Reactjs开发自制编程语言Monkey的编译器:高能技术干货之语法高亮1
由于本节技术难点不好理解,请观看视频中的代码讲解和调试过程,以便消化难度,加深知识点的理解。
更详细的讲解和代码调试演示过程,请点击链接
使用各种IDE编写代码时,其有一个功能是关键字高亮,当你敲下的字符串形成编程语言的关键字时,它的颜色会比普通变量更加靓丽显眼,而且这种高亮是即时的,当你在编辑器上敲下”if”两个字母时,这两个字母的颜色会变成引人注目的红色,当你在”if”后面添加其他字符时,字符串的颜色就会从显眼的红色转变为令人难以察觉的浅色,例如白色。关键字的即时高亮是一个难度很大技术点,由于我们自创的Monkey编程语言所使用的IDE是网页版,在web上实现关键字高亮更是颇费周折,本节技术含量很大,完成本节后,你的数据结构,算法,设计模式等技术内力会有明显提升,同时你对前端DOM的多叉树模型以及浏览器内核通过遍历DOM模型渲染页面的内在机制会有更深层次的理解,而这些重要能力往往是前端开发工程师所缺乏的。
我们先弥补上一节留下的问题。词法解析器会把代码中的关键字”let”解读成一个普通的变量字符串,给它的分类是IDENTIFIER, 由于let是关键字,它自己单独成为一个分类,不属于IDENTIFIER分类,现在我们先解决这个问题。打开MonkeyLexer.js , 我们在词法解析器对象里添加关键字初始化功能,代码如下:
class MonkeyLexer {
constructor(sourceCode) {
this.initTokenType()
this.initKeywords()
....
}
//change here
initKeywords() {
this.keyWordMap = [];
this.keyWordMap["let"] = new Token(this.LET, "let", 0)
this.keyWordMap["if"] = new Token(this.IF, "if", 0)
this.keyWordMap["else"] = new Token(this.ELSE, "else", 0)
}
....
nextToken () {
....
switch (this.ch) {
....
default:
var res = this.readIdentifier()
if (res !== false) {
//change here
if (this.keyWordMap[res] !== undefined) {
tok = this.keyWordMap[res]
} else {
tok = new Token(this.IDENTIFIER, res, lineCount)
}
}
....
}
....
}
}首先我们增加了一个新函数叫initKeywords,在该函数中,我们先创建一个名为keyWordMap的哈希表,这个表的key是Monkey语言关键字对应的字符串,例如let, if , else 都是Monkey语言的关键字,哈希表的值,则是我们手动为关键字专门生成的Token对象。
在nextToken函数中,词法解析器在解析代码时,当读入一串有连续字符组成的字符串时,这个字符串可能属于Monkey语言的关键字,也可能就是普通变量而已,那么当解析到字符串时,解析器现在关键字哈希表中,用该字符串作为key去查找一下,如果查找返回非空结果,那表明当前字符串是我们预先定义好的关键字,于是我们直接从哈希表中把关键字对应的token返回回去,如果在哈希表中查找不到,那表明字符串只是普通的变量,于是解析器就会构造一个类型为IDENTIFIER的token返回。完成上面代码后,上一节遗留的把let分类成IDENTIFIER的问题就能解决掉了。
接下来我们要进入重点,也是一个技术难点,那就是关键字的即时高亮,完成后效果如下:
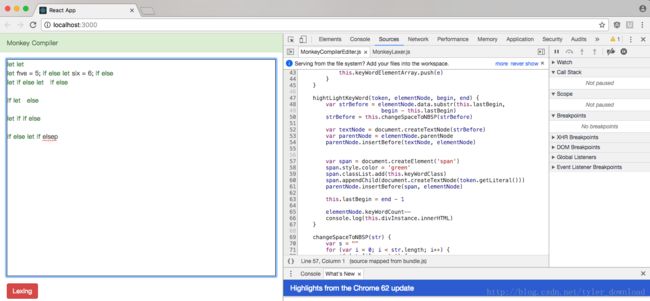
一旦我们在代码编辑框中输入关键字字符串,输入完毕,整个字符串立马变成绿色,如果你在关键字变成绿色后,直接在关键字后面添加其他字符,使得整个字符串变成不是关键字了,那么字符串立马由绿色变成普通的黑色,这种即时性是一个不好处理的技术难点。
把一个字符串变成绿色不难,只要在这个字符串的html格式上添加一个span标签就可以,例如在html中含有一个关键字字符串如下:
<div>letdiv>上面的html代码在页面上渲染时,”let”显示出来只不过是普通的黑色,为了让他变成高亮绿色,我们在let的作用添加一堆span标签,变化如下:
<div><span style="color:green">letspan>div>上面这段html代码被页面渲染后,”let”字符串在页面上显示的字体就是绿色了。假设我们在编辑框中输入如下一段代码:
let five = 5; let six = 6; let seven = 7;这段代码相应的html格式为:
<div>let five = 5; let six = 6; let seven = 7;div>我们算法要做的是,先找到包含这段文字的div节点,然后通过该节点的data属性把div节点中包含的字符串拿出来,然后把字符串根据关键字拆分成若干部分,其中关键字独立成为一部分,拆分后情况如下:
let
five = 5;
let
six = 6;
let
seven = 7;接着把每部分拿出来,专门构造成独立节点,关键字构成的节点需要用标签span包裹,于是我们得到如下情况:
<span style="color:green">letspan>
<text>five = 5;text>
<span style="color:green">letspan>
<text>six = 6;text>
<span style="color:green">letspan>
<text>seven = 7;text>这里需要强调一下,在DOM模型中,任何字符串都是一个text节点,因此上面我们提到的html格式:
<div>let five = 5; let six = 6; let seven = 7;div>它本质上其实是:
<div><text>let five = 5; let six = 6; let seven = 7;text>div>只不过在一般情况下,浏览器显示页面源码时,会直接忽略掉标签,直接把里面的字符串显示出来。
我们接着说高亮算法。完成前面将的字符串根据关键字切割并为每部分单独创建节点后,把这些节点通过DOM API insertBefore插入到原来的节点前面,得到以下情况:
<div>
<span style="color:green">letspan><text>five = 5;text><span style="color:green">letspan><text>six = 6;text><span style="color:green">letspan><text>seven = 7;text><text>let five = 5; let six = 6; let seven = 7;text>
div>然后我们通过DOM API removeChild 把div节点下面原来的text节点:
<text>let five = 5; let six = 6; let seven = 7;text>删除掉,最后得到的html页面代码为:
<div>
<span style="color:green">letspan><text>five = 5;text><span style="color:green">letspan><text>six = 6;text><span style="color:green">letspan><text>seven = 7;text>
div>上面的html代码经页面渲染后,所有的关键字let都会变成高亮的绿色,而其他字符串则显示黑色。算法基本原理如此,但实现的时候其实有若干个技术难点需要考虑,第一,如何根据关键字把字符串正确的切分成相应部分,第二,如何实现即时性,也就是用户敲下键盘,后就立即执行我们上面所说的算法步骤。第三,要考虑已经有关键字高亮后,用户继续输入新关键字时的情形。
我们将逐步解决上面的技术难点。首先,我们需要用新的组件来实现代码编辑框,在src目录下新建一个文件,命名为MonkeyCompilerEditer.js,然后添加如下代码:
class MonkeyCompilerEditer extends Component{
constructor(props) {
super(props)
this.keyWords = props.keyWords
}
render() {
let textAreaStyle = {
height: 480,
border: "1px solid black"
};
return (
<div style={textAreaStyle}
contentEditable>
div>
);
}
}从上面代码可以看到,我们的组件只是简单的在页面上绘制一个可编辑的div控件而已。需要我们注意的是,其构造函数constructor(props)有一个输入参数叫props,这个东西是怎么传进来的呢,我们先回到MonkeyCompilerIDE.js,看看新生成的组件是如何被调用的:
render () {
return (
<bootstrap.Panel header="Monkey Compiler" bsStyle="success">
<MonkeyCompilerEditer
ref={(ref) => {this.inputInstance = ref}}
keyWords={this.lexer.getKeyWords()}/>
<bootstrap.Button onClick={this.onLexingClick.bind(this)}
style={{marginTop: '16px'}}
bsStyle="danger">
Lexing
bootstrap.Button>
bootstrap.Panel>
);
}上面代码中,我们把原来使用的textarea控件换成了我们新创建的组件,注意这行代码:
ref={(ref) => {this.inputInstance = ref}}
keyWords={this.lexer.getKeyWords()}/> 里面有一行是keyWords={this.lexer.getKeyWords()},注意看这里的keyWords和组件构造函数里的props.keyWords是完全对应的。我们知道reactjs的设计思想是通过多个独立组件相互搭建后形成复杂功能,其中组件直接如何相互通讯呢?reactjs为每个组件提供了一个内置属性对象叫props,当外界调用组件时,可以把想传递给组件的信息以上面的方式传递,上面代码的keyWords就是MonkeyCompilerEditer组件被调用时,它的调用方MonkeyCompilerIDE想传递给它的信息,这个信息传入到组件内部后,会存储在组件内置属性对象props里,在组件内部通过props.keyWords就能访问外部组件传递给它的相应内容。
我们看看getKeyWords的实现,在MonkeyLexer.js里,添加如下代码:
getKeyWords() {
return this.keyWordMap
}它的实现简单,就是返回词法解析器初始化好的关键字token哈希表。该表的用处在于,当前面高亮算法的第一步分词完成后,利用关键字哈希表查找所得分词是否是关键字。根据语句中是否含有关键字对节点中的字符串进行分割是一个复杂的功能,还在上一节我们实现过的词法解析器已经实现了这种功能,现在问题是,我们如何在MonkeyCompilerEditer组件中,直接使用词法解析器的相关功能,在此我们引入一种应用广泛的设计模式叫观察者模式。

词法解析器对象将作为信号的发出者,它会把传给它的代码进行词法解析,当读入一个字符串,词法解析器把该字符串识别并分类形成token后,它就向所有观察者发出信号,把刚刚识别到的token提交给观察者,MonkeyCompilerEditer把用户敲入的代码提交给MonkeyLexer进行解析,MonkeyLexer解读代码,并把代码分词,也就是把代码分解成相应token时,调用给定接口,把解析出来的token对象提交给MonkeyCompilerEditer。我们看看代码实现,在MonkeyLexer.js中,添加如下代码:
setLexingOberver(o, context) {
if (o !== null && o !== undefined) {
this.observer = o
this.observerContext = context
}
}
nextToken () {
var tok
this.skipWhiteSpaceAndNewLine()
var lineCount = this.lineCount
var needReadChar = true;
//change here
this.position = this.readPosition
switch(this.ch) {
....
}
if (tok !== undefined) {
this.notifyObserver(tok)
}
return tok
}
notifyObserver(token) {
this.observer.notifyTokenCreation(token,
this.observerContext, this.position - 1,
this.readPosition)
}setLexingOberver用来注册成为词法解析过程的观察者,注册后词法解析过程中,一旦识别到一个token,解析器就会调用oberser的接口,把识别到的token提交给它,oberser必须实现规定好的接口,在我们的上面代码例子中,observer必须实现notifyTokenCreation接口,这个接口需要接收4个参数,第一个是解析出来的token对象,第二个是观察者在注册时提交的上下文环境对象,第三个是token对应字符串的起始位置,第四个是token字符串的结束位置。
回到MonkeyCompilerEditer组件,它自己要作为MonkeyLexer的Observer,它必须实现notifyTokenCreation接口,我们在该组件中添加代码如下:
import MonkeyLexer from './MonkeyLexer'
class MonkeyCompilerEditer extends Component{
....
changeNode(n) {
var f = n.childNodes;
for(var c in f) {
this.changeNode(f[c]);
}
if (n.data) {
console.log(n.parentNode.innerHTML)
this.lastBegin = 0
n.keyWordCount = 0;
var lexer = new MonkeyLexer(n.data)
lexer.setLexingOberver(this, n)
lexer.lexing()
}
}
notifyTokenCreation(token, elementNode, begin, end) {
if (this.keyWords[token.getLiteral()] !== undefined) {
var e = {}
e.node = elementNode
e.begin = begin
e.end = end
e.token = token
elementNode.keyWordCount++;
this.keyWordElementArray.push(e)
}
}
}changeNode函数的功能,在后面我们会详细讲解,它的基本作用是变量DOM树,找到包含代码语句的HTML节点,通过节点的data属性获得用户输入到编辑框中的代码字符串,并把字符串提交给词法解析器进行分词。假设当用户输入代码后,页面形成如下的html结构内容:
<div>let five = 5; let six = 6; let seven = 7;div>changeNode就会把上面代码中的div节点找到,n.data对应的就是节点里面的字符串,也就是:”let five = 5; let six = 6; let seven = 7;”,把这段字符串提交给词法解析器进行解析,词法解析器解析语句,当得到一个token对象时,调用MonkeyCompilerEdier实现的notifyTokenCreation接口,把相关信息提交给它。
例如词法解析器读取字符串”let”,解析出第一个token,内容为{type:MonkeyLexer.LET, literal: “let”, lineCount: 0}, 同时记录出第一个”let”字符串的起始和结束位置,然后就把这些信息,通过调用MonkeyCompilerEditer的notifyTokenCreation接口传递出去,MonkeyCompilerEditer接收到这些信息后,在接口的实现中我们可以看到,它会先通过传入的token对应的字符串在关键词哈希表中查询,如果对应的token字符串是关键字字符串,那么它把信息集中到一个对象中,然后存入一个数组叫keyWordElementArray,其中elementNode参数对应的就是包含代码字符串的div节点在DOM中的对象实例。
至此,把代码字符串根据关键词切分成若干部分的步骤就完成了,在后续章节中,我们将继续完成关键字语法高亮算法的余下步骤。由于本节技术难点不好理解,请观看视频中的代码讲解和调试过程,以便消化难度,加深知识点的理解。
更详细的讲解和代码调试演示过程,请点击链接
更多技术信息,包括操作系统,编译器,面试算法,机器学习,人工智能,请关照我的公众号:
