RabbitMQ消息可靠性
你用支付宝给商家支付,如果是个仔细的人,会考虑我转账的话,会不会把我的钱扣了,商家没有收到我的钱?
一般我们使用支付宝或微信转账支付的时候,都是扫码,支付,然后立刻得到结果,说你支付了多少钱,如果你绑定的是银行卡,可能这个时候你并没有收到支付的确认消息。往往是在一段时间之后,你会收到银行卡发来的短信,告诉你支付的信息。
支付平台如何保证这笔帐不出问题?

支付平台必须保证数据正确性,保证数据并发安全性,保证数据最终一致性。
支付平台通过如下几种方式保证数据一致性:
(1)分布式锁
这个比较容易理解,就是在操作某条数据时先锁定,可以用redis或zookeeper等常用框架来实现。比如我们在修改账单时,先锁定该账单,如果该账单有并发操作,后面的操作只能等待上一个操作的锁释放后再依次执行。
优点:能够保证数据强一致性。缺点: 并发场景下可能有性能问题。
(2)消息队列
消息队列是为了保证最终一致性,我们需要确保消息队列有ack机制客户端收到消息并消费处理完成后,客户端发送ack消息给消息中间件如果消息中间件超过指定时间还没收到ack消息,则定时去重发消息。
比如我们在用户充值完成后,会发送充值消息给账户系统,账户系统再去更改账户余额。
优点:异步、高并发缺点:有一定延时、数据弱一致性,并且必须能够确保该业务操作肯定能够成功完成,不可能失败。
我们可以从以下几方面来保证消息的可靠性:
(1)客户端代码中的异常捕获,包括生产者和消费者
(2)AMQP/RabbitMQ的事务机制
(3)发送端确认机制
(4)消息持久化机制
(5) Broker端的高可用集群
(6)消费者确认机制
(7)消费端限流
(8)消息幂等性
1 异常捕获机制
先执行行业务操作,业务操作成功后执行行消息发送,消息发送过程通过try catch方式捕获异常,在异常处理理的代码块中执行行回滚业务操作或者执行行重发操作等。这是一种最大努力确保的方式,并无法保证100%绝对可靠,因为这里没有异常并不代表消息就一定投递成功。
boolean result = doBiz();
if (result) {
try {
sendMsg();
} catch (Exception ex) {
// retrySend();
// delaySend();
rollbackBiz();
}
}
另外,可以通过spring.rabbitmq.template.retry.enabled=true配置开启发送端的重试
2 AMQP/RabbitMQ的事务机制
没有捕获到异常并不能代表消息就一定投递成功了。
一直到事务提交后都没有异常,确实就说明消息是投递成功了。但是,这种方式在性能方面的开销比较大,一般也不推荐使用。
try {
// 将channel设置为事务模式
channel.txSelect();
//发布消息到交换器,routingKey为空
channel.basicPublish(EXCHANGE_NAME,"",null,message.getBytes("UTF-8"));
//提交事务,只有消息成功被Broker接收了才能提交成功
channel.txCommit();
} catch (Exception e) {
//事务回滚
channel.txRollback();
}
3 发送端确认机制
RabbitMQ后来引入了一种轻量量级的方式,叫发送方确认(publisher confirm)机制。生产者将信道设置成confirm(确认)模式,一旦信道进入confirm模式,所有在该信道上面面发布的消息都会被指派一个唯一的ID(从1开始),一旦消息被投递到所有匹配的队列之后(如果消息和队列是持久化的,那么确认消息会在消息持久化后发出),RabbitMQ 就会发送一个确认(Basic.Ack)给生产者(包含消息的唯一ID),这样生产者就知道消息已经正确送达了。
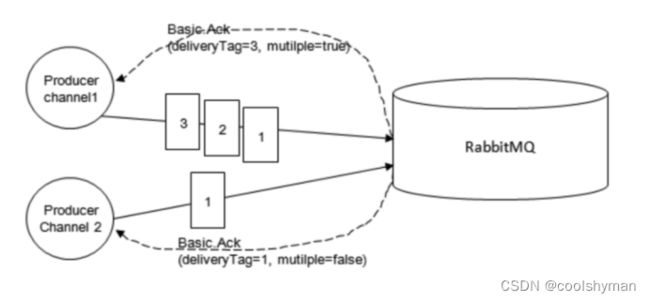
RabbitMQ回传给生产者的确认消息中的deliveryTag字段包含了确认消息的序号,另外,通过设置channel.basicAck方法中的multiple参数,表示到这个序号之前的所有消息是否都已经得到了处理了。生产者投递消息后并不需要一直阻塞着,可以继续投递下一条消息并通过回调方式处理理ACK响应。如果RabbitMQ因为自身内部错误导致消息丢失等异常情况发生,就会响应一条nack(Basic.Nack)命令,生产者应用程序同样可以在回调方法中处理该nack命令。
Connection connection = factory.newconnection();
Channel channel = connection.createChannel();
// Publisher Confirms
channel.confirmSelect();
channel.exchangeDeclare(EX_PUBLISHER_CONFIRMS,BuiltinExchangeType.DIRECT);
channel.queueDeclare(QUEUE_PUBLISHER_CONFIRMS,false,false,false,nu11);
channel.queueBind(QUEUE_PUBLISHER_CONFIRMS,EX_PUBLISHER_CONFIRMS,QUEUE_PUBLISHER_CONFIRMS);
String message = "hello";
channel.basicPub1ish(EX_PUBLISHER_CONFIRMS,QUEUE_PUBLISHER_CONFIRMS,null,message.getBytes());
try {
channel.waitForconfirmsorDie(5000);
System.out.print1n("消息被确认: message = " + message);
} catch (IOException e) {
e.printStackTrace();
System.err.print1n("消息被拒绝! message = " + message);
} catch (InterruptedException e) {
e.printStackTrace();
System.err.print1n("在不是Publisher Confirms的通道上使用该方法");
} catch (TimeoutException e) {
e.printStackTrace();
System.err.print1n("等待消息确认超时! message = " + message);
}
waitForConfirm方法有个重载的,可以自定义timeout超时时间,超时后会抛TimeoutException。类似的有几个waitForConfirmsOrDie方法,Broker端在返回nack(Basic.Nack)之后该方法会抛出java.io.lOException。需要根据异常类型来做区别处理理,TimeoutException超时是属于第三状态(无法确定成功还是失败),而返回Basic.Nack抛出IOException这种是明确的失败。上
面的代码主要只是演示confirm机制,实际上还是同步阻塞模式的,性能并不是太好。
实际上,我们也可以通过“批量处理”的方式来改善整体的性能(即批量发送消息后仅调用一次waitForConfirms方法)。正常情况下这种批量处理的方式效率会高很多,但是如果发生了超时或者nack (失败)后那就需要批量量重发消息或者通知,上游业务批量回滚(因为我们只知道这个批次中有消息没投递成功,而并不知道具体是那条消息投递失败了,所以很难针对性处理),如此看来,批量重发消息肯定会造成部分消息重复。另外,我们可以通过异步回调的方式来处理Broker的响应。
addConfirmListener方法可以添加ConfirmListener这个回调接口,这个ConfirmListener接口包含两个方法:handleAck和handleNack,分别用来处理RabbitMQ回传的Basic.Ack和Basic.Nack。
4 持久化存储机制
持久化是提高RabbitMQ可靠性的基础,否则当RabbitMQ遇到异常时(如:重启、断电、停机等)数据将会丢失。主要从以下几个方面来保障消息的持久性:
(1)Exchange的持久化。通过定义时设置durable参数为ture来保证Exchange相关的元数据不丢失。
(2)Queue的持久化。也是通过定义时设置durable参数为ture来保证Queue相关的元数据不丢失。
(3)消息的持久化。通过将消息的投递模式(BasicProperties中的deliveryMode属性)设置为2
即可实现消息的持久化,保证消息自身不丢失。
try (Connection connection = factory.newConnection();
Channel channel = connection.createChannel()) {
//交换器元数据持久化
channel.exchangeDeclare(EXCHANGE_NAME, BuiltinExchangeType.DIRECT, true);
//队列元数据的持久化
channel.queueDeclare(QUEUE_NAME, true, false, false, null);
String message =“";
for(int i = 0 ; i < 1000000 ; i++ ){
message = "Hello World! " + i;
AMQP.BasicProperties.Builder builder = new AMQP.BasicProperties.Builder();
builder.contentType("text/plain");
//消息持久化
builder.deliveryMode(2);
final AMQP.BasicProperties properties = builder.build();
//发送消息
channel.basicPublish(EXCHANGE_NAME, QUEUE_NAME, properties, message.getBytes());
}
RabbitMQ中的持久化消息都需要写入磁盘(当系统内存不足时,非持久化的消息也会被刷处
理),这些处理理动作都是在"持久层”中完成的。持久层是一个逻辑上的概念,实际包含两个部分:
(1)队列索引(rabbit _queue_index),rabbit_queue_index负责维护Queue中消息的信息,包括
消息的存储位置、是否已交给消费者、是否已被消费及Ack确认等,每个Queue都有与之对应的rabbit_queue_index。
(2)消息存储(rabbit_msg_store), rabbit_msg_store以键值对的形式存储消息,它被所有队列
共享,在每个节点中有且只有一个。
5 Consumer ACK
如何保证消息被消费者成功消费?
前面我们讲了生产者发送确认机制和消息的持久化存储机制,然而这依然无法完全保证整个过程的可靠性,因为如果消息被消费过程中业务处理失败了但是消息却已经出列了(被标记为已消费了),我们又没有任何重试,那结果跟消息丢失没什么分别。
RabbitMQ在消费端会有Ack机制,即消费端消费消息后需要发送Ack确认报文给Broker端,告知自己是否已消费完成,否则可能会一直重发消息直到消息过期(AUTO模式)。
这也是我们之前一直在讲的“最终一致性”、“可恢复性”的基础。
一般而言,我们有如下处理手段:
(1)采用NONE模式,消费的过程中自行捕获异常,引发异常后直接记录日志并落到异常恢复表,再通过后台定时任务扫描异常恢复表尝试做重试动作。如果业务不自行处理则有丢失数据的风险
(2)采用AUTO (自动Ack)模式,不主动捕获异常,当消费过程中出现异常时会将消息放回Queue中,然后消息会被重新分配到其他消费者节点(如果没有则还是选择当前节点)重新被消费,默认会一直重发消息并直到消费完成返回Ack或者一直到过期
(3)采用MANUAL (手动Ack)模式,消费者自行控制流程并手动调用channel相关的方法返回Ack
/**
* NONE模式,则只要收到消息后就立即确认(消息出列,标记已消费),有丢失数据的风险
* AUTO模式,看情况确认,如果此时消费者抛出异常则消息会返回到队列中
* MANUAL模式,需要显式的调用当前channel的basicAck方法
* @param channel
* @param deliveryTag
* @param message
*/
@RabbitListener(queues = "clair.topic.queue", ackMode = "AUTO")
pub1ic void handleMessageTopic(Channel channel,
@Header(AmqpHeaders.DELIVERY_TAG) long deliveryTag, @payload byte[] message) {
System.out.print1n("RabbitListener消费消息,消息内容:”+ new String((message)));
try {
// 手动ack,deliveryTag表示消息的唯一标志,multiple表示是否是批量确认
channel.basicAck(deliveryTag,false);
// 手动nack,告诉broker消费者处理失败,最后一个参数表示是否需要将消息重新入列
channel.basicNack(deliveryTag,false, true);
// 手动拒绝消息。第二个参数表示是否重新入列
channel.basicReject(deliveryTag, true);
} catch (IOException e) {
e.printStackTrace();
}
}
上面是通过在消费端直接配置指定ackMode,在一些比较老的spring项目中一般是通过xml方式去定义、声明和配置的,不管是XML还是注解,相关配置、属性这些其实都是大同小异,触类旁通。然后需要注意的是channel.basicAck这几个手工Ack确认的方法。
SpringBoot项目中支持如下的一些配置:
#最大重试次数
spring.rabbitmq.listener.simple.retry.max-attempts=5
#是否开启消费者重试(为false时关闭消费者重试,意思不是“不重试”,而是一直收到消息直到jack确认或者一直到超时)
spring.rabbitmq.1istener.simple.retry.enab1ed=true
#重试间隔时间(单位毫秒)
spring.rabbitmq.listener.simp1e.retry.initial-interval=5000
#重试超过最大次数后是否拒绝
spring.rabbitmq.listener.simple.default-requeue-rejected=false
#ack模式
spring.rabbitmq.listener.simple.acknowledge-mode=manual
6 消费端限流
在电商的秒杀活动中,活动一开始会有大量并发写请求到达服务端,需要对消息进行削峰处理,如何削峰?
当消息投递速度远快于消费速度时,随着时间积累就会出现"消息积压"。消息中间件本身是具备一定的缓冲能力的,但这个能力是有容量限制的,如果长期运行并没有任何处理,最终会导致Broker崩溃,而分布式系统的故障往往会发生上下游传递,连锁反应那就会很悲剧....
下面我将从多个角度介绍QoS.与限流,防止上面的悲剧发生。
(1)RabbitMQ可以对内存和磁盘使用量设置阈值,当达到阈值后,生产者将被阻塞(block),直到对应项指标恢复正常。全局上可以防止超大流量、消息积压等导致的Broker被压垮。当内存受限或磁盘可用空间受限的时候,服务器都会暂时阻止连接,服务器将暂停从发布消息的已连接客户端的套接字读取数据。连接心跳监视也将被禁用。所有网络连接将在rabbitmqct和管理插件中显示为"已阻止”,这意味着它们尚未尝试发布,因此可以继续或被阻止,这意味着它们已发布,现在已暂停。兼容的客户端被阻止时将收到通知。
(2)RabbitMQ还默认提供了一种基于credit flow的流控机制,面向每一个连接进行流控。 当单个队列达到最大流速时,或者多个队列达到总流速时,都会触发流控。触发单个链接的流控可能是因为connection、channel、 queue的某一个过程处于flow状态,这些状态都可以从监控平台看到。
(3)RabbitMQ中有一种QoS保证机制,可以限制Channel上接收到的未被Ack的消息数量,如果超过这个数量限制RabbitMQ将不会再往消费端推送消息。这是一种流控手段,可以防止大量消息瞬时从Broker送达消费端造成消费端巨大压力(甚至压垮消费端)。比较值得注意的是QoS机制仅对于消费端推模式有效,对拉模式无效。而且不支持NONE Ack模式。执行
channe1. basicConsume方法之前通过channe1.basicQoS方法可以设置该数量。消息的发送是异步的,消息的确认也是异步的。在消费者消费慢的时候,可以设置Qos的prefetchCount,它表示broker在向消费者发送消息的时候,一旦发送了prefetchCount个消息而没有一个消息确认的时候,就停止发送。消费者确认一个,broker就发送个,确认两个就发送两个。换句话说,消费者确认多少,broker就发送多少,消费者等待处理的个数永远限制在prefetchCount个。
如果对于每个消息都发送确认,增加了网络流量,此时可以批量确认消息。如果设置了multiple为true,消费者在确认的时候,比如说id是8的消息确认了,则在8之前的所有消息都确认了。
生产者往往是希望自己产生的消息能快速投递出去,而当消息投递太快且超过了下游的消费速度时就容易出现消息积压/堆积,所以,从上游来讲我们应该在生产端应用程序中也可以加入限流、应急开关等控制手段,避免超过Broker端的极限承载能力或者压垮下游消费者。
再看看下游,我们期望下游消费端能尽快消费完消息,而且还要防止瞬时大量消息压垮消费端(推模式),我们期望消费端处理速度是最快、最稳定而且还相对均匀(比较理想化)。
提升下游应用的吞吐量和缩短消费过程的耗时,优化主要以下几种方式:
(1)优化应用程序的性能,缩短响应时间(需要时间)
(2)增加消费者节点实例(成本增加,而且底层数据库操作这些也可能是瓶颈)
(3)调整并发消费的线程数(线程数并非越大越好,需要大量压测调优至合理值)
7 消息可靠性保障
(1)消息传输保障
(2)各种限流、应急手段
(3)业务层面的一些容错、补偿、异常重试等手段
消息可靠传输一般是业务系统接入消息中间件时首要考虑的问题,一般消息中间件的消息传输保障分为三个层级:
(1)At most once:最多一次。消息可能会丢失,但绝不会重复传输
(2)At least once:最少一次。消息绝不会丢失,但可能会重复传输
(3)Exactly once:恰好一次。每条消息肯定会被传输一次且仅传输一次
RabbitMQ支持其中的“最多一次"和”最少一次"。
其中"最少一次"投递实现需要考虑以下这个几个方面的内容:
(1)消息生产者需要开启事务机制或者publisher confirm机制以确保消息可以可靠地传输到RabbitMQ中。
(2)消息生产者需要配合使用mandatory参数或者备份交换器来确保消息能够从交换器路由到队列中,进而能够保存下来而不会被丢弃。
(3)消息和队列都需要进行持久化处理,以确保RabbitMQ服务器在遇到异常情况时不会造成消息丢失。
(4)消费者在消费消息的同时需要将autoAck设置为false,然后通过手动确认的方式去确认已经正确消费的消息,以避免在消费端引起不必要的消息丢失。
“最多一次”的方式就无须考虑以上那些方面,生产者随意发送,消费者随意消费,不过这样很难确保消息不会丢失。
“恰好一次”是RabbitMQ 目前无法保障的。
考虑这样一种情况,消费者在消费完一条消息之后向RabbitMQ 发送确认Basic.Ack命令,此时由于网络断开或者其他原因造成RabbitMQ并没有收到这个确认命令,那么RabbitMQ不会将此条消息标记删除。在重新建立连接之后,消费者还是会消费到这一条消息,这就造成了重复消费。
再考虑一种情况,生产者在使用publisher confirm机制的时候,发送完一条消息等待RabbitMQ返回确认通知,此时网络断开,生产者捕获到异常情况,为了确保消息可靠性选择重新发送,这样RabbitMQ中就有两条同样的消息,在消费的时候消费者就会重复消费。
8 消息幂等性处理
刚刚我们讲到,追求高性能就无法保证消息的顺序,而追求可靠性那么就可能产生重复消息,从而导致重复消费..真是应证了那句老话:做架构就是权衡取舍。
RabbitMQ层面有实现"去重机制"来保证"恰好一次"吗?答案是并没有。而且这个在目前主流的消息中间件都没有实现。
当为了在基础的分布式中间件中实现某种相对不太通用的功能,需要牺牲到性能、可靠性、扩展性时,并且会额外增加很多复杂度,最简单的办法就是交给业务自己去处理。事实证明,很多业务场景下是可以容忍重复消息的。例如:操作日志收集,而对一些金融类的业务则要求比较严苛。
一般解决重复消息的办法是,在消费端让我们消费消息的操作具备幂等性。
幂等性问题并不是消息系统独有,而是(分布式)系统中普遍存在的问题。例如:RPC框架调用超后会重试,HTTP请求会重复发起(用户手抖多点了几下按钮)
幂等(Idempotence)是一个数学上的概念,它是这样定义的:
如果一个函数f(x)满足:f{f(x)) = f(x),则函数f(x)满足幂等性。这个概念被拓展到计算机领域,被用来描述一个操作、方法或者服务。
一个幂等操作的特点是,其任意多次执行所产生的影响均与一次执行的影响相同。一个幂等的方法,使用同样的参数,对它进行多次调用和一次调用,对系统产生的影响是一样的。
对于幂等的方法,不用担心重复执行会对系统造成任何改变。
举个简单的例子(在不考虑并发问题的情况下) :
select * from xx where id=1
delete from xx where id=1
这两条sql语句就是天然幂等的,它本身的重复执行并不会引起什么改变。而update就要看情况的,
update XXX set amount = 100 where id =1
这条语句执行1次和100次都是一样的结果(最终余额都还是100) ,所以它是满足幂等性的。
update XXX set amount = amount + 100 where id =1
它就不满足幂等性的。
业界对于幂等性的一些常见做法:
(1)借助数据库唯一索引,重复插入直接报错事务回滚。还是举经典的转账的例子,为了保证不重复扣款或者重复加钱,我们这边维护一张“资金变动流水表”,里面至少需要交易单号、变动账户、变动金额等3个字段。我们选择交易单号和变动账户做联合唯一索引(单号是上游生成的可保证唯一性),这样如果同一笔交易发生重复请求时就会直接报索引冲突,事务直接回滚。现实中,数据库唯一索引的方式通常做为兜底保证;
(2)前置检查机制。这个很容易理解,并且有几种实现办法。还是引用上面转账的例子,当我在执行更改账户余额这个动作之前,我得先检查下资金娈动流水表(或者Tair中)中是否已经存在这笔交易相关的记录了,select * from xxx where accountNumber=xxx and orderId=yyy,如果已经存在,那么直接返回,否则执行正常的更新余额的动作。为了防止并发问题,我们通常需要借助“排他锁”来完成。在支付宝有一条铁律叫:一锁、二判、三操作。当然,我们也可以使用乐观锁或CAS机制,乐观锁-般会使用扩展一个版本号字段做判断条件
(3)唯一ld机制,比较通用的方式。对于每条消息我们都可以生成唯一ld,消费前判断Tair中是否存在(Msgld做Tair排他锁的key),消费成功后将状态写入Tair中,这样就可以防止重复消费了。
对于接口请求类的幂等性保证要相对更复杂,我们通常要求上游请求时传递一个类GUID的请求号(或TOKEN),如果我们发现已经存在了并且上一次请求处理结果是成功状态的(有时候上游的重试请求是正常诉求,我们不能将上一次异常/失败的处理结果返回或者直接提示"请求异常”,如果这样重试就变得没意义了)则不继续往下执行,直接返回"重复请求的提示和上次的处理结果(上游通常是由于请求超时等未知情况才发起重试的,所以直接返回上次请求的处理结果就好了)。如果请求ID都不存在或者上次处理结果是失败/异常的,那就继续处理流程,并最终记录最终的处理结果。这个请求序号由上游自己生成,上游通用需要根据请求参数、时间间隔等因子来生成请求ID。同样也需要利用这个请求ID做分布式锁的KEY实现排他。