存活探针副本机制2
本次我们开始 k8s 中存活探针和副本控制器的学习
如何保持 pod 健康
前面我们已经知道如何创建 pod,删除和管理 pod了,但是我们要如何才能保持 pod 的健康状态呢?
我们可以使用 存活探针和副本机制
探针的分类
探针目前有
- 存活探针 liveness probe
- 就绪探针 readiness probe
本次我们这里先分享存活探针
存活探针
使用存活探针可以检查容器是否还在运行,我们可以为 pod 中的每一个容器单独的指定存活探针,如果探测失败,那么 k8s 就会定期的执行探针并重启容器
在 k8s 中,有 3 中探测容器的机制:
- http get 探针
可以对容器的 IP 地址,指定的端口和路径,进行 http get 请求,若探测器收到的状态码不是错误(2xx,3xx 的状态码),那么就认为是认为是探测成功,否则就是探测失败,本次容器就会被终止,然后重新启动一个 pod
- tcp 套接字探针
探测器尝试与指定端口建立 TCP 连接,如果成功建立连接,则探测成功,否则,失败
- Exec 探针
在容器内部执行命令,并检查退出的错误码,如果错误码是 0 ,则探测成功,否则失败
存活探针案例
我们来创建一个 pod ,加入我们的存活探针
kubia-liveness.yaml
apiVersion: v1
kind: Pod
metadata:
name: kubia-liveness
spec:
containers:
- image: luksa/kubia-unhealthy
name: kubia
livenessProbe:
httpGet:
path: /
port: 8080
还是使用之前的 kubia 的例子,我们拉取的镜像是 luksa/kubia-unhealthy,这个镜像和之前的镜像有一些区别,就是当收到外部访问的时候,前 5 次会正常响应,后面的请求都会报错
我们就可以通过这样的方式来测试 存活探针
部署一个 liveprobe 的案例,不健康的应用 kubia
部署 pod
kubectl create -f kubia-liveness.yaml
部署之后,大概1-2 分钟的时候,我们就可以看到我们启动的 pod 存在重启的情况
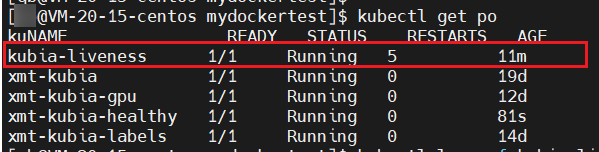
例如上图,kubia-liveness 11 分钟内,就重启了 5 次
查看崩溃应用的日志
我们查看日志的时候一般使用 kubectl logs -f xxx ,但是我们现在需要查看崩溃应用的日志,我们可以这么查看
kubectl logs -f kubia-liveness --previous
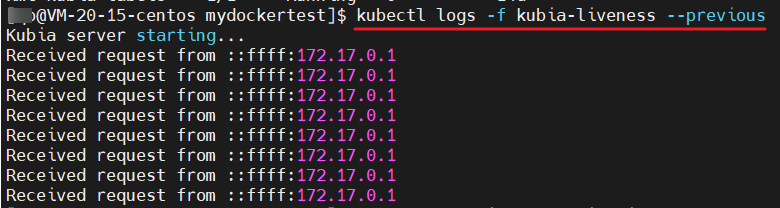
我们可以看到崩溃应用的程序是这样的
查看 pod 的详细信息
kubectl describe po kubia-liveness
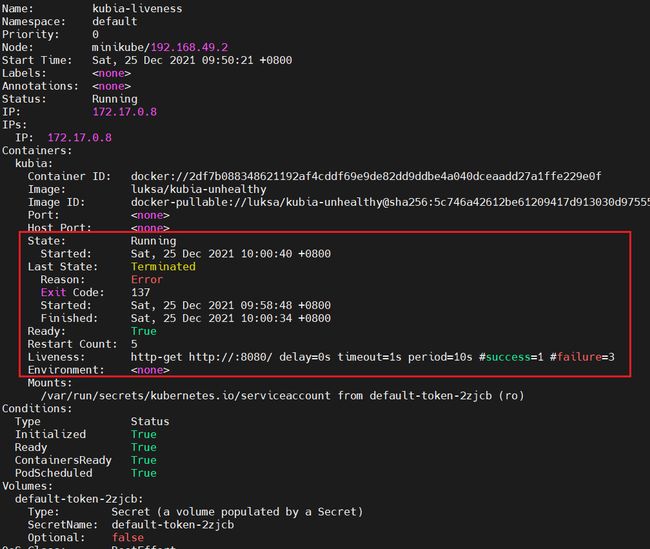
查看 pod 的详细信息的时候,我们可以看到这些关键信息:
- Exit Code
137 是代表 128 + x , 可以看出 x 是 9,也就是 SIGKILL 的信号编号,以为这强行终止
有时候,也会是 143,那么 x 就是 15,就是 SIGTERM 信号
Liveness
- delay 延迟
容器启动后延时多少时间才开始探测,若 该数值为 0 , 那么在容器启动后,就会立即探测
- timeout 超时时间
超时时间,可以看出上图超时时间为 1 秒,因此容器必须在 1 s 内做出响应,否则为探测失败
- period 周期
上图为 10 s 探测一次
- failure 失败次数
指 失败多少次之后,就会重启容器(此处说的重启容器,指删除掉原有 pod,重新创建一个 pod),上图是 失败 3 次后会重启容器

如上图,我们还可以看到 pod 的状态是不健康的,存活探针探测失败,原因是容器报 500 了,没有响应,因此会立即重启容器
配置存活探针的参数
配置存活探针的参数也就是和上述的 liveness probe 的参数一一对应,我们一般会设置一个延迟时间,因为容器启动之后,具体的应用程序有时并准备好
因此我们需要设定一个延迟时间,这个延迟时间,也可以标志是应用程序的启动时间
我们可以这样加入配置,设置容器启动后第一次探测时间延迟 20 s:
apiVersion: v1
kind: Pod
metadata:
name: kubia-liveness
spec:
containers:
- image: luksa/kubia-unhealthy
name: kubia
livenessProbe:
httpGet:
path: /
port: 8080
initialDelaySeconds: 20存活探针的注意事项
我们创建存活探针的时候,需要保证是一个有效的存活探针
- 配置存活探针请求的端口和地址,保证端口和地址有效
- 存活探针访问地址的时候,保证不需要认证,否则会一直失败,一起重启容器
- 一定要检查程序的内部,没有被外部因素所影响
- 要注意探针的不应消耗太多资源,一般必须在 1 s 内完成响应
遗留问题
使用探测保持 pod 健康,看上去感觉还不错,当 pod 中容器出现异常的时候,存活探针能够删除掉异常的 pod ,并立刻重新创建 pod
但是,如果是 pod 所在节点挂掉了,那么 存活探针就没有办法进行处理了,因为是节点上面的 Kubelet 来处理存活探针的事项,现在节点都异常了
我们可以使用副本机制来解决

ReplicationController 副本控制器
ReplicationController 也是K8S 的一种资源,前面有简单说到过,可以确保它管理的 pod 始终保持运行状态,如果 pod 因为任何原因消失了,ReplicationController 都会检测到这个情况,并会创建 pod 用于替代
举个 rc 的例子
rc 是 ReplicationController 的简称,rc 旨在创建和管理 pod 的多个副本
例如,node1 上面 有 2 个 pod, podAA 和 pod BB
- podAA 是单独创建的 pod,不受 rc 控制
- pod BB,是由 rc 控制的

当 node1 节点出现异常的时候,podAA 是没了就没了,没有人管它,自身自灭的
pod BB 就不一样,当 node1 出现异常的时候,rc 会在 node2 上面创建一个 pod BB 的副本
rc 小案例
rc 也是 k8s 的一种资源,那么创建 rc 的时候,也是通过 json 或者 yaml 的方式来创建的,创建 rc 有 3 个重要的组成部分:
- label selector 标签选择器
用于 rc 作用域哪些 pod
- replica count 副本个数
指定应运行的 pod 数量
- pod template pod 模板
用于创建新的 pod 股本
我们可以这样写,创建一个名为 kubia 的 rc
kubia-rc.yaml
apiVersion: v1
kind: ReplicationController
metadata:
name: kubia
spec:
replicas: 3
selector:
app: xmt-kubia
template:
metadata:
labels:
app: xmt-kubia
spec:
containers:
- name: rc-kubia
image: xiaomotong888/xmtkubia
ports:
- containerPort: 8080- 表示创建一个 rc,名字是 kubia,副本数是 3 个,选择器是 app=xmt-kubia
- rc 对应的 pod 模板,拉取的镜像地址是 xiaomotong888/xmtkubia,标签是 app=xmt-kubia
我们创建 rc 的时候,一般也可以不用写 selector,因为 Kubernetes API 会去检查 yaml 是否正确,yaml 中是否有模板,如果有模板的话,selector 对应的标签,就是 pod 模板中的标签
但是一定要写 pod 的模板 template,否则 Kubernetes API 就会报错误信息
部署 rc
kubectl create -f kubia-rc.yaml
查看 rc 和 查看 pod 的标签
kubectl get rc
kubectl get pod --show-labels
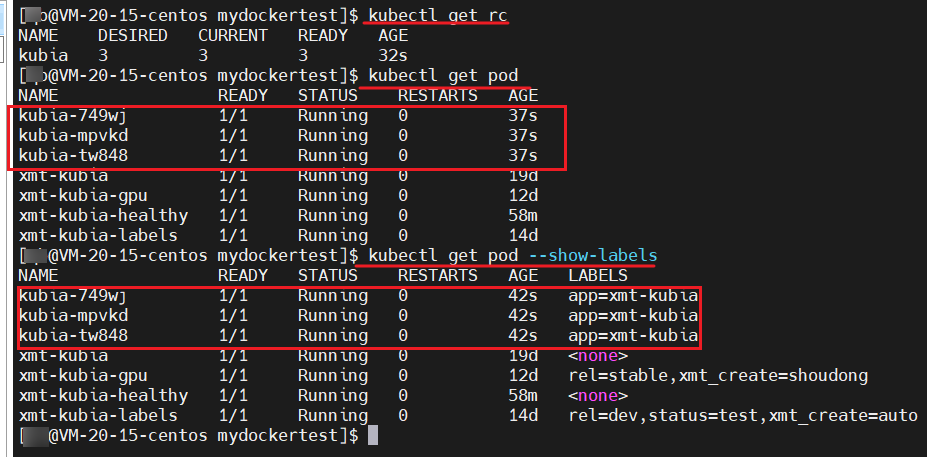
我们可以看到创建的 rc 资源,所需要创建 pod 数量是 3,当前实际数量是 3 ,就绪的也是 3 个
kubia-749wj
kubia-mpvkd
kubia-tw848
并且,他们的标签都是 app=xmt-kubia,没毛病老铁
rc 的扩容和缩容
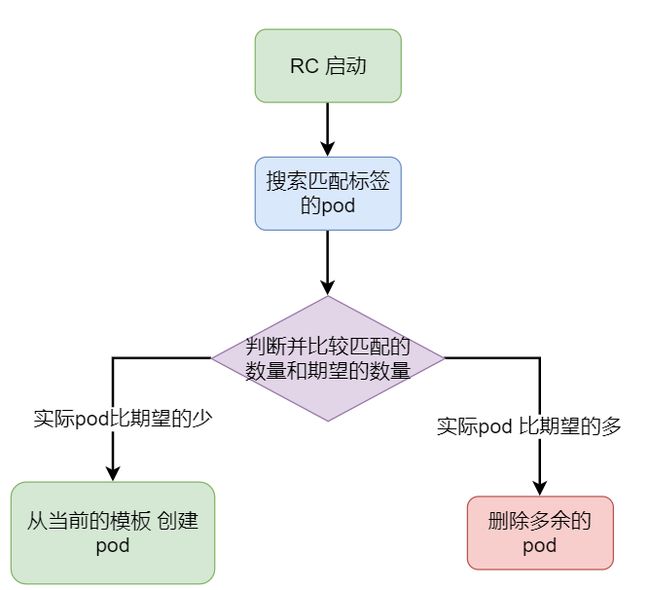
rc 控制器会控制创建 pod 和删除 pod,大致逻辑是这样的
rc 启动的时候,会在环境中搜索匹配的标签,
- 若搜索到的标签数量小于 rc 中配置的期望数量,则进行创建新的 pod
- 若搜索到的标签数量大于rc 中配置的期望数量,则进行删除多余的 pod
我们尝试删除掉 kubia-749wj ,验证 rc 是否会自动创建新的 pod
kubectl delete po kubia-749wj

果然 kubia-749wj 已经是终止状态了,且 rc 已经为我们创建了一个 新的 pod
查看 rc 的详情
kubectl describe rc kubia
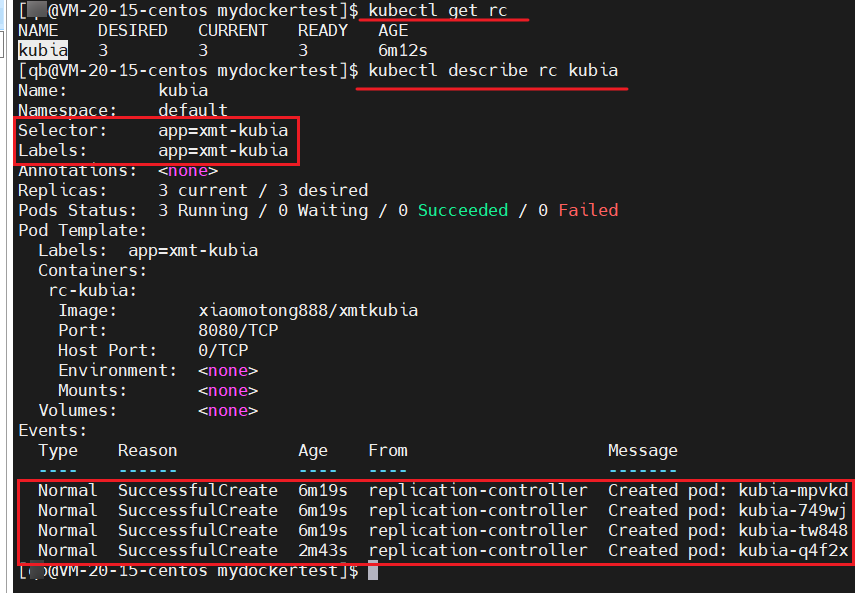
我们可以看到,从创建 rc 到现在,rc 创建的 pod 的记录是 4 个
修改 pod 的标签
我们尝试修改某个 pod 的标签,看看是否会影响 rc 的
在 kubia–mpvkd pod 上面增加一个 ver=dev 的标签,看看该 pod 是否会被删除掉
kubectl get pod --show-labels
kuebctl label pod kubia-mpvkd ver=dev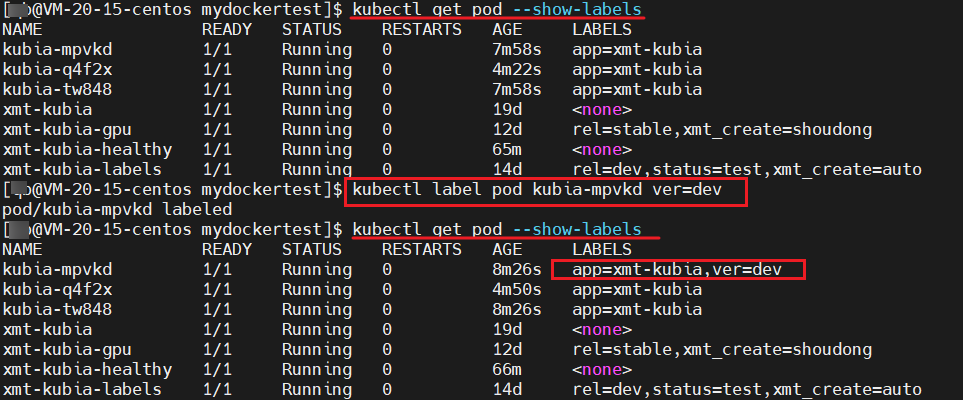
果然是没有的,对于 rc 来说,他只会管理和控制自己配置好的标签,其余的标签他一概不管
重写 app 标签
前面我们有说到过,如果 pod 上已经有标签,若是要修改的话,需要使用--overwrite 进行重写,这也是 k8s 为了方式误操作,覆盖了已经配置好的标签
我们将 app标签修改成 app=anonymous
kubectl label pod kubia-mpvkd app=anonymous --overwrite
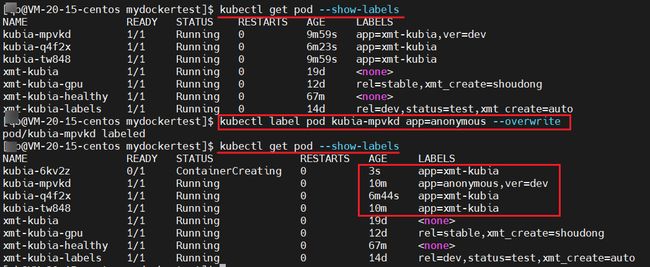
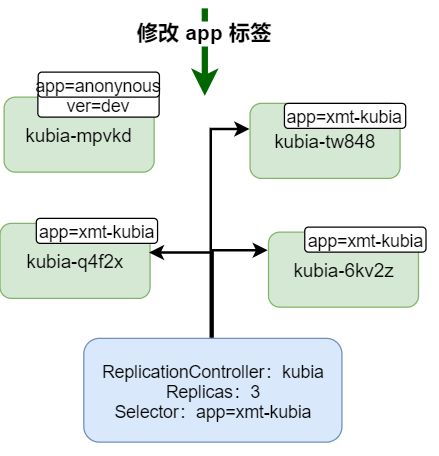
查看到的效果是原来的 kubia-mpvkd pod 没有什么影响,但是 rc 检测到 app=xmt-kubia 标签的数量小于 rc 的期望值,因此会主动创建一个新的 pod 作为替代
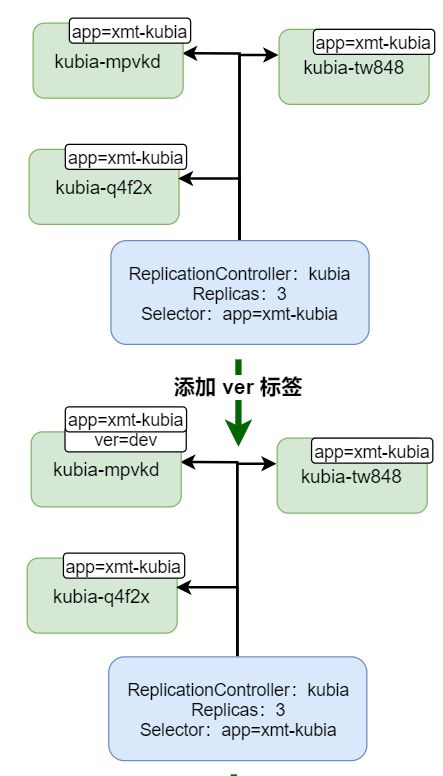
简单流程和效果如下图:
说一下修改模板
修改模板的话,是很简单的,只需要编辑一个 rc 配置即可
kubectl edit rc kubia
执行命令后,将 rc 配置中 pod 模板中 image 的位置,修改成自己需要下载的镜像地址即可,关于 pod 模板的简单流程如下:

上图中,我们可以理解,修改了 pod 模板的话,对于之前的 pod 是没有影响的,因为副本的个数还是没有变化
当我们删除掉一个 pod 的时候,次数 rc 检测到 实际的 pod 个数小于 期望的个数,因此会创建一个新的 pod,此时创建的 pod,用的就是刚才我们修改的 pod 模板
修改副本数
我们可以尝试修改副本数为 6 ,还是一样的操作,编辑 rc 配置即可
kubectl edit rc kubia
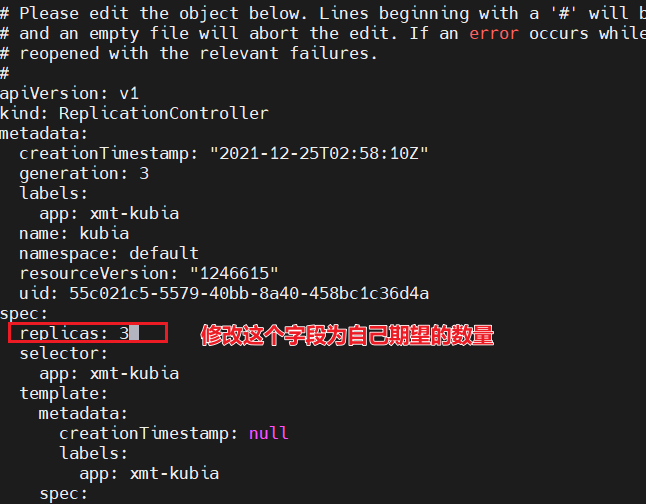
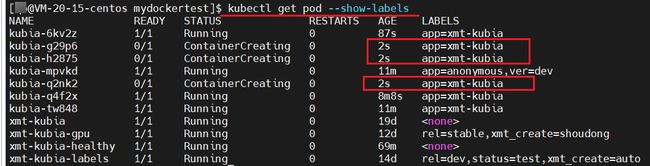
效果如上, rc 为我们又创建了 3 个 pod,总共是 6 个
修改副本数为 2

效果如上,rc 确实将其余的 4 个pod 都干掉了,最后剩下 2 个 pod
删除 rc
小伙伴们有没有这样的疑问,删除 rc 的话,是不是 pod 也就跟着被销毁了,是的,没毛病老铁
但是我们也可以做到删除 rc 后,不影响 pod 资源,可以这样来执行
kubectl delete rc kubia --cascade=false

看到信息提示, --cascade=false 已经被废弃了,我们可以使用 --cascade=orphan
删除 rc 生效,我们来看看简单的删除流程和效果
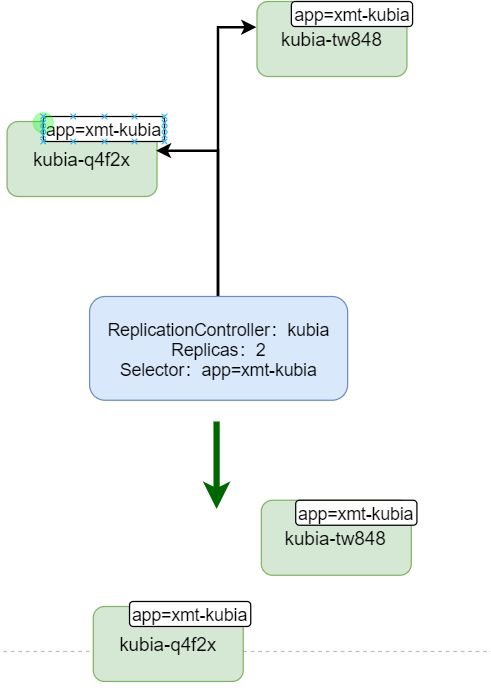
今天就到这里,学习所得,若有偏差,还请斧正
欢迎点赞,关注,收藏
朋友们,你的支持和鼓励,是我坚持分享,提高质量的动力

好了,本次就到这里
技术是开放的,我们的心态,更应是开放的。拥抱变化,向阳而生,努力向前行。
我是阿兵云原生,欢迎点赞关注收藏,下次见~