FLINKSQL自定义UDF函数1之collect_list&collect_set
FLINKSQL自定义UDF函数1之collect_list&collect_set`
文章目录
- FLINKSQL自定义UDF函数1之collect_list&collect_set`
- 前言
- 一、collection_list
-
- 1.编写CollectList类
-
- 注意点
-
- 1.1类型的输入
- 1.2方法
- 1.3测试结果展示
- 2.collection_set
-
- 注意点
-
- 1.1这里我使用Set直接作为ACC有问题
- 1.2 测试结果
- 总结
前言
由于flink里面没有hive的collection_list以及collection_set的函数,因此我们需要自定义聚合函数也就是相当于是AGGREGATION来实现,多条数据汇集输出对应的一条数据.
一、collection_list
1.编写CollectList类
代码如下(示例):
public class CollectList extends AggregateFunction<String[],List<String>> {
public void retract(List acc,String conlum){
acc.remove(conlum);
}
public void accumulate(List acc,String conlum){
acc.add(conlum);
}
@Override
public String[] getValue(List list) {
return (String[]) list.toArray(new String[0]);
}
@Override
public List createAccumulator() {
List list = new ArrayList<>();
return list;
}
public void resetAccumulator(List list){
list.clear();
}
}
测试类
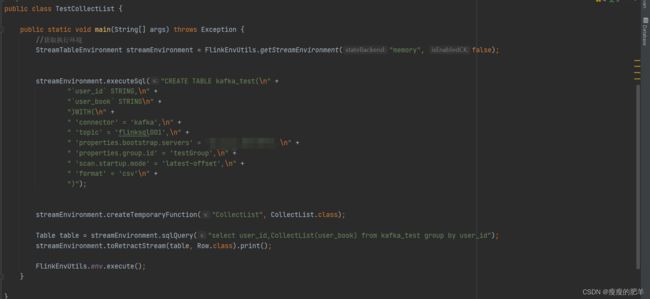
注意点
1.1类型的输入
public class CollectList extends AggregateFunction<String[],List<String>>
这里我们第一个参数是输出的结果类型,第二个参数是累加器的类型,但是可以看到这里我类型是List,但是对于后面的具体方法的实现的时候我并没有写明泛型,这里其实写不写应该不影响,java会自动根据类型推断,不写的原因还有就是可能后面写明具体类型,可能会报错。
1.2方法
可以看到对于这个类有三个方法是必须实现的
1.createAccumulator:创建一个累加器
2.accumulate:累加的规则
3.getValue:获取结果
需要注意的是如果我们的流式数据结果涉及到回撤流,那么我们还需要实现以下方法
retract,resetAccumulator
注意这些方法都要是public并且非static的。
1.3测试结果展示


2.collection_set
代码如下(示例):
public class CollectSet extends AggregateFunction<String[], List<String>> {
public void accumulate(List acc,String column){
acc.add(column);
}
public void retract(List acc,String column){
acc.remove(column);
}
@Override
public String[] getValue(List list) {
Set set= new HashSet(list);
return (String[]) set.toArray(new String[0]);
}
@Override
public List createAccumulator() {
List list = new ArrayList();
return list;
}
public void resetAccumulator(List acc){
acc.clear();
}
// public static void main(String[] args) {
// Set set=new HashSet<>();
// System.out.println(HashSet.class.getModifiers());
// }
}
测试类

注意点
1.1这里我使用Set直接作为ACC有问题
开始我先传的是
public class CollectSet extends AggregateFunction<String[], Set<String>>
之后报错说 must no abstract,之后通过看源码发现,再数据类型校验的时候,因为我们的Set其实底层是调用的Map接口,所以然后源码判断的时候走了map的下层判断,走到java.util.set的时候可以看到他会计算你的标识符
public static void main(String[] args) {
Set<String> set=new HashSet<>();
System.out.println(HashSet.class.getModifiers());
}
通过反射拿到标识符,当当前的class是接口或者是抽象类的时候,返回的int值就是1537
然后就会报错,因此我后面换成了 hashset具体的实现类,但是源码校验的时候再次报错

在这一步,进去看到下一步

可以看到这里把当前类包括父类的属性字段都遍历判断了,但是会把static,transient标识的字段排除,所以很遗憾,对于Hashset里面其实还是调用的Hashmap,只有个序列化ID,还有就是transient的

所以报错Class HashSet has no fields.
因此我后面选择直接还是使用List,只不过去重的时候调用了Set.
1.2 测试结果


总结
本节记录了FLINKSQLUDF的实现,包括报错的排查等,还是很有意义的,对于以后的编写以及排错都是一个好的开始,bug不可怕!解决一个我们就成长一步,一起加油吧!