HanLP分词+用户自定义词典
文章目录
- 1. 分词重要性
- 2. 词典说明
-
- 2.1 CustomDictionary
- 2.2 追加词典
- 2.3 词典格式
- 2.4 添加词典
- 3. 实验
-
- 3.1 未添加词典
- 3.2 加入词典后
- 4 其他深入实验
-
- 4.1 自定义词性
- 4.2 删除词典
- 4.3 删除词典和bin
前面谈到分词:
HanLP安装与使用-python版和java版
pynlpir中文分词+加载用户自定义词典
我比较喜欢用HanLP,它的粒度刚刚好。 pynlpir太细了,词全切开了。
1. 分词重要性
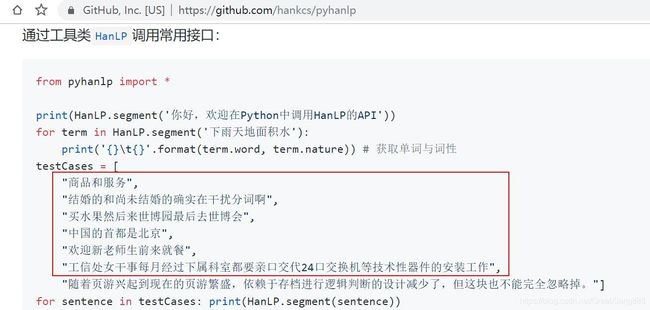

分错了可不好搞。
2. 词典说明
用户自定义词典 第8点。 - 1.x
2.1 CustomDictionary
- CustomDictionary 是一份全局的用户自定义词典,可以随时增删,影响全部分词器。
- 另外可以在任何分词器中关闭它。通过代码动态增删不会保存到词典文件。
- 中文分词≠词典,词典无法解决中文分词,Segment提供高低优先级应对不同场景,可参考 为什么修改了词典还是没有效果? - FAQ
- 代码动态添加词典方法:demo_custom_dictionary.py - github
2.2 追加词典
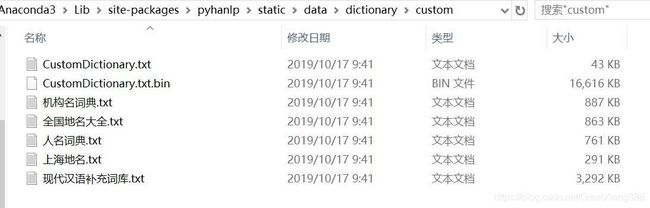
- CustomDictionary主词典文本路径是
data/dictionary/custom/CustomDictionary.txt,用户可以在此增加自己的词语(不推荐)
我的文件位置是C:\Users\ASUS\Anaconda3\Lib\site-packages\pyhanlp\static\data\dictionary\custom,如图:
- 也可以单独新建一个文本文件,通过配置文件
CustomDictionaryPath=data/dictionary/custom/CustomDictionary.txt; 我的词典.txt;来追加词典(推荐)。 - 始终建议将相同词性的词语放到同一个词典文件里,便于维护和分享。
2.3 词典格式
- 每一行代表一个单词,格式遵从
[单词] [词性A] [A的频次] [词性B] [B的频次] ...如果不填词性则表示采用词典的默认词性。 - 词典的默认词性默认是名词n,可以通过配置文件修改:
全国地名大全.txt ns;如果词典路径后面空格紧接着词性,则该词典默认是该词性。 - 在统计分词中,并不保证自定义词典中的词一定被切分出来。用户可在理解后果的情况下通过
Segment#enableCustomDictionaryForcing强制生效。 - 关于用户词典的更多信息请参考词典说明一章。 词典说明 - 词典说明
字典样例:
万死 a 2 v 1
三冬 n 1
三天两头儿 nz 1
三星堆遗址 n 1
三键 a 1 n 1
上口字 n 1
所有词典统一使用UTF-8编码
2.4 添加词典
参考:hanlp用户自定义词典添加
-
打开
C:\Users\ASUS\Anaconda3\Lib\site-packages\pyhanlp\static\hanlp.properties文件,找到第20~21行:#另外data/dictionary/custom/CustomDictionary.txt是个高质量的词库,请不要删除。所有词典统一使用UTF-8编码。 CustomDictionaryPath=data/dictionary/custom/CustomDictionary.txt; 现代汉语补充词库.txt; 全国地名大全.txt ns; 人名词典.txt; 机构名词典.txt; 上海地名.txt ns;data/dictionary/person/nrf.txt nrf;并添加字典。如下:
CustomDictionaryPath=data/dictionary/custom/CustomDictionary.txt; my_dict.txt; 现代汉语补充词库.txt; 全国地名大全.txt ns; 人名词典.txt; 机构名词典.txt; 上海地名.txt ns;data/dictionary/person/nrf.txt nrf; -
在
C:\Users\ASUS\Anaconda3\Lib\site-packages\pyhanlp\static\data\dictionary\custom目录下,添加文件my_dict.txt。 -
输入如下:保存。
疏水性 a 10
3. 实验
3.1 未添加词典
代码:
def pyhanlpSplit():
sent = '分别以疏水性氨基酸色氨酸、苯丙氨酸、缬氨酸、丙氨酸、亮氨酸和异亮氨酸来替换X位置。'
from pyhanlp import HanLP
res = HanLP.segment(sent)
print(res)
结果:
[分别/d, 以/p, 疏水/nz, 性/ng, 氨基酸/n, 色氨酸/nmc, 、/w, 苯丙氨酸/nmc, 、/w, 缬氨酸/nmc, 、/w, 丙氨酸/nmc, 、/w, 亮氨酸/gb, 和/cc, 异亮氨酸/nmc, 来/vf, 替换/v, X/nx, 位置/n, 。/w]
我们想将 “疏水性” 作为一个词语来切分。
3.2 加入词典后
添加过程可参考 2.4 添加词典。
结果如下:
[分别/d, 以/p, 疏水性/a, 氨基酸/n, 色氨酸/nmc, 、/w, 苯丙氨酸/nmc, 、/w, 缬氨酸/nmc, 、/w, 丙氨酸/nmc, 、/w, 亮氨酸/gb, 和/cc, 异亮氨酸/nmc, 来/vf, 替换/v, X/nx, 位置/n, 。/w]
可以看到,“疏水性”作为一个词语,成功。
4 其他深入实验
4.1 自定义词性
如果词性为词典没有出现过的词性呢?会正确识别吗?
会。
-
例如,词典:
疏水性 ph 10结果:
[分别/d, 以/p, 疏水性/ph, 氨基酸/n, 色氨酸/nmc, 、/w, 苯丙氨酸/nmc, 、/w, 缬氨酸/nmc, 、/w, 丙氨酸/nmc, 、/w, 亮氨酸/gb, 和/cc, 异亮氨酸/nmc, 来/vf, 替换/v, X/nx, 位置/n, 。/w] -
再如:
疏水性 entityph 10结果:
[分别/d, 以/p, 疏水性/entityph, 氨基酸/n, 色氨酸/nmc, 、/w, 苯丙氨酸/nmc, 、/w, 缬氨酸/nmc, 、/w, 丙氨酸/nmc, 、/w, 亮氨酸/gb, 和/cc, 异亮氨酸/nmc, 来/vf, 替换/v, X/nx, 位置/n, 。/w]
很棒。
4.2 删除词典
在3.2基础完成后,我将词典文件删除,发现结果并未变化,还是将“疏水性”作为一个词语。
笔者猜想,hanlp已经将词典内容写入到C:\Users\ASUS\Anaconda3\Lib\site-packages\pyhanlp\static\data\dictionary\custom\CustomDictionary.txt.bin中了。
4.3 删除词典和bin
为了证实猜想,笔者同时将CustomDictionary.txt.bin和my_dict.txt删除,再次运行代码。
此时运行结果为:
一月 14, 2020 1:27:41 下午 com.hankcs.hanlp.dictionary.CustomDictionary load
严重: 自定义词典c:/users/asus/anaconda3/lib/site-packages/pyhanlp/static/data/dictionary/custom/my_dict.txt读取错误!java.io.FileNotFoundException: c:\users\asus\anaconda3\lib\site-packages\pyhanlp\static\data\dictionary\custom\my_dict.txt (系统找不到指定的文件。)
一月 14, 2020 1:27:41 下午 com.hankcs.hanlp.dictionary.CustomDictionary loadMainDictionary
警告: 失败:c:/users/asus/anaconda3/lib/site-packages/pyhanlp/static/data/dictionary/custom/my_dict.txt
[分别/d, 以/p, 疏水/nz, 性/ng, 氨基酸/n, 色氨酸/nmc, 、/w, 苯丙氨酸/nmc, 、/w, 缬氨酸/nmc, 、/w, 丙氨酸/nmc, 、/w, 亮氨酸/gb, 和/cc, 异亮氨酸/nmc, 来/vf,
替换/v, X/nx, 位置/n, 。/w]
疏水、性 又分为了两个词。并且又产生了CustomDictionary.txt.bin文件,由此说明笔者猜想正确。
运行过程:
先加载词典文件,产生bin文件(只加不减)。
再通过bin文件和切词原理进行切词。
完成,完美,鼓掌。
b站讲解:https://www.bilibili.com/video/av83440716/