JVM - 垃圾收集器
目录
垃圾收集器
串行垃圾收集器
并行垃圾收集器
什么是 吞吐量优先 什么是 响应时间优先 ?
CMS(并发)垃圾收集器
G1 垃圾收集器
垃圾收集器
垃圾收集器大概可以分为:
- 串行垃圾收集器
- 并行垃圾收集器
- CMS(并发)垃圾收集器
- G1垃圾收集器
串行垃圾收集器
Serial 和 Serial Old 是 串行垃圾收集器
使用单线程回收,因此就适用于堆内存较小,CPU数量少的(因为多了也没用)个人电脑
开启串行垃圾收集器的VM参数是:-XX:+UseSerialGC = Serial + SerialOld
Serial 垃圾收集器工作在新生代,采用 标记-复制 算法
SerialOld 垃圾收集器工作在老年代,采用 标记-整理 算法
工作流程如下:
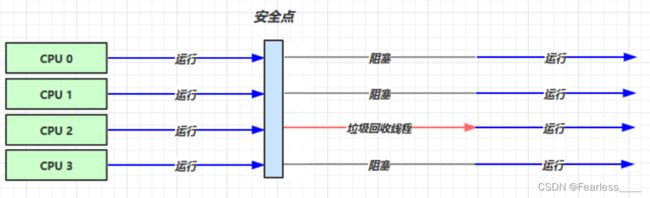
从上图我们看到,在串行垃圾收集器的回收过程中,进程中的其他应用线程需要暂停,也叫 Stop The World(简称 STW)
为什么需要STW?
因为在垃圾回收的工程中,有些对象的地址是会发生改变的,如果垃圾回收的过程中用户线程还在工作,那用户线程就有可能找不到对象, 从而产生错误,因此在垃圾回收器进行回收的过程中,其他用户线程都要阻塞
并行垃圾收集器
并行垃圾收集器即 Parallel New 和 Parallel Old
并行垃圾收集器是 吞吐量优先 的垃圾收集器
什么是 吞吐量优先 什么是 响应时间优先 ?
吞吐量优先
使用多线程回收,适用于堆内存较大,CPU较多的场景(如果是CPU个数较少,比如单核CPU,会导致回收线程之间相互争抢CPU的时间片,导致线程上下文切换的时间浪费,效率反而会比串行的垃圾回收器低),适合工作在服务器上
吞吐量优先的目标是:在单位时间内,让Stop The World(以下简称STW)的时间最短
响应时间优先
同样也是多线程回收,同样适用于堆内存较大,CPU较多的场景,同样适合工作在服务器上
响应时间优先的目标是:让单次的STW的时间最短
一个例子区分 吞吐量优先 和 响应时间优先:
在一个单位时间内,吞吐量优先追求 0.5 + 0.5 = 1,吞吐量不在乎 0.5 很大,只在乎 1 最小,而响应时间优先追求 0.3 + 0.3 + 0.3 +0.3 +0.3 =1.5 ,响应时间优先不在乎1.5很大,只在乎 0.3 最小
开启并行的垃圾收集器的参数是:-XX:+UseParallelGC ~ -XX:+UseParallelOldGC
ParallelGC 垃圾收集器工作在新生代中,采用 标记-复制 算法
ParallelOldGC 垃圾收集器工作在老年代中,采用 标记-整理 算法
在 jdk 1.8 中默认使用的就是 ParallelGC,而这两个开关是一同开启的,也就是开启 ParallelGC会连同开启ParallelOldGC
Parallel 就是并行的意思,说明这些垃圾回收线程是并行执行的
工作流程如下:
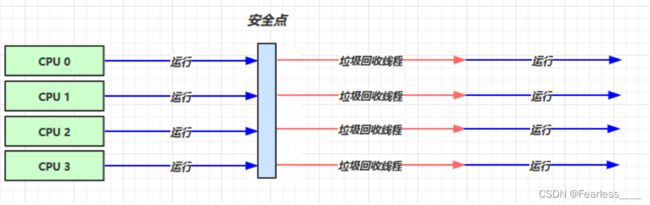
通过参数 -XX:ParallelGCThreads=n 可以设置垃圾回收线程的数量
除此之外还有三个比较重要的参数:
-XX:+UseAdaptiveSizePolicy :采用自适应的大小调整策略,会动态的调整 Eden 和 Survivor 的比例,还会调整堆的大小、老年代的晋升阈值等
-XX:GCTimeRatio=ratio : 用于调整垃圾回收的时间在总工作时间中的占比,计算公式为 1/(1+ratio),如果达不到设置的时间占比,ParallelGC就会尝试调大堆的大小,因为堆的容量较大,GC的次数就会比较少,ratio的值默认为99,但是 1/100 的占比时间很难达到,因此我们正常将 ratio 设置为19
-XX:MaxGCPauseMillis=ms : 单次垃圾回收的最大时间,默认值200ms,于 -XX:GCTimeRatio 参数存在冲突,因为 -XX:GCTimeRatio 可能为了达到目标,而调大堆的大小,而且堆越大,单次垃圾回收的时间就越长
CMS(并发)垃圾收集器
CMS全称 Concurrent Mark Sweep,是一款并发的、使用 标记-清除 算法的垃圾回收器
该回收器是针对老年代垃圾回收的,是一款 响应时间优先 的收集器,停顿时间短,用户体验就好
其最大特点是在进行垃圾回收时,应用仍然能正常运行
开启 CMS垃圾收集器 的参数:-XX:+UseConcMarkSweepGC ~ -XX:+UseParNewGC ~ SerialOld
ConcMarkSweepGC 可能会存在并发失败的问题,如果出现并发失败,那 ConcMarkSweepGC 就会退化成 SerialOldGC
工作流程如下:
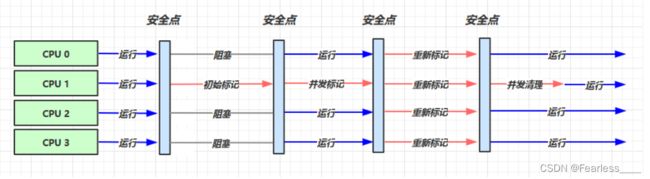
从上面我们可以看到,只有 初始标记 和 重新标记 阶段需要STW,而这两阶段的时间又非常短,因此能达到更好的响应时间
在初始标记阶段,只会标记出跟GC Roots直接相连的对象,在并发标记时,再去标记完整个引用链,因为并发标记的过程中,应用线程仍在运行,所以可能产生出新的垃圾对象,因此需要最后STW去重新标记一遍,标记出新产生的垃圾对象
G1 垃圾收集器
G1(Garbage First)是 JDK 9 之后默认的垃圾收集器,同时注重吞吐量和低延迟
适用于超大的堆内存,其工作原理是将堆划分为多个大小相等的 Region ,此时就没有了新生代和老年代的比例一说,因为每个 Region 都可以单独作为 Eden、Survivor、老年代
G1采用 标记 - 复制 算法
如果在 JDK 1.8 中使用G1,需要设置VM参数:-XX:+UseG1GC
工作流程如下:
初始状态下,会将几块 Region 划分为 Eden ,G1垃圾收集器中新生代的占比只有 5% - 6% ,当Eden中的对象过多时,就会进行垃圾回收
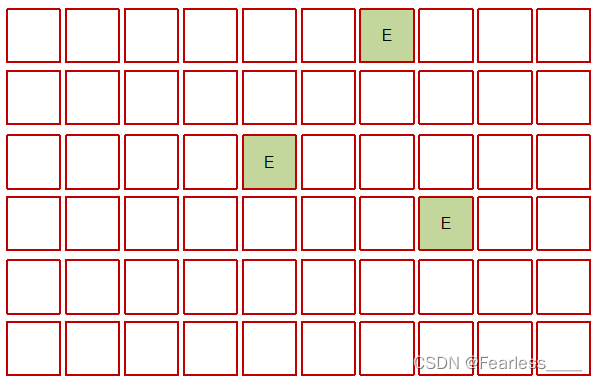
垃圾回收采用 标记 - 复制 算法,将 Eden 中幸存的对象复制到 Survivor,并清空Eden,该过程需要STW,但因为幸存的对象是比较少的,所以STW的时间很短
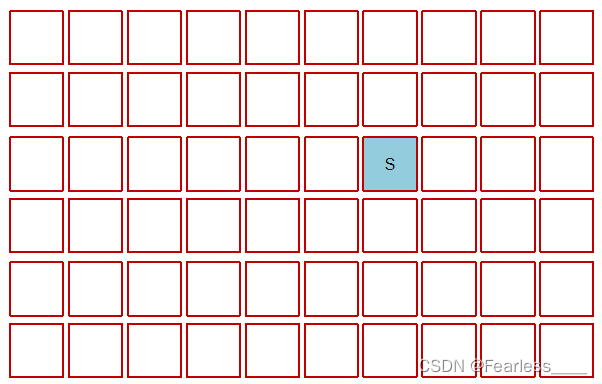
接下来,又产生多个新对象
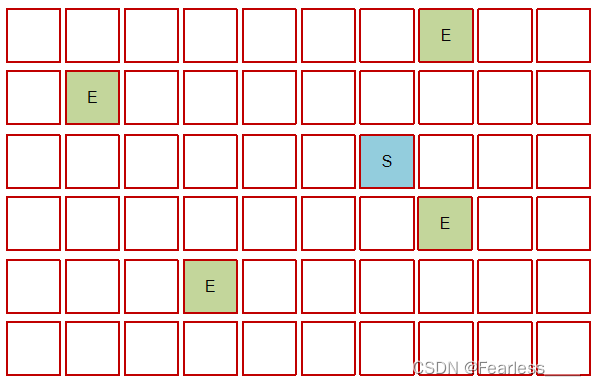
再次进行新生代的垃圾回收,Eden中和上一个Survivor中幸存的对象会被复制到新的Survivor中,但上一个Survivor中幸存的对象如果年龄超过晋升阈值,会直接进入老年代中
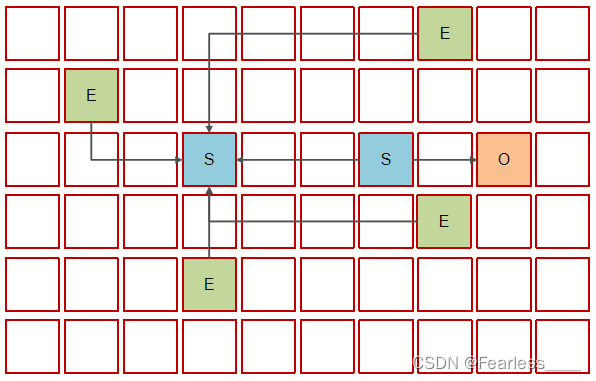
最后变成

当老年代占用的内存超过一定阈值(默认45%)后,需进行老年代的垃圾回收,该过程会先进行并发标记,标记出老年代中存活的对象,并发标记过程无需暂停应用线程,并发标记结束后需再进行重新标记(和CMS原理相同,需标记处并发标记过程中新产生的垃圾对象),这个过程需暂停应用线程,但是时间很短
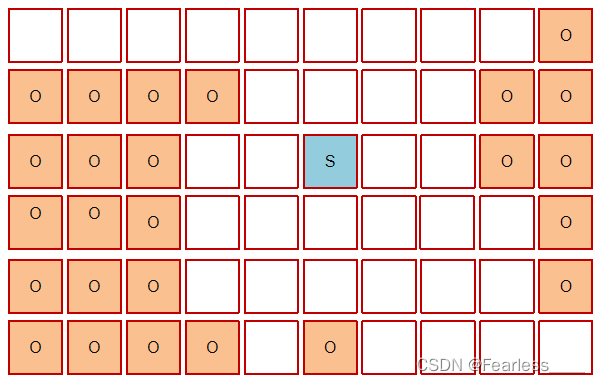
之后进入混合收集阶段,此时不会对所有老年代区域进行回收,而是根据暂停时间目标优先回收价值高(存活对象少)的区域(这也是 Gabage First 名称的由来),比如下图中标红的老年代
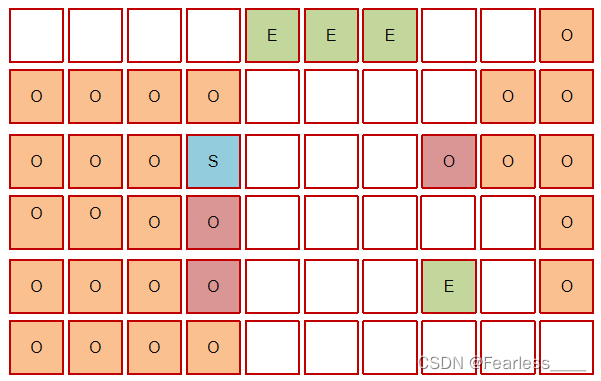
混合收集 就是连同 Eden 、Survivor 、老年代 进行一次垃圾回收,Eden 、Survivor 的回收过程和上面相同,老年代的回收是新开一个老年代,将三个标红的老年代,还有Survivor中年龄到达阈值的存活对象复制到新的老年代中
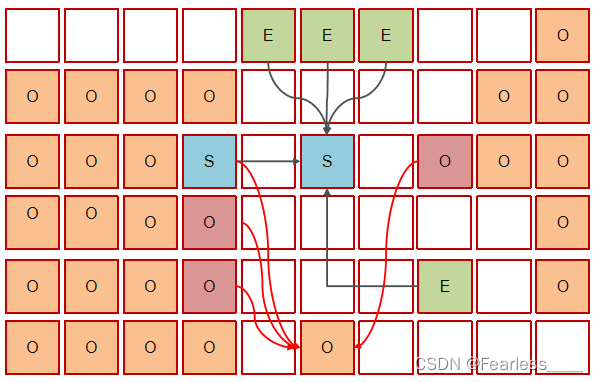
最后变成如下结果