论文阅读 - Jukebox: A Generative Model for Music
文章目录
- 1 概述
- 2 什么是VQ-VAE
-
- 2.1 Auto-encoder(AE)
- 2.2 Variational AutoEncoder(VAE)
- 2.3 Vector-Quantized Variational AutoEncoder(VQ-VAE)
- 2.4 VQ-VAE-2
- 3 Music VQ-VAE
- 4 Prior and upsamplers
- 5 Lyrics Conditioning
- 参考文献
By learning to produce the data, we can learn the best features of the data.
— OpenAI
1 概述
音乐生成一直是一个很有意思的话题,之前看过一些音乐生成的方式,都是将midi格式的音乐进行结构化之后,把这些midi音乐当作文本放到NLP的模型里去训练生成任务。然后输出也是一堆midi,再用其他的软件渲染出来。这样出来的音乐虽然还可以,但是把音乐限制在了某些固定的乐器当中,如果要想这样的音乐有人声是别想了。
Jukebox从raw audio入手,让模型直接生成音频信号。最终的模型可以控制演唱者,音乐风格,以及唱的歌词,效果很惊艳!
本文的目的是让读者对Jukebox有个直观上的了解,其中很多细节不回去深究。
2 什么是VQ-VAE
如果知道VQ-VAE的,本节可跳过。知道了VQ-VAE,也就知道了Jukebox的一半,因此花些篇幅来讲这个。
VQ-VAE(Vector-Quantized Variational AutoEncoder)不是这篇文章当中提出来的一种方法,而是生成任务中已有的一种方法,下面来说下什么是VQ-VAE,说的顺序是AE -> VAE -> VQ-VAE -> VQ-VAE-2。这里不会设计数学公式的推导,只是直观上的理解,要看公式推导的可以参看最下面的参考文献。
2.1 Auto-encoder(AE)
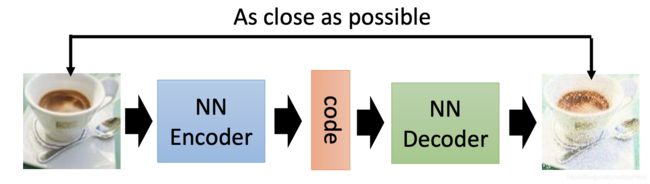
如下图1所示,自编码器是很早就已经提出来的一种抽取特征的方法,它有一个Encoder和一个Decoder。以输入图片为例,Encoder会把图片压缩成一个指定维度的向量,这个向量当中包含了用于重建图片的重要特征,Decoder会把这个特征重建成和输入尽可能接近的图片。这是一种无监督或者说自监督的学习方法,loss就是输入和输出图片的距离,被叫做reconstruction loss。
可想而知,若要重构的图片尽可能接近输入图片,Encoder输出的特征就必须要包含输入图片尽可能多的信息,也就是这是一个可以表达输入图片的特征。
这本质上和PCA很像,就是给图片降维。
AE的Decoder部分可以当作一个生成模型,但是有很大的问题。对于生成模型,我们希望输入稍微变化后,输出的图片变化不会太大。但是AE没有办法保证这一点。比如下图2所示,红色的code线是在code特征空间上的一条线,线上每个点都是一个特征,一个code,一个decoder的输入。假设在训练过程中,模型知道了左边这个点对应满月,右边这个点对应上弦月。那么我们希望把这两个点的中点输入给decoder之后,得到的是盈凸月(就是3/4个月亮是亮着的)。而AE训练出来的模型并不知道这种事情,只能看运气了。
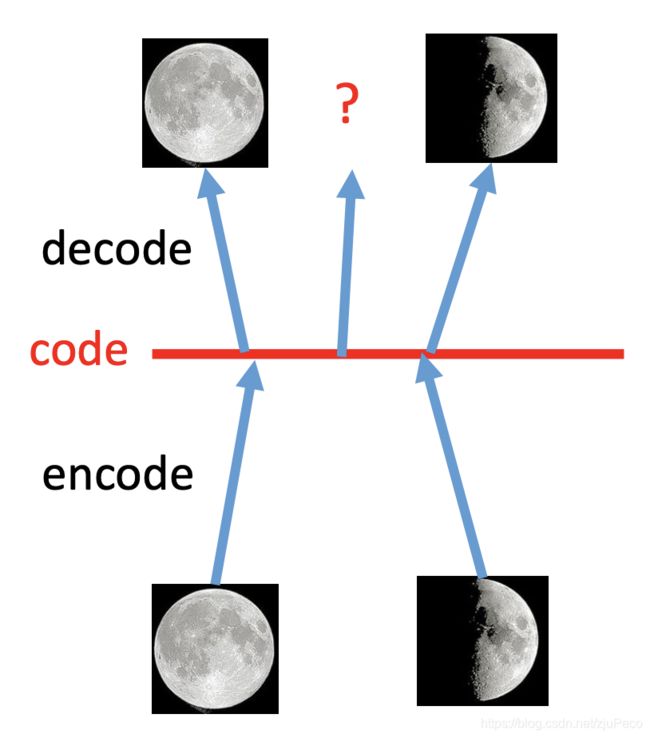
因此AE并不适合用于生成任务。
2.2 Variational AutoEncoder(VAE)
为了让AE适用于生成任务,就有人提出了VAE。想法很直接,既然映射到一个点上不好,我们就把输入图片映射到一个分布上,或者形象点说是一块区域上。
VAE的Encoder输出就是均值 m i m_i mi和方差 σ i \sigma_i σi。Decoder接到的特征 c i = m i + e x p ( σ i ) × e i c_i=m_i + exp(\sigma_i) \times e_i ci=mi+exp(σi)×ei。这里要这么折腾是因为从分布中sample的过程是不可导,那么就干脆把标准的正太分布当作一个外部的常量放进来,不参与梯度更新。这样每次传播的时候,均值和方差由encoder提供,利用外部的标准正太分布做sample,这样整个网络就可导了,机智啊!
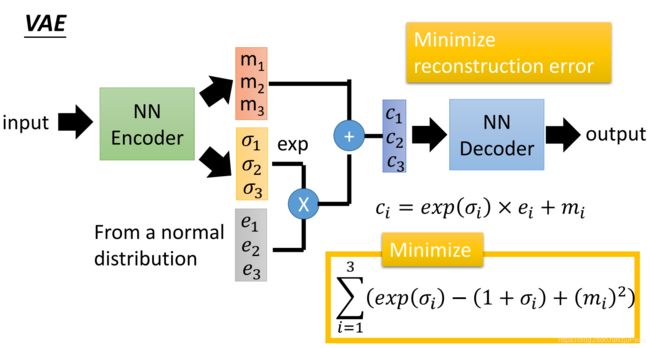
不过模型也挺机智,如果还是像AE一样只有一个reconstruction loss,那么网络就会学会把 σ i \sigma_i σi都置为0,因为 σ i \sigma_i σi的存在,encoder的输入是同一张图片时,decoder的输入却会是不同的,这样decoder烦的很,干脆把 σ i \sigma_i σi置0,这样对模型来说训练简单了,但是却退化为了AE。我们就是要让decoder在有 σ i \sigma_i σi的噪声干扰下,仍旧尽可能地还原图片。
于是,更机智的人类就加了一项KL散度loss,让encoder输出的分布 N ( m i , σ i ) N(m_i,\sigma_i) N(mi,σi)尽可能接近 N ( 0 , 1 ) N(0, 1) N(0,1)。这个loss化简后也就是图中的
L K L = ∑ i = 1 n ( e x p ( σ i ) − ( 1 + σ i ) + ( m i − 0 ) 2 ) L_{KL}=\sum_{i=1}^{n}(exp(\sigma_i) - (1+\sigma_i) + (m_i - 0)^2) LKL=i=1∑n(exp(σi)−(1+σi)+(mi−0)2)
实际情况下,还会有一个权重来调节reconstruction loss和KL loss的权重。
有了 σ i \sigma_i σi提供的噪声和足够多的训练数据,模型就会遇到不同输入映射到同一块特征区域的情况,这种时候,模型就知道要如何渐变了。

2.3 Vector-Quantized Variational AutoEncoder(VQ-VAE)
VAE不好的地方在于容易后验失效,也就是容易train坏掉。而且现实生活中,有些特征它就是不连续的,它就是离散的,比如音乐当中的note,于是就有了VQ-VAE。
VQ-VAE有一个东西叫做codebook(图5中的embedding space),这个codebook里有有限个特征,decoder的输入就会是这个codebook中的特征的一个组合,换句话说,encoder的输出都会被映射到codebook当中的某个特征上。映射的方法很简单,就是取距离最接近的那一个。
codebook当中的特征都是模型学出来的。

整个过程可以描述成下面这样:
(1)输入图片 X X X,经过encoder之后得到特征 Z e ( X ) Z_e(X) Ze(X)
(2)在codebook中找到与 Z e ( X ) Z_e(X) Ze(X)最接近的特征的index,并记在 q ( z ∣ x ) q(z|x) q(z∣x)当中
(3)通过 q ( z ∣ x ) q(z|x) q(z∣x)从code中取特征得到 Z q ( X ) Z_q(X) Zq(X)
(4) Z q ( X ) Z_q(X) Zq(X)经过decoder之后得到生成的图片 X ′ X' X′
这里从codebook中找最接近的特征的过程也是一个不可导的过程,但是作者用了一个Straight-through estimator的方法,让整个网络可导。其本质就是引入stop gradient,用codebook中选中的特征和encoder输出特征的差值来辅助传导。其loss为
L = L r e c o n s + L c o d e b o o k + β L c o m m i t L = L_{recons} + L_{codebook} + \beta L_{commit} L=Lrecons+Lcodebook+βLcommit
其中, L r e c o n s L_{recons} Lrecons为reconstruction loss,也就是输出图片和原图的距离。这个loss当中会把codebook当中的特征当成常量,不更新codebook的内容。也就是这个操作使得整个网络可以梯度更新。
L r e c o n s = − log p ( X ∣ Z q ( X ) ) L_{recons} = -\log p(X|Z_q(X)) Lrecons=−logp(X∣Zq(X))
L c o d e b o o k L_{codebook} Lcodebook为codebook loss。这部分更新codebook里的向量。sg就是stop gradient。这一步是让codebook的向量和encode的输出尽可能接近。
L c o d e b o o k = ∣ ∣ s g ( Z e ( X ) ) − e ∣ ∣ 2 2 L_{codebook} = || sg(Z_e(X)) - e||_2^2 Lcodebook=∣∣sg(Ze(X))−e∣∣22
L c o m m i t L_{commit} Lcommit为commit loss。这部分不更新codebook里的向量。这一步是让encode的输出和codebook的向量尽可能接近。
L c o d e b o o k = ∣ ∣ Z e ( X ) − s g ( e ) ∣ ∣ 2 2 L_{codebook} = || Z_e(X) - sg(e)||_2^2 Lcodebook=∣∣Ze(X)−sg(e)∣∣22
VQ-VAE就是这点东西,有意思在这个loss的设计上。我们再来看看它的全称,Vector-Quantized Variational AutoEncoder。Vector-Quantized指的就是把特征映射到codebook当中的向量上,用codebook的向量把encoder的输出进行量化。Variational在哪里呢?这里没有 σ i \sigma_i σi啊?我的理解是,codebook中的每个向量都对应了一片离它最近的区域的向量,这篇区域就是它噪声的容忍度,也就是variational的地方。
2.4 VQ-VAE-2
VQ-VAE还是容易坏掉,而且生成的大图会比较模糊,所以又有人提出了进阶版VQ-VAE-2。简单来说就是把模型变成了multi-level的,也就是hierarchical。Top level负责全局信息,bottom level负责局部信息。这样的模型不容易 collapse,而且细节也会比较到位。我没有仔细看VA-VAE-2的文章,所以具体的细节这里不讲了,可以参考下文献[4]。

3 Music VQ-VAE
音乐里的"do",“re”,"mi"都是离散的,因此相比于VAE,在音乐领域VQ-VAE显得更为合适。
这里的Music VQ-VAE既不是单纯的VQ-VAE也不是VQ-VAE-2。它的结构图如下图6所示,乍看之下就是多个VQ-VAE。Music VQ-VAE相比于VQ-VAE和VQ-VAE-2主要有3点不同:
(1)codebook随机初始化
VQ-VAE的codebook是很容易train坏掉的,说的夸张点,可能train着train着,codebook中的向量都映射到同一个向量上了。Music VQ-VAE会在每个batch计算codebook中各个向量的平均使用率,如果使用率过低,就会把这个向量随机初始化成当前batch中的一个向量上。保证codebook中的向量使用率都是比较高的。
(2)多个level的VQ-VAE
Music VQ-VAE的encoder会把音频压缩成不同的尺寸,也就是抽取特征时的hop_length不同。比如下图中的top level可能是1s抽一个feature,middle level可能是0.5s抽一个feature,bottom level可能是0.2s抽一个feature,这里的时间只是我随便举的例子。然后每个level独自是一个VQ-VAE,相互之间不影响,codebook也是独立的。top level关注于一些全局的信息,middle level和bottom level则更关注细节。如果单独拿它们的feature进行decode的话,bottom level的效果应该是最好的。
(3)加了 Spectral Loss
增加了Spectral Loss来让生成的音频保留高频的信号,否则高频信号很容易丢失。不同STFT参数的结果对时间和频率的分辨率影响不同,为了让模型不对某一组STFT的参数过拟合,Music VQ-VAE还用了多组参数的STFT,然后取它们loss的和。
L s p e c = ∣ ∣ ∣ S T F T ( x ) ∣ − ∣ S T F T ( x ^ ) ∣ ∣ ∣ 2 L_{spec} = || | STFT(x) | - | STFT(\hat{x}) | ||_2 Lspec=∣∣∣STFT(x)∣−∣STFT(x^)∣∣∣2

4 Prior and upsamplers
在生成模型的时候,我们是没有图5中左边部分的encoder的,我们只需要decoder和codebook中向量的组合就可以了。decoder的输入,也就是codebook中向量的组合在生成任务中是要无中生有变出来的,这就是prior和upsamplers的作用,生成decoder的输入。
p ( z ) = p ( z t o p , z m i d d l e , z b o t t o m ) = p ( z t o p ) p ( z m i d d l e ∣ z t o p ) p ( z b o t t o m ∣ z m i d d l e , z t o p ) p(z) = p(z^{top}, z^{middle}, z^{bottom}) \\ = p(z^{top})p(z^{middle}|z^{top})p(z^{bottom}|z^{middle}, z^{top}) p(z)=p(ztop,zmiddle,zbottom)=p(ztop)p(zmiddle∣ztop)p(zbottom∣zmiddle,ztop)
我们的Music VQ-VAE是三个levels的,top level的decoder输入生成器叫做prior, p ( z t o p ) p(z^{top}) p(ztop),因为它不依赖于其他输入,我们只要给一个随机的高斯分布或者什么随机的分布就行了,它是先验的。middle level和bottom level的decoder输入生成器叫做upsampler, p ( z m i d d l e ∣ z t o p ) p(z^{middle}|z^{top}) p(zmiddle∣ztop)和 p ( z b o t t o m ∣ z m i d d l e , z t o p ) p(z^{bottom}|z^{middle}, z^{top}) p(zbottom∣zmiddle,ztop),它依赖于上面生成的结果,是后验的。下图7中蓝色的block就是prior和upsamplers。
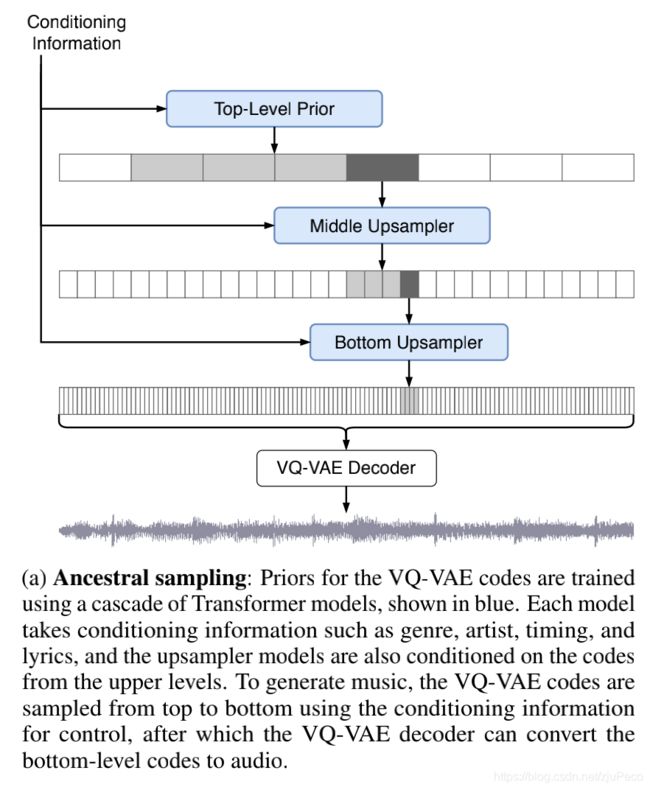
这三个东西就是三个网络结构,对于prior,论文设计了一个和Sparse Tranformer很像的网络,叫做Scalable Transformer的东西,对于upsampler,论文在WaveNet上加了点东西。具体的结构这里不展开讲。我们希望它们生成的特征和Music VQ-VAE训练时的中间从codebook生成的特征是类似的,这就是用自回归的方式去训练就可以了。
我们一方面希望生成模型是多样的,一方面又希望可以控制一下生成的结果,因此会在prior和upsampler的输入中也加入音乐家,音乐风格以及时间的信息。
如果不用prior和upsampler的话,也可以直接用音乐的某个片段经过Music VQ-VAE的encode部分的结果,这个时候的任务变成了续写歌曲了(completions of the song)。

5 Lyrics Conditioning
这篇论文惊艳的地方就在于,它可以生成有人声的音乐,而且唱的真像那么回事儿,压根儿听不出是机器合成的。这就得益于它的lyrics conditioning的机制了。为什么说它厉害,现在不是Text-to-speech(TTS)也搞得像模像样吗?唱和说还是有难度区别的,唱有这么三个难点:
(1)模型需要学会对齐歌词和唱的声音
(2)模型需要知道不同音乐家唱歌的风格
(3)模型需要知道同一句话,因为音调,节奏和歌曲风格的不同,唱出来的方法是不一样的
这么一想,还真的挺难的。不光解决这些问题难,要达到大量的歌词和音乐对应的数据就很难。论文为了让任务更简单,就把音乐切成24s的一段一段,然后对应歌词,放进去让模型去学习。网上爬下来的歌词和音乐是不一定能对上的,因此,论文又用了Spleeter抽取人声,用了NUS AutoLyricsAlign把歌词和时间对上。总之就是得到了许多音乐片段,并且这些片段都有对应的歌词文本。
这个歌词是经过一个tranformer变成特征之后和其他conditions一起输进去训练的,其结构如下图9。

事实证明,这样的训练,模型可以学到歌词和音乐之间的对齐方式。不过偶尔也会有坏掉的情况,这种情况下,歌词就乱唱了。

Jukebox放出了很多生成的音乐,可见在https://jukebox.openai.com/听一下。
参考文献
[1] Unsupervised Learning: Deep Generative Model
[2] 帶你認識Vector-Quantized Variational AutoEncoder - 理論篇
[3] 变分自编码器VAE:原来是这么一回事
[4] Generating Diverse High-Fidelity Images with VQ-VAE-2
[5] Jukebox: A Generative Model for Music