大家好,我是小菜,前面几篇文章我们已经从 k8s 集群的搭建然后到 k8s 中NameSpace 再说到了 k8s 中 Pod 的使用,如果还干到意犹未尽,那么接下来的 Pod 控制器 同样是一道硬菜!
死鬼~看完记得给我来个三连哦!

本文主要介绍
k8s中pod控制器的使用如有需要,可以参考
如有帮助,不忘 点赞 ❥
微信公众号已开启,小菜良记,没关注的同学们记得关注哦!
前文回顾:
既然有 pod 的存在,那便需要对pod 进行管理,控制器又怎么了少的了,那么接下来的时间交给小菜,带你一探到底!
Pod控制器
一、前头预热
我们已经清楚了Pod是 k8s 中最小的管理单元。想想我们之前是怎么创建 pod,动动小脑袋,隐约想起好像有3种方式!1. 命令式对象管理 2. 命令式对象配置 3. 声明式对象配置 。 如果能想到这三种,说明上篇没白学!但是这三种的创建方式,我们都是围绕 pod 展开的,不管是通过命令直接创建,还是通过 yaml文件配置完再生成,我们生成的 Kind 都是直接指明 Pod,仿佛我们对 pod 的认知也局限于此了。但是今天,小菜就带你认识点不一样的东西,我们可以通过 Pod管理器 来创建 pod!
1)概念
什么是 pod 控制器呢?上面只是简单说了可以用来创建 pod,难道作用也仅此而已,那我何必又多此一举呢~
Pod 控制器,意如其名。就是用来控制 pod的,它是作为管理 pod 的中间层,使用 pod 控制器之后,只需要告诉 pod 控制器,我想要几个pod,想要什么样的pod,它便会为我们创建出满足条件的 pod,并确保每一个 pod 资源都是处于用户期望的目标状态,如果 pod 资源在运行中出现故障,它便会基于指定的策略重新编排 pod
相当于控制器也就是一个管家,可以更好的为我们管理 pod。
通过 pod 控制器创建的 pod还有个最大的不同点,那便是:如果通过直接创建出来的 pod,这种 pod 删除后也就真的删除了,不会重建。而通过 pod 控制器创建的pod,删除后还会基于指定的策略重新创建!
pod控制器 也分为很多种类型,k8s 中支持的控制器类型如下:
- ReplicaSet:保证副本数量一致维持在期望值,支持 pod 数量扩缩容 和 镜像版本升级
- Deployment: 通过控制 ReplicaSet 来控制 Pod,支持滚动升级和回退版本
- Horizontal Pod Autoscaler:可以根据集群负载自动水平调整 pod 的数量
- DaemonSet: 在集群中的指定 Node 上运行且仅运行一个副本,一般用于守护进程类的任务
- Job:它创建出来的pod只要完成任务就会立即退出,不需要重启或重建,用于执行一次性任务
- Cronjob: 它创建的pod负责周期性任务控制,不需要持续后台运行
- StatefulSet: 管理有状态的应用
这么多控制器,看了也别慌,接下来我们一个个认识过去~
二、实际操作
1)ReplicaSet
ReplicaSet 简称 rs,它的主要作用便是保证一定数量的 pod 正常运行,它会持续监听这些pod的运行状态,一旦 pod 发生故障,就会重启或重建,同时它还支持对 pod 数量的扩缩容和镜像版本的升降级。
我们来看下 RS 的资源清单:
apiVersion: apps/v1 # 版本号
kind: ReplicaSet # 类型
metadata: # 元数据信息
name: # 名称
namespace: # 命名空间
labels: # 标签
key: value
spec: # 详细描述
replicas: # 副本数
selector: # 选择器,通过它指定该控制器管理那些Pod
matchLabels: # labels 匹配规则
app:
matchExpressions:
- key: xxx
operator: xxx
values: ['xxx', 'xxx']
template: # 模板,当副本数量不足时,会根据以下模板创建Pod副本
metadata:
labels:
key: value
spec:
containers:
- name:
image:
ports:
- containerPort: 我们这里需要新了解的属性如下:
- spec.replicas: 副本数量。当前 rs 会创建出来的 pod 数量,默认为 1
- spec.selector: 选择器。建立 pod 控制器和 pod 之间的关联关系,在 pod 模板上定义 label,在控制器上定义选择器,就可以让pod归属于哪个控制器底下
- spec.template: 模板。当前控制器创建 pod 所使用的的模板,里面定义内容与上节说到的 pod 定义是一样的
创建RS
我们编写一个 yaml 试着创建一个 RS 控制器:

通过 kubectl create -f rs.yaml 后可以发现已经存在了两个pod,说明副本数量生效,当我们删除一个 pod,过一会便会自动启动一个 pod!
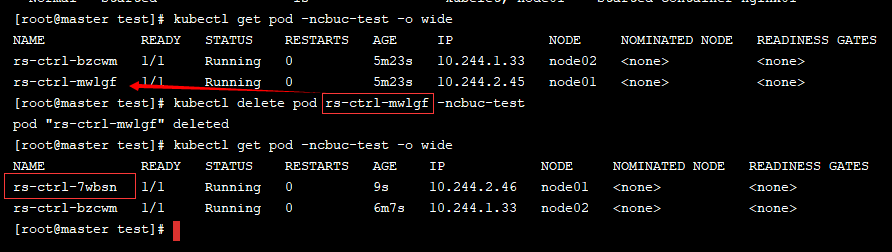
扩缩容
既然 RS 创建的时候能控制 pod 的副本数量,当然在运行的时候也能够动态扩缩容。
直接修改
我们通过以下命令,能够直接编辑 rs 的yaml文件
kubectl edit rs rs-ctrl -n cbuc-test将 replicas 数量改为 3,保存退出后,可以发现正在运行的pod 数量已经变成了 3 个。
命令修改
除了以上通过修改yaml的方式,我们也可以直接通过命令的方式修改
kubectl scale rs rs-ctrl --replicas=2 -n cbcu-test以上命令我们是借助 scale 指令的帮助修改 pod 的副本数量。
镜像更新
除了可以控制副本数量,还可以进行镜像的升级。我们上面运行Pod使用的镜像是 nginx:1.14.1 如果我们想要升级镜像版本号同样有两种方法:
直接修改
我们通过以下命令,能够直接编辑 rs 的yaml文件
kubectl edit rs rs-ctrl -n cbuc-test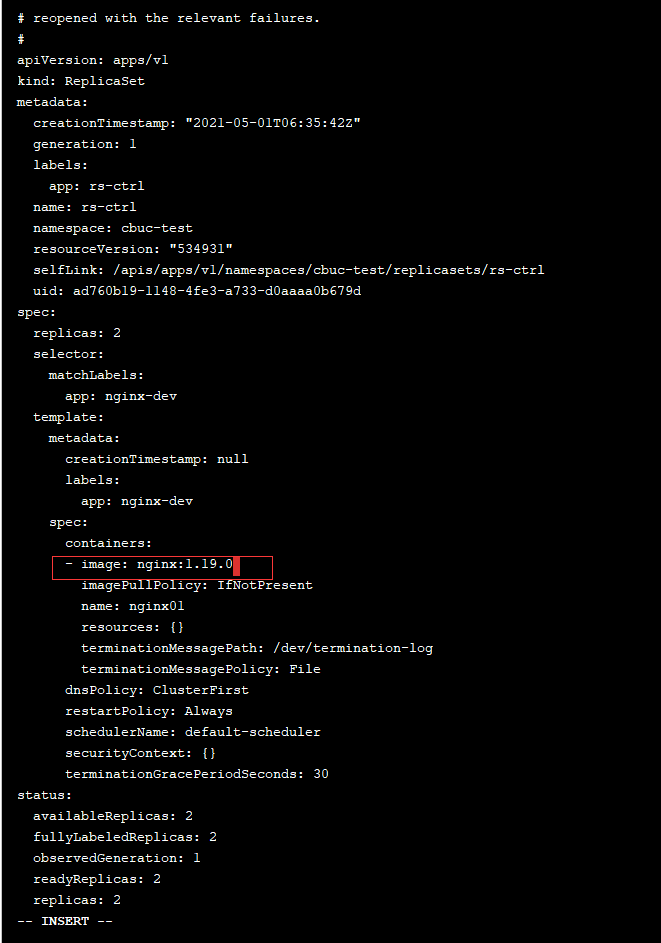
编辑镜像版本号后保存退出,可以发现正在运行的pod使用的镜像已经变了

命令修改
处理以上通过修改yaml的方式,我们也可以直接通过命令的方式修改
kubectl set image rs rs-ctrl nginx=nginx:1.17.1 -n cbuc-test格式如下:
kubectl set image rs 控制器名称 容器名称=镜像名称:镜像版本 -n 命名空间删除镜像
如果我们不想要使用该控制器了,最好的方式便是将其删除。我们可以根据资源清单删除
kubectl delete -f rs.yaml也可以直接删除
kubectl delete deploy rs-ctrl -ncbuc-test但是我们需要清楚的是,默认情况下,控制器删除后,底下所控制的pod也会对应删除,但是有时候我们只是想单纯的删除控制器,而不想删除pod,就得借助命令选项--cascade=false
kubectl delete rs rs-ctrl -n cbuc-test --cascade=false2)Deployment
Deployment 控制器简称 Deploy,这个控制器是在kubernetes v1.2版本之后开始引入的。这种控制器并不是直接管理 pod,而是通过管理 ReplicaSet 控制器 来间接管理 pod
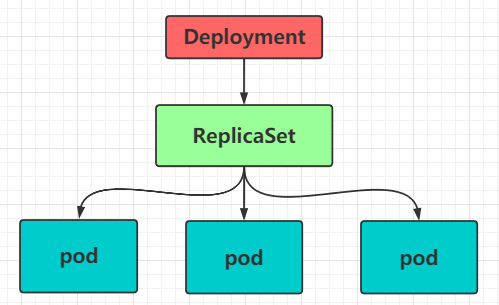
由图可知,Deployment的功能只会更加强大:
- 支持 ReplicaSet 所有功能
- 支持发布的停止、继续
- 支持滚动升级和回滚版本
三大利器,将开发拿捏死死地~我们来看下资源清单是如何配置的:
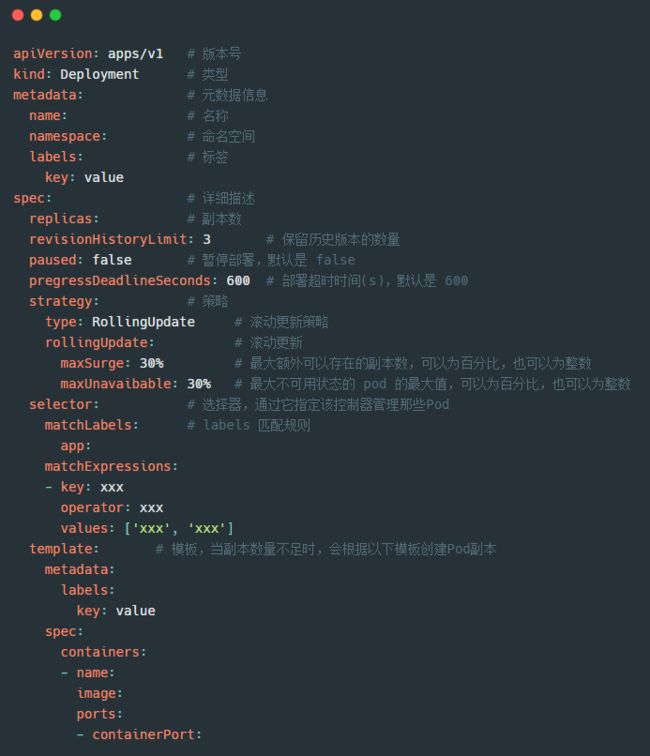
从资源清单中我们可以看出,ReplicaSet 中有的,Deployment 都有,而且还增加了许多属性
创建Deploy
准备一份 deploy 资源清单:
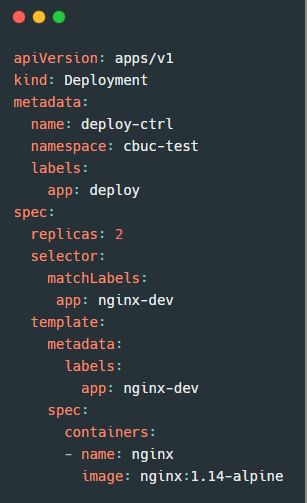
然后通过 kubectl create -f deploy-ctrl.yaml 创建pod控制器,查看结果:

扩缩容
扩缩容的方式和 ReplicaSet 一样,有两种方式,这里简单带过
直接修改
kubectl edit deploy deploy-ctrl -n cbuc-test将 replicas 数量改为 3,保存退出后,可以发现正在运行的pod 数量已经变成了 3 个。
命令修改
kubectl scale deploy deploy-ctrll --replicas=2 -n cbcu-test镜像更新
Deployment支持两种更新策略: 重建更新和滚动更新 ,可以通过 strategy 指定策略类型,支持两个属性:
strategy: # 指定新的Pod替换旧的Pod的策略, 支持两个属性:
type: # 指定策略类型,支持两种策略
Recreate: # 在创建出新的Pod之前会先杀掉所有已存在的Pod
RollingUpdate: # 滚动更新,就是杀死一部分,就启动一部分,在更新过程中,存在两个版本Pod
rollingUpdate: # 当type为RollingUpdate时生效,用于为RollingUpdate设置参数,支持两个属性
maxUnavailable: # 用来指定在升级过程中不可用Pod的最大数量,默认为25%。
maxSurge: # 用来指定在升级过程中可以超过期望的Pod的最大数量,默认为25%。正常来说 滚动更新 会比较友好,在更新过程中更加趋向于“无感”更新
版本回退
Deployment 还支持版本升级过程中的暂停、继续以及版本回退等诸多功能,这些都与rollout有关:
使用方式:

- history
显示升级历史记录
kubectl rollout history deploy deploy-ctrl -ncbuc-test
- pause
暂停版本升级过程
kubectl rollout pause deploy deploy-ctrl -ncbuc-test- restart
重启版本升级过程
kubectl rollout restart deploy deploy-ctrl -ncbuc-test- resume
继续已经暂停的版本升级过程
kubectl rollout resume deploy deploy-ctrl -ncbuc-test- status
显示当前升级状态
kubectl rollout status deploy deploy-ctrl -ncbuc-test- undo
回滚到上一级版本
kubectl rollout undo deploy deploy-ctrl -ncbuc-test
3)Horizontal Pod Autoscaler
看名字就感觉这个不简单,该控制器简称 HPA ,我们之前是手动控制 pod 的扩容或缩容,但是这中方式并不智能,我们需要随时随地观察资源状态,然后控制副本数量,这是一个相当费时费力的工作~ 因此我们想要能够存在一种能够自动控制 Pod 数量的控制器来帮助我们监测 pod 的使用情况,实现 pod 数量的自动调整。而 K8s 也为我们提供了 Horizontal Pod Autoscaler - HPA
HPA 可以获取每个 pod 的利用率, 然后和 HPS 中定义的指标进行对比,同时计算出需要伸缩的具体数量,然后对 pod 进行调整。
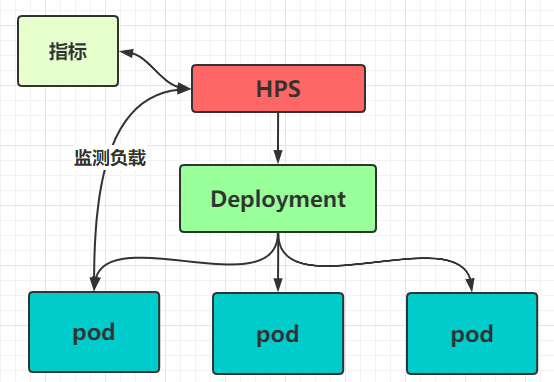
如果需要监测 pod 的负载情况,我们需要 metrics-server 的帮助,因此我们首先需要先安装 metrics-server
# 安装git
yum install -y git
# 获取mertrics-server
git clone -b v0.3.6 https://github.com/kubernetes-incubator/metrics-server
# 修改metrics-server deploy
vim /root/metrics-server/deploy/1.8+/metrics-server-deployment.yaml
# 添加下面选项
hostNetwork: true
image: registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server-amd64:v0.3.6
args:
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP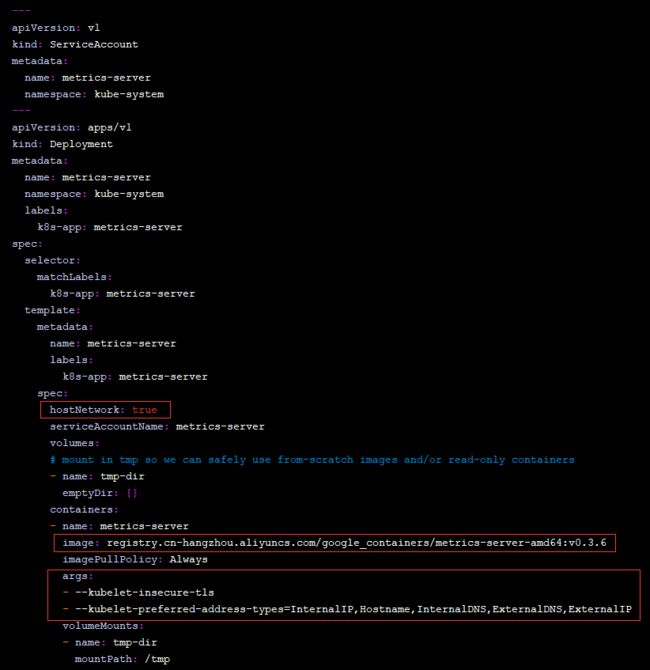
然后直接创建即可:
kubectl apply -f /root/metrics-server/deploy/1.8+/安装结束后我们便可以使用以下命令查看每个node的资源使用情况了
kubectl top node
查看pod资源使用情况
kubectl top pod -n cbuc-test
然后我们便可以创建 HPA,准备好资源清单:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: hpa-ctrl
namespace: cbuc-test
spec:
minReplicas: 1 # 最小Pod数量
maxReplicas: 5 # 最大Pod数量
targetCPUUtilzationPercentage: 3 # CPU使用率指标
scaleTargetRef: # 指定要控制 deploy 的信息
apiVersion: apps/v1
kind: Deployment
name: deploy-ctrl# 创建hpa
[root@master /]# kubectl create -f hpa-deploy.yaml
# 查看hpa
[root@master /]# kubectl get hpa -n dev到这里我们就创建好了一个 HPA,它可以动态对 pod 进行扩缩容,这里就不做测试了,有兴趣的同学可以进行压测,看看结果是否如自己所期望的~
4)DaemonSet
DaemonSet 控制器简称 DS ,它的作用便是可以保证在集群中的每一台(或指定)节点上都运行一个副本。这个作用场景一般是用来做日志采集或节点监控。
如果一个Pod提供的功能是节点级别的(每个节点都需要且只需要一个),那么这类Pod就适合使用 DaemonSet 类型的控制器创建
特点:
- 每向集群添加一个节点时,指定的 Pod 副本也将会被添加到该节点上
- 当节点从集群中移除时,Pod 也将被回收
资源清单模板:

其实不难发现,该清单跟 Deployment 几乎一致,因此我们不妨大胆猜测,这个控制器就是针对 Deployment 改良的懒人工具,可以自动帮我们创建Pod~
实战清单:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: pc-daemonset
namespace: dev
spec:
selector:
matchLabels:
app: nginx-pod
template:
metadata:
labels:
app: nginx-pod
spec:
containers:
- name: nginx
image: nginx:1.14-alpine通过该清单创建后,我们可以发现在每个 Node 节点上都创建了 nginx pod~

5)Job
Job,意如其名,该控制器的任务便是 负责批量处理(一次要处理指定数量任务)短暂的一次性(每个任务仅运行一次就结束)的任务。
特点:
- 当Job创建的Pod执行成功结束时,Job会记录成功结束的pod数量
- 当成功结束的pod达到指定的数量时,Job将完成执行
资源清单模板:

这里重启策略是必须指明的,且只能为 Never 或 OnFailure,原因如下:
- 如果指定为OnFailure,则job会在pod出现故障时重启容器,而不是创建pod,failed次数不变
- 如果指定为Never,则job会在pod出现故障时创建新的pod,并且故障pod不会消失,也不会重启,failed次数加1
- 如果指定为Always的话,就意味着一直重启,意味着job任务会重复去执行了,当然不对,所以不能设置为
Always
实战清单:
apiVersion: batch/v1
kind: Job
metadata:
name: job-ctrl
namespace: cbuc-test
labels:
app: job-ctrl
spec:
manualSelector: true
selector:
matchLabels:
app: job-pod
template:
metadata:
labels:
app: job-pod
spec:
restartPolicy: Never
containers:
- name: test-pod
image: cbuc/test/java:v1.0
command: ["bin/sh","-c","for i in 9 8 7 6 5 4 3 2 1; do echo $i;sleep 2;done"]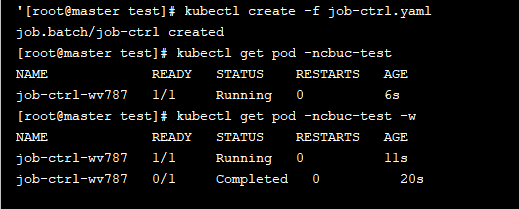
通过观察pod状态可以看到,pod在运行完毕任务后,就会变成Completed状态
6)CronJob
CronJob控制器简称 CJ,它的作用是以 Job 控制器为管理单位,借助它管理 pod 资源对象。Job 控制器定义的任务在创建时便会立刻执行,但 cronJob 控制器可以控制其运行的 时间点及 重复运行 的方式。
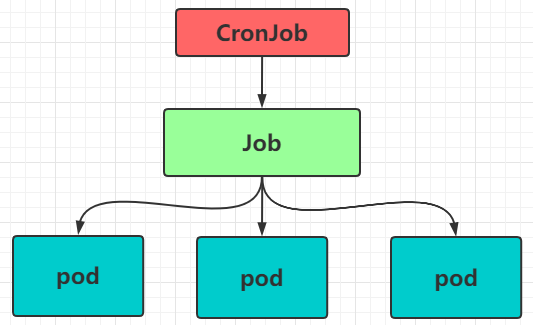
资源清单模板:
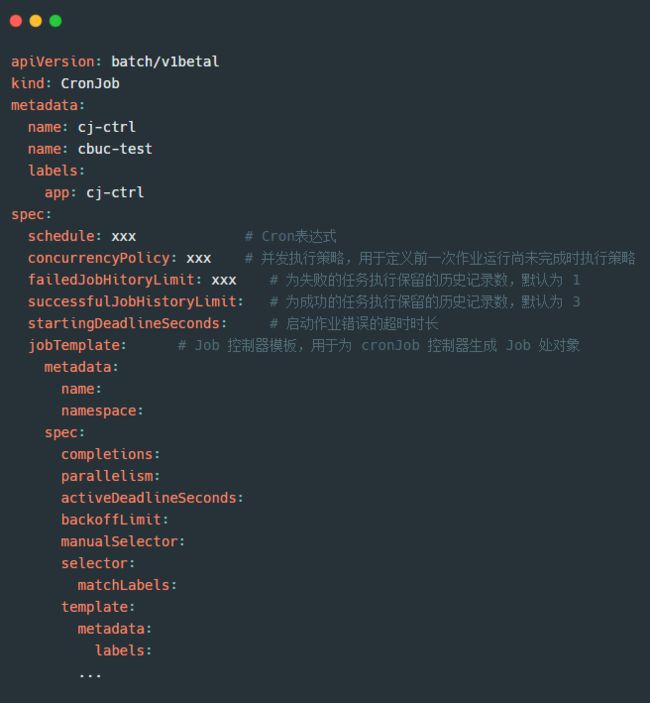
其中 并发执行策略 有以下几种:
- Allow: 允许 Jobs 并发运行
- Forbid: 禁止并发运行,如果上一次运行尚未完成,则跳过下一次运行
- Replace: 替换,取消当前正在运行的作业并用新作业替换它
实战清单:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: cj-ctrl
namespace: cbuc-test
labels:
controller: cronjob
spec:
schedule: "*/1 * * * *"
jobTemplate:
metadata:
spec:
template:
spec:
restartPolicy: Never
containers:
- name: test
image: cbuc/test/java:v1.0
command: ["bin/sh","-c","for i in 9 8 7 6 5 4 3 2 1; do echo $i;sleep3;done"]
从结果上看我们也已经成功实现了定时任务,每秒执行了一次~
END
这篇我们介绍了 Pod 控制器的使用,一共有 6种控制器,不知道看完后,你还记住几种呢~老样子,实践出真知,凡事还是要上手练习才能记得更牢哦~ K8s 仍未结束,我们还有 Service、Ingress和 Volumn 还没介绍!路漫漫,小菜与你一同求索~

今天的你多努力一点,明天的你就能少说一句求人的话!
我是小菜,一个和你一起学习的男人。
微信公众号已开启,小菜良记,没关注的同学们记得关注哦!