引言
随着网络应用的不断发展,在linux系统中对应用层网络管控的需求也日益增加,而传统的iptables、firewalld等工具难以针对应用层进行网络管控。因此需要一种创新的解决方案来提升网络应用的可管理性。
本文将探讨如何使用eBPF技术构建一种应用层网络管控解决方案,为linux系统上的网络管控带来一种新的可能。
相关技术介绍
eBPF
eBPF(Extended Berkeley Packet Filter)是一种在Linux内核中执行安全、可编程的字节码的技术。它最初是作为传统的Berkeley Packet Filter(BPF)的扩展而引入的,用于网络数据包过滤和分析。然而,随着时间的推移,eBPF已经演变成一种通用的可编程框架,不仅可以用于网络管控,还可以应用于系统跟踪、安全监控、性能分析等领域。
eBPF具有灵活性和可扩展性,通过编写自定义的eBPF程序,开发人员可以根据特定的需求实现各种功能。同时,eBPF还支持动态加载和卸载,使得运行时可以根据需要加载不同的eBPF程序,而无需重新编译内核。
eBPF的另一个重要特点,那就是它的安全性。eBPF的字节码在内核中执行之前,会经过严格的验证和限制,以确保它不会对系统的稳定性和安全性造成破坏。这种安全性保证了BPF的可编程性不会成为潜在的安全漏洞。
由于eBPF的这些特性,使其成为现在Linux系统上最炙手可热的一项技术。例如,开源容器网络方案Cilium、开源Linux动态跟踪程序BCC、熟知的bpftrace等,都是基于eBPF技术实现的。换句话说,通过对eBPF字节码进行验证和限制,系统能够保持稳定和安全,同时还能实现BPF的灵活编程能力。
下图展示了eBPF所支持的所有追踪点,可以发现eBPF可以探测几乎所有的子系统:

KProbes
Kprobes是Linux内核中的一种动态跟踪机制,它允许用户在内核的关键代码路径上插入探针,以便在运行时捕获和分析内核事件。Kprobes可以在内核函数的入口和出口处插入探针,以便观察函数的调用和返回情况。通过在关键代码路径上插入探针,就可以收集各种内核事件的信息,如函数调用次数、参数值、返回值等。
eBPF程序可由Kprobes事件驱动,eBPF与Kprobes的结合可以实现内核级别的事件跟踪和分析。
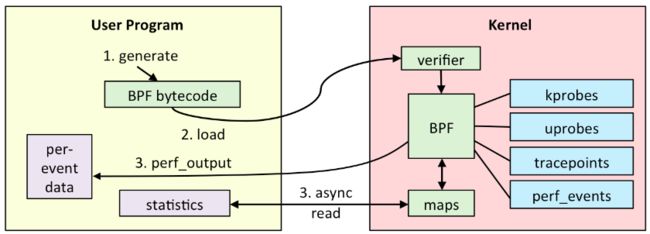
eBPF Maps
eBPF Maps是一种键值对数据结构,类似于传统编程语言中的字典或哈希表。它由键(key)和值(value)组成,程序员可以根据需要定义键和值的类型,并在eBPF程序中进行读取、写入和更新操作。它可以在用户空间和内核空间之间进行安全的数据传输,避免了传统用户空间和内核空间之间的数据拷贝和安全隐患。

NFQUEUE
NFQUEUE利用Netfilter框架中的hook机制,将选定的网络数据包从内核空间传递到用户空间进行处理。具体的工作流程如下:
配置规则:使用iptables或nftables等工具配置规则,将特定的网络流量匹配到NFQUEUE。
注册队列:在用户态程序中,通过libnetfilter_queue库注册一个NFQUEUE队列,并指定一个唯一的队列ID。
数据包传递:当匹配到与规则相符的网络数据包时,内核将其放入相应的NFQUEUE队列,并将队列ID与网络数据包相关联。
用户态处理:用户态程序通过监听注册的NFQUEUE队列,可以接收到内核传递的网络数据包。程序可以对网络数据包进行处理、修改、过滤或记录等操作。
决策:在用户态处理完网络数据包后,可以根据需要决定是否接受、丢弃、修改或重定向网络数据包。

有固应用层网络管控实现
上面介绍了eBPF和NFQUEUE的基本概念,可以发现,eBPF和NFQUEUE都可以将内核中网络协议栈的网络数据包转发到用户态,下面说明在UOS系统有固中网络管控方案的具体实现步骤:
使用iptables配置NFQUEUE规则,将系统中的网络数据包转发到NFQUEUE队列,用户态程序从队列中获取数据包,并对这些数据包进行研判,是ACCEPT 还是DROP。但是NFQUEUE队列中的数据包并不包含应用层信息,无法针对应用层信息进行研判,那么就需要将每个网络数据包与具体的应用关联起来。
通过eBPF程序在内核网络协议栈相关函数的入口和出口处插入Kprobes探针,这里将hook点设为tcp_v4_connect、tcp_v6_connect、security_socket_sendmsg。
每当系统中有网络流量产生的时候,就可以截获其中的网络数据包送入eBPF程序处理。eBPF程序同时可以获取此时的进程ID(PID),并将PID与数据包进行绑定,在之后处理数据包的时候就可以清晰的知道每个数据包是由哪个进程产生的了。通过eBPF Maps将绑定好PID的网络流量包送入用户空间,至此,eBPF程序完成了它的一次任务。当然,对于监控的每个数据包,eBPF程序都需要进行一次这样的处理。
在用户空间中,通过PID可以获取到进程的相关信息,例如启动时间、文件路径、进程状态等,将这些信息收集起来保存供后续使用。
用户态程序通过数据包的 IP、端口、协议类型等信息将NFQUEUE队列中的数据包与eBPF模块捕获的数据包关联起来,这样就知道NFQUEUE队列中每个数据包对应的进程信息。
将NFQUEUE队列中的数据包送入规则引擎,对比配置好的流量规则,对数据包作出研判。

优势
传统的linux网络管控方案如iptables、firewalld等都只能工作在网络层和传输层,而该网络方案可以将网络管控扩展到应用层。对比firewalld的XML模版,该方案在真正意义上实现了对应用层的网络管控。
规则配置、网络管控方式更加灵活,该方案可以针对单个应用进行规则配置,由于最后的处理过程是在应用态,而非内核中的netfilter,所以可以实现定制化的管控方式。
不足
由于NFQUEUE会将数据包转发到用户态处理,这牺牲了一部分的性能。
在linux的网络协议栈中,并非所有的网络流量都可以通过eBPF获取到对应的进程信息,当前测试比较稳定的是应用程序的出口流量。
展望
eBPF是一项创新且强大技术,在过去的 eBPF summit 2022中,《The future of eBPF in the Linux Kernel》展望了 eBPF 的发展方向,其中包括:
更完备的编程能力:当前 eBPF 的编程能力存在一些局限性(比如不支持变量边界的循环,指令数量受限等),演进目标提供图灵完备的编程能力。
更强的安全性:支持类型安全,增强运行时 Verifier,演进目标是提供媲美 Rust 的安全编程能力。
更广泛的移植能力:增强 CO-RE,加强 Helper 接口可移植能力,实现跨体系、平台的移植能力。
更强的可编程能力:支持访问/修改内核任意参数、返回值,实现更强的内核编程能力。
结合以上eBPF即将会实现的新特性,应用层的网络管控可以在eBPF模块中直接实现,这样一来在降低性能开销的同时,也提升了网络管控的灵活性。未来,可以期待更多基于eBPF的应用层网络管控方案出现,用于实现强大的应用层流量分析、智能的流量调度、自动化的安全防御和灵活的网络管控。这将为网络管理人员和开发人员提供更多的工具和技术,以应对不断增长的网络挑战和需求。