【Linux】进程信号篇:信号的产生(signal、kill、raise、abort、alarm)、信号的保存(core dump)
文章目录
- 一、 signal 函数:用户自定义捕捉信号
- 二、信号的产生
-
- 1. 通过中断按键产生信号
- 2. 调用系统函数向进程发信号
-
- 2.1 kill 函数:给任意进程发送任意信号
- 2.2 raise 函数:给调用进程发送任意信号
- 2.3 abort 函数:给调用进程发送 6 号信号
- 3. 软件条件产生信号
-
- alarm 函数:闹钟时间后,发送 14(SIGALRM )号信号
- 4. 硬件异常产生信号
-
- 4.1 除0:8) SIGFPE
- 4.2 野指针:11) SIGSEGV
- 三、信号保存的细节
-
- 1. core 和 term
- 2. waitpid 中,status 第八位的 core dump 标志位
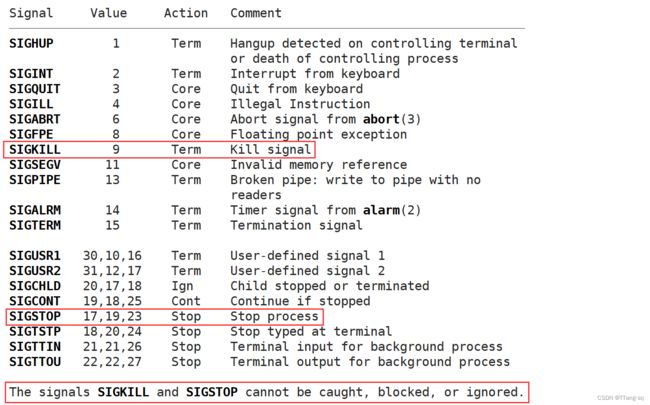
kill -l 可以查看所有信号:

其中,前面的数字就是信号,后面的大写英文就是信号名称,实际就是宏。
我们需要关注的是 1~31 号普通信号,关注他们有没有产生(可以用 0 或者 1 表示)。
所以,进程的 pcb 中,需要对产生的信号先用 位图 保存起来,再按照一定的顺序去处理他们。
我们所谓发送信号,本质其实就是写入信号,直接修改特定进程的信号位图中的特定比特位(0 / 1)。位图中,比特位的位置,是信号的编号;比特位的内容表示,是否收到该信号。
无论后面有多少种信号产生的方式,最终都必须要让 OS 来完成最后发送 / 写入的过程。
man 7 signal:查看所有信号详细信息
一、 signal 函数:用户自定义捕捉信号
#include
typedef void (*sighandler_t)(int);
sighandler_t signal(int signum, sighandler_t handler);
参数 signum:
- 信号编号
参数 handler:
- 用户自定义处理动作,在 signum 信号发生时触发。
使用举例:
// 自定义方法
// signo:特定信号被发送给当前进程的时候,执行handler方法的时候,要自动填充对应的信号给handler方法
// 我们甚至可以给所有的信号设置同一个处理函数
void handler(int signo)
{
std::cout << "get a singal: " << signo << std::endl;
// exit(2);
}
int main()
{
// signal(SIGINT, handler);
// signal(SIGQUIT, handler);
signal(2, handler); // 2:ctrl+c
signal(3, handler); // 3:ctrl+\
while(true)
{
std::cout << "我是一个进程,我正在运行 ..., pid: " << getpid() << std::endl;
sleep(1);
}
return 0;
}
1. 2号信号,进程的默认处理动作是终止进程
2. signal 可以进行对指定的信号设定自定义处理动作
3. signal(2, handler)调用完这个函数的时候,handler方法没有被调用,只是更改了2号信号的处理动作。
4. 那么handler方法在当2号信号产生的时候才会被调用
5. 默认我们对2号信号的处理动作:终止进程,我们用signal(2, handler), 我们在执行用户动作的自定义捕捉!不是每个信号我们都可以自定义捕捉的!!比如 9 就不行。是 OS 规定的
二、信号的产生
1. 通过中断按键产生信号
比如用户按下 ctrl+c,键盘输入产生一个 硬件中断,用电信号将中断号写入寄存器,系统再根据中断号去中断向量表中查找,然后 OS 再从键盘中去读取数据(看是键盘哪些位置被摁下)。被 OS 获取后,解释成信号,发送给目标前台进程。
2. 调用系统函数向进程发信号
2.1 kill 函数:给任意进程发送任意信号
头文件
#include
int kill(pid_t pid, int sig);
参数 pid:
- 进程pid
参数 sig:
- 信号
2.2 raise 函数:给调用进程发送任意信号
头文件
#include
int raise(int sig);
参数 sig:
- 信号
2.3 abort 函数:给调用进程发送 6 号信号
头文件
#include
void abort(void);
进程收到 6 号信号就会终止,即使可以被用户捕捉到,也会完成终止。
3. 软件条件产生信号
(SIGPIPE也是一个由软件条件产生的信号
alarm 函数:闹钟时间后,发送 14(SIGALRM )号信号
默认动作是终止(Term)当前进程
头文件
#include
unsigned alarm(unsigned seconds);
参数 seconds:
- 时间
返回值:
- 0,或者是以前设定的闹钟时间还余下的秒数。(比如第一次提前结束,在次重新设定时,就会返回之前剩余的时间)
alarm 函数是一次性的,可以利用捕捉器,进行 自取 操作,达到不断设置闹钟的作用。
使用举例:
void myhandler(int signo)
{
std::cout << "get a signal: " << signo << " count: " << count << std::endl;
alarm(1);
// exit(0);
}
int main(int argc, char *argv[])
{
std::cout << "pid: " << getpid() << std::endl;
signal(SIGALRM, myhandler);
alarm(1); //一次性的
while(true)
{
sleep(1);
}
}
alarm 也是有内核数据结构的,OS 管理这些内核数据结构,每隔一段时间就会去比如说管理 alarm 的最小堆中,当堆顶 timestamp >= 系统当前时间 时,就会给这个对应的进程 pid 发送 SIGALRM 信号,并把这个闹钟从堆中拿走。
struct alarm
{
int timestamp; // curr + 设置的seconds
// ...进程 pid ...等等
};
4. 硬件异常产生信号
硬件异常被硬件以某种方式被硬件检测到并通知内核,然后内核向当前进程发送适当的信号。
4.1 除0:8) SIGFPE
| Signal | Value | Action | comment |
|---|---|---|---|
| SIGFPE | 8 | Core | Floating point exception |
例如当前进程执行了除 0 的指令,CPU的运算单元会产生异常,内核将这个异常解释为 SIGFPE 信号,发送给进程。
状态寄存器:用比特位表示状态,其中有一位,就是反映本次计算是否有溢出问题。
出现除 0 后,溢出标志位被置 1,os 发现后立即将 相应进程 pcb 中发送 8号 信号。
4.2 野指针:11) SIGSEGV
| Signal | Value | Action | comment |
|---|---|---|---|
| SIGSEGV | 11 | Core | Invalid memory reference |
再比如当前进程访问了非法内存地址,MMU 会产生异常,内核将这个异常解释为 SIGSEGV 信号发送给进程。
虚拟地址 通过页表 转换访问到物理内存,这个过程其实是软硬件结合的方式完成的。这个页表的 KV 转换过程就是由硬件 MMU 完成的。
MMU:内存管理单元,被集成在 CPU 内,转换时,只需要把虚拟地址导入到 MMU 这个硬件中,用这个硬件转。
举例:
// 一个野指针问题
int *p = nullptr;
p* = 100;
分析上述代码,当我们赋值给指针为 nullptr 时,p 里面放的是 0 或者 nullptr,*p 代表的就是虚拟地址空间中的 0 号地址,我们想将 100 写入 0 号地址,但这个地址我们没有申请过,他也不允许我们访问,所以造成了野指针 / 悬垂指针问题。
其实,*p = 100;第一步并不是写入,而是首先进行虚拟地址到物理内存的转换。
- 没有映射:MMU 硬件报错
- 有映射,但是没有权限:MMU 直接报错
- OS 接收到报错后,传递给 CPU 中的一个寄存器,找到相应进程的 pcb 对其发送 11号 信号。
三、信号保存的细节
1. core 和 term
查看信号的 Action 栏有 core 和 term 两种。
他们有什么不同呢?

-
term 终止的就是终止,没有多余的动作。
-
core 终止,会先进行核心转储,再进行终止。
进程在异常的时候,OS 可以将该核心代码部分进行 核心转储,将内存中进程的相关数据,全部 dump 到磁盘中。核心转储的目的是,方便异常后进行调试。
一般核心转储文件在云服务器上确实看不到,而是云服务器默认是关闭这个功能的!
ulimit -a可以查到 core_file_size 大小是0,即关闭的,按照提示ulimit -c [数值]设置大小,即可打开核心转储功能,数值设为 0 就是关闭。
当程序异常时,我们不知道哪里出了问题。有如下解决方法,称作 事后调试:
-
-g生成可执行程序,使用gdb命令打开调试模式 -
命令行中输入:
core-file core.xxxx(xxxx 为相应的核心转储生成文件),就会出现报错原因的详细信息,和报错位置
既然核心转储那么方便,为什么云服务器要关闭这个功能呢?
Linux环境根据使用目的可以分为:开发环境、测试环境、生产环境
云服务器属于生产环境,生产环境是默认关闭核心转储的!
按照 CPU 的运行速度,错误的代码,在短时间内可以造成大量的 core. 文件,磁盘写满甚至系统崩溃都是有可能的,所以生产环境下,一般都是将这个功能关闭的。
2. waitpid 中,status 第八位的 core dump 标志位

这里的 core dump 标志位,就是用来记录,是否有 core dump 出现的。