MySQL--复合查询--内外链接--0422
注:为了方便查看 mysql语句会有突然的换行,书写时请勿模仿。
目录
1.单表查询回顾
显示工资最高的员工的名字和工作岗位
显示工资高于平均工资的员工信息
2.多表查询
比如需要查询雇员名字和所在部门编号及部门名字。
显示部门号为10的部门名,员工名和工资
显示各个员工的姓名,工资,及工资级别
2.2 多表查询总结
3.自连接
显示员工ford的上级领导的编号和姓名
4. 子查询
4.1 单行子查询
显示SMITH同一部门的员工
4.2 多行子查询
查询和10号部门的工作岗位相同的雇员的名字,岗位,工资,部门号,但是不包含10自己的
显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号
4.3 多列子查询
查询和SMITH的部门和岗位完全相同的所有雇员,不含SMITH本人
4.4 在from子句中使用子查询
显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资
查找每个部门工资最高的人的姓名、工资、部门、最高工资
4.5 合并查询
将工资大于2500或职位是MANAGER的人找出来
1.单表查询回顾
显示工资最高的员工的名字和工作岗位
可以使用如下语句吗?
select ename,max(sal) from emp;max(sal)是聚合函数,把整个表当做一个数据来看,但是ename不能将整个表当做一个数据,所以会出现错误。但是如果select筛选的表结构是max(sal)显示出来的表,那么就不会再有错误了。所以用过两条语句也可以达成目的。
select max(sal) from emp;
select ename,job from emp where sal=5000; -->5000就是表里面最大值select是支持嵌套的
select ename, job from EMP where sal = (select max(sal) from EMP);有一条select语句的结果被当做某条select的条件,这条select语句称为子查询。执行顺序类似递归。注意子查询设置的别名,在主查询中依然看不到!
显示工资高于平均工资的员工信息
mysql> select ename,job from emp where sal>(select avg(sal) from emp);
+-------+-----------+
| ename | job |
+-------+-----------+
| JONES | MANAGER |
| BLAKE | MANAGER |
| CLARK | MANAGER |
| SCOTT | ANALYST |
| KING | PRESIDENT |
| FORD | ANALYST |
+-------+-----------+
2.多表查询
有时仅使用一张表达不到查询效果。
比如需要查询雇员名字和所在部门编号及部门名字。
由于雇员名字在emp表中,而部门名字在dept表中,因此需要联合查询。
mysql> select * from dept,emp;
上述语句也会生成一个表,这个表是dept和emp的笛卡尔积。
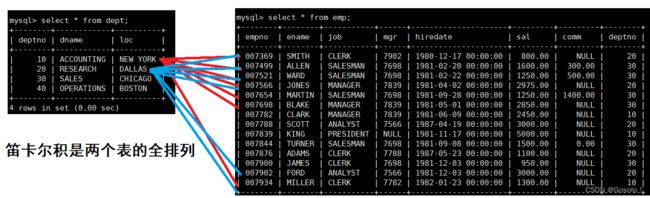
笛卡尔积会出现很多冗余数据是没有意义的,可以使用两张表有关联的部分进行筛选。比如部门编号。
mysql> select * from dept,emp where dept.deptno=emp.deptno;这张表就是多表查询后最完整的表,然后就可以从这张表里挑需要的数据进行显示了。
mysql> select ename,emp.deptno,dname from dept,emp where dept.deptno=emp.deptno;
+--------+--------+------------+
| ename | deptno | dname |
+--------+--------+------------+
| SMITH | 20 | RESEARCH |
| ALLEN | 30 | SALES |
| WARD | 30 | SALES |
| JONES | 20 | RESEARCH |
| MARTIN | 30 | SALES |
| BLAKE | 30 | SALES |
| CLARK | 10 | ACCOUNTING |
| SCOTT | 20 | RESEARCH |
| KING | 10 | ACCOUNTING |
| TURNER | 30 | SALES |
| ADAMS | 20 | RESEARCH |
| JAMES | 30 | SALES |
| FORD | 20 | RESEARCH |
| MILLER | 10 | ACCOUNTING |
+--------+--------+------------+显示部门号为10的部门名,员工名和工资
mysql> select dname,ename,sal from emp,dept where emp.deptno=dept.deptno
and dept.deptno=10;
+------------+--------+---------+
| dname | ename | sal |
+------------+--------+---------+
| ACCOUNTING | CLARK | 2450.00 |
| ACCOUNTING | KING | 5000.00 |
| ACCOUNTING | MILLER | 1300.00 |
+------------+--------+---------+显示各个员工的姓名,工资,及工资级别
mysql> select ename,sal,grade from emp,salgrade where emp.sal between losal and hisal;
+--------+---------+-------+
| ename | sal | grade |
+--------+---------+-------+
| SMITH | 800.00 | 1 |
| ALLEN | 1600.00 | 3 |
| WARD | 1250.00 | 2 |
| JONES | 2975.00 | 4 |
| MARTIN | 1250.00 | 2 |
| BLAKE | 2850.00 | 4 |
| CLARK | 2450.00 | 4 |
| SCOTT | 3000.00 | 4 |
| KING | 5000.00 | 5 |
| TURNER | 1500.00 | 3 |
| ADAMS | 1100.00 | 1 |
| JAMES | 950.00 | 1 |
| FORD | 3000.00 | 4 |
| MILLER | 1300.00 | 2 |
+--------+---------+-------+
14 rows in set (0.00 sec)2.2 多表查询总结
多表组合,形成笛卡尔积本质上就是数据的穷举。
解决多表查询的思路:
- 先确定和哪些表有关系
- 让几张有联系的表形成笛卡尔积
- 在形成的笛卡尔积中添加筛选条件,将多表查询看做为一张表的查询
3.自连接
自连接是指在同一张表连接查询。
显示员工ford的上级领导的编号和姓名
可以发现当前语句在书写时,需要在emp表中查找名字为ford的数据而且在显示筛选条件时也是在emp表中。称为子连接。
可以使用子查询来写
mysql> select empno,ename from emp where
empno=(select mgr from emp where ename='FORD');
+--------+-------+
| empno | ename |
+--------+-------+
| 007566 | JONES |
+--------+-------+也可以使用多表查询
同一张表不能直接查询两次,但是如果将该表起别名,就可以拼起来了。
mysql> select leader.empno,leader.ename from emp leader,emp worker
where worker.mgr=leader.empno and worker.ename='ford';
+--------+-------+
| empno | ename |
+--------+-------+
| 007566 | JONES |
+--------+-------+4. 子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询。
4.1 单行子查询
显示SMITH同一部门的员工
mysql> select ename,deptno from emp where deptno=(select deptno from emp where ename='smith');
+-------+--------+
| ename | deptno |
+-------+--------+
| SMITH | 20 |
| JONES | 20 |
| SCOTT | 20 |
| ADAMS | 20 |
| FORD | 20 |
+-------+--------+4.2 多行子查询
| in | in (...) 在(...)范围中 |
| all | all(...) 比(...)范围内都 |
| any | any(...) 比(...)范围内任意一个 |
查询和10号部门的工作岗位相同的雇员的名字,岗位,工资,部门号,但是不包含10自
己的
mysql> select * from emp where job in
(select distinct job from emp where deptno=10) and deptno!=10;
+--------+-------+---------+------+---------------------+---------+------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+-------+---------+------+---------------------+---------+------+--------+
| 007566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 007698 | BLAKE | MANAGER | 7839 | 1981-05-01 00:00:00 | 2850.00 | NULL | 30 |
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 |
| 007876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | NULL | 20 |
| 007900 | JAMES | CLERK | 7698 | 1981-12-03 00:00:00 | 950.00 | NULL | 30 |
+--------+-------+---------+------+---------------------+---------+------+--------+显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号
mysql> select ename,sal,deptno from emp where
sal>all(select sal from emp where deptno=30);
+-------+---------+--------+
| ename | sal | deptno |
+-------+---------+--------+
| JONES | 2975.00 | 20 |
| SCOTT | 3000.00 | 20 |
| KING | 5000.00 | 10 |
| FORD | 3000.00 | 20 |
+-------+---------+--------+4.3 多列子查询
查询和SMITH的部门和岗位完全相同的所有雇员,不含SMITH本人
mysql> select * from emp where (deptno,job)=
(select deptno,job from emp where ename='smith');
+--------+-------+-------+------+---------------------+---------+------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+-------+-------+------+---------------------+---------+------+--------+
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 |
| 007876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | NULL | 20 |
+--------+-------+-------+------+---------------------+---------+------+--------+
mysql> select * from emp where (deptno,job)=
(select deptno,job from emp where ename='smith') and ename!='smith';
+--------+-------+-------+------+---------------------+---------+------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+-------+-------+------+---------------------+---------+------+--------+
| 007876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | NULL | 20 |
+--------+-------+-------+------+---------------------+---------+------+--------+
4.4 在from子句中使用子查询
本质上还是多表查询,无非是把select的结果当做一个临时的表和其他表拼起来。
显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资
(1)先求一下每个部门的平均工资
mysql> select avg(sal), deptno from emp group by deptno;
+-------------+--------+
| avg(sal) | deptno |
+-------------+--------+
| 2916.666667 | 10 |
| 2175.000000 | 20 |
| 1566.666667 | 30 |
(2)把平均工资表和emp表拼起来,形成笛卡尔积,然后进行条件筛选。
mysql> select * from emp,
(select avg(sal) avgsal, deptno dt from emp group by deptno) tmp
where emp.deptno=tmp.dt;
+--------+--------+-----------+------+---------------------+---------+---------+--------+-------------+------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno | avgsal | dt |
+--------+--------+-----------+------+---------------------+---------+---------+--------+-------------+------+
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 | 2175.000000 | 20 |
| 007499 | ALLEN | SALESMAN | 7698 | 1981-02-20 00:00:00 | 1600.00 | 300.00 | 30 | 1566.666667 | 30 |
| 007521 | WARD | SALESMAN | 7698 | 1981-02-22 00:00:00 | 1250.00 | 500.00 | 30 | 1566.666667 | 30 |
| 007566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 | 2175.000000 | 20 |
| 007654 | MARTIN | SALESMAN | 7698 | 1981-09-28 00:00:00 | 1250.00 | 1400.00 | 30 | 1566.666667 | 30 |
| 007698 | BLAKE | MANAGER | 7839 | 1981-05-01 00:00:00 | 2850.00 | NULL | 30 | 1566.666667 | 30 |
| 007782 | CLARK | MANAGER | 7839 | 1981-06-09 00:00:00 | 2450.00 | NULL | 10 | 2916.666667 | 10 |
| 007788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | NULL | 20 | 2175.000000 | 20 |
| 007839 | KING | PRESIDENT | NULL | 1981-11-17 00:00:00 | 5000.00 | NULL | 10 | 2916.666667 | 10 |
| 007844 | TURNER | SALESMAN | 7698 | 1981-09-08 00:00:00 | 1500.00 | 0.00 | 30 | 1566.666667 | 30 |
| 007876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | NULL | 20 | 2175.000000 | 20 |
| 007900 | JAMES | CLERK | 7698 | 1981-12-03 00:00:00 | 950.00 | NULL | 30 | 1566.666667 | 30 |
| 007902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | NULL | 20 | 2175.000000 | 20 |
| 007934 | MILLER | CLERK | 7782 | 1982-01-23 00:00:00 | 1300.00 | NULL | 10 | 2916.666667 | 10 |
+--------+--------+-----------+------+---------------------+---------+---------+--------+-------------+------+
(3)进行筛选
mysql> select ename,deptno,sal,avgsal from emp,
(select avg(sal) avgsal, deptno dt from emp group by deptno)tmp
where emp.deptno=tmp.dt and emp.sal>tmp.avgsal;
查找每个部门工资最高的人的姓名、工资、部门、最高工资
(1)先筛出来最高工资
mysql> select max(sal) maxsal,deptno from emp group by deptno;
+---------+--------+
| maxsal | deptno |
+---------+--------+
| 5000.00 | 10 |
| 3000.00 | 20 |
| 2850.00 | 30 |
+---------+--------+(2) 将最高工资表和emp表拼起来
mysql> select* from emp,(select max(sal) maxsal,deptno
from emp group by deptno) tmp
where emp.deptno=tmp.deptno;
(3)加上限制条件和需要显示的信息列
mysql> select ename,emp.deptno,sal,maxsal from emp,
(select max(sal) maxsal,deptno from emp group by deptno) tmp
where emp.deptno=tmp.deptno and emp.sal=maxsal;
+-------+--------+---------+---------+
| ename | deptno | sal | maxsal |
+-------+--------+---------+---------+
| BLAKE | 30 | 2850.00 | 2850.00 |
| SCOTT | 20 | 3000.00 | 3000.00 |
| KING | 10 | 5000.00 | 5000.00 |
| FORD | 20 | 3000.00 | 3000.00 |
+-------+--------+---------+---------+
4.5 合并查询
为了合并多个select的执行结果,可以使用集合操作符 union(自带去重),union all(不去重)
union的两个表的结构必须相同,否则union出来的结果无意义。
mysql> select ename,sal from emp where sal>2500
union select sal,job from emp where job='manager';
+---------+---------+
| ename | sal |
+---------+---------+
| JONES | 2975.00 |
| BLAKE | 2850.00 |
| SCOTT | 3000.00 |
| KING | 5000.00 |
| FORD | 3000.00 |
| 2975.00 | MANAGER |
| 2850.00 | MANAGER |
| 2450.00 | MANAGER |
+---------+---------+将工资大于2500或职位是MANAGER的人找出来
mysql> select ename,sal,job from emp where sal>2500
union select ename,sal,job from emp where job='manager';
+-------+---------+-----------+
| ename | sal | job |
+-------+---------+-----------+
| JONES | 2975.00 | MANAGER |
| BLAKE | 2850.00 | MANAGER |
| SCOTT | 3000.00 | ANALYST |
| KING | 5000.00 | PRESIDENT |
| FORD | 3000.00 | ANALYST |
| CLARK | 2450.00 | MANAGER |
+-------+---------+-----------+
5.内外连接
5.1内连接
select 字段 from 表1 inner join 表2 on 连接条件 and 其他条件;
select ename, dname from EMP, DEPT where EMP.deptno=DEPT.deptno and
ename='SMITH';
select ename, dname from EMP inner join DEPT on EMP.deptno=DEPT.deptno and
ename='SMITH';上述使用的全都是内连接
inner join 相当于求两个表的交集。
5.2外连接
外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示,称为左外连接。
右侧的表完全显示,称为右外连接。
select 字段名 from 表名1 left join 表名2 on 连接条件内连接和外连接的区别在于
- left/right join相当于求left/right表的全集。没有对应的列属性就置成NULL
- 内连接是求交集