Redis——Redis详解
文章目录
- Redis
-
- 1. 常见数据类型
-
- 1.1 测试一下
- 2. Redis持久化
-
- 2.1 RDB (Redis DataBase)快照
- 2.1 AOF (Append-only file)文件命令
- 3. Redis的过期键的删除策略
-
- 3. 1 定时删除
- 3. 2 惰性删除
- 3. 3 定期删除
- 4. Redis的内存淘汰策略
Redis
1. 常见数据类型
常见的数据类型,一共有5种。
String: 标准的key、value类型。给Key取名字的时候比较关键,这样我们直接判断缓存中有没有值,没有值就查库。
Hash: Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
List: Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
set: Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。类似于java的set集合。
zset: 有序集合和集合一样也是string类型的元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个double类型的分数,redis 正是通过分数来集合中的成员进行从小到大的排序,有序集合的成员是唯一的,但分数(score)却可以重复。
1.1 测试一下
首先开启redis的server。找到redis的安装目录,运行redis-server 脚本,启动redis服务。
redis-server
在Springboot工程中配置redis的配置,依赖此处不展示。
server:
port: 8080
spring:
datasource:
password: 123
username: root
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1/city?useUnicode=true&characterEncoding=UTF-8
application:
name: zlDemo
## redis连接
redis:
database: 0
port: 6379
password: 123
host: localhost
随便编写一个工具类
package cn.zl.springbootdemo.redis;
import org.apache.commons.beanutils.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.*;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import java.util.*;
/**
* @ClassName : RedisCache
* @Description :
* @Author : zl
* @Date: 2021-07-18 14:42
*/
@Component
public final class RedisCache {
// redisTemplate是redis内置的一个操作redis的对象。
private static RedisTemplate<String, String> redisTemplate;
// String 数据类型的操作对象
private static ValueOperations<String, String> stringOps;
// Hash 数据类型的操作对象
private static HashOperations<String, Object, Object> hashOps;
// List 数据类型的操作对象
private static ListOperations<String, String> listOps;
// set 数据类型的操作对象
private static SetOperations<String, String> setOps;
// zset 数据类型的操作对象
private static ZSetOperations<String, String> zsetOps;
private RedisCache() {
}
@Autowired
public void setRedisTemplate(RedisTemplate<String, String> redisTemplate) {
RedisCache.redisTemplate = redisTemplate;
}
@PostConstruct
public void init() {
RedisCache.stringOps = redisTemplate.opsForValue();
RedisCache.hashOps = redisTemplate.opsForHash();
RedisCache.listOps = redisTemplate.opsForList();
RedisCache.setOps = redisTemplate.opsForSet();
RedisCache.zsetOps = redisTemplate.opsForZSet();
}
/**
* 获取字符串类型的值
*
* @param key
* @return
*/
public static String getValueByString(String key) {
return stringOps.get(key);
}
/**
* 设置字符串类型的值
*
* @param key
* @param value
*/
public static void setValueByString(String key, String value) {
stringOps.set(key, value);
}
/**
* 设置Hash值
*
* @param key
* @param object
* @param tClass
* @throws InvocationTargetException
* @throws IllegalAccessException
*/
public static void setHashValueByHash(String key, Object object, Class tClass) throws InvocationTargetException, IllegalAccessException {
if (!object.getClass().equals(tClass)) {
return;
}
// 获取类上的所有字段
HashMap map = new HashMap<>();
Method[] declaredMethods = tClass.getDeclaredMethods();
for (Method declaredMethod : declaredMethods) {
String name = declaredMethod.getName();
if (name.startsWith("get")) {
Object invoke = declaredMethod.invoke(object);
// 存储的字段一定要与类的字段相同。
map.put(name.split("get")[1].substring(0, 1).toLowerCase() + name.split("get")[1].substring(1), String.valueOf(invoke));
}
}
hashOps.putAll(key, map);
}
/**
* 获取Hash值
*
* @param key 根据key 获取对象
*/
public static Object getHashValueByHash(String key, Class tclass) {
Map<Object, Object> map = hashOps.entries(key);
Object newInstance = null;
try {
newInstance = tclass.newInstance();
// map 转成bean
HashMap<String, Object> hashMap = new HashMap<>();
map.forEach((k, v) -> {
hashMap.put((String) k, v);
});
BeanUtils.populate(newInstance, hashMap);
} catch (Exception e) {
e.printStackTrace();
}
return newInstance;
}
/**
* 设置List,尾插法
*/
public void setListValueByList(String key ,String value){
listOps.rightPush(key,value);
}
public String getListValueByList(String key){
String value = listOps.leftPop(key);
return value;
}
public void setSetValueBySet(String key,Set<String> values){
String[] objects = (String[]) values.toArray();
setOps.add(key,objects);
}
public String getSetValueBySet(String key){
return setOps.pop(key);
}
}
写一点测试代码
@Transactional(propagation = Propagation.REQUIRED)
public List<City> getAllCity(){
List<City> allCity = cityDao.getAllCity();
allCity.stream().forEach(city -> {
RedisCache.setValueByString(city.getName()+":"+city.getId(),JSON.toJSONString(city));
try {
RedisCache.setHashValueByHash(city.getName(),city,City.class);
} catch (InvocationTargetException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
});
return allCity;
}
测试结果: 可以看见redis已经插入数据了。
2. Redis持久化
持久化,就是将redis内存中的数据写入到硬盘中。防止服务宕机了内存数据丢失。
Redis 提供了两种持久化机制RDB(默认)和AOF机制;
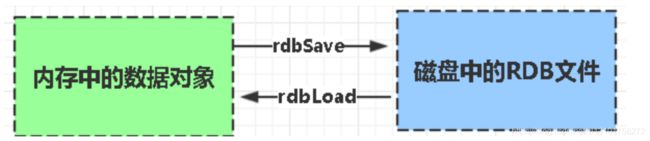
2.1 RDB (Redis DataBase)快照
RDB是Redis默认的持久化方式。按照一定的时间将内存的数据以快照的形式保存到硬盘中,对应产生的数据文件为dump.rdb。通过配置文件中的save参数来定义修改快照的周期。
持久化默认配置
save 900 1 900秒内,如果超过一个1key被修改,则发起快照保存
save 300 10 300秒内,如果超过10个key被修改,则发起快照保存
save 60 10000 60秒内,如果1万个key被修改,则发起快照保存
备份文件存储的位置
![]()
此文件是一个二进制的文件。也就是说rdb是采用二进制的存储方式来持久化redis缓存中的数据。
优点:
- 性能高,redis fork子进程来完成写操作。不影响主进程处理命令。
- 只有一个文件 dump.rdb,方便持久化
- 容灾性好,一个文件可以保存到安全的磁盘
- 相对于数据集大时,比 AOF 的启动效率更高。
缺点:
- 数据安全性低,容易丢失数据
2.1 AOF (Append-only file)文件命令
修改配置参数开启AOF
appendonly yes
持久化配置
# appendfsync always 每次操作都会立即写入AOF文件中
appendfsync everysec 每秒持久化一次(默认配置)
# appendfsync no 不主动进行同步操作,默认30s一次
当然 always一定是效率最低的,个人认为everysec就够用了,数据安全性能搞。Redis也允许我们同时使用两种方式,再重启redis后会从AOF中恢复数据,因为AOF比RDB数据损失小嘛
更多的配置
appendonly改为yes,开启AOF
appendonly yes
# AOF文件的名字
appendfilename "appendonly.aof"
# AOF文件的写入方式
# everysec 每个一秒将缓存区内容写入文件 默认开启的写入方式
appendfsync everysec
# 运行AOF重写时AOF文件大小的增长率的最小值
auto-aof-rewrite-percentage 100
# 运行AOF重写时文件大小的最小值
auto-aof-rewrite-min-size 64mb
优点:
- 数据安全,aof 持久化可以配置 appendfsync 属性,有 always,每进行一次 命令操作就记录到 aof 文件中一次。
- 通过 append 模式写文件,即使中途服务器宕机,可以通过 redis-check-aof 工具解决数据一致性问题。
- AOF 机制的 rewrite 模式。AOF 文件没被 rewrite 之前(文件过大时会对命令 进行合并重写),可以删除其中的某些命令(比如误操作的 flushall))
缺点:
- AOF 文件比 RDB 文件大,且恢复速度慢。
- 数据集大的时候,比 rdb 启动效率低。
3. Redis的过期键的删除策略
Redis是key-value 数据库,我们可以设置Redis中缓存的key的过期时间。Redis的过期策略就是指当Redis中缓存的key过期了,Redis如何处理?一共有三种处理策略。定时删除,惰性删除,定期删除。
redis使用的是惰性删除+定期删除策略。
3. 1 定时删除
会为每一个设置了过期时间的key开启一个定时器,定时器一到。就会去删除对应的key(节约内存空间,因为过期了的key是要被删除的,而这个策略会马上删除腾出更多的内存空间,但是每一个key都维护了一个定时器,带来一部分的开销,CPU消耗大,如果同时过期的key太多的话,还会出现卡顿的情况),并发量小,内存小,可以使用。
3. 2 惰性删除
在使用key的时候,才进行删除,CPU效率最高,但是过期了key可能会长期占用内存。就比如说:你设置1G的内存,存活时间为3分钟,但是,五分钟之后,你发现redis还是占用着那1g的内存,那么就是因为采用了惰性删除的策略,那么在没有操作这些key之前,是不会去删除,如果你想要删除,你可以去查看一下这些key,他们就会被删除了。
3. 3 定期删除
就是没隔一段时间,就对过期了的key进行删除,节省了cpu,但是有些过期了的key会在下一个定时周期到来之前占用一部分内存。
4. Redis的内存淘汰策略
Redis内存淘汰策略,其实就是redis的垃圾回收。
maxmemory 可以用来设置内存的最大使用量,达到限度是就会执行内存淘汰机制。
| 名称 | 描述 |
|---|---|
| volatile-lru | 从已经设置过期时间的数据集中挑选出最近最少使用的数据淘汰 |
| volatile-lfu | 从已经设置过期时间的数据集合中挑选出最不经常用的数据淘汰 |
| volatile-ttl | 从已经设置过期时间的数据集合中挑选将要过期的数据淘汰 |
| volatile-random | 从已经设置过期时间的数据集中套选出任意数据淘汰 |
| allkeys-lru | 当内存不足写入新数据时淘汰最近最少使用的key |
| alllkeys-random | 当内存不足写入新数据时随机选择key淘汰 |
| alllkeys-lfu | 当内存不足写入新数据时移出最不经常使用的key |
| no-eviction | 当内存不足写入新数据时,写入操作会报错,同时不删除数据 |
- volatile 为前缀的策略都是从已经过期的数据集中进行淘汰。
- allkeys 为前缀的策略都是面向所有key进行淘汰。
- LRU (least recently used)最近最少用的。
- LFU(least Frequently used)最不常用的。
- 它们的触发条件都是Redis使用的内存达到阈值时。
参数设置:
maxmemory 设置最大内存
maxmemory-policy 设置内存的淘汰机制