【Spring】统一事件的处理(拦截器、统一异常处理、统一数据格式返回)
文章目录
- 前言
- 一、Spring 拦截器
-
- 1.1 用户登录权限校验案例
-
- 1.1.1 最初的用户登录验证
- 1.1.2 使用 Spring AOP 实现登录验证的问题
- 1.2 Spring 拦截器的使用
-
- 1.2.1 Spring 拦截器概念与使用步骤
- 1.2.2 使用拦截器实现对用户登录权限的校验
- 1.3 拦截器实现原理
- 1.4 Spring 拦截器和 Spring AOP 的区别
- 二、统一异常处理
-
- 2.1 为什么要统一异常处理
- 2.2 统一异常处理的使用
- 三、统一数据返回格式
-
- 3.1 为什么需要统一数据返回格式
- 3.2 统一数据返回格式的实现
- 3.3 针对 body 为 String 类型报错的问题
前言
在现代的 Web 应用程序开发中,往往需要处理用户权限、异常情况以及数据返回格式等诸多方面的问题。Spring 框架为我们提供了强大的工具和机制来应对这些挑战。本文将重点介绍 Spring 框架中的拦截器、统一异常处理以及统一数据返回格式等相关内容。
一、Spring 拦截器
在 Web 应用开发中,拦截器是一种非常有用的机制,它允许我们在请求处理的不同阶段执行一些特定的操作。这些操作可以是权限校验、日志记录、数据预处理等。下面将详细探讨 Spring 框架中的拦截器相关内容。
1.1 用户登录权限校验案例
首先介绍一个常见的应用案例:
- 用户登录权限校验。通常,在Web应用中,某些资源或功能需要登录后才能访问,因此需要对用户进行登录状态的验证。在没有拦截器的情况下,我们可能会使用传统的方式来实现这个验证逻辑。让我们来看一下最初的用户登录验证方法
1.1.1 最初的用户登录验证
在使用拦截器之间,我们先来回顾一下最开始使用用户登录验证的方法:
@RestController
public class UserController {
// 最开始实现用户登录权限验证的方式
@RequestMapping("/method1")
public Object method1(HttpServletRequest request){
// 获取Session,没有不创建
HttpSession session = request.getSession(false);
if(session == null || session.getAttribute("userinfo") == null){
// 没有获取到 session, 此时说明用户未登录
return false;
}
// 此时则说明已经登录了,执行后续业务逻辑
// ...
return true;
}
@RequestMapping("/method2")
public Object method2(HttpServletRequest request){
// 获取Session,没有不创建
HttpSession session = request.getSession(false);
if(session == null || session.getAttribute("userinfo") == null){
// 没有获取到 session, 此时说明用户未登录
return false;
}
// 此时则说明已经登录了,执行后续业务逻辑
// ...
return true;
}
// 其他方法...
}
当使用最初的方式在每个需要用户登录权限验证的方法中加入相同的登录验证逻辑时,会导致一些问题:
-
代码重复性: 需要在每个需要验证的方法中复制粘贴相同的验证代码,增加了代码冗余,不利于维护和修改。
-
可读性差: 多个方法中都包含相同的验证逻辑,使得代码可读性降低,难以快速理解每个方法的实际功能。
-
维护困难: 如果需要修改验证逻辑或者增加新的验证条件,需要在多个地方进行修改,容易出错。
-
代码耦合: 将验证逻辑直接嵌入到每个方法中,导致业务逻辑和验证逻辑紧密耦合在一起,不利于代码的解耦和单元测试。
-
扩展性差: 如果未来需要添加更多的验证逻辑,或者对验证逻辑进行定制化,需要修改多个方法,增加了工作量和风险。
1.1.2 使用 Spring AOP 实现登录验证的问题
面对上述的问题,就需要考虑使用统一的用户登录验证来解决了。一提到统一登录验证,我们可以会想到使用 Spring AOP 的面向切面编程来实现,但是其他却存在很大的问题,首先来回顾一下 Spring AOP 代码的实现:
// 创建一个切面(类)
@Aspect
@Component
public class UserAspect{
// 创建切点(方法)定义拦截规则
@Pointcut("execution(public * com.example.demo.controller.UserController.*(..))")
public void pointcut() {
}
// 前置通知
@Before("pointcut()")
public void doBefore() {
System.out.println("执行了前置通知:" + LocalDateTime.now());
}
// 后置通知
@After("pointcut()")
public void doAfter() {
System.out.println("执行了后置通知:" + LocalDateTime.now());
}
// 返回后通知
@AfterReturning("pointcut()")
public void doAfterReturning() {
System.out.println("执行了返回后通知:" + LocalDateTime.now());
}
// 抛异常后通知
@AfterThrowing("pointcut()")
public void doAfterThrowing() {
System.out.println("抛异常后通知:" + LocalDateTime.now());
}
// 环绕通知
@Around("pointcut()")
public Object doAround(ProceedingJoinPoint joinPoint) {
Object proceed = null;
System.out.println("Around 方法开始执行:" + LocalDateTime.now());
try {
// 执行拦截的方法
proceed = joinPoint.proceed();
} catch (Throwable e) {
e.printStackTrace();
}
System.out.println("Around 方法结束执行: " + LocalDateTime.now());
return proceed;
}
}
如果要使用上面 Spring AOP 的通知方法来实现用户登录验证,主要存在两个问题:
1. 获取 HttpSession 对象问题
- 在 AOP 中,通知(Advice)是在切点(Pointcut)匹配的连接点(Join Point)上执行的,然而,这些连接点都是方法级别的,不能直接提供对
HttpServletRequest或HttpSession等相关对象的访问。因此,在 AOP 切面中无法直接访问HttpSession对象。
2. 选择性拦截问题
- 在实际的应用程序中,我们可能只需要对部分功能进行登录权限验证,而
需要排除一些其他方法,比如用户的注册和登录。 - 使用基于方法名的
切点表达式则难以精确地实现这一目标,因为这可能会涉及到复杂的正则表达式匹配,而且如果有新的方法需要排除,就需要手动更新切点表达式。
为了解决这些问题,Spring 的拦截器机制更适合处理这类情况。拦截器可以访问 HttpServletRequest 和 HttpSession 等请求相关对象,也可以更方便地配置哪些路径需要被拦截,哪些不需要。
1.2 Spring 拦截器的使用
1.2.1 Spring 拦截器概念与使用步骤
Spring 拦截器是 Spring 框架中的一种拦截机制,用于在请求进入控制器前后执行的特定的操作。拦截器可以用于实现登录权限校验、日志记录、数据预处理等功能。拦截器使用面向切向编程(AOP)的思想,可以在请求的不同阶段插入自己的逻辑,从而实现各种功能。
下面是使用 Spring 拦截器的一般步骤:
1. 创建拦截器类
首先,创建一个类来实现 Spring 的 HandlerInterceptor接口,并重写其中的方法。通常包括下面这三种方法:
preHandle:在请求处理之前执行,可以用于权限校验等操作。如果返回false则中断请求处理。postHandle:在请求处理之后执行,但在视图渲染之前执行。可以进行日志记录等操作。afterCompletion:在视图渲染之后执行,可以进行一些资源清理等操作。
2. 添加并配置拦截器
在 Spring Boot 中配置添加拦截器大致可以分为以下两步:
1)将创建的拦截器类添加到 Spring 容器中: 在 Spring Boot 中,可以使用 @Component 注解来标记创建的拦截器类,将其交由 Spring 容器管理。这样,Spring Boot 会自动扫描并将这个拦截器类纳入到应用的上下文中。
例如,在拦截器类上添加 @Component 注解,如下所示:
import org.springframework.stereotype.Component;
@Component
public class AuthInterceptor implements HandlerInterceptor {
// 拦截器的具体实现
}
2)实现 WebMvcConfigurer 接口并重写 addInterceptors 方法来添加拦截器到系统配置: 在 Spring Boot 中,可以通过实现 WebMvcConfigurer 接口,重写其中的 addInterceptors 方法来添加拦截器。这个方法会将创建的拦截器添加到系统中,使其在请求被处理时生效。
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Autowired
private AuthInterceptor authInterceptor; // 注入你的拦截器类
@Override
public void addInterceptors(InterceptorRegistry registry) {
// 添加拦截器,并指定拦截的路径
registry.addInterceptor(authInterceptor)
.addPathPatterns("/**")
.excludePathPatterns("/user/login")
.excludePathPatterns("/user/reg")
;
}
}
上述代码中,addInterceptors 方法会将拦截器类 authInterceptor 添加到系统配置中,并通过 addPathPatterns 指定要拦截的路径,然后可以使用excludePathPatterns方法来指定放弃拦截的指定接口,如登录、注册功能。这样,当程序运行时,配置好的拦截器就会自动生效。
3. 配置拦截器顺序
如果同时使用了多个拦截器,可以通过配置来定义它们的执行顺序。在 Spring MVC 中,拦截器的执行顺序与它们在配置文件中声明的顺序一致。
4. 使用拦截器
配置好拦截器后,它们会在请求被处理之前、之后或之后的渲染阶段执行相应的逻辑。这样就可以在拦截器中实现所需的功能,如权限校验、日志记录等。
1.2.2 使用拦截器实现对用户登录权限的校验
1. 创建用户登录验证的拦截器:
/**
* Spring MVC拦截器(LoginInterceptor),用于检查用户是否已登录。
* 如果用户未登录,则重定向到登录页面。
*/
@Component
public class LoginInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 判断用户登录
HttpSession session = request.getSession(false); // 默认值是true
if (session != null && session.getAttribute(ApplicationVariable.SESSION_KEY_USERINFO) != null) {
// 用户已经登录了
return true;
}
// 当代码执行到此次,表示用户未登录
response.sendRedirect("/login.html");
return false;
}
}
2. 添加并配置拦截规则
/**
* 配置拦截规则
*/
@Configuration
public class MyConfig implements WebMvcConfigurer {
@Autowired
private LoginInterceptor loginInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(loginInterceptor)
.addPathPatterns("/**") // 拦截所有的 url
// 放开拦截的内容
.excludePathPatterns("/**/*.js")
.excludePathPatterns("/**/*.css")
.excludePathPatterns("/**/*.jpg")
.excludePathPatterns("/login.html")
.excludePathPatterns("/user/reg")
.excludePathPatterns("/user/login")
// ...
;
}
}
1.3 拦截器实现原理
拦截器的实现原理涉及到 Spring 框架的核心概念:面向切面编程(AOP)。在 AOP 的帮助下,拦截器可以被织入到方法调用链中,从而在请求处理的不同阶段执行相应的操作。下面将介绍拦截器的实现原理和工作流程。
1. AOP 概念回顾
AOP 是一种编程范式,旨在解决横切关注点(Cross-cutting Concerns)的问题。它通过将横切关注点与主要业务逻辑分离,使得我们能够更好地管理和维护代码。在 Spring 中,AOP 是通过代理模式和动态代理来实现的。
在 AOP 中,有两个重要的概念:切点(Pointcut)和通知(Advice)。
-
切点(Pointcut): 切点定义了在哪些连接点(Join Point)上应用通知。连接点可以是方法调用、方法执行、字段访问等等。切点使用表达式来匹配连接点,以确定哪些连接点会被通知所影响。
-
通知(Advice): 通知定义了在切点处执行的代码。在 Spring 中,有多种类型的通知,包括前置通知(在方法调用之前执行)、后置通知(在方法调用之后执行)、环绕通知(在方法调用前后执行)、异常通知(在方法抛出异常时执行)、最终通知(在方法调用结束后执行)。
2. 拦截器的工作流程
拦截器实际上是一种 AOP 的应用,通过 AOP 的方式实现对请求处理过程的干预。以下是拦截器的工作流程:
-
当请求到达 DispatcherServlet(前端控制器)时,拦截器首先会根据配置的拦截规则(切点)来判断是否要拦截该请求。
-
如果拦截器决定要拦截该请求,它会在切点前执行通知的逻辑,比如前置通知。这样,拦截器可以在请求处理之前执行一些预处理操作,如权限校验、日志记录等。
-
接下来,请求会继续被传递到相应的控制器进行处理。拦截器不会中断请求的流程,只是在处理前插入了自己的逻辑。
-
当控制器处理完请求后,拦截器会再次执行通知的逻辑,比如后置通知。这样,拦截器可以在请求处理之后执行一些后续操作,如数据封装、日志记录等。
-
最终,拦截器会在切点后执行通知的逻辑,比如最终通知。这样,拦截器可以在请求处理结束后执行一些清理操作。
通过拦截器,我们可以实现对请求处理过程中不同阶段的干预,从而达到一些横切关注点的处理。这种机制使得我们能够更好地管理和维护代码,提高了代码的可维护性和重用性。
1.4 Spring 拦截器和 Spring AOP 的区别
Spring 拦截器(Interceptor)和 Spring AOP(面向切面编程)是两种在 Spring 框架中用于处理横切关注点的机制,它们有些相似,但也有一些关键的区别。以下是它们之间的主要区别:
1. 目标领域不同
-
Spring 拦截器: 主要用于处理 Web 请求。它在请求处理的不同阶段执行特定的操作,如权限校验、日志记录等。拦截器主要关注于对 Web 请求的处理流程进行干预,以及在请求前后插入自定义的逻辑。
-
Spring AOP: 用于处理应用程序中的横切关注点,不仅限于 Web 请求。AOP 可以在方法调用、方法执行、字段访问等不同连接点上执行通知,从而实现一些与主要业务逻辑解耦的功能,如事务管理、性能监控等。
2. 应用范围不同
-
Spring 拦截器: 主要应用于 Web 层,处理 Web 请求。它可以控制请求的处理流程,但只作用于 Web 层,不会影响到业务层的方法调用。
-
Spring AOP: 可以应用于多个层面,包括业务层、持久层、Web 层等。AOP 可以跨足不同的层面,通过拦截连接点实现对不同层之间的通用关注点的处理。
3. 处理方式不同
-
Spring 拦截器: 拦截器是基于 Java 动态代理的机制,它通过织入在请求处理流程中的方式来实现对请求的干预。拦截器主要关注于请求处理的前后环节,可以进行预处理、后处理、资源释放等操作。
-
Spring AOP: AOP 是通过代理模式来实现的,可以使用 JDK 动态代理或者 CGLIB 来生成代理对象。AOP 可以在方法调用前后、异常抛出时、方法执行结束等连接点上执行通知,从而实现不同类型的横切关注点。
4. 原理和灵活性
-
Spring 拦截器: 拦截器是一种 Spring MVC 提供的机制,更加针对 Web 层的处理。它具有一定的灵活性,但在处理跨层面的通用关注点时相对较为有限。
-
Spring AOP: AOP 是 Spring 框架的核心特性之一,可以在多个层面应用,包括对方法调用、字段访问等各种连接点的处理。AOP 更具通用性,适用于处理各种横切关注点。
总之,Spring 拦截器和 Spring AOP 都是用于处理横切关注点的重要机制,但在应用范围、处理方式和灵活性等方面存在一些区别。选择合适的机制取决于实际需求以及在哪个层面需要处理横切关注点。
二、统一异常处理
2.1 为什么要统一异常处理
在开发过程中,应用程序难免会遇到各种异常情况,如数据库连接失败、空指针异常等。为了提供更好的用户体验和更好的错误信息管理,采用统一异常处理机制是很有必要的。以下是为什么要采用统一异常处理的一些原因:
-
友好的用户体验: 统一异常处理可以捕获各种异常,并返回统一的错误响应。这样,用户可以获得更友好、更易于理解的错误提示,而不会直接暴露应用程序内部的错误细节。
-
减少代码重复性: 在应用程序中,同一类型的异常可能会在多个地方发生。通过统一异常处理,可以将相同的错误处理逻辑抽取到一个地方,减少代码的重复性,提高代码的可维护性。
-
集中式错误管理: 统一异常处理可以将错误信息集中管理,方便进行日志记录、监控和错误分析。这有助于快速定位问题,提高应用程序的稳定性。
2.2 统一异常处理的使用
在 Spring 框架中,可以使用 @ControllerAdvice 和 @ExceptionHandler 注解来实现统一异常处理。
步骤如下:
-
创建一个异常处理类,并使用
@ControllerAdvice注解标记该类,表示它是一个控制器通知类,用于处理全局的异常情况。 -
在异常处理类中,使用
@ExceptionHandler注解定义异常处理方法。可以针对不同类型的异常编写不同的处理方法,或者使用一个通用的方法处理所有异常。 -
在异常处理方法中,可以自定义错误信息,构建错误响应,并返回适当的视图或 JSON 响应。
以下是一个示例代码,展示了如何使用统一异常处理:
/**
* 统一异常处理
*/
@ControllerAdvice
@ResponseBody
public class MyExceptionAdvice {
/**
* 处理空指针异常
* @param e
* @return
*/
@ExceptionHandler(NullPointerException.class)
public HashMap<String, Object> doNullPointerException(NullPointerException e){
HashMap<String, Object> result = new HashMap<>();
result.put("code", -300);
result.put("msg", "空指针: " + e.getMessage());
result.put("data", null);
return result;
}
/**
* 默认异常处理(当具体的异常处匹配不到时,会执行此方法)
* @param e
* @return
*/
@ExceptionHandler(Exception.class)
public HashMap<String, Object> doException(Exception e){
HashMap<String, Object> result = new HashMap<>();
result.put("code", -300);
result.put("msg", "Exception: " + e.getMessage());
result.put("data", null);
return result;
}
}
在这个代码示例中,创建了一个名为 MyExceptionAdvice 的全局异常处理类,通过 @ControllerAdvice 注解来标记它。这个类中包含了两个异常处理方法:
-
doNullPointerException方法,用于处理空指针异常(NullPointerException)。当应用程序抛出空指针异常时,这个方法会被调用,然后构建一个包含错误信息的HashMap并返回。 -
doException方法,用于处理其他类型的异常。如果应用程序抛出的异常类型不匹配前面定义的处理方法,就会执行这个默认异常处理方法。它也会构建一个错误响应并返回。
通过这样的方式,实现了针对不同类型异常的定制处理,提供了统一的错误响应格式,从而提升了用户体验和代码的可维护性。
三、统一数据返回格式
3.1 为什么需要统一数据返回格式
在开发中,不同接口可能返回不同的数据格式,这可能导致前端处理数据时需要根据不同接口的返回格式进行不同的处理逻辑,增加了代码的复杂性和维护成本。为了简化前端处理逻辑,提高代码的可维护性,可以考虑统一数据返回格式。
统一数据返回格式的优点包括:
-
减少前端逻辑复杂性: 前端不需要针对不同接口编写不同的处理逻辑,可以统一处理数据格式,降低代码复杂性。
-
提高前后端协作效率: 前后端通过明确的数据格式约定,可以更快地进行接口开发和联调,减少沟通成本。
-
规范错误处理: 统一的数据返回格式可以规范错误处理方式,使得前端可以更方便地判断请求是否成功,以及获取错误信息。
3.2 统一数据返回格式的实现
在实现统一数据格式返回的时候,主要借助 Spring 框架提供的 ResponseBodyAdvice 接口和@ControllerAdvice注解,并且需要重写接口中的supports和beforeBodyWrite方法,其中supports方法表示是否要使用统一数据格式返回,而beforeBodyWrite则是实现对数据格式的统一。
以下是一个示例,展示了如何实现统一数据返回格式,其中规定返回的数据格式为:
{
"cede":code,
"msg":msg,
"data":data
}
在返回的时候可以使用HashMap来组织。下面是具体的实现代码:
/**
* 统一数据格式处理
*/
@ControllerAdvice
public class ResponseAdvice implements ResponseBodyAdvice {
@Autowired
private ObjectMapper objectMapper;
@Override
public boolean supports(MethodParameter returnType, Class converterType) {
return true;
}
/**
* 返回数据之前进行处理
*/
@SneakyThrows
@Override
public Object beforeBodyWrite(Object body, MethodParameter returnType, MediaType selectedContentType, Class selectedConverterType, ServerHttpRequest request, ServerHttpResponse response) {
//规定标准格式为:HashMap -> code,msg.data
if (body instanceof HashMap) {
// 如果已经是标准格式
return body;
}
// 重写返回结果,让其返回一个统一的数据格式
HashMap<String, Object> result = new HashMap<>();
result.put("code", 200);
result.put("data", body);
result.put("msg", "");
return result;
}
}
上述示例代码很清晰地演示了如何使用 @ControllerAdvice 注解和 ResponseBodyAdvice 接口来实现统一数据返回格式。通过重写 supports 和 beforeBodyWrite 方法,实现了对返回数据格式的统一处理。
在这个示例中,规定了统一的数据格式,即返回的 JSON 包含了 “code”、“msg” 和 “data” 字段。如果返回的数据已经是标准格式(HashMap),则直接返回;否则,就构建一个标准格式的返回对象,并将原始数据放入其中。
3.3 针对 body 为 String 类型报错的问题
当针对处理基本数据类型的时候,例如:
@RestController
@RequestMapping("/user")
public class UserController {
@RequestMapping("/login")
public int login() {
return 1;
}
}
浏览器访问结果:
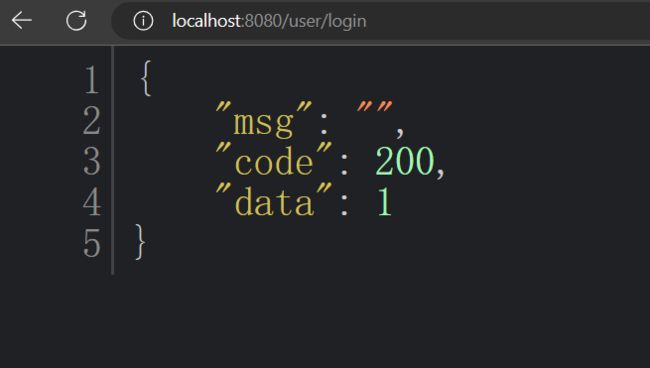
此时发现没有任何问题,并且成功实现了对数据格式的统一返回。但是如果返回的是 String 类型呢?
@RestController
@RequestMapping("/user")
public class UserController {
@RequestMapping("/hello")
public String hello(){
return "hello world";
}
}
再次通过浏览器访问:
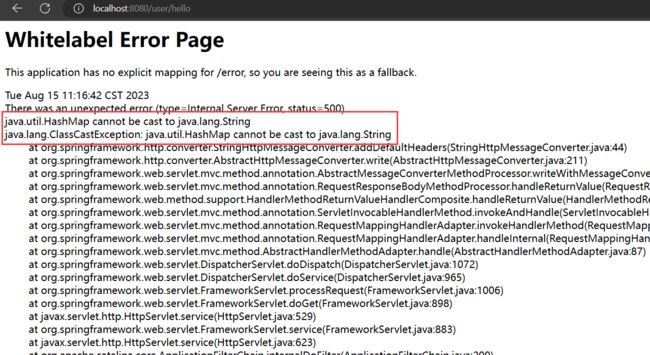
1. 返回 String 类型出错原因分析:
其报错的内容大致是HashMap类型不能够转换成String类型。为什么会这样呢?首先需要了解数据在返回过程中的执行流程:
- 控制器方法返回 String 类型;
- 针对于 String 类型进行统一数据格式处理,即把为 String 类型的
body作为value设置到key为data的HashMap中; - 将
HashMap转换成application/json字符串并通过网络传输给前端。
值得注意的是:
- 其中,如果
body的类型如果是 String 类型,则会使用StringHttpMessageConverter进行类型的转换;- 否则使用
HttpMessageConverter进行类型转换。
但是使用针对于第三步,由于 body 是 String 类型的,因此使用的是StringHttpMessageConverter类,它只能够将 String 类型数据转换为 JSON 字符串,如果转换 HashMap 就会出错。
2. 解决方法:
解决方法大致可以分为两种:
- 解决方法一: 如果
body类型是 String,就直接返回 String 类型,其中可以使用字符串拼接,也可以使用jackson中的ObjectMapper进行转换成 JSON 格式。
1)拼接形成 String 进行返回:
@SneakyThrows
@Override
public Object beforeBodyWrite(Object body, MethodParameter returnType, MediaType selectedContentType, Class selectedConverterType, ServerHttpRequest request, ServerHttpResponse response) {
if (body instanceof String) {
// 返回一个 String 字符串
return "{\"code\" : 200, \"msg\": \"\", \"data\":\"" + body + "\"}";
}
if (body instanceof HashMap) {
// 如果已经是标准格式
return body;
}
// 重写返回结果,让其返回一个统一的数据格式
HashMap<String, Object> result = new HashMap<>();
result.put("code", 200);
result.put("data", body);
result.put("msg", "");
return result;
}
2)使用 jackson 中的 ObjectMapper:
@SneakyThrows
@Override
public Object beforeBodyWrite(Object body, MethodParameter returnType, MediaType selectedContentType, Class selectedConverterType, ServerHttpRequest request, ServerHttpResponse response) {
if (body instanceof HashMap) {
// 如果已经是标准格式
return body;
}
// 重写返回结果,让其返回一个统一的数据格式
HashMap<String, Object> result = new HashMap<>();
result.put("code", 200);
result.put("data", body);
result.put("msg", "");
if(body instanceof String){
// 返回一个 String 字符串
return objectMapper.writeValueAsString(result);
}
return result;
}
2. 解决方法二: 直接禁用 StringHttpMessageConverter 类。
可以在配置类中通过重写 configureMessageConverters 方法来实现禁用 StringHttpMessageConverter:
@Configuration
public class MyConfig implements WebMvcConfigurer {
/**
* 移除 StringHttpMessageConverter
* @param converters
*/
@Override
public void configureMessageConverters(List<HttpMessageConverter<?>> converters) {
converters.removeIf(converter -> converter instanceof StringHttpMessageConverter);
}
}
其中,converter -> converter instanceof StringHttpMessageConverter 是一个 Lambda 表达式,用于检查 converter 是否是 StringHttpMessageConverter 的实例。如果是,则移除该实例。
当选择任意一个解决方法之后,再次访问返回 String 类型的控制器方法,其结果如下:

此时便能够正确返回统一的数据格式了。