python爬虫爬取东方财富网股票走势+一些信息
一、目标
我们的目标是爬取东方财富网(https://www.eastmoney.com/)的股票信息
我的目标是爬取100张股票信息图片
经过实际测试我的爬取范围为000001-000110,000960-000999,002540-002557
爬取完图片后从中挑选好股票并且进行数据分析判断
二、设计
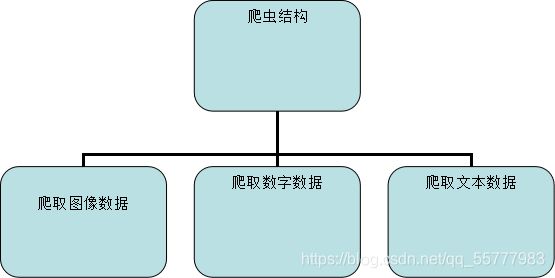
2.1设计框架
通过selenium爬取股票的图片,(需要selenium库)
然后通过request爬取股票的增长信息与文字信息(需要requests库)
爬取的数据需要json化所以需要导入json库(需要json库)
为了记录爬取所需的时间所以我还加入了time库(需要time库)
2.1.1图像数据
先来观察一下网页
000001是我用来测试的第一个目标,我们直接在搜索框中进行搜索。
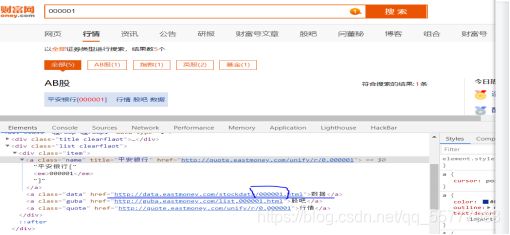
经过查询网页代码,我们发现数据指向的页面的url的格式更方便我们进行爬取。
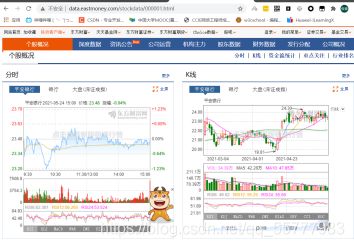
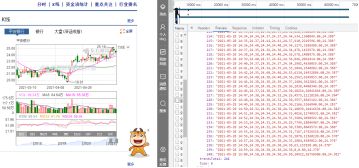
很明显,右边这幅图就是我们需要进行截取的图。
下面我们可以开始写代码
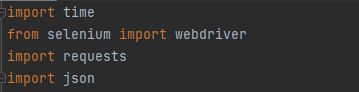
首先,要导入我们的库,并设置好我们的浏览器驱动器的目录
![]()
将我们的爬取作为一个自定义函数
![]()
它需要两个数,分别是开始的股票代码与结束的股票的代码
因为之前发现的url所以我们的股票代码可以先不考虑前面要补位的0
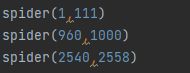
根据我的目标,我传入以下参数
回到我们的自定义函数spider()
先写一个循环
![]()
然后用format补全股票代码
![]()
用我们的驱动器打开网页
![]()
设置浏览器窗口的大小
![]()
这个大小可以根据你要截取的图片大小自行调整
调整网页滚动条
![]()
将其窗口调整到能够显示目标图表的程度
![]()
通过查看网页代码发现title包含了该股票代码的名字
获取目标网页的title,通过“-”分隔出股票代码的名字
![]()
因为有的股票代码会出现空缺位,而空缺位的网页title会特别长所以我们做一个判断
![]()
然后我们可以开始截图,但是我们需要进行精品的判断,以及同比环比数据的爬取和风险的数据,所以我们把这些加入到文件名中(具体爬取看2.1.2和2.1.3)
![]()
截取到图片后以图片股票代码+股票名+是否精品+环比同比+风险的格式命名
2.1.2基本数据
在之前的网页通过分析我们找到了储存图的数据的js
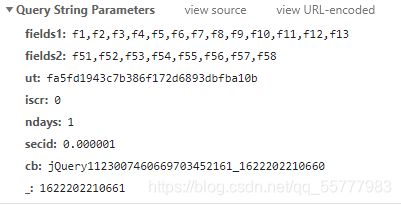
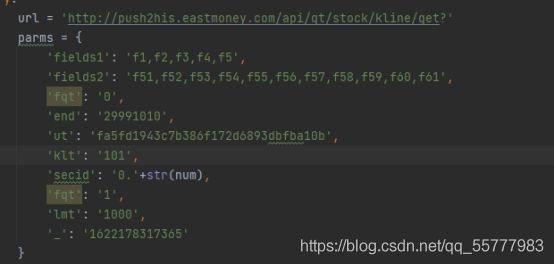
我们拿到需要的url

拿取我们需要的参数
写一个用于判断加精的自定义函数
![]()
通过requests获取数据
![]()
转换为JSON的数据
![]()
通过分析JSON的数据找到需要的股票头和结尾的价格
![]()
将其相减,获得它3个月增了多少或者减了多少,并以此为判断
单只涨了3以上的为精品,并回传一个字符串标识精品
http://data.eastmoney.com/bbsj/(股票代码).html
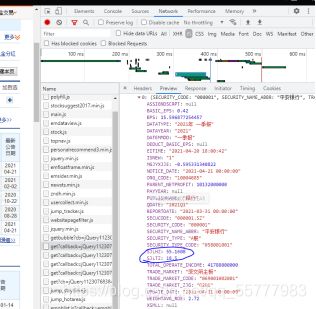
这个网页可以看到我们的同比环比数据

经过分析寻找,我们在一个js中找到了目标数据
这是它的url包含了get传过去的参数
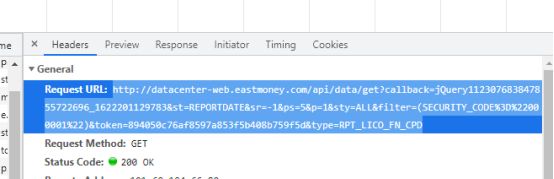
这是我们需要的url部分
![]()
拿上我们需要的参数
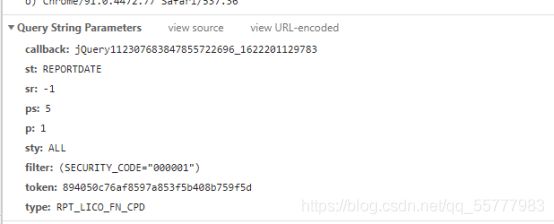
然后我们写一个自定义函数来抓取同比环比数据
![]()
使用我们的url和参数
使用requests库抓取数据
![]()
转换为JSON数据
![]()
通过分析JSON数据我们找到了同比环比存储的地方

将时间和同比环比放入txt并返回
![]()
2.1.3文本数据
http://data.eastmoney.com/bbsj/002206.html
为了有效爬取能代表股票价值的文本,先准备有效的关键词列表。不光是正向的,也包含负向。
分析发现有的会同时出现减少和增加等正负面类型所以受限制于技术我们选择预告类型

拿到需要的URL以及参数
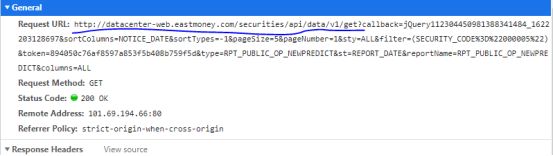
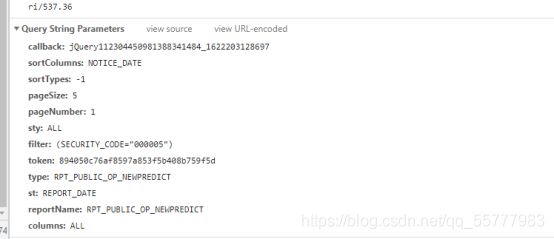
我们写一个自定义函数抓取风险数据
![]()
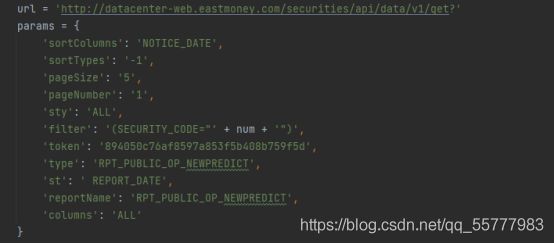
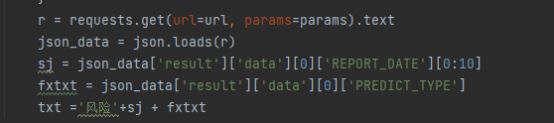
通过requsts获取数据
并转为JSON数据

分析JSON数据,找到风险时间以及数据并回传
最后为各个模块加上防报错机制(具体使用try和except就不细细讲了)
三 总结
测试: 爬虫大小、耗时、正确率、查全率
爬虫大小 4kb
第一次时间测试:
开始时间 2021/5/28 17:21:42
结束时间 2021/5/28 17:36:36
耗时大约15分钟
性能分析:
根据事实讲道理
个人小结:
我认为速度还是偏慢的
我认为可能的原因(欢迎各位大佬指点):
1.网速
2.代码效率
3.selenium自动化测试要亲自打开网页就需要等驱动器渲染页面
4.一些股票代码是空号,程序进入错误的页面在等响应
进步空间还是很大的
初步掌握了简单爬虫的技巧
再附上代码:
import time
from selenium import webdriver
import requests
import json
def sj(num):
try:
url='http://datacenter-web.eastmoney.com/api/data/get?'
parms = {
'st': 'REPORTDATE',
'sr': '-1',
'ps': '5',
'p': '1',
'sty': 'ALL',
'filter': '(SECURITY_CODE="'+num+'")',
'token': '894050c76af8597a853f5b408b759f5d',
'type': 'RPT_LICO_FN_CPD'
}
r = requests.get(url=url, params=parms).text
json_data = json.loads(r)
sj = json_data['result']['data'][0]['REPORTDATE'][0:10]
tb = json_data['result']['data'][0]['SJLTZ']
hb = json_data['result']['data'][0]['SJLHZ']
txt='时间'+str(sj)+'同比'+str(tb)+'环比'+str(hb)
except:
txt = '无数据或错误'
return txt;
def fx(num):
try:
url = 'http://datacenter-web.eastmoney.com/securities/api/data/v1/get?'
params = {
'sortColumns': 'NOTICE_DATE',
'sortTypes': '-1',
'pageSize': '5',
'pageNumber': '1',
'sty': 'ALL',
'filter': '(SECURITY_CODE="' + num + '")',
'token': '894050c76af8597a853f5b408b759f5d',
'type': 'RPT_PUBLIC_OP_NEWPREDICT',
'st': ' REPORT_DATE',
'reportName': 'RPT_PUBLIC_OP_NEWPREDICT',
'columns': 'ALL'
}
r = requests.get(url=url, params=params).text
json_data = json.loads(r)
sj = json_data['result']['data'][0]['REPORT_DATE'][0:10]
fxtxt = json_data['result']['data'][0]['PREDICT_TYPE']
txt ='风险'+sj + fxtxt
except:
txt='风险无数据'
return txt;
def xl(num):
try:
url = 'http://push2his.eastmoney.com/api/qt/stock/kline/get?'
parms = {
'fields1': 'f1,f2,f3,f4,f5',
'fields2': 'f51,f52,f53,f54,f55,f56,f57,f58,f59,f60,f61',
'fqt': '0',
'end': '29991010',
'ut': 'fa5fd1943c7b386f172d6893dbfba10b',
'klt': '101',
'secid': '0.'+str(num),
'fqt': '1',
'lmt': '1000',
'_': '1622178317365'
}
r = requests.get(url=url, params=parms).text
data = json.loads(r)
txt = float(json.dumps(data['data']['klines'][945]).split(",")[1])
txt2 = float(json.dumps(data['data']['klines'][999]).split(",")[1])
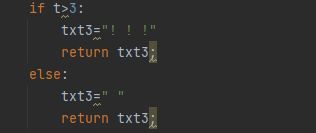
t = txt2 - txt
if t>3:
txt3="! ! !"
return txt3;
else:
txt3=" "
return txt3;
except:
txt3="? ? ?"
return txt3;
def spider(a,b):
driver = webdriver.Chrome(executable_path="F:\webdriver\chromedriver.exe")
for i in range(a, b):
try:
num = '{:0>6d}'.format(i)//补全股票代码
driver.get("http:data.eastmoney.com/stockdata/" + num + ".html")
driver.set_window_size(200,400)
driver.execute_script('window.scrollBy(800,650)')
title = driver.title
title = title.split("_", 1)[0]
if len(title)>10:
continue
data = sj(num)
txt = fx(num)
x=xl(num)
driver.get_screenshot_as_file("F:\picture\ " + num + title +x+ data + txt + ".png")//截图并保存到该路径下命名为
except:
continue
time1=time.localtime(time.time())
now1=time.strftime("%Y/%m/%d %H:%M:%S",time1)//按年月日 小时分钟秒格式 开始时间
print(now1)
spider(1,111)
spider(960,999)
spider(2540,2558)
time2=time.localtime(time.time())
now2=time.strftime("%Y/%m/%d %H:%M:%S",time2)//按年月日 小时分钟秒格式 结束时间
print(now2)