【大数据Hive】hive 事务表使用详解
目录
一、前言
二、Hive事务背景知识
hive事务实现原理
hive事务原理之 —— delta文件夹命名格式
_orc_acid_version 说明
bucket_00000
合并器(Compactor)
二、Hive事务使用限制
参数设置
客户端参数设置
客户端参数设置
三、Hive事务使用操作演示
操作步骤
客户端设置参数
创建一张事务表
插入几条数据
删除一条数据
针对事务表的增删改查操作演示
创建事务表
插入一条数据
修改数据
删除数据
一、前言
使用过mysql的同学对mysql的事务这个概念应该不陌生,当对mysql的表进行增删改的时候,mysql会开启一个事务,以确保本次操作的数据的安全性,在hive3.0之后,hive也开始支持了事务,以满足一些增删改的业务场景,接下来将对hive的事务操作做详细的说明。
二、Hive事务背景知识
Hive设计之初时,是不支持事务的,原因:
- Hive的核心目标是将已经存在的结构化数据文件映射成为表,然后提供基于表的SQL分析处理,是一款面向历史、面向分析的工具;
- Hive作为数据仓库,是分析数据规律的,而不是创造数据规律的;
- Hive中表的数据存储于HDFS上,而HDFS是不支持随机修改文件数据的,其常见的模型是一次写入,多次读取;
从Hive0.14版本开始,具有ACID语义的事务(支持INSERT,UPDATE和DELETE)已添加到Hive中,以解决以下场景下遇到的问题:
1)流式传输数据
使用如Apache Flume或Apache Kafka之类的工具将数据流式传输到现有分区中,可能会有脏读(开始查询后能看到写入的数据)
2)变化缓慢数据更新
星型模式数据仓库中,维度表随时间缓慢变化。例如,零售商将开设新商店,需要将其添加到商店表中,或者现有商店可能会更改其平方英尺或某些其他跟踪的特征。这些更改需要插入单个记录或更新记录(取决于所选策略)
3)数据修正
有时发现收集的数据不正确,需要局部更正
hive事务实现原理
Hive的文件是存储在HDFS上的,而HDFS上又不支持对文件的任意修改,只能是采取另外的手段来完成。具体来说:
- 用HDFS文件作为原始数据(基础数据),用delta保存事务操作的记录增量数据;
- 正在执行中的事务,是以一个staging开头的文件夹维护的,执行结束就是delta文件夹。每次执行一次事务操作都会有这样的一个delta增量文件夹;
- 当访问Hive数据时,根据HDFS原始文件和delta增量文件做合并,查询最新的数据;
对于insert,update,delete三种操作来说,
1、INSERT语句会直接创建delta目录;
2、DELETE目录的前缀是delete_delta;
3、UPDATE语句采用了split-update特性,即先删除、后插入;
hive事务原理之 —— delta文件夹命名格式
通过上面的描述,大概了解到hive的事务在执行过程中,delta目录文件很重要,具体来说,一个delta文件的完整名称,可以拆开来看,各个部分的含义需要分别去理解,比如当我们执行一条delete语句开启一个事务时,将会出现类似下面第一条格式的文件;

对于这个文件来说,其完整的含义,可以类比为:delta_minWID_maxWID_stmtID,拆开来看即:
1、即delta前缀、写事务的ID范围、以及语句ID;删除时前缀是delete_delta,里面包含了要删除的文件;
2、Hive会为写事务(INSERT、DELETE等)创建一个写事务ID(Write ID),该ID在表范围内唯一;
3、语句ID(Statement ID)则是当一个事务中有多条写入语句时使用的,用作唯一标识;
而每个事务的delta文件夹下,都存在两个文件

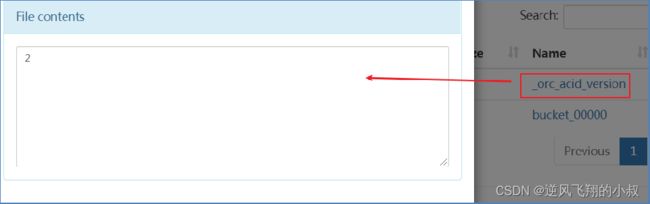
_orc_acid_version 说明
_orc_acid_version的内容是2,即当前ACID版本号是2。和版本1的主要区别是UPDATE语句采用了split-update特性,即先删除、后插入。这个文件不是ORC文件,可以下载下来直接查看。
bucket_00000
bucket_00000文件则是写入的数据内容。如果事务表没有分区和分桶,就只有一个这样的文件。文件都以ORC格式存储,底层二级制,需要使用ORC TOOLS查看,详见附件资料;
可以通过引入相关的依赖包进行查看

对于其中的内容做一下补充说明:
- operation:0 表示插入,1 表示更新,2 表示删除。由于使用了split-update,UPDATE是不会出现的,所以delta文件中的operation是0 , delete_delta 文件中的operation是2;
- originalTransaction、currentTransaction:该条记录的原始写事务ID,当前的写事务ID;
- rowId:一个自增的唯一ID,在写事务和分桶的组合中唯一;
- row:具体数据,对于DELETE语句,则为null,对于INSERT就是插入的数据,对于UPDATE就是更新后的数据;
合并器(Compactor)
随着表的修改操作,创建了越来越多的delta增量文件,就需要合并以保持足够的性能,合并器Compactor是一套在Hive Metastore内运行,支持ACID系统的后台进程。所有合并都是在后台完成的,不会阻止数据的并发读、写。合并后,系统将等待所有旧文件的读操作完成后,删除旧文件。
合并操作分为两种
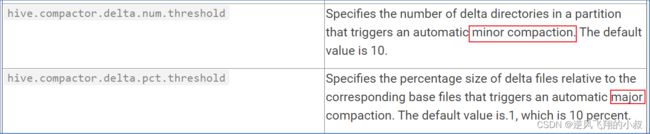
- minor compaction(小合并),小合并会将一组delta增量文件重写为单个增量文件,默认触发条件为10个delta文件;
- major compaction(大合并),大合并将一个或多个增量文件和基础文件重写为新的基础文件,默认触发条件为delta文件相应于基础文件占比10%;
二、Hive事务使用限制
然Hive支持了具有ACID语义的事务,但是在使用起来,并没有像在MySQL中使用那样方便,有很多限制,归纳如下:
- 尚不支持BEGIN,COMMIT和ROLLBACK,所有语言操作都是自动提交的;
- 表文件存储格式仅支持ORC(STORED AS ORC);
- 需要配置参数开启事务使用;
- 外部表无法创建为事务表,因为Hive只能控制元数据,无法管理数据;
- 表属性参数transactional必须设置为true;
- 必须将Hive事务管理器设置为org.apache.hadoop.hive.ql.lockmgr.DbTxnManager才能使用ACID表;
- 事务表不支持LOAD DATA ...语句;
参数设置
在使用hive的事务表时,需要对部分参数做设置之后才能生效,参数的设置可以在客户端,也可以在服务端,两者任选其一;
客户端参数设置
# 可以使用set设置当前session生效 也可以配置在hive-site.xml中)
set hive.support.concurrency = true; --Hive是否支持并发
set hive.enforce.bucketing = true; --从Hive2.0开始不再需要 是否开启分桶功能
set hive.exec.dynamic.partition.mode = nonstrict; --动态分区模式 非严格
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; --事务管理器客户端参数设置
set hive.compactor.initiator.on = true; --是否在Metastore实例上运行启动压缩合并
set hive.compactor.worker.threads = 1; --在此metastore实例上运行多少个合并程序工作线程三、Hive事务使用操作演示
接下来通过实际操作演示下hive事务表的使用
操作步骤
客户端设置参数
打开一个客户端窗口后,执行下面的事务设置参数
set hive.support.concurrency = true; --Hive是否支持并发
set hive.enforce.bucketing = true; --从Hive2.0开始不再需要 是否开启分桶功能
set hive.exec.dynamic.partition.mode = nonstrict; --动态分区模式 非严格
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; --
set hive.compactor.initiator.on = true; --是否在Metastore实例上运行启动压缩合并
set hive.compactor.worker.threads = 1; --在此metastore实例上运行多少个压缩程序工作线程。
创建一张事务表
CREATE TABLE emp (id int, name string, salary int)
STORED AS ORC TBLPROPERTIES ('transactional' = 'true');

插入几条数据
INSERT INTO emp VALUES (1, 'Jerry', 5000);
INSERT INTO emp VALUES (2, 'Tom', 8000);
INSERT INTO emp VALUES (3, 'Kate', 6000);
执行过程可以看到走了M-R任务

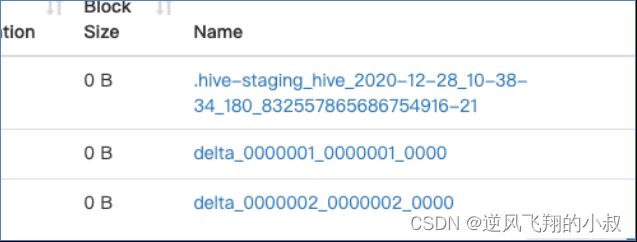
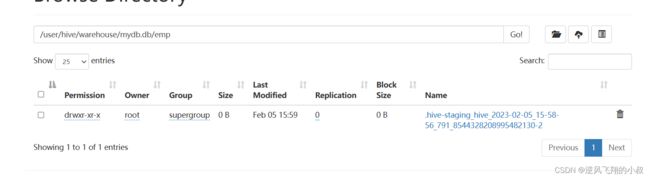
同时执行过程中,观察hdfs目录文件,可以看到产生了下面的staging文件
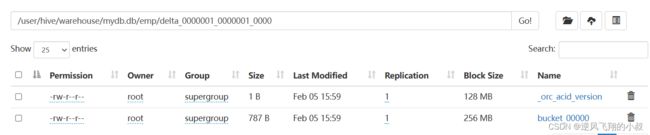
而执行完成后,正好产生了一个_orc_acid_version文件,以及bucket_00000文件;
如果执行多条数据的插入,就会产生多少个下面的文件目录;

查询数据,可以看到已经完成数据的插入;
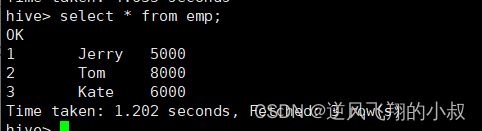
删除一条数据
delete from emp where id =2;
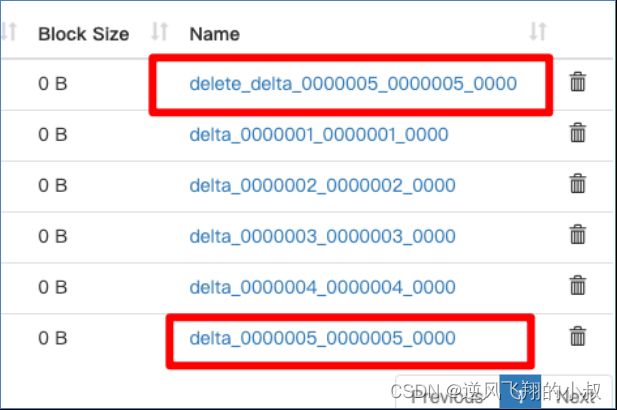
执行删除之后,再次查看hdfs文件目录,可以看到这里多了一个delete_delta文件,关于这个文件上面我们有详细的说明;
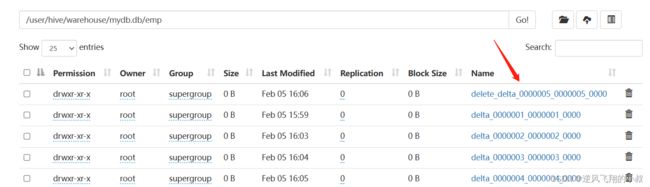
针对事务表的增删改查操作演示
创建事务表
create table trans_student(
id int,
name String,
age int
)stored as orc TBLPROPERTIES('transactional'='true');可以通过describe命令查看表的详细信息
describe formatted trans_student;
插入一条数据
insert into trans_student (id, name, age) values (1,"allen",18);

插入完成后,hdfs文件目录就生成了相关的事务文件
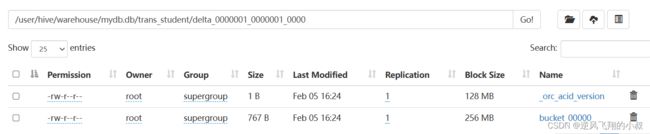
修改数据
update trans_student
set age = 20
where id = 1;
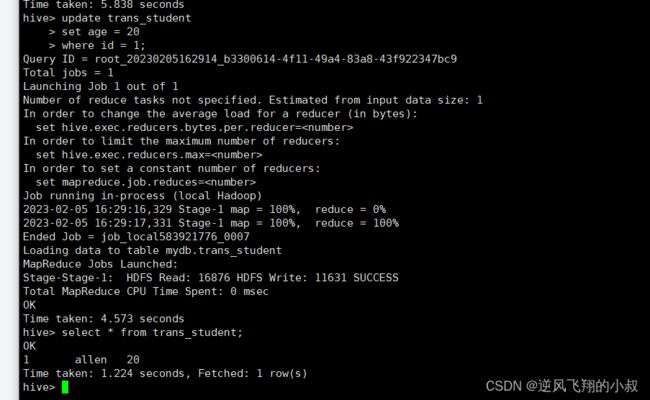
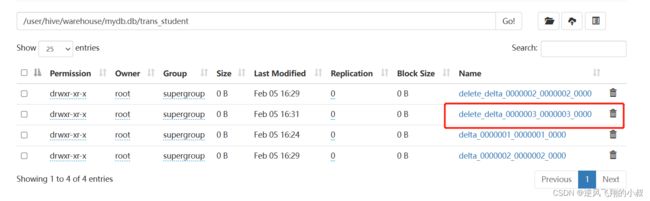
执行完成后,检查hdfs目录就多了一个delete_delta文件;
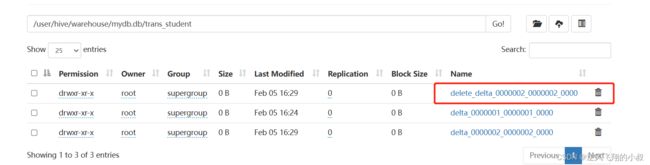
删除数据
delete from trans_student where id =1;
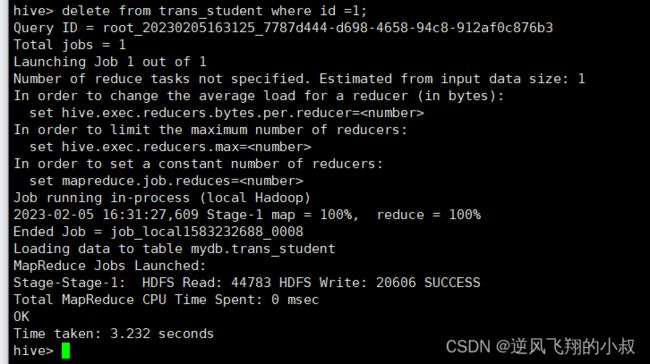
执行完成后,检查hdfs目录又多了一个delete_delta文件;