一文读懂|Linux 虚拟文件系统(VFS)
前言
虚拟文件系统是一个很庞大的架构,如果要分析的面面俱到,会显得特别复杂而笨拙,让人看着看着,就不知所云了(当然主要还是笔者太菜),所以这篇博客,以 open() 函数为切入点,来试着分析分析VFS文件系统的运转机理,本文的代码来源于 linux3.4.2。
基础知识
首先我们来看一张图:
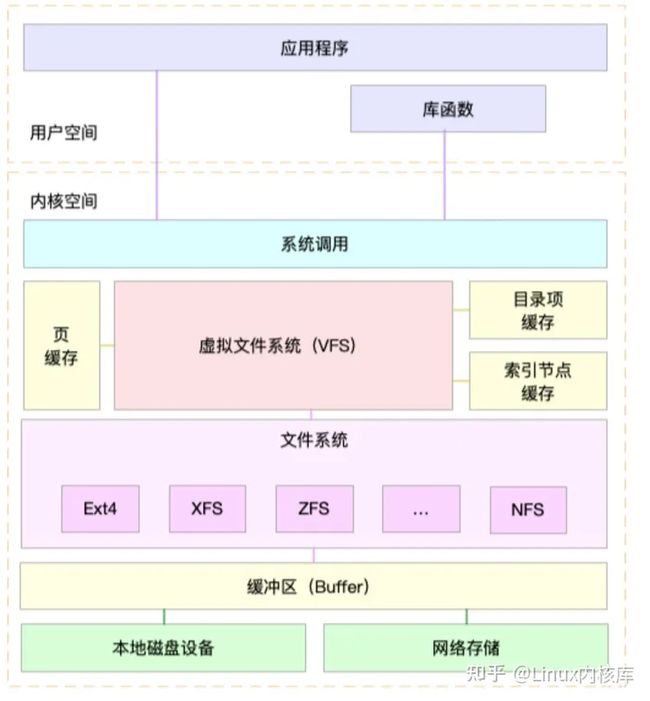
(图1)
从这张图中,我们可以看出,系统调用函数并不是直接操作真正的文件系统,而是通过一层中间层,也就是我们说的虚拟文件系统,为什么要有虚拟文件系统?
linux中常见的文件系统有三类:基于磁盘的文件系统;基于内存的文件系统;网络文件系统,(这三类文件系统是共存于文件系统层,为不同类型的数据提供存储服务,这三类文件系统格式是不一样的,也就是说如果不通过虚拟文件系统,直接对真正的文件系统进行读取,有种类型的文件系统,你就得写几种相对应的读取函数),所以说虚拟文件的出现(VFS)就是为了通过使用同一套文件 I/O 系统 调用即可对 Linux 中的任意文件进行操作而无需考虑其所在的具体文件系统格式。
VFS的数据结构
VFS依靠四个主要的数据结构和一些辅助的数据结构来描述其结构信息,这些数据结构表现得就像是对象;每个主要对象中都包含由操作函数表构成的操作对象,这些操作对象描述了内核针对这几个主要的对象可以进行的操作。
1、超级块对象
存储一个已安装的文件系统的控制信息,代表一个已安装的文件系统;每次一个实际的文件系统被安装时, 内核会从磁盘的特定位置读取一些控制信息来填充内存中的超级块对象。一个安装实例和一个超级块对象一一对应。超级块通过其结构中的一个域s_type记录它所属的文件系统类型。
struct super_block { //超级块数据结构
struct list_head s_list; /*指向超级块链表的指针*/
……
struct file_system_type *s_type; /*文件系统类型*/
struct super_operations *s_op; /*超级块方法*/
……
struct list_head s_instances; /*该类型文件系统*/
……
};
struct super_operations { //超级块方法
……
//该函数在给定的超级块下创建并初始化一个新的索引节点对象
struct inode *(*alloc_inode)(struct super_block *sb);
……
//该函数从磁盘上读取索引节点,并动态填充内存中对应的索引节点对象的剩余部分
void (*read_inode) (struct inode *);
……
};
2、索引节点对象
索引节点对象存储了文件的相关信息,代表了存储设备上的一个实际的物理文件。当一个 文件首次被访问时,内核会在内存中组装相应的索引节点对象,以便向内核提供对一个文件进行操 作时所必需的全部信息;这些信息一部分存储在磁盘特定位置,另外一部分是在加载时动态填充的。
struct inode {//索引节点结构
……
struct inode_operations *i_op; /*索引节点操作表*/
struct file_operations *i_fop; /*该索引节点对应文件的文件操作集*/
struct super_block *i_sb; /*相关的超级块*/
……
};
struct inode_operations { //索引节点方法
……
//该函数为dentry对象所对应的文件创建一个新的索引节点,主要是由open()系统调用来调用
int (*create) (struct inode *,struct dentry *,int, struct nameidata *);
//在特定目录中寻找dentry对象所对应的索引节点
struct dentry * (*lookup) (struct inode *,struct dentry *, struct nameidata *);
……
};
3、目录项对象
引入目录项的概念主要是出于方便查找文件的目的。一个路径的各个组成部分,不管是目录还是 普通的文件,都是一个目录项对象。如:在路径 /home/source/test.c 中,目录 /、home、source 和文件 test.c都对应一个目录项对象。不同于前面的两个对象,目录项对象没有对应的磁盘数据结构,VFS 在遍历路径名的过程中现场将它们逐个地解析成目录项对象。
struct dentry {//目录项结构
……
struct inode *d_inode; /*相关的索引节点*/
struct dentry *d_parent; /*父目录的目录项对象*/
struct qstr d_name; /*目录项的名字*/
……
struct list_head d_subdirs; /*子目录*/
……
struct dentry_operations *d_op; /*目录项操作表*/
struct super_block *d_sb; /*文件超级块*/
……
};
struct dentry_operations {
//判断目录项是否有效;
int (*d_revalidate)(struct dentry *, struct nameidata *);
//为目录项生成散列值;
int (*d_hash) (struct dentry *, struct qstr *);
……
};
4、文件对象
文件对象是已打开的文件在内存中的表示,主要用于建立进程和磁盘上的文件的对应关系。它由 sys_open() 现场创建,由 sys_close() 销毁。文件对象和物理文件的关系有点像进程和程序的关系一样。
当我们站在用户空间来看待 VFS,我们像是只需与文件对象打交道,而无须关心超级块,索引节点或目录项。因为多个进程可以同时打开和操作 同一个文件,所以同一个文件也可能存在多个对应的文件对象。
文件对象仅仅在进程观点上代表已经打开的文件,它 反过来指向目录项对象(反过来指向索引节点)。一个文件对应的文件对象可能不是惟一的,但是其对应的索引节点和 目录项对象无疑是惟一的。
struct file {
……
struct list_head f_list; /*文件对象链表*/
struct dentry *f_dentry; /*相关目录项对象*/
struct vfsmount *f_vfsmnt; /*相关的安装文件系统*/
struct file_operations *f_op; /*文件操作表*/
……
};
struct file_operations {
……
//文件读操作
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
……
//文件写操作
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
……
int (*readdir) (struct file *, void *, filldir_t);
……
//文件打开操作
int (*open) (struct inode *, struct file *);
……
};
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
正篇
经过基础知识点的介绍后,我们开始来探究,当我们通 open() 尝试去打开一个文件的时候,Linux 内部是如何找到对应的存储在硬件上的该文件的数据。

(图2)

(图3)
首先我们来看看上面这两张图,files_struct 主要就是一个 file 指针数组,我们通常说的文件描述符是一个整数,而这个整数正好可以作为下标,从而从 files_struct 中获得 file 结构。
task_struct 为进程描述符,代表的是打开文件的这么一个动作,这里我想表达的知识点:当文件第一次被打开时(打开成功),会建立起如上图所示的联系,返回 fd 文件描述符就这样和底层的存储结构联系在了一起,fd 作为文件描述符,文件作为数据的载体,我们可以将它们理解为密码和保险柜之间的关系,第一打开文件就是相当初始化时设置密码(建立起了密码和保险柜的联系),当我们以后再需要拿取保险柜中的东西时,只需要通过第一次设置的密码就可以对保险柜进程操作。
内核中,对应于每个进程都有一个文件描述符表,表示这个进程打开的所有文件。文件描述表中每一项都是一个指针,指向一个用于描述打开的文件的数据块 ——— file 对象,file 对象中描述了文件的打开模式,读写位置等重要信息,当进程打开一个文件时,内核就会创建一个新的 file 对象。
需要注意的是,file 对象不是专属于某个进程的,不同进程的文件描述符表中的指针可以指向相同的 file 对象,从而共享这个打开的文件。 file 对象有引用计数,记录了引用这个对象的文件描述符个数,只有当引用计数为0时,内核才销毁 file 对象,因此某个进程关闭文件,不影响与之共享同 一个 file 对象的进程.
下面我们来分析具体的代码。
应用层:
应用程序在操作任何一个文件之前,必须先调用 open() 来打开该文件,即通知内核新建一个代表该文件的结构,并且返回该文件的描述符(一个整数),该描述符在进程内唯一。所用到函数为 open():
int open(const char * pathname,int oflag, mode_t mode )
/*pathname:代表需要打开的文件的文件名;
oflag:表示打开的标识 (只读打开/只写打开/读写打开 ...........)
mode: 当新创建一个文件时,需要指定mode参数(设置权限)
*/
内核层:
当 open() 系统调用进入内核时候,最终调用的函数为:
SYSCALL_DEFINE3(open, const char __user , filename, int, flags, int,mode)
该函数位于 fs/open.c 中,下面将会分析其具体的实现过程。
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, int, mode)
{
long ret;
//判断系统是否支持大文件,即判断long的位数,如果64则表示支持大文件;
if (force_o_largefile())
flags |= O_LARGEFILE;
//完成主要的open工作,AT_FDCWD表示从当前目录开始查找
ret = do_sys_open(AT_FDCWD, filename, flags, mode);
/* avoid REGPARM breakage on x86: */
asmlinkage_protect(3, ret, filename, flags, mode);
return ret;
}
该函数主要调用 do_sys_open() 来完成打开工作,do_sys_open() 的代码分析如下。
long do_sys_open(int dfd, const char__user *filename, int flags, int mode)
{
//将欲打开的文件名拷贝到内核中,该函数的分析见下文;
char *tmp = getname(filename);
int fd = PTR_ERR(tmp);
if (!IS_ERR(tmp)) {
//从进程的文件表中找到一个空闲的文件表指针,如果出错,则返回,见下文说明;
fd = fd = get_unused_fd();
if (fd >= 0) {
//执行打开操作,见下文说明,dfd=AT_FDCWD;
struct file *f = do_filp_open(dfd, tmp, flags, mode, 0);
if (IS_ERR(f)) {
put_unused_fd(fd);
fd = PTR_ERR(f);
} else {
fsnotify_open(f);//作用是将 filp 的监控点打开,并将其添加到监控系统中
//添加打开的文件表f到当前进程的文件表数组中,见下文说明;
fd_install(fd, f);
}
}
putname(tmp);
}
return fd;
}

(图4)
从代码和流程图的分析中我们知道了,fd 和 file 是如何建立联系 (file 对象中包含一个指针,指向 dentry 对象。dentry 对象代表一个独立的文件路径,如果一个文件路径被打开多次,那么会建立多个 file 对象,但它们都指向同一个 dentry 对象。dentry 对象中又包含一个指向 inode 对象的指针。inode 对象代表一个独立文件。因为存在硬链接与符号链接,因此不同的 dentry 对象可以指向相同的 inode 对象。inode 对象包含了最终对文件进行操作所需的所有信息,如文件系统类型、文件的操作方法、文件的权限、访问日期等)。
那我们反向思考一下,现在我们已经得到 fd,如何找到对应 file, 在当前进程中我们保留着文件描述符,文件描述符中(files_structs),文件描述符中又保留着文件描述表(fatable),通过文件描述符表中 file 类型的指针数组对应的 fd 的项,我们可以找到 file。
这篇文章到这里就算结束了,还留有一个工作没有完成,如 do_filp_open(dfd, tmp, flags, mode) 是如何得到 file?,这是一个很复杂的过程,以后有空,笔者会尝试着去分析。
原文作者:Linux内核那些事
