1357篇ECCV 2020论文打包下载!奖项公布:李飞飞高徒获最佳论文奖
点击上方“计算机视觉工坊”,选择“星标”
干货第一时间送达
![]()
ECCV2020论文合集下载
ECCV2020论文现已开放下载,地址为:
http://www.ecva.net/papers.php
为了方便大家学习,现已经将全部论文(共1357篇)下载并打包,在 计算机视觉工坊 后台回复 ECCV2020 即可获取论文打包下载链接。
下面将介绍本次ECCV2020的五项大奖。(内容来源:机器之心)
最佳论文奖

论文地址:https://arxiv.org/abs/2003.12039
GitHub 地址:https://github.com/princeton-vl/RAFT
这项研究提出了一种用于光流的新型深度网络架构——循环全对场变换(Recurrent All-Pairs Field Transforms,RAFT)。RAFT 提取每个像素(per-pixel)的特征,为所有像素对构建多尺度 4D 相关体(correlation volume),并通过循环单元迭代地更新流场,循环单元基于相关体执行查找。
RAFT 在多个数据集上实现了 SOTA 性能:在 KITTI 数据集上,RAFT 的 F1-all 误差是 5.10%,相比先前的最佳结果(6.10%)减少了 16%;在 Sintel 数据集(final pass)上,RAFT 只有 2.855 像素的端点误差(end-point-error),相比先前的最佳结果(4.098 像素)减少了 30%。另外,RAFT 具有强大的跨数据集泛化能力,并且在推理时间、训练速度和参数计数方面具有很高的效率。

RAFT 架构设计。
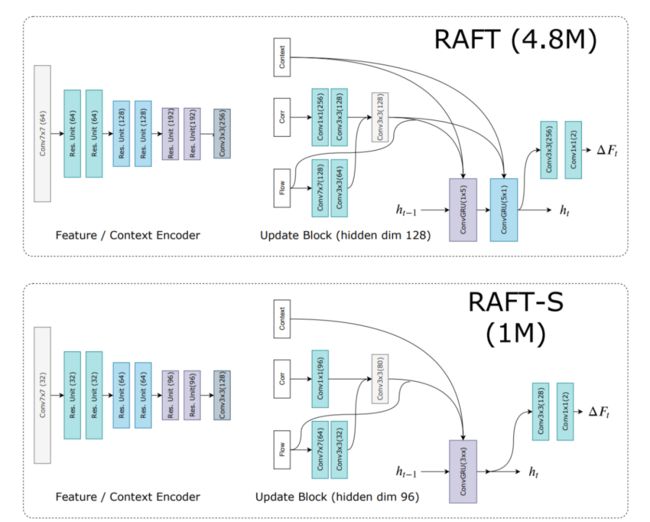
4.8M 参数完整版模型和 1.0M 参数小模型的网络架构细节。
作者简介

最佳论文的第一作者 Zachary Teed 现在普林斯顿读博,导师为邓嘉。他的研究兴趣是:3D 视频重建,包括运动恢复结构(Structure from Motion,SfM)、场景流(Scene Flow)和 SLAM。

论文二作是普林斯顿大学计算机科学系助理教授邓嘉,主要研究方向是计算机视觉和机器学习,
目前的研究兴趣是:3D 视觉、目标识别、动作识别和自动定理证明。曾获得 Sloan Research Fellowship、PAMI Mark Everingham Prize、 Yahoo ACE Award、Google Faculty Research Award、ICCV Marr Prize 等奖项。
值得一提的是,这并不是邓嘉第一次获得 ECCV 的最佳论文奖,2014 年他凭借论文《Large-Scale Object Classification Using Label Relation Graphs》获得当年的 ECCV 最佳论文奖,并且是该研究的第一作者。
除此之外,他还是 ImageNet 论文的第一作者。ImageNet 数据集是目前机器学习领域最常用的数据集之一,它催生出了极大促进人工智能发展的 ImageNet 比赛。作为 ImageNet 的一作,邓嘉为其倾注了许多心血。
2019 年,这篇论文获得了 CVPR PAMI Longuet-Higgins(经典论文)奖。邓嘉在接受机器之心采访时表示:「这个项目很说明一件事情,当时做 ImageNet 不是最主流的工作,但是我们所有做此项目的人都相信它会有很大的影响,所以我们就花了很大力气做这个事情。确实,它给我自己的一个启示是,你不一定要做最流行的事情,但要做自己相信会有影响的事情。」目前,这篇发表于 2009 年的论文被引用量已超过两万。
最佳论文荣誉提名奖
大会还公布了最佳论文荣誉提名奖,共有两篇论文获得此奖项。

论文 1:Towards Streaming Image Understanding
论文地址:https://arxiv.org/abs/2005.10420
论文作者:Mengtian Li、Yu-Xiong Wang、Deva Ramanan(卡内基梅隆大学)
具身感知(embodied perception)指自动智能体感知环境以便做出反应的能力。智能体的响应度很大程度上取决于处理流程的延迟。之前的工作主要涉及延迟和准确率之间的算法权衡,但缺少一种明确的指标来对比不同方法的帕累托最优延迟 - 准确率曲线。这篇论文指出标准离线评估和实时应用之间的差异:算法处理完特定图像帧时,周围环境已经发生改变。该研究提出将延迟和准确率协调地集成到一个度量指标中,用于实时在线感知,这就是「流准确率」(streaming accuracy)。
此外,该研究基于此度量指标提出了一个元基准,它可以系统性地将任意图像理解任务转换成流图像理解任务。研究人员主要关注城市视频流中的目标检测和实例分割任务,并创建了具备高质量、时序稠密标注的新数据集。
该研究提出的解决方案及其实证分析结果显示:
在帕累托最优延迟 - 准确率曲线上,存在能够最大化流准确率的最优点;
异步跟踪和未来预测很自然地成为流图像理解的内部表征;
动态调度可用于克服时间混叠(temporal aliasing),得到一个吊诡的结果:什么都不做可能使延迟最小化。
论文 2:NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
论文地址:https://arxiv.org/abs/2003.08934
论文作者:Ben Mildenhall(UC 伯克利)、Pratul P. Srinivasan(UC 伯克利)、Matthew Tancik(UC 伯克利)、Jonathan T. Barron(谷歌)、Ravi Ramamoorthi(加州大学圣地亚哥分校)、Ren Ng(UC 伯克利)
该研究提出了一种在合成复杂场景新视图任务中实现 SOTA 结果的新方法,该方法通过使用稀疏的输入视图集来优化基础的连续体场景函数。该算法使用全连接深度网络表示场景,其输入为单个连续 5D 坐标(空间位置 (x, y, z) 和视角方向 (θ, φ)),输出为体积密度和在此空间位置上的视图相关 emitted radiance。该研究通过查询沿着摄像头光线的 5D 坐标来合成视图,并使用经典的体渲染技术将输出颜色和密度投影到图像中。
由于体渲染本身是可微的,因此优化表征所需的唯一输入是一组具备已知摄像机位姿的图像。研究者介绍了如何高效优化神经辐射场(neural radiance field),渲染出逼真的具备复杂几何形状和外观的场景新视图,而且其在神经渲染和视图合成方面的效果优于之前的工作。
经典论文:Koenderink 奖
Koenderink 奖旨在表彰计算机视觉领域的基础性贡献研究,获奖论文均为发表时间超过十年并经受住时间检验的研究。
本届 ECCV 会议 Koenderink 奖颁发给了以下两篇论文:

论文 1:Improving the Fisher Kernel for Large-Scale Image Classification
论文地址:https://lear.inrialpes.fr/pubs/2010/PSM10/PSM10_0766.pdf
论文作者:Florent Perronnin、Jorge S´anchez、Thomas Mensink(施乐欧洲研究中心)
Fisher Kernel(FK)是一个结合了生成和判别方法优点的通用框架。在图像分类领域,FK 扩展了流行的视觉词袋(BOV)模型。然而,在实践中,这种丰富的表征尚未显现出相对 BOV 的优越性。
在论文的第一部分,研究者对原始框架进行了多项修改,使得 FK 准确率得到提升。在 PASCAL VOC 2007 数据集上的平均精度(AP)从 47.9% 提升到了 58.3%。改进后的框架在 CalTech 256 数据集上也展现出了 SOTA 准确率。其主要优势在于这些结果仅使用 SIFT 描述子和线性分类器获得。使用该表征后,FK 框架可用于探索更大规模的图像分类任务。
在论文的第二部分应用部分,研究者对比了在两个大规模标注图像数据集上的分类器训练情况:ImageNet 和 Flickr groups 数据集。在涉及数十万训练图像的评估中,研究者发现基于 Flickr groups 学得的分类器性能非常好,而且它们可以对在更精细标注数据集上学得的分类器进行补充。
论文 2:BRIEF: Binary Robust Independent Elementary Features
论文地址:https://www.cs.ubc.ca/~lowe/525/papers/calonder_eccv10.pdf
论文作者:Michael Calonder、Vincent Lepetit、Christoph Strecha、Pascal Fua(洛桑联邦理工学院)
这项研究提出将二进制字符串用作高效的特征点描述符,即 BRIEF。研究证明,即使在 bits 相对较少的情况下,BRIEF 依然呈现出高判别性,并且可以通过简单的强度差测试来计算。
此外,对描述符相似度的评估没有采用常见的 L_2 范数,而是使用了汉明距离(Hamming distance),后者计算起来非常高效。
因此,BRIEF 的构建和匹配速度非常快。该研究在标准基准上将 BRIEF 与 SURF 和 U-SURF 进行比较,结果表明 BRIEF 能够实现相当或更优的识别性能,同时运行时间只需其他二者的一部分。
PAMI Everingham 奖
该奖项旨在纪念 Mark Everingham,并鼓励其他人向他学习,推进整个计算机视觉社区进一步发展。PAMI Everingham 奖授予对计算机视觉社区做出无私贡献的研究者或研究团队,由 IEEE 计算机协会模式分析与机器智能(PAMI)技术委员会颁发。
今年的 PAMI Everingham 奖颁给了微软高级科学家 Johannes Schönberger,以及 MIT 教授 Antonio Torralba 及创建多个数据集的合作者。

Johannes Schönberger 现为微软混合现实与人工智能苏黎世实验室高级科学家,开发了 COLMAP SFM 和 MVS 软件库。
Johannes Schönberger 的获奖理由是:他的工作为 3D 图像重建提供了一个开源的端到端 pipeline 以及相关支持、开发和文档。目前这已成为运动恢复结构(SFM)和多视角立体视觉(Multi-view Stereo,MVS)的参考软件。

Antonio Torralba 现为 MIT 电气工程与计算机科学教授。在十多年的时间里,Antonio Torralba 与其他合作者定期发布新数据集以及创建这些数据集的方法。他们创建的 LabelMe、Tiny images、SUN/SUN-3D 和 MIT-Places 等数据集在计算机视觉领域有着极大的影响力。
Demo 奖
此外,大会公布了 Demo 奖。获奖论文是《Inter-Homines: Distance-Based Risk Estimation for Human Safety》。

该研究的 demo 如下:
另有两篇研究获得了 ECCV 2020 Demo 奖提名:
论文 1:FingerTrack:Continous 3D Hand Pose Tracking
论文 2:Object Detection Kit:Identifying Urban Issues in Real-time

本文转载自公众号@极市平台。
本文仅做学术分享,如有侵权,请联系删文。
下载1
在「计算机视觉工坊」公众号后台回复:3D视觉,即可下载 3D视觉相关资料干货,涉及相机标定、三维重建、立体视觉、SLAM、深度学习、点云后处理、多视图几何等方向。
下载2
在「计算机视觉工坊」公众号后台回复:3D视觉github资源汇总,即可下载包括结构光、标定源码、缺陷检测源码、深度估计与深度补全源码、点云处理相关源码、立体匹配源码、单目、双目3D检测、基于点云的3D检测、6D姿态估计源码等。
下载3
在「计算机视觉工坊」公众号后台回复:相机标定,即可下载独家相机标定学习课件与视频网址;后台回复:立体匹配,即可下载独家立体匹配学习课件与视频网址。
重磅!计算机视觉工坊-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的知识点汇总、入门进阶学习路线、最新paper分享、疑问解答四个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000+星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~ 