Prompt、RAG、微调还是重新训练?如何选择正确的生成式AI的使用方法
生成式人工智能正在快速发展,许多人正在尝试使用这项技术来解决他们的业务问题。一般情况下有4种常见的使用方法:
- Prompt Engineering
- Retrieval Augmented Generation (RAG 检索增强生成)
- 微调
- 从头开始训练基础模型(FM)
本文将试图根据一些常见的可量化指标,为选择正确的生成式人工智能方法提供建议。
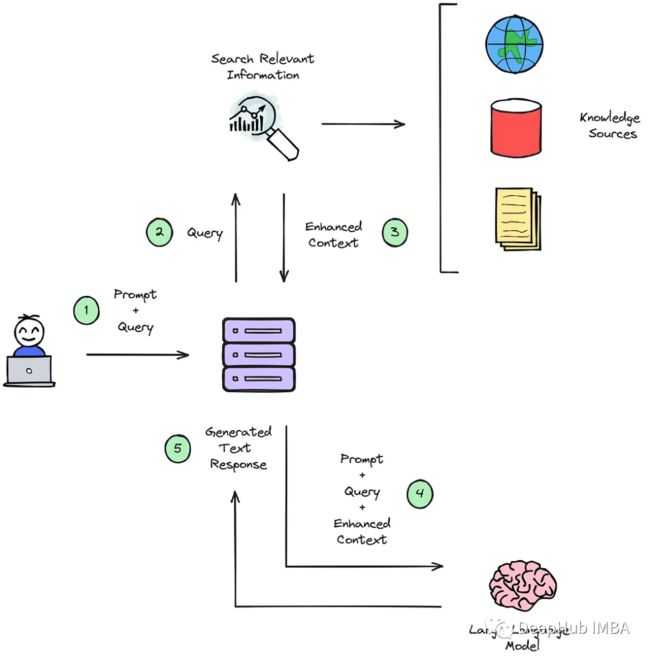
本文不包括“使用原模型”的选项,因为几乎没有任何业务用例可以有效地使用基础模型。按原样使用基础模型可以很好地用于一般搜索,但对于任何特定的用力,则需要使用上面提到的选项之一。
如何执行比较?
基于以下指标:
- 准确性(回答有多准确?)
- 实现复杂性(实现可以有多复杂?)
- 投入工作量(需要多少工作的投入来实现?)
- 总成本(拥有解决方案的总成本是多少?)
- 灵活性(架构的耦合有多松?更换/升级组件有多容易?)
我们将对这些度量标准上的每个解决方案方法进行评级,进行一个简单的对比。
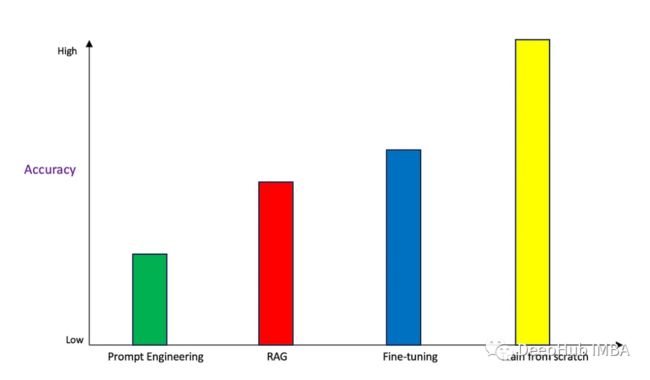
准确性
让我们首先得到讨论最总要的一点:哪种方法提供最准确的响应?
Prompt Engineering就是通过提供少量示例提供尽可能多的上下文,以使基础模型更好地了解用例。虽然单独来看,结果可能令人印象深刻,但与其他方法相比,它产生的结果最不准确。
RAG产生了高质量的结果,因为它增加了直接来自向量化信息存储的特定于用例的上下文。与Prompt Engineering相比,它产生的结果大大改善,而且产生幻觉的可能性非常低。
微调也提供了相当精确的结果,输出的质量与RAG相当。因为我们是在特定领域的数据上更新模型权重,模型产生更多的上下文响应。与RAG相比,质量可能稍微好一些,但这取决于具体实例。所以评估是否值得花时间在两者之间进行权衡分析是很重要的。一般来说,选择微调可能有不同的原因,而不仅仅是精度。还包括数据更改的频率、在自己的环境中控制模型实现法规、遵从性和可再现性等目的等等。
从头开始的训练产生了最高质量的结果(这是肯定的)。由于模型是在用例特定数据上从零开始训练的,所以产生幻觉的几率几乎为零,输出的准确率也是比较中最高的。
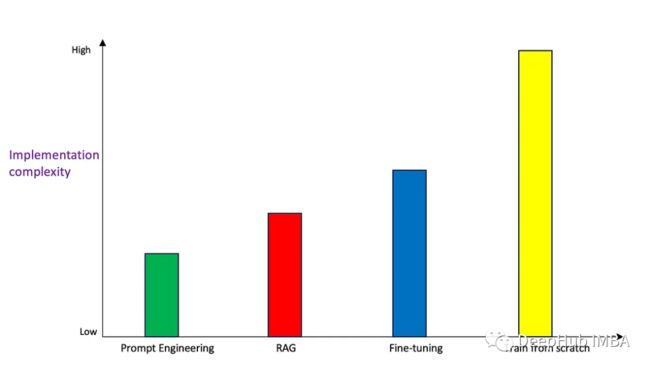
实现的复杂性
除了准确性以外,另外一个需要关注的就是实现这些方法的难易程度。
Prompt Engineering具有相当低的实现复杂性,因为它几乎不需要编程。需要具备良好的英语(或其他)语言技能和领域专业知识,可以使用上下文学习方法和少样本学习方法来创建一个好的提示。
RAG比Prompt Engineering具有更高的复杂性,因为需要编码和架构技能来实现此解决方案。根据在RAG体系结构中选择的工具,复杂性可能更高。
微调比上面提到的两个更复杂,因为模型的权重/参数是通过调优脚本更改的,这需要数据科学和ML专业知识。
从头开始训练肯定具有最高的实现复杂性,因为它需要大量的数据管理和处理,并且训练一个相当大的模型,这需要深入的数据科学和ML专业知识。
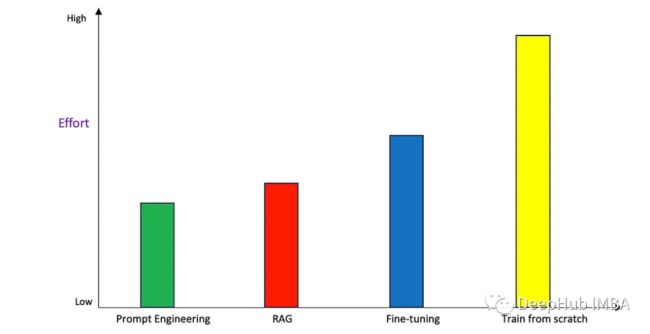
工作量投入
实现的复杂性和工作量并不总是成正比的。
Prompt Engineering需要大量的迭代努力才能做到正确。基础模型对提示的措辞非常敏感,改变一个词甚至一个动词有时会产生完全不同的反应。所以需要相当多的迭代才能使其适用于相应的需求。
由于涉及到创建嵌入和设置矢量存储的任务,RAG也需要很多的工作量,比Prompt Engineering要高一些。
微调则比前两个要更加费力。虽然微调可以用很少的数据完成(在某些情况下甚至大约或少于30个示例),但是设置微调并获得正确的可调参数值需要时间。
从头开始训练是所有方法中最费力的方法。它需要大量的迭代开发来获得具有正确技术和业务结果的最佳模型。这个过程从收集和管理数据开始,设计模型体系结构,并使用不同的建模方法进行实验,以获得特定用例的最佳模型。这个过程可能会很长(几周到几个月)。
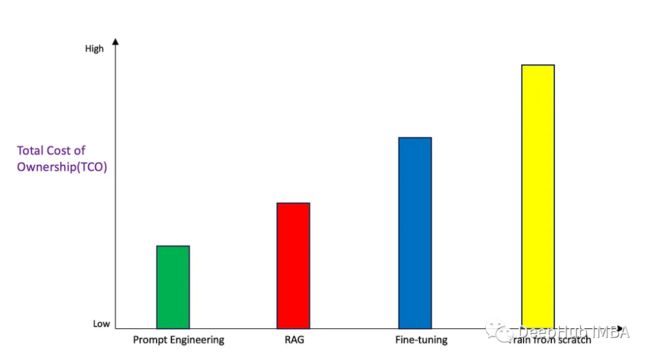
总成本
我们讨论的不仅仅是服务/组件花费,而是完全实现解决方案的成本,其中包括熟练工程师(人员),用于构建和维护解决方案的时间,其他任务的成本,如自己维护基础设施,执行升级和更新的停机时间,建立支持渠道,招聘,提高技能和其他杂项成本。
Prompt Engineering的成本是相当低的,因为需要维护的只是提示模板,并在基础模型版本更新或新模型发布时时保持它们的最新状态即可。除此之外,托管模型或通过API直接使用还会有一些而额外的成本。
由于架构中涉及多个组件,RAG 的成本要比Prompt Engineering略高。这取决于所使用的嵌入模型、向量存储和模型。因为在这里需要为3个不同的组件付费。
微调的成本肯定要高于前两个,因为调整的是一个需要强大计算能力的模型,并且需要深入的ML技能和对模型体系结构的理解。并且维护这种解决方案的成本也会更高,因为每次有基本模型版本更新或新数据批次进入时都需要调优。
从头开始训练无疑是成本最高的,因为团队必须拥有端到端数据处理和ML训练、调优和部署能力。这需要一群高技能的机器学习从业者来完成。维护这种解决方案的成本非常高,因为需要频繁的重新训练周期来保持模型与用例周围的新信息保持同步。
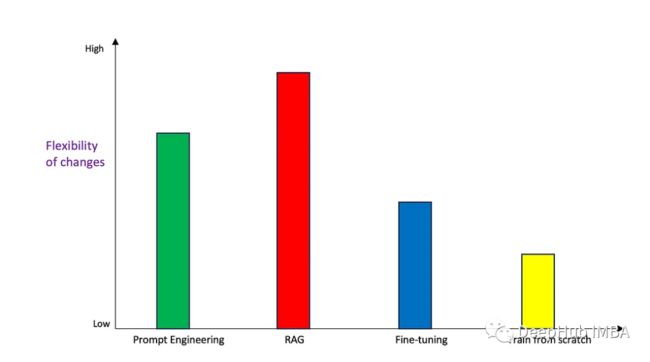
灵活性
我们来看看在简化更新和更改方面的是什么情况
Prompt Engineering具有非常高的灵活性,因为只需要根据基础模型和用例的变化更改提示模板。
当涉及到架构中的更改时,RAG也具很最高程度的灵活性。可以独立地更改嵌入模型、向量存储和LLM,而对其他组件的影响最小。它还可以在不影响其他组件的情况下在复杂授权等流程中添加更多组件。
微调对更改的灵活性非常低,因为数据和输入的任何更改都需要另一个微调周期,这可能非常复杂且耗时。同样,将相同的微调模型调整到不同的用例也需要很多的工作,因为相同的模型权重/参数在其他领域的表现可能比它所调整的领域差。
从头开始训练的灵活性最低的。因为模型是从头构建的,对模型执行更新会触发另一个完整的重新训练周期。我们也可以微调模型,而不是从头开始重新训练,但准确性会有所不同。
总结
从以上所有的比较中可以明显看出,没有明显的输赢。因为最终的选择取决于设计解决方案时最重要的指标是什么,我们的建议如下:
当希望在更改模型和提示模板方面具有更高的灵活性,并且用例不包含大量域上下文时,可以使用Prompt Engineering。
当想要在更改不同组件(数据源,嵌入,FM,矢量引擎)方面具有最高程度的灵活性时,使用RAG,这样简单并且可以保持输出的高质量(前提是你要有数据)。
当希望更好地控制模型工件及其版本管理时,可以使用微调。尤其是领域特定术语与数据非常特定时(如法律、生物学等),它也很有用。
当以上都不适合的时候,可以从头开始训练。既然觉得上面的方案准确性都不够高,所以就需要有足够的预算和时间来做的更好。
总而言之,选择正确的生成AI方法需要深入思考并评估可接受和不可接受的指标。甚至是根据不同的时期选择不同的方案。
https://avoid.overfit.cn/post/94751a166b9f49509f7e0b449542733f
作者:Vikesh Pandey