30、IP数据包结构
本节来学习IP数据包的结构,前面我们一直在说数据包,IP数据包是网络层的PDU。PDU的概念我们在本专栏第2节的内容中谈到过,忘记了就赶快去复习。数据包也被称为“IP数据报”或者“IP分组”,这三个概念是通用的,到任何一本计算机网络教材中都适用的。
IP数据包的组成
IP数据包是由数据发送方的传输层交付下来的信息加上网络层的IP首部封装而成的,所以从整体来看,IP数据包有两个组成部分:IP首部+数据部分。
数据部分就是网络层的上层交付下来的信息,具体是什么格式我们现在不用管。本节主要重点学习的是,IP首部的格式。
首部格式
仍然按照惯例,先给出IP首部的格式图,然后我们逐一地解释各个字段。
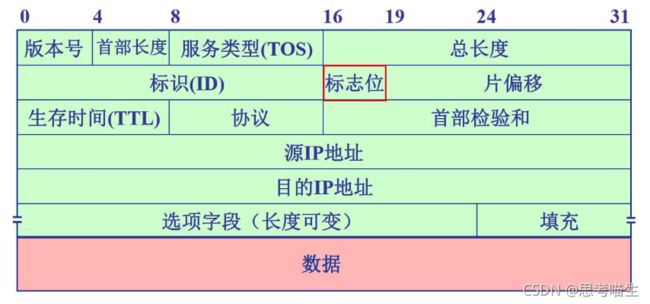
上图的绿色部分即为IP首部的格式,粉色部分是数据部分。
先来看图的最上边,写着“0 4 8 16 19 24 31”的这一行数字,这代表的是二进制位数,也就表示了每个字段的长度是多少,比如第二行第一个,标识字段,长度是0~16,也就是16个位的长度,也就是两个字节的长度(1字节=8位),再比如第四行的,源IP地址字段,长度是从0到第31位,一共有32个位的长度,也就是四个字节的长度。
所以,整个IP首部中,从版本号字段到目的IP地址字段一共是有20个字节的长度,这是IP首部固定首部的长度,这个长度永远是20字节。然后我们可以看到整个IP首部的最后一行是“选项字段和填充”,选项字段标着“长度可变”,这就意味着这个字段的长度不是固定的,就不属于固定首部的部分。
字段含义
版本号
指明了此IP数据包使用的IP协议是什么版本的,如果此字段值为4,就表示这是一个IPv4的数据包,如果此字段值为6,则表示这是一个IPv6的数据包。
首部长度
指明了此IP数据包的首部的长度是多少字节。首部长度字段的值的单位是4个字节,也就是说如果此字段的值为5,则表示整个IP数据包的首部长度是5×(4个字节)=20字节。事实上,20字节是最小首部长度,原因是:可以看到,如果一个IP数据包没有可变长度的部分,只有固定首部的话,那么首部长度就是20字节。
那么,首部长度有没有最大值呢?有,首部长度最大60字节,也就是不仅包含了20字节的固定首部,还有40字节的可变首部。因为首部长度这个字段在整个IP首部中占了4位,4位二进制能表示的最大数就是15,15×(4个字节)=60字节,这就是最大首部长度的来源。
服务类型
或者称为“区分服务”字段,这个字段只有在使用一定QoS策略的时候才起作用,而我们现在涉及不到这么复杂的知识,QoS以后会在路由交换专栏中去介绍。
总长度
总长度的值=首部长度+数据部分的长度,单位是字节。而总长度这个字段在整个IP数据包中的长度是16位,16位二进制最大可表示的数就是65535,所以这就意味着总长度字段的值最大是65535,也就表示整个IP数据包最大也就到65535个字节(当然这么大的包很少见)。
标识、标志位、片偏移
这三个字段是有联系的,所以我们放在一起学习。
要理解这三个字段的含义,必须要和数据链路层学过的MTU(最大传输单元)的概念联系起来,以太网规定MTU值为1500字节,那么当IP数据包的长度大于1500字节时,向下交付到数据链路层的时候,在数据链路层是通不过的,所以在这时候就使用了把“IP数据包”分片的技术。形象的说,就是由于数据包太长,超过了数据链路层规定的最大传输值,所以就要把数据包“切割”成几个合适长度的小包,使之能通过数据链路层。
要注意的是,“切割”数据包的时候,只“切割”数据部分,不“切割”首部,然后再把每个部分分别加上首部。比如说,“切割”一个很长的数据包,我们先去除其首部,然后把剩下的数据部分切割成三片,在这三片前面分别加上合适的首部,使这三片各自单独成包。
在传输比较长的数据包的时候,可以这样“切割”成几片,但是到达数据接收方后,还要把这几片再重新组合起来,这就需要用到“标识、标志位、片偏移”这三个字段。
标识:此字段的作用是可以识别出哪些被“切割”的段能组装成一个数据包。举例:假设一个数据包的编号是101,那么由于这个数据包过长,需要“切割”成三片,那么切割后的这三片的各自的首部中的标识字段的值就全都是101,以表示这三片本来应该是在一起的,但后来被切割开了,接收端一看这三片数据包的标识都是一样的,就知道要把它们重新组合在一起。
标志位:此字段的长度是3位,每一位都有不同的作用,其中:第一位没意义,保留不用;第二位是DF位,全称“Don't Fragment”,意为“不能分片”,如果这个DF位的值为1,则表示此数据包是不允许分片的,所以这也就意味着如果一个数据包被“切割”了,那么切割成的所有“片”的DF位肯定都是0;第三位是MF位,全称“More Fragment”,意为“更多分片”,如果某个“分片”的MF位的值为1,则表示此分片不是最后一片,在后面还有更多的片,如果MF的值为0了,则表示这是最后一片,后面没有分片了。
片偏移:这个字段是用来确定出几个分片该按照什么顺序组合成原来的数据包的,片偏移的值指出了某个分片在原来数据包的相对位置,以8个字节为偏移单位。假设某个数据包被分了3片,那么每一片在原来数据包中的开始位置除以8,即为片偏移值。
谢希仁教授的教材上展示了一个非常经典的例子:
设一个IP数据包,编号为12345,总长度为3820字节(其中首部长20字节,数据部分3800字节),数据链路层的MTU值为1420字节。于是此数据包被分为3片:
第一片:数据部分长1400字节,加上20字节的首部,总长度为1420字节。标识应为12345,DF位应为0,MF位应为1,片偏移值应为0(因为第一片在原来数据包中的开始位置是第0字节,结束位置是第1399字节,我们用开始位置除以偏移单位,也就是0除以8,得到0)。
第二片:数据部分长1400字节,加上20字节的首部,总长度为1420字节。标识应为12345,DF位应为0,MF位应为1,片偏移值应为175(第二片的开始位置1400除以8,得175)。
第三片:数据部分长1000字节,加上20字节的首部,总长度为1020字节。标识应为12345,DF位应为0,MF位应为0,片偏移值应为350(第三片的开始位置2800除以8,得350)。
生存时间(TTL)
此字段是为了保证在网络出现环路的情况,不会让数据包在环路的几个路由器之间无限制的兜圈子而设定的,TTL值指出了一个数据包的“寿命”,每经过一个路由器,路由器都会把数据包的TTL值减1,当“寿命”减小到0的时候,此数据包将被丢弃。
例如设定一个TTL值为5的数据包,发送到网络中,而这时网络中的路由器R1、R2、R3之间出现了环路,此数据包就会在这三个路由器之间兜圈子,R1收到后,TTL值减1发送给R2,R2接过来又把TTL值减1发给R3,如此循环,直到此数据包的TTL值为0,最后收到的那个路由器就丢弃此数据包。
可见,如果不设置TTL这个字段,那么一旦网络出现环路,将会有大量数据包无限制的被循环转发,极大消耗网络带宽。
协议
此字段指明了IP协议的上层使用的是什么协议,一般就是传输层的TCP协议或者UDP协议,当然也有可能是不属于传输层但也位于IP协议之上的ICMP和IGMP协议等。
协议字段的值是上层各种协议的协议号,有几个知名的协议号是需要了解的:
ICMP协议号为1;IGMP协议号是2;TCP协议号是6,UDP协议号是17;OSPF协议号为89。
比如某个IP数据包的数据部分是传输层的TCP进程交付下来的,那么此数据包首部的协议字段的值即为6,如果是上层UDP协议交付下来的,那么协议字段的值即为17,如果数据部分承载的是ICMP的数据,那么协议字段的值即为1。
首部检验和
此字段的功能是对IP数据包的首部进行校验,数据包每经过一个路由器,路由器都会校验一遍首部检验和,如果检验出差错就把数据包丢弃掉(但一般情况下不会出差错)。具体是怎么检验的,我们不需要去关心,考试也涉及不到。
选项字段和填充
这两个字段的长度不是固定的,属于IP首部中的可变首部。选项字段具有支持测试、安全等扩展的功能。填充字段是为了保证IP首部一定是4个字节的整数倍而设置的,如果加入了选项之后,IP首部的长度不是4个字节的整数倍,那就要用全“0”填充到4个字节整数倍的长度。
本节的内容,很多,其中最主要的是理解“标识、标志位和片偏移”。IP数据包的结构我们就学习完了,下一节将学习一下路由器转发数据包的原理。
参考教材:谢希仁《计算机网络》第七版