ByteBuffer 使用
ByteBuffer 使用
- 1 java.nio包中的类定义的缓冲区类型
- 2 缓冲区常用属性
-
- 2.1缓冲区的容量(capacity)
- 2.2 缓冲区的位置(position)
- 2.3 缓冲区的限制(limit)
- 2.4 缓冲区的标记(mark)
- 2.5 剩余容量 remaining/hasRemaining
- 3 缓冲区常用方法
-
- 3.1 创建缓冲区
-
- 3.1.1 allocate方法
- 3.1.2 wrap通过封装数组来创建缓冲区
- 3.2 创建视图缓冲区
- 3.3. 复制缓冲区 duplicate
- 3.4 切分缓冲区slice
- 3.5 标记和重置mark和reset
- 3.6 翻转flip
- 3.7 清除clear
- 3.8 压缩compact
- 3.9 rewind(倒回)
- 3.10 写数据
- 3.11 读数据
- 4 常用使用方式
-
- 4.1 读写范式
- 4.2 与字符串之间的转换
- 参见java7入门经典
1 java.nio包中的类定义的缓冲区类型
| 类 | 描述 |
|---|---|
| ByteBuffer | 用来存储 byte 类型值的缓冲区,也可以在这种缓冲区中存储任意其他基本类型的进制值(boolean 类型除外)。存储的每个二进制值在缓冲区中占据的字节长度根据类型长度决定char 或short 类型值占据2字节int 类型值占据4字节,等等 |
| CharBuffer | 只存储char类型值的缓冲区 |
| ShortBuffer | 只存储short 类型值的缓冲区 |
| IntBuffer | 只存储int类型值的缓冲区 |
| LongBuffer | 只存储 long 类型值的缓冲区 |
| Doublebuffer | 只存储double类型值的缓冲区 |
虽然有不同的类可以定义缓冲区,但是只使用 BvteBuffer 类型的缓冲区来读写其他类型的缓冲区被称为视图缓冲区,因为通常将它们创建为已有 ByteBuffer 类型缓冲区的视图视图缓冲区提供了一种容易的方式可以将各种类型的数据项从 ByteBuffer 中读出或者写入到其中
2 缓冲区常用属性
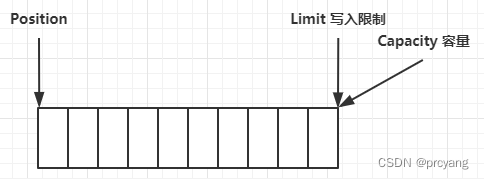
2.1缓冲区的容量(capacity)
缓冲区的容量是指缓冲区所能包含的值的最大数目而不是字节数目(除ByteBuffer外)创建缓冲区时,缓冲区的容量是固定的并且不能在随后进行修改。通过调用从 Buffer 类继承而来的 capacity0方法,可以获取 int 类型的缓冲区对象的容量。
2.2 缓冲区的位置(position)
位置(position)是指可用于读或写的下一个缓冲区元素的索引位置
2.3 缓冲区的限制(limit)
限制(limit)是指缓冲区中第一个不应该被读或写的值的索引位置,所以从 position 所指的元素到 limit-1所指的元素都可以被读取或写入。如果想要填充缓冲区,位置必须是零,因为这是第一个数据项所要存储的位置,而且限制必须等于缓冲区的容量,因为最后一个数据项必须存储到缓冲区的最后一个元素中,值为 capacity-1。
2.4 缓冲区的标记(mark)
标记(mark)记录当前position的值, 默认值-1。和reset方法结合使用,position被改变后,可以通过调用reset() 方法恢复到mark的位置
2.5 剩余容量 remaining/hasRemaining
//Returns the number of elements between the current position and the limit.
//Returns:The number of elements remaining in this buffer
public final int remaining() {
return limit - position;
}
//Tells whether there are any elements between the current position and the limit.
public final boolean hasRemaining() {
return position < limit;
}
3 缓冲区常用方法
3.1 创建缓冲区
3.1.1 allocate方法
定义缓冲区的这些类都没有可用的公共构造函数。作为替代,可以使用静态的工厂方法来创建缓冲区。通常会通过调用类的静态 allocate0方法来创建 ByteBuffer 类型的缓冲区对象。将int类型值作为参数传入定义缓冲区容量的方法一一缓冲区必须加载的最大字节数。
//创建缓冲区(java 的堆内存)位置为0并且容量为 1024,限制未1024
ByteBuffer buf = ByteBuffer.allocate(1024);
//Allocates a new direct byte buffer.操作系统直接内存(非java堆内存,创建成本高,如果进行IO、Socket操作,读取效率要高)
ByteBuffer bufdir = ByteBuffer.allocateDirect(1024);
当使用缓冲区类的 allocate0方法创建新缓冲区时,位置为零并且限制被设置为新缓冲区的容量
3.1.2 wrap通过封装数组来创建缓冲区
通过调用静态 wrap()方法中的一种来封装已有的与缓冲区元素类型相同的数组,也能创建缓冲,使用这种方法创建的缓冲区已经包含数组中的数据。可以通过封装 bytel类型的数组来创建ByteBuffer 对象。
当通过封装数组来创建缓冲区时,缓冲区对象没有自己的内存来存储数据。缓冲区被放在用来定义它的数组的背后,所以对缓冲区中值的修改也会修改数组,反之也一样。缓冲区的容量和限制被设置为数组的长度,位置为零
- 无参wrap()
byte[] bytes= {1,2,3};
ByteBuffer buffer = ByteBuffer.wrap(bytes);
- 有参 wrap(byte[] array, int offset, int length)
String saying = "Handsome is as handsome does.";
// Get string as byte array
byte[] array = saying.getBytes();
ByteBuffer buf = ByteBuffer.wrap(array, 9,14);
缓冲区的容量是 array.length,并且位置被设置为第二个参数的值 9。第三个参数设定要读或写的缓冲区元素的数目,这个值与位置相加就可以定义缓冲区的限制。
3.2 创建视图缓冲区
// Buffer of 1024 bytes capacity
ByteBuffer buf = ByteBuffer.allocate(20);
buf.put((byte)1);
buf.put((byte)2);
// Now create a view buffer,
IntBuffer intBuf buf.asIntBuffer();
视图缓冲区的内容都起始于原始字节缓冲区的当前位置。视图缓冲区本身的位置被初始设置为零,而且容量和限制被设置为由原始字节缓冲区剩余的字节数(limit-position)除以视图缓冲区存储的元素类型所占的字节数目而得到的值。视图缓冲区 的position、limit 与原始字节缓冲区position、limit 相互独立。
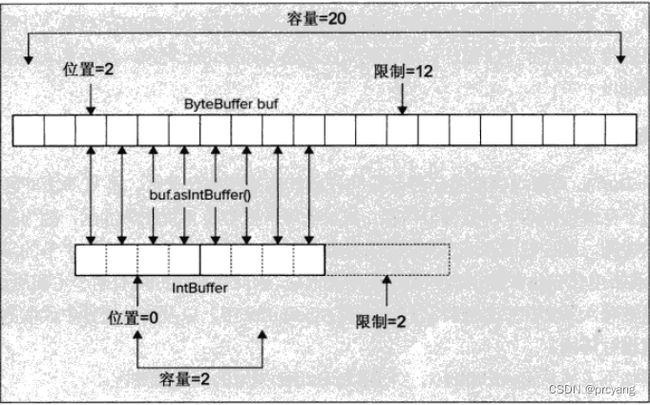
3.3. 复制缓冲区 duplicate
通过调用缓冲区的 duplicate()方法可以复制任何讨论过的缓冲区。该方法返回一个指向缓冲区的引用,其类型与原始缓冲区一样,并且共享原始缓冲区的内容和内存。复制缓冲区与原始缓冲区拥有同样的容量、位置和限制(duplicate时刻只是值一样,两个彼此独立)。但是,虽然对复制内容的修改会反映到原始缓冲区,而且反之也一样,但是原始缓冲区与复制缓冲区的位置和限制都彼此独立。使用复制缓冲区的一种情况是当并行访问缓冲区的不同部分,这使得在复制缓冲区中,能以不影响原始缓冲区的任何方式来提取访问缓冲区内容的不同部分。
因此,复制缓冲区实际上并不真的是内存中的一个新缓冲区,它只是一个新对象,能提供访问用于缓存数据的同一块内存的另一种方式。duplicate0方法返回的指向新对象的通用类型与原始对象的一样,但是没有任何独立的数据存储。这里只是共享属于原始缓存区对象的内存,但是使用独立的位置和限制值。
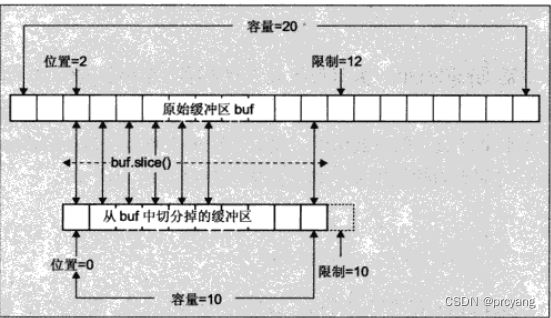
3.4 切分缓冲区slice
由 slice()方法生成的缓冲区会映射到原始缓冲区的一部分-从当前位置开始直到 imit-1的所有元素(包括 limit-1 处的元素)。当然,如果原始缓冲区对象的位置为零并且限制与容量相等,那么slice0方法将产生与 duplicate0方法一样的结果一缓冲区内存被共享。切分缓冲区实际上是通过两个或更多的途径来给予访问缓冲区中给定部分数据的权限,使得切分后的每个缓冲区都有自己独立的位置和限制(调用slice后,新的缓冲区position=0,limit/capacity=原始缓冲区limit-position)
3.5 标记和重置mark和reset
对缓冲区使用标记属性是为了记录缓冲区中想要稍后返回的特定索引位置。通过调用从 Buffer类继承而来的缓冲区对象的 mark0方法,可以将标记设置为当前位置。例如:
buf.position(32);
// Mark the current position 32
buf.mark();
在经过一系列修改位置的操作之后,可以通过调用从 Buffer 类继承而来的 reset0方法,将缓冲区的位置重新设置为之前的标记:
//一系列buf 的操作
// Reset position to last marked 32
buf.reset();
3.6 翻转flip
flip将limit设置为当前位置,然后将位置设置回0
flip 方法源代码
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
flip 方法通常用于由写模式转换为读模式即 完成写操作后 需要读取操作前调用flip
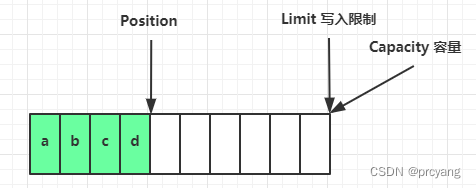
上图是完成写操作,然后调用flip
limit = position;position = 0;
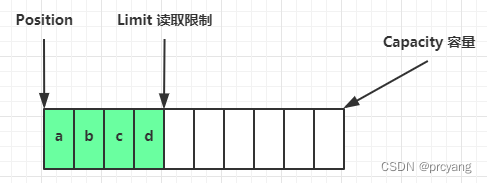
3.7 清除clear
clear0方法将限制设置为容量,将位置设置为零,所以能够将这些值存储为之前创建缓冲区时
它们的状态,但是这不会重新设置缓冲区中的数据,内容会保持不变。如果要重新设置数据,就必
须将新数据传输到缓冲区中。在想要重用缓冲区时通常需要调用 clear0方法
clear 源代码
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}
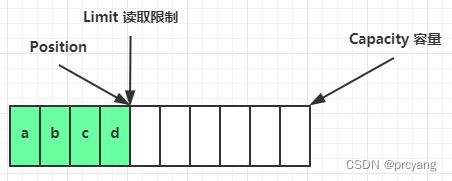
clear 之后
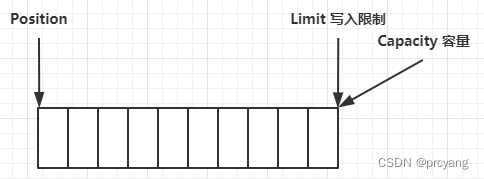
3.8 压缩compact
compact 将position到limit 之间的数据拷贝到从头部(0开始-limit-position)
完成后 position=limit-position. limit=capacity
常用于 读模式切换为写模式
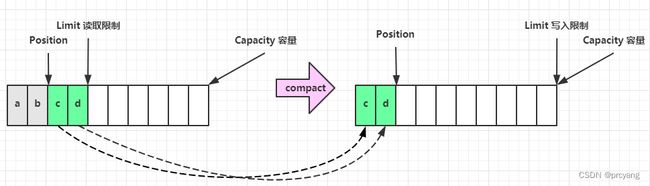
3.9 rewind(倒回)
rewind0方法只是简单地重新将位置设置为零,但不改变限制
rewind 源代码
//Rewinds this buffer. The position is set to zero and the mark is discarded.
public final Buffer rewind() {
position = 0;
mark = -1;
return this;
}
3.10 写数据
- 调用 channel 的 read 方法
- 调用 buffer 自己的 put 方法
//从channel 中读取数据写入buf,buf 的 position 会向后移动 readBytes 位
int readBytes = channel.read(buf);
//position 会向后移动1位
buf.put((byte)127);
| 方法 | 描述 |
|---|---|
| put(byte b) | 将参数指定的字节传输到缓冲区的当前位置并且将位置增加 1如果缓冲区的位置不比限制小,将会抛出BuferOverflowException 类型的异常 |
| put(int index, byte b) | 将第二个参数指定的字节传输到缓冲区中由第一个参数指定的索引位置。缓冲区的位置不会改变。如果索引值为负,或者如果索引值大于或等于缓冲区的限制,将抛出IndexOutOfBoundsException 类型的异常 |
| put(byte[] array) | 将 array 数组中的所有元素都传输到缓冲区中从当前位置开始的位置。位置被增加的值为数组的长度。如果缓冲区中没有足够的空间来存储数组的内容,将会抛出BufferOverflowException 类型的异常 |
| put(bytel] array, int offset, int length) | 从aray[offset]到array[offset+length-1](包括这两个字节)的字节传输到缓冲区中从当前位置开始的位置,位置被增加的值为length。如果缓冲区中没有足够的空间来存储它们,将会抛出BufferOverflowExcepiton类型的异常 |
| put(ByteBuffer src) | 将src中保留的字节即src 中从当前索引位置到limit一1位置的元素传输到缓冲区中(从当前位置开始的位置,位置被增加的值为 src.remaining()),。如果存储这些素的空间不够,将会抛出BufficrOverflowException类型的异常。如果src与当前缓冲区一样尝试将级冲区传输到自身,将会抛出IlegalArgumentException 类型的异常 |
3.11 读数据
- 调用 channel 的 write 方法
- 调用 buffer 自己的 get 方法
//从buf中读取数据,写入channel 中,position 会向后移动 writeBytes 位,注意写后调取 buf.hasRemaining判断是否buf 数据全部写入channel 中(受channel 缓冲区的限制,不一定一次能把buf 中剩余的的数据全部写入channel 中)
int writeBytes = channel.write(buf);
//position 会向后移动1位
byte b = buf.get();
| 方法 | 描述 |
|---|---|
| get() | 提取并返回当前缓冲区位置所在的字节并且增加位置的值 |
| get(int index) | 返回索引位置index上的字节,position 不变 |
| get(byte[]bytes) | 从缓冲区的位置0开始,往后提取 byteslength 个字节对缓冲区的位置值增加bytes.length,然后返回指向当前缓冲区的引用。如果缓冲区中可用的字节数少于bytes.length,将抛出 BufferUnderflowException 类型的异常 |
| get(byte[] bytes,int offset, int length) | 从当前缓冲区位置开始,往后提取 length 个字节并且将它们存储在 bytes 数组中从索引位置ofset开始的地方。缓冲区的位置值会增加 length,指向当前缓冲区的用会被返回。如果可用的字节数少于 length,将会抛出 BufferUnderflowException类型的异常;如果 ofset 和/或 length 的值导致一个非法的数组索引,将会抛出IndexOutOfBoundsException 类型的异常 |
4 常用使用方式
4.1 读写范式
- 向 buffer 写入数据,例如调用 channel.read(buffer)
- 调用 flip() 切换至读模式
- 从 buffer 读取数据,例如调用 buffer.get()
- 调用 clear() 或 compact() 切换至写模式
- 重复 1~4 步骤
4.2 与字符串之间的转换
编码:字符串调用getByte方法获得byte数组,将byte数组放入ByteBuffer中
解码:先调用ByteBuffer的flip方法,然后通过StandardCharsets的decoder方法解码
public class Translate {
public static void main(String[] args) {
// 准备两个字符串
String str1 = "hello";
// 方式1 通过字符串的getByte方法获得字节数组,放入缓冲区中
ByteBuffer buffer1 = ByteBuffer.allocate(16);
buffer1.put(str1.getBytes());
// 切换模式
buffer1.flip();
// 方式2 ByteBuffer buffer1 = ByteBuffer.wrap(str1.getBytes()); //此方式不用flip 因为wrap返回的buf position =0
// 通过StandardCharsets解码,获得CharBuffer,再通过toString获得字符串
String str2 = StandardCharsets.UTF_8.decode(buffer1).toString();
System.out.println(str2);
}
}