 二维数组 时间j 成交次数 count[j][i] */ public static void storeToHive(List<String> list_camp, int[][] count) throws IOException, SQLException { // 传入参数存在空值则退出 if (list_camp.isEmpty() || (count == null || count.length == 0) || (count.length == 1 && count[0].length == 0)) { return; } System.out.println("====== store data to Hive ======"); long t1 = System.currentTimeMillis(); // 初始化表,即判断是否存在,不存在则创建 initialize(); // 上传数据到 HDFS 中 uploadData("/kunHive/data.txt", list_camp, count); // 将数据加载到 Hive 中 loadData("/kunHive/data.txt"); long t2 = System.currentTimeMillis(); // 打印消耗时间 System.out.printf("store data to Hive spend time %dms%n", t2 -t1); // 查看 Hive 中的数据 selectAll(); }
-
-
演示
-
将Sum_Bolt.java文件中的cleanup函数修改为如下。
@Override public void cleanup(){ System.out.println("************** begin to write to Hive **************"); try { HiveTools hiveTools = new HiveTools(); hiveTools.storeToHive(list_camp, sum); System.out.println("************** finish write to Hive **************"); } catch (Exception e){ System.out.println("!!!!!! fail to write to Hive !!!!!!"); e.printStackTrace(); } } -
将HiveTools.java和修改后的Sum_Bolt.java文件移动到消费端,进行第4.3步:数据的采集和消费操作。
区别在于,编译和运行Consumer_pull.java文件时指令修改为如下javac -cp lib/*:/usr/local/apache-hive-1.1.0-bin/lib/*:/usr/local/hadoop-2.6.5/share/hadoop/common/*:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/*:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/*: Consumer_pull.java java -cp lib/*:/usr/local/apache-hive-1.1.0-bin/lib/*:/usr/local/hadoop-2.6.5/share/hadoop/common/*:/usr/local/hadoop-2.6.5/share/hadoop/common/lib/*:/usr/local/hadoop-2.6.5/share/hadoop/hdfs/*: Consumer_pull运行结果:
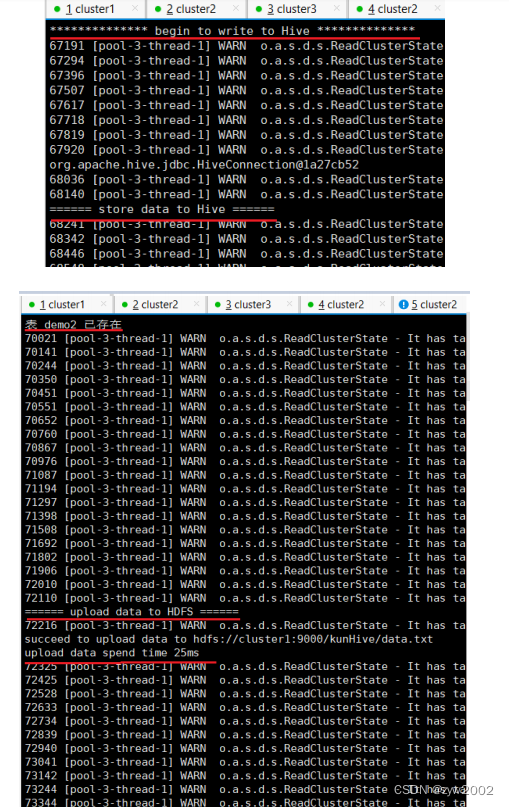 -
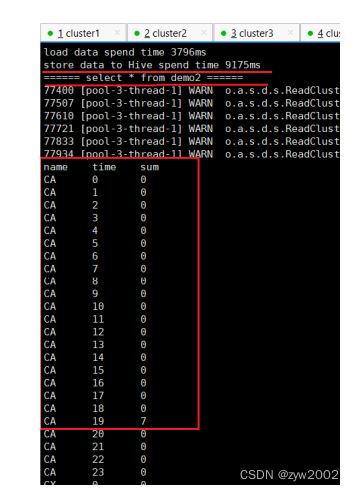
3. 在Hive数据库中查看结果
```sql
use myTest;
select * from demo2;
```
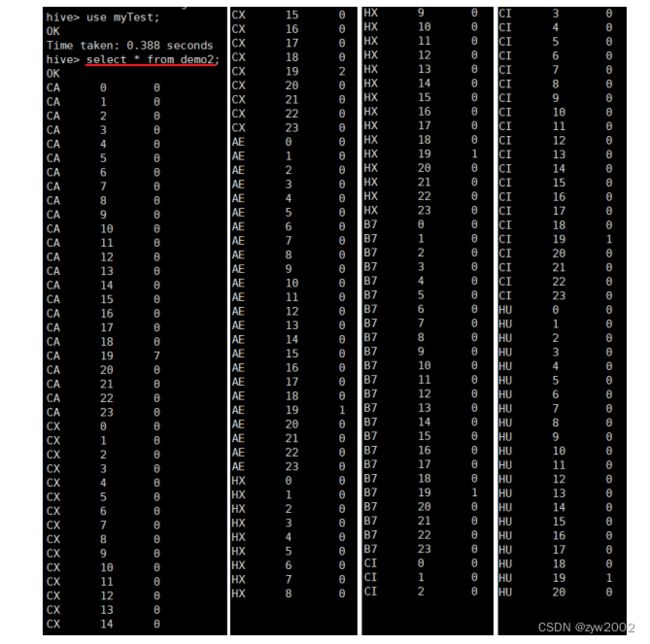
4.4.3 Hdfs存储
- 实验流程
- 使用Hdfs存储的过程首先应该按启动zookeeper集群,再在cluster1上启动HDFS和YARN。
$ zkServer.sh start //启动zookeeper集群(所有cluster)
$ start-dfs.sh //启动HDFS(cluster1)
$ start-yarn.sh //启动YARN(cluster1
- 编译,按照4.3的步骤运行程序
//cluster1
$ kafka-topics.sh --create --zookeeper cluster1:2181,cluster2:2181,cluster3:2181 --replication-factor 3 --p Created topic "test01"
$ javac -cp lib/*: *.java
$ java -cp lib/*: Producer_push
//cluster2
$ javac -cp lib/*: *.java
$ java -cp lib/*: Consumer_pull test01
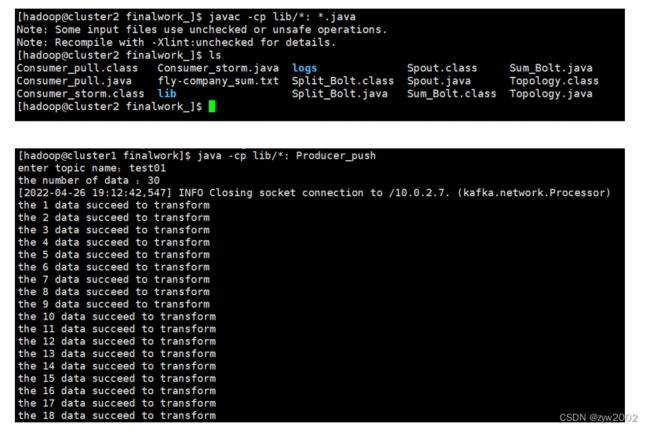
- 在HDFS查看结果
$ hadoop fs -ls //查看目录
$ hadoop fs -text fly-company_sum.txt //查看文件内容

在此展示前30条数据的结果。
- 源码解析
编写uploadtoHDFS()函数实现对生成文件的上传功能
使用 FileSystem来与HDFS文件系统建立连接,再根据生成文件的存放位置和HDFS存放位置,用copyFromLocalFile进行从本地到HDFS的文件拷贝。可以在此处把函数放在Consumer_Pull.java的main函数中调用执行。
public void uploadtoHDFS() throws Exception{
// 1 创建配置信息对象
String dsf = "hdfs://cluster1:9000";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(dsf),conf);
// 2 结果存放位置
Path src = new Path( "fly-company_sum.txt");
// 3 HDFS存放位置
Path dst = new Path("final_flyout.txt");
System.out.println("==============Upload to HDFS==============");
fs.copyFromLocalFile(src, dst);
System.out.println("==============finish Upload==============");
}
4.4.4 Mysql存储
- 使用Maven管理拓展jar包依赖
- ORM类型框架MyBatis成Mysql数据库管理
- 查询
- 插入
- 删除
- 修改
- 使用Junit4进行单元测试
- 第一步:
配置数据源:采用本地数据库测试(前端展示可以采用其他数据源)
操作映射:
DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="dev">
<environment id="dev">
<transactionManager type="JDBC">transactionManager>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url"
value="jdbc:mysql://rm-2ze1525no1u02fazjao.mysql.rds.aliyuncs.com:3306/cloud_db?useUnicode=true&characterEncoding=UTF-8"/>
<property name="username" value="xxx"/>
<property name="password" value="xxx"/>
dataSource>
environment>
environments>
<mappers>
<package name="dao">package>
mappers>
configuration>
- 第二步:工具类
package com.liangjiajia.mybatis.utils;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import java.io.IOException;
import java.io.Reader;
public class MyBatisUtils {
private static SqlSessionFactory sqlSessionFactory = null;
static {
Reader reader = null;
try {
reader = Resources.getResourceAsReader("mybatis-config.xml");
sqlSessionFactory = new SqlSessionFactoryBuilder().build(reader);
} catch (IOException e) {
e.printStackTrace();
throw new ExceptionInInitializerError(e);
}
}
public static SqlSession openSession() {
return sqlSessionFactory.openSession();
}
public static void closeSession(SqlSession session) {
if (session != null) {
session.close();
}
}
}
package utils;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class IOUtils {
public static void main(String[] args) {
IOData();
}
public static List<Map<String, Integer>> IOData() {
List<Map<String, Integer>> entries = new ArrayList<Map<String, Integer>>();
try {
RandomAccessFile file = new RandomAccessFile("src/main/java/fly-company_sum.txt", "r");
String str;
while ((str = file.readLine()) != null) {
Map<String, Integer> temp = new HashMap<String, Integer>();
int index = str.indexOf(":");
int time = Integer.parseInt(str.substring(0, index));
temp.put("time", time);
String ss = str.substring(index + 2);
String[] sss = ss.split(" ");
for (int i = 1, j = 0; j < sss.length; i++) {
temp.put(sss[j].toLowerCase(), Integer.parseInt(sss[j + 1]));
j += 2;
}
entries.add(temp);
}
file.close();
} catch (IOException e) {
e.printStackTrace();
}
return entries;
}
}
测试:
- 第三步:实体类Sum.java
- 第四步:DAO SQL语句接口
package dao;
import entity.Sum;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.SelectKey;
public interface SumDAO {
@Insert("INSERT INTO `sum`(`time`,ca, cx, ae, hx, b7, ci, hu, gs, mu, cz, tg) VALUES (#{time}, #{ca} , #{cx}, #{ae}, #{hx}, #{b7}, #{ci},#{hu}, #{gs}, #{mu}, #{cz}, #{tg})")
@SelectKey(statement = "select last_insert_id()", before = false, keyProperty = "time", resultType = Integer.class)
public int insert(Sum sums);
}
- 远程连接测试
@Test
public void testMyBatisUtils() throws Exception {
SqlSession sqlSession = null;
try {
sqlSession = MyBatisUtils.openSession();
Connection connection = sqlSession.getConnection();
System.out.println(connection);
} catch (Exception e) {
throw e;
} finally {
MyBatisUtils.closeSession(sqlSession);
}
}

- 远程初始化数据库
@Test
public void testInsert() throws Exception {
SqlSession session = null;
try {
session = MyBatisUtils.openSession();
List<Map<String, Integer>> collection = IOUtils.IOData();
for (Map<String, Integer> element : collection) {
Class SumClass = Class.forName("entity.Sum");
Class[] classes = new Class[12];
Arrays.fill(classes, Integer.class);
Constructor constructor = SumClass.getConstructor(classes);
Object[] objects = new Object[12];
Arrays.fill(objects, 0);
Sum sum = (Sum) constructor.newInstance(objects);
for (String key : element.keySet()) {
Integer value = element.get(key);
Field keyField = SumClass.getDeclaredField(key);
keyField.setAccessible(true);
keyField.set(sum, value);
}
SumDAO sumDAO=session.getMapper(SumDAO.class);
sumDAO.insert(sum);
session.commit();
}
} catch (Exception e) {
if (session != null) {
session.rollback();
}
throw e;
} finally {
MyBatisUtils.closeSession(session);
}
}
- Alibaba MySQL 查看

初始化云数据库成功(前面演示的30条数据)
4.5 可视化展示
4.5.1 后端实现
- django 环境配置
- 安装虚拟环境以及django
// 首先打开Anaconda Prompt,新建一个名为djangoEnv的虚拟环境
conda create -n djangoEnv python=3.6.3
// 进入虚拟环境
activate djangoEnv
// 安装django 2.1.4 版本
pip install django==2.1.4
- 检查是否安装成功
// 检测是否安装成功。在命令行中输入python
import django
django.get_version()

- 设置环境变量
输入 conda env list 查看该虚拟环境的安装路径。
然后在该安装路径下找到Script 文件夹
Scripts 文件夹中有一个django-admin.exe文件,就说明Django已安装成功。把scripts文件夹的路径加入操作系统的环境变量Path中,这样就可以直接在命令行终端输入Django命令。
在这里插入图片描述
- 创建django 项目
使用 django-admin 来创建项目:Anaconda Prompt窗口下输入django-admin startproject 项目名称
然后就可以看到新生成的项目目录bigdata,以及manage.py文件,可以通过这个文件生成应用程序。
然后打开项目目录,会有4个文件,分别如下
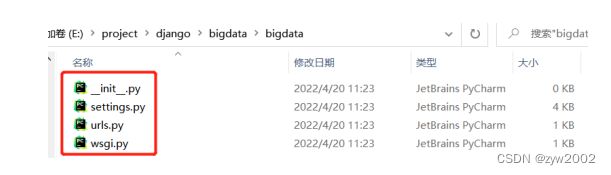
__init.py__
# 一个空文件,用来告诉Python这是myproject目录的一个模块
setting.py
# 项目配置文件,包含一些初始化设置# 存放URL表达式的文件,这里定义的每一个URL都对应一个视图函数,这个文件称为路由文件
urls.py
# 服务器程序和应用程序的一个协议接口,规定了使用的接口和功能,这个文件不需修改, Django已为项目配置好
wsgi.py
# 一个 WSGI 兼容的 Web 服务器的入口,以便运行你的项目
- 创建应用程序
创建应用(一个项目下可以创建多个应用): 键入命令python manage.py startapp myapp

__init__.py
admin.py # 配置管理后台,写少量代码就可以启用Django Admin管理后台
apps.py: # 存放当前应用程序的配置
models.py # 存放数据库相关的内容
tests.py # 可在这个文件写测试代码以对当前应用程序进行测试
views.py # 存放业务请求功能的代码
migrations/ # 这个文件夹中的文件保存该应用程序的数据库表与变化的相关内容
最后在pycharm中导入django的环境

- 连接阿里云数据库
-
新建一个云数据库
cloud_db

-
创建表格
use `cloud_db`;
DROP TABLE IF EXISTS sum;
create table sum
(
time int(10)AUTO_INCREMENT ,
ca int (10) DEFAULT 0,
cx int (10) DEFAULT 0,
ae int (10) DEFAULT 0,
hx int (10) DEFAULT 0,
b7 int (10) DEFAULT 0,
ci int (10) DEFAULT 0,
hu int (10) DEFAULT 0,
gs int (10) DEFAULT 0,
mu int (10) DEFAULT 0,
cz int (10) DEFAULT 0,
tg int (10) DEFAULT 0,
primary key (time)
);
DESC sum;
运行效果如下图所示:
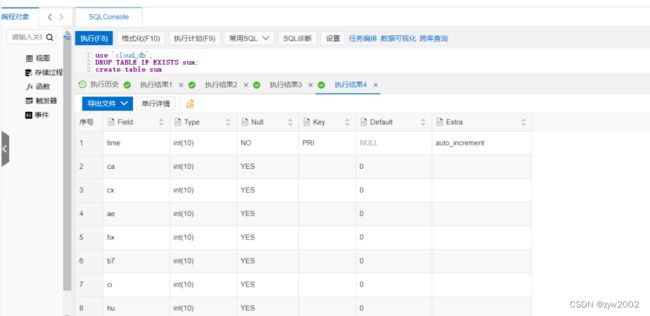
- 向表中插入数据
- 连接阿里云数据库RDS
首先现在阿里云控制台上申请一个外网地址,然后复制该外网地址。

setting.py 文件中修改数据库的配置如下:
NAME:数据库的名称。先要进阿里云创建一个数据库才行,因为一个RDS云数据库里面可以有很多个数据库的。
USER:阿里云数据库的账号。
PASSWORD:账号的密码。
HOST:数据库服务器的外网地址。
PORT:数据库默认的端口是3306。

然后需要在_init_.py文件中添加如下配置,指明以pymysql模块代替MySQLdb模块,这里要十分注意字母的大小写

- 功能模块1:表格显示
-
编写models.py文件,建立数据表。
其中sum是数据表的名称,以一个类的形式被定义。然后接下来的每一项都是一列数据。如time表示时间段,其中0表示01点,1表示12点,以此类推。后续的ca, cx分别表示不同航空公司在该时间段预定成功的个数。
from django.db import models
# Create your models here.
class sum(models.Model):
time = models.IntegerField()
ca = models.IntegerField(default=0)
cx = models.IntegerField(default=0)
ae = models.IntegerField(default=0)
hx = models.IntegerField(default=0)
b7 = models.IntegerField(default=0)
ci = models.IntegerField(default=0)
hu = models.IntegerField(default=0)
gs = models.IntegerField(default=0)
mu = models.IntegerField(default=0)
cz = models.IntegerField(default=0)
tg = models.IntegerField(default=0)
- 编写
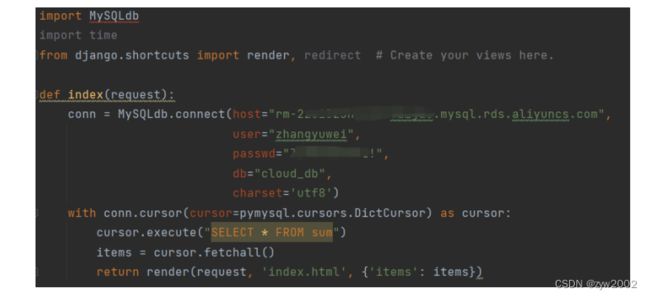
views.py文件,实现业务逻辑代码
定义一个index函数,传入的参数是request的请求信息。首先用MySQLdb.connect函数用来连接数据库,然后用游标conn.cursor对数据表进行遍历。得到数据库cloud_db中数据表sum的所有信息,然后用render返回给网页进行展示。
- 编写
index.xml文件,建立网页模板
在myapp下新建一个templates的文件夹,然后在该文件夹下新建一个index.html的文件。
DOCTYPE html>
<html lang="en">
<head> <meta charset="UTF-8">
<title>数据汇总title>
head>
<body> <table border="1px" width="100%" style="border-collapse: collapse;">
<h1>大数据统计平台h1>
<h5>说明: Time这列中0表示0点到1点,1表示1点到2点,依次类推h5>
<tr>
<th>序号th>
<th>Timeth>
<th>CAth>
<th>CXth>
<th>AEth>
<th>HXth>
<th>B7th>
<th>CIth>
<th>HUth>
<th>GSth>
<th>MUth>
<th>CZth>
<th>TGth>
tr>
{% for item in items %}
<tr>
<td>{{ forloop.counter }} td>
<td align="center">{{ item.time }}td>
<td align="center">{{ item.ca }}td>
<td align="center">{{ item.cx }} td>
<td align="center">{{ item.ae }}td>
<td align="center">{{ item.hx }} td>
<td align="center">{{ item.b7 }}td>
<td align="center">{{ item.ci }} td>
<td align="center">{{ item.hu }}td>
<td align="center">{{ item.gs }} td>
<td align="center">{{ item.mu }}td>
<td align="center">{{ item.cz }} td>
<td align="center">{{ item.tg }}td>
tr>
{% endfor %}
table>
body>
html>
- 配置
urls.py, 建立URL和视图函数的对应关系
首先在myapp文件夹下新建一个urls.py文件,在urlpatterns中添加列表项,声明views中编写的逻辑代码与网页地址之间的映射关系,代码内容如下
from django.conf.urls import url
from . import views
urlpatterns = [ url(r'^$', views.index),
]
然后还需要修改bigdata/urls.py 文件,使其包括所有在myapp/urls.py中定义的路径,修改代码如下:
from django.contrib import admin
from django.urls import path,include
from myapp import views
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('myapp.urls')),
]
- 运行代码,测试结果
直接在pycharm中点击运行,然后在浏览器中访问127.0.0.1:8000 , 效果示意如下图,说明成功的实现了代码逻辑部分。

- 功能模块2:数据查询
- 在views.py文件中添加逻辑函数
time_select,执行SELECT * FROM sum where time between 0 and 11实现按照时间段的范围进行查找的功能。

- 编写
time_select.html文件,实现前端网页模板
- 建立URL与视图函数间的对应关系

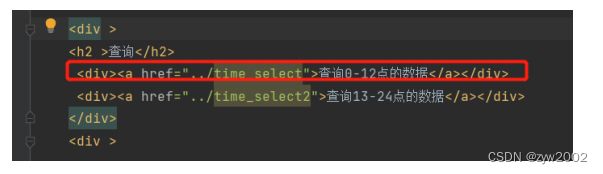
- 在主页面index中添加查询入口
同理,按照上述的方法还实现了查询13-24点的航班预定信息。测试效果如下

- 功能模块3——数据统计
按照功能模块2的实现方法,同样可以编写逻辑函数,通过对游标执行不同的sql语句实现数据的统计功能。例如 cursor.execute("SELECT AVG(ca) as avg_ca,AVG(cx) as avg_cx, AVG(ae) as avg_ae, AVG(hx) as avg_hx, AVG(b7) as avg_b7, AVG(ci) as avg_ci, AVG(hu) as avg_hu,AVG(gs) as avg_gs,AVG(mu) as avg_mu, AVG(cz) as avg_cz,AVG(tg) as avg_tg from sum") 语句实现平均值,然后还可以将AVG函数变为MAX,MIN函数来求解最大值和最小值。具体实现不再赘述,功能展示如下:

- 功能模块4——数据排序
按照功能模块2的实现方法,同样可以编写逻辑函数,通过对游标执行不同的sql语句实现数据的排序功能。例如 SELECT * FROM sum order by ca 语句实现按照ca的数量进行升序排序,然后还可以在其后添加关键字 DESC实现 降序排序。 具体实现不再赘述,功能展示如下:

4.5.2 前端实现
- 前端实现配置
由于Django在默认情况下不能实现CSS、FONT等界面前端效果,因此我们需要对Django进行进一步配置。
- 在项目中
manage.py同级目录下新建static文件夹,在static文件夹下新建css、js等文件夹,并在相应的文件下放入我们需要的文件。

- 与项目同名的包下的settings.py中配置静态文件路径,在
settings.py的最后面,STATIC_URL = '/static/'这一行后面添加:
STATIC_URL = '/static/'
STATICFILES_DIRS = [
(os.path.join(BASE_DIR, 'static'))
]
-
在调用了.css文件的html文件(templates\index.html)中加入custom-style.css的路径,注意此处路径为
/static/css/custom-style.css

-
在terminal下运行
python [manage.py](http://manage.py) runserver,在浏览器中输入http://127.0.0.1:8000/即可看见可视化界面(下图为index.html文件的示例)
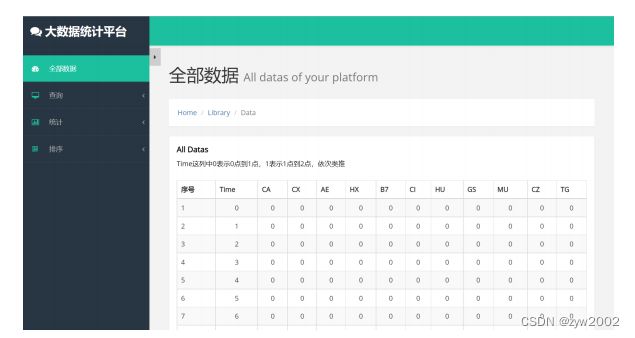
- 界面总体设计
基于4.5.1中提到的后端基本功能,我们进行了界面的进一步细化与展示。
我们将现有功能分为四部分(全部数据展示、数据查询、数据统计、数据排序),并由index.html作为主界面完成数据的全部展示,并在界面左侧提供数据查询、统计与排序的选项,点击左侧栏相应按钮进行功能界面跳转。各界面展示如下
- 首页:index.html
此部分主要采取表格的形式展示,如上图
- 数据查询(0-11):time_select.html
数据查询(12-23):time_select2.html

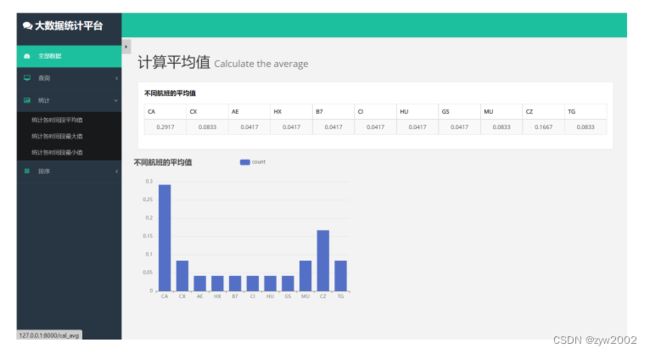
- 数据统计-计算平均值(cal_avg.html)
在此界面除了利用表格展示信息外,我们额外增加了柱状图便于观察。
首先引入echarts用以柱状图的显示,需要在中加入
<script src="https://cdn.bootcdn.net/ajax/libs/echarts/5.3.2/echarts.common.js"></script>
然后在中加入柱状图的具体实现部分,用dd存取从数据库中获取的数据,由于获取的数据为一个字符串,且存在一定的干扰项,因此我们通过正则语法对其进行拆分,再将拆分后的数据进行显示。
<script type="text/javascript">
var dd = '{{ items }}';
console.log(typeof dd);
var ss = dd.match(/\d+\.\d+/g);
ss = ss.map(Number);
var myChart = echarts.init(document.getElementById('main'));
var option = {
title: {
text: '不同航班的平均值'
},
tooltip: {},
legend: {
data: ['count']
},
xAxis: {
data: ['CA', 'CX', 'AE', 'HX', 'B7', 'CI', 'HU', 'GS', 'MU', 'CZ', 'TG']
},
yAxis: {},
series: [
{
name: 'count',
type: 'bar',
data: ss
}
]
};
myChart.setOption(option);
</script>
界面运行展示如下:
- 数据统计-计算最大值(cal_max.html)
同cal_avg.html一样,我们采用了echarts用以显示折线图,除了增加必要的echarts引用外,我们还需要在部分增加的代码部分如下
<script type="text/javascript">
var dd = '{{ items }}';
console.log(dd);
console.log(typeof dd);
var dd = dd.split("'");
console.log(dd);
var ss = []
for (var i = 1; i <= dd.length - 1; i++) {
if (i % 2 == 0) {
ss.push(dd[i]);
console.log(dd[i]);
}
}
for (let i in ss) {
ss[i] = ss[i].replace(/[^0-9]/ig, "");
console.log(ss[i]);
}
ss = ss.map(Number);
var myChart = echarts.init(document.getElementById('main'));
var option = {
xAxis: {
data: ['CA', 'CX', 'AE', 'HX', 'B7', 'CI', 'HU', 'GS', 'MU', 'CZ', 'TG']
},
yAxis: {},
series: [
{
data: ss,
type: 'line',
label: {
show: true,
position: 'bottom',
textStyle: {
fontSize: 20
}
}
}
]
};
myChart.setOption(option);
</script>
界面运行展示如下:

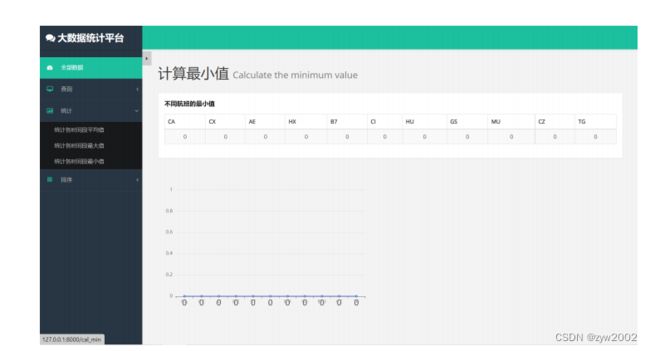
- 数据统计-计算最小值(cal_min.html)
<script type="text/javascript">
var dd = '{{ items }}';
console.log(dd);
console.log(typeof dd);
var dd = dd.split("'");
console.log(dd);
var ss = []
for (var i = 1; i <= dd.length - 1; i++) {
if (i % 2 == 0) {
ss.push(dd[i]);
console.log(dd[i]);
}
}
for (let i in ss) {
ss[i] = ss[i].replace(/[^0-9]/ig, "");
console.log(ss[i]);
}
ss = ss.map(Number);
var myChart = echarts.init(document.getElementById('main'));
var option = {
xAxis: {
data: ['CA', 'CX', 'AE', 'HX', 'B7', 'CI', 'HU', 'GS', 'MU', 'CZ', 'TG']
},
yAxis: {},
series: [
{
data: ss,
type: 'line',
label: {
show: true,
position: 'bottom',
textStyle: {
fontSize: 20
}
}
}
]
};
myChart.setOption(option);
</script>
界面运行展示如下:
- 数据排序-按CA降序排序(orderby_ca.html )、按CA升序排序(orerby_ca_up.html)
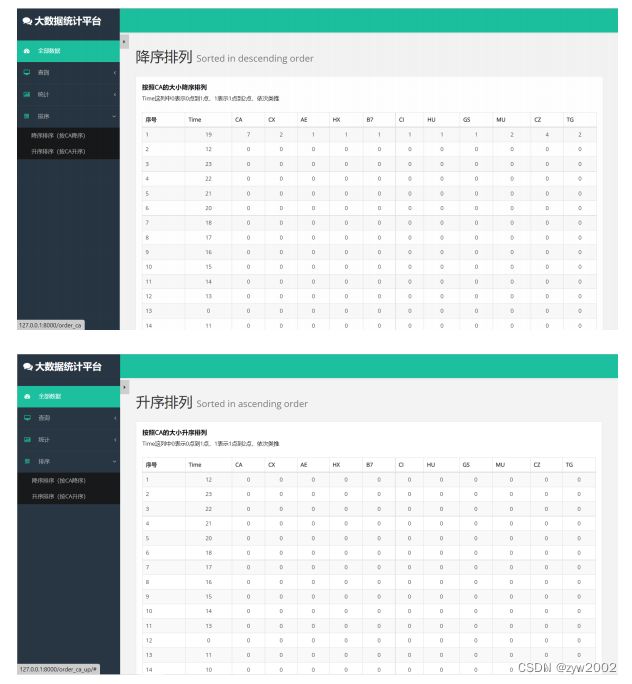
4.5.3 网站部署
- 环境部署
一、 下载 python3 到/usr/local 目录
1.1. 切换到 /usr/local 目录
1.2. 获取 python3.6 的压缩文件 wget [https://www.python.org/ftp/python/3.6.3/Python-3.6.3.tgz](https://www.python.org/ftp/python/3.6.3/Python-3.6.3.tgz)
1.3 解压 python3.6 tar -zxvf Python-3.6.6.tgz
1.4 编译安装 python3 到指定路径
1.4.1 执行命令 ./configure --prefix=/usr/local/python3
1.4.2 安装 python3 make make install
1.4.3 安装完成之后,建立软链接,添加变量,方便在终端中直接使用 python3
a)python3 的软连接
执行命令: ln -s /usr/local/python3/bin/python3.6 /usr/bin/python3
b)pip3 的软连接
执行命令: ln -s /usr/local/python3/bin/pip3.6 /usr/bin/pip3
二、 安装软件管理包和可能使用的依赖
2.1. 执行命令: yum -y groupinstall "Development tools"
2.2. 执行命令: yum install openssl-devel bzip2-devel expat-devel gdbm-devel readline-devel sqlite-devel
三、 安装 virtualenv
3.1.执行命令: pip3 install virtualenv
3.2.建立软连接 执行命令: ln -s /usr/local/python3/bin/virtualenv /usr/bin/virtualenv
3.3.在根目录下建立文件夹,用于存放 env mkdir -p /data/env
四、 切换到/data/env/下,创建指定版本的虚拟环境
4.1.执行命令 : cd /data/env 切换目录
4.2.执行命令: virtualenv --python=/usr/bin/python3 pyweb
4.3.进入/data/env/pyweb/bin,启动虚拟环境
A.执行命令: cd /data/env/pyweb/bin
B.执行命令: source activate
- 修改代码配置
修改 setting.py 文件
ALLOWED_HOSTS = ['*'] # 设置为所有的主机都可以访问
STATIC_ROOT = os.path.join(BASE_DIR,"static") # 设置静态文件的路径
DEBUG = False
修改url.py文件, 添加静态配置路径
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('myapp.urls')),
url(r'^static/(?P.*)$' ,static.serve,{'document_root': '/www/wwwroot/bigdata/static',}),
]
- 代码上传与启动
通过阿里云控制台,开放安全组
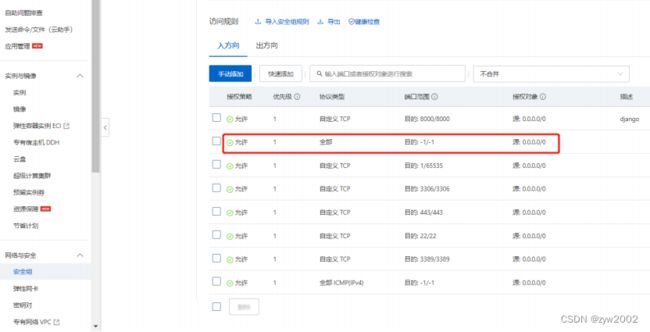
首先通过宝塔面板,将代码上传到阿里云服务器上。
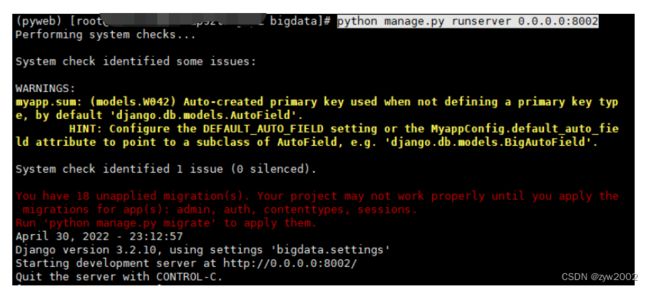
输入如下命令,激活并进入虚拟环境
cd /www/wwwroot/bigdata/
source /data/env/pyweb/bin/activate
然后启动网站
python manage.py runserver 0.0.0.0:8002
- 测试
分别在手机和电脑的浏览器中输入域名+端口号
-
电脑端测试
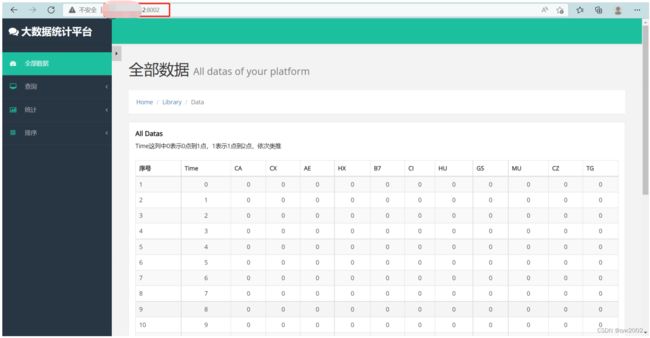
-
手机端测试

5. 踩坑记录
- 在向kafka传输数据时,出现以下错误,ERROR Failed to collate messages by topic, partition due to: Failed to fetch topic metadatafor topic: zzj(kafka.producer.async.DefaultEventHandler),原因是kafka-0.8.2.1需要先手动创建topic然后才能发送数据,利用命令创建一个topic后报错消失,但原先的报错并不影响topic的创建。
- 导入路径运行程序时,报错,detected both log4j-over-slf4j.jar and bound slf4j-log4j12.jar on the class path,原因是kafka libs里面的slf4j-log4j12.jar和storm lib里面的log4j-over-slf4j.jar 冲突,将slf4j-log4j12.jar先剪切到本地,问题解决
- 消费者的线程数要与topic的分区数相对应,即一个线程对应一个分区,对应可以改正的错误没有遇到,但是我做了这方面的修改。
- 在部署kafka消费者和生产者时,一开始没有仔细理解kafka的结构,将生产者程序和消费者程序部署在同一台服务器上,导致无法接收到数据,以及程序卡住等现象,正确的顺序应该是消费者部署在cluster2,生产者部署在cluster1,先启动消费者,再启动生产者,数据传输成功。
- 在使用storm向集群上传数据时,需要将程序打包,在本地maven工程打包时,pom.xml的依赖导入不了,使用手动命令输入的形式,将包下载下来之后导入。命令如下
mvn install:install-file -Dfile=libs/kafka_2.10-0.8.2.1.jar DgroupId=org.apache.kafka DartifactId=kafka_2.10 -Dversion=0.8.2.1 -Dpackaging=jar,这是kafka的包导入,storm格式相同,将名称改变即可。 - 在实验的后续过程中发现,测试和调试只需要在本地提交topology就可以,无需将程序打包,也就减少了很多错误的处理。
- 在kafka消费者配置时有一个参数,consumer.timeout.ms,这个参数决定在消费者实例中while(it.hasnext())中判断条件的真值,其默认值为-1,所以在未设置时,此循环始终无法进入。
- 在4.3程序集成部分,storm 1.1.1的包中的kafkaSpout无法使用,将包替换成storm-core-1.0.4,不同核心的匹配方式在maven的依赖库中都能查找,并且还根据提示增加了依赖的包,最关键的是curator的client和framework包,添加后编译成功。
- 在4.3程序集成部分,在cluster2上接收数据时会报错java的heap满了,也就是java的堆满了,上网查找也并没有找到好的解决方法,仔细分析了一下,发现数据发送和处理的速度并不匹配,我认为应该是kafkaSpout将数据都先存储在数组中导致堆爆了,所以在发送数据端书写一个线程延迟,让发送和处理速度基本一致,发送一条就处理一条。问题解决。
- 在处理django view向模板文件发送item对象时,误认为为json object,发送不符合json对象标准,为了不破坏前后端的接口,我将其解析为字符串,并用正则表达式已经一系列字符串操作得到对应的数值,并结合Echart的图表官方给出的样例合理优化形成我们自己所需要的折线图和柱状图。
6. 心得体会
-
ZYW
通过本次实验,我主要负责了kafka数据的发送,网页展示的后端实现,以及网站的部署。首先对整个大数据流程都有一个整体的认识。其次,我们将数据保存到阿里云的RDS云数据库中,网站的后端连接云数据库。最后又把网站的代码上传到云服务器中,实现了通过域名就可以在任何设备上访问网站。在本次实验中,大家远程互相帮助,小组内的合作氛围非常好,使得我受益匪浅。
-
ZZJ
通过本次实验,我对kafka storm hbase在实际场景中的应用进行了尝试,提高了我的java编程能力,让我熟练掌握流处理技术和kafka之间的配合。掌握本次课程所学的所有技术,为将来的继续学习做了铺垫。理解了API,classpath在编译运行过程中的大致作用,完成了基本上整个的实验流程,收获很大。
-
ZYQ
本次大作业,我主要负责HDFS部分的数据存储以及前端的部分代码实现。虽然并没有完全的参与到整个实验设计中,但我对每一步实验流程都有着一定的了解。虽然在实验的过程中遇见过一定的复现困难,但在组内同学的帮助下,问题都得以解决。本次大作业对我不但是对本学期所学知识的一次巩固与提升,也是对我们小组分工合作能力的测试与考验,我从中受益匪浅。
-
WK
这次实验,我做的主要工作是将消费数据处理的结果存储到Hive数据库中。在这个过程中,我学习并掌握了利用 JDBC 远程连接并操作Hive的知识技能。由于一开始Hive未能开启远程连接方式,我还顺便学习了如何开启Hive远程连接的功能。
Hive 对于每一次insert和update操作,都要执行Map和Reduce的操作,因此我使用 load data 的方法将数据直接存储到数据库中,具体做法是先将数据临时存放到HDFS文件系统中,在将其导入Hive数据库,完成了实验要求。 -
LJJ
通过本次实验,在同学们共同的努力下完成了一个比较完整的企业数据处理流程,对我来说的任务主要是将解析数据文本并将数据存储在云数据库,以及和朱雨琦同学一起将将组长搭建的框架前端部分完善。因为这两项任务基于的都是我这学期学习的课程内容,相当于也是一种别样的训练。数据存储部分为了得到数据部署了张子健同学的相同的结果也走了一遍流程,大致了解了kafka的工作流程。总得来说,一是个人收获很大!其次十分感谢同学们的配合和支持!
7. 团队协作
- ZYW负责工作
- 完成4.1:准备工作
- 完成4.2:数据的采集与发送
- 完成4.5.1: 数据可视化展示——后端实现
- 完成4.5.3: 网站部署
- ZZJ负责工作
- 完成4.3:数据的消费和处理
- 完成4.4.1:数据的存储——Hbase存储
- ZYQ负责工作
- 完成4.4.3:数据的存储——Hdfs存储
- 完成4.5.2:数据可视化展示——前端实现
- WK负责工作
- 完成4.4.2:数据的存储——Hive存储
- LJJ负责工作
- 完成4.4.4:数据的存储——mysql存储
- 完成4.5.2:数据可视化展示——前端实现
后记: 由于时间原因,如网站可视化的交互功能以及界面比较简单,有待后续进一步完善和美化。