图像分割工具箱 Segmentation model pytorch安装+使用教程
一、smp介绍
GitHub地址:https://github.com/qubvel/segmentation_models.pytorch#installation
这个库的主要特点:
-
高级API(只需两行即可创建神经网络)
-
用于二进制和多类分割的9种模型架构(包括传奇的Unet)
-
113个可用编码器
-
所有编码器都有预训练的权重,以便更快更好的收敛
二、smp安装
(默认环境已经安装anaconda)
首先创建一个虚拟环境
conda create -n segmentation python==3.7segmentation 是环境的名字 python==3.7 是python的版本 可以按照实际需求进行修改
创建好虚拟环境后,开始安装smp(segmentation models pytorch)
pip install segmentation-models-pytorch安装segmentation-models-pytorch会一同安装上torch和torchvision,但是安装的是CPU版本的最新的pytorch,CPU跑smp会非常痛苦,慢的离谱(200 epoch 放在中配游戏本需要24+小时(使用GPU加速),如果纯用CPU跑需要非常非常久的时间,非常不建议),这里就需要把他自动给你下载的torch和torchvisvion卸载掉
pip uninstall torchpip uninstall torchvisvion卸载完成后去下载torch 和 torchvision 这里注意要下载与电脑环境一一对应的版本
关于如何查看cuda版本:
win + R 输入cmd 再按回车打开命令行窗口 输入
nvcc --version即可查看cuda版本
https://download.pytorch.org/whl/torch_stable.html进入这个网站下载合适的torch 和 torchvision
torch-1.7.1+cu110-cp37-cp37m-win_amd64.whl
torchvision-0.8.2+cu110-cp37-cp37m-win_amd64.whl网上教程给的是这两个版本,为了保守也可以直接下载这个版本
在 Anaconda Prompt里面cd +文件下载的位置
如:把文件下载到桌面 cd Desktop
跳转到下载文件地址后开始安装
pip install torch-1.7.1+cu110-cp37-cp37m-win_amd64.whl
pip install torchvision-0.8.2+cu110-cp37-cp37m-win_amd64.whl同时还需要安装以下库
pip install albumentations
pip install matplotlib
pip install imageio
pip install opencv-python安装好之后去pycharm创建这个环境,在anaconda安装目录里面有个envs,找到你那个环境名字命名的文件夹,选择python.exe就
到此为止这个环境安装好,因为每个环境有所差异,所以如果代码报错缺少什么库,去下载就行了,这里介绍几个pip 的镜像,用这几个镜像下载比较快,包括上面的也可以用镜像下载,只不过我忘记说了
阿里云 http://mirrors.aliyun.com/pypi/simple/
豆瓣 http://pypi.douban.com/simple/
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学http://pypi.hustunique.com/
#使用方法:
pip install opencv-python -i https://pypi.douban.com/simple/
opencv-python 可以换成你需要安装的库
-i 后面填写一个你喜欢的镜像就
www.baidu.com里面有很多教程,遇到问题可以查查教程,会大有收获,不要怕电脑会弄坏,弄坏了想办法弄回来就行了三、smp使用 以Unet++为例子
数据集的准备
smp的数据集这块也算是踩雷踩了好几次,smp的数据集格式如下:
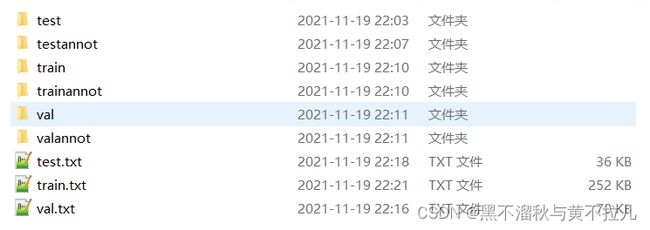
测试集的原图像、测试集的标注图像、训练集的原图像、训练集的标注图像、验证集的原图像、验证集的标注图像
大部分标注选择labelme或者网上下载来的数据集进行处理,这里存在一个比较棘手的问题,labelme标注完成后生成json,json转化完成出来的label.png是二值图像,0 255的图像,但是CamVid数据集比较奇妙的地方是他以像素点的值为标签,对于二分类图像,一般class=['background','objective'],网络以像素点为0的值为class[0],以像素点为1的值为class[1],所以可以查看CamVid原始数据集中很多的类,训练中选中的类为[car],所以对于我们自己的数据集,需要进行处理,二分类的像素值处理是最简单的,直接像素点转换成矩阵然后/255.0即可,简单粗暴,这里强烈建议用遍历文件夹内每一个数据去进行操作,千万不要一张一张人手去更改path,这样处理完成之后看上去就是一张黑乎乎的图片,肉眼分辨不出来不代表人家没有,现在实际上是0 1像素值,背景像素值依旧为0,目标像素值现在已经为1了。这时候放进去训练一点点问题都没
对于这三个txt可能第一眼看上去会头疼,里面内容是数据与标签path的一一对应,在实践中我发现一个比较巧妙的方法,有点投机取巧,使用excel,把第一个path和第二个path填写好,选中下拉自动填充,完了之后两列一起复制粘贴到txt,再用查找替换的方式把中间那个长空隙替换为一个空格,简单高效顶呱呱
smp数据集整理好之后就可以开始看代码了
smp真的yyds用起来巨方便,调过GitHub上代码的都会发现,一个网络一个环境,配置起来比较麻烦而且不一定能跑通,smp就更改几个参数就行了,简单高效,下面来瞅一瞅这个代码
首先贴上rain.py 和text.py
#train.py
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import numpy as np
import cv2
import matplotlib.pyplot as plt
import albumentations as albu
import torch
import segmentation_models_pytorch as smp
from torch.utils.data import DataLoader
from torch.utils.data import Dataset as BaseDataset
# ---------------------------------------------------------------
### 加载数据
class Dataset(BaseDataset):
"""CamVid数据集。进行图像读取,图像增强增强和图像预处理.
Args:
images_dir (str): 图像文件夹所在路径
masks_dir (str): 图像分割的标签图像所在路径
class_values (list): 用于图像分割的所有类别数
augmentation (albumentations.Compose): 数据传输管道
preprocessing (albumentations.Compose): 数据预处理
"""
# CamVid数据集中用于图像分割的所有标签类别
CLASSES = ['sky', 'building', 'pole', 'road', 'pavement',
'tree', 'signsymbol', 'fence', 'car',
'pedestrian', 'bicyclist', 'unlabelled']
def __init__(
self,
images_dir,
masks_dir,
classes=None,
augmentation=None,
preprocessing=None,
):
self.ids = os.listdir(images_dir)
self.images_fps = [os.path.join(images_dir, image_id) for image_id in self.ids]
self.masks_fps = [os.path.join(masks_dir, image_id) for image_id in self.ids]
# convert str names to class values on masks
self.class_values = [self.CLASSES.index(cls.lower()) for cls in classes]
self.augmentation = augmentation
self.preprocessing = preprocessing
def __getitem__(self, i):
# read data
image = cv2.imread(self.images_fps[i])
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
mask = cv2.imread(self.masks_fps[i], 0)
# 从标签中提取特定的类别 (e.g. cars)
masks = [(mask == v) for v in self.class_values]
mask = np.stack(masks, axis=-1).astype('float')
# 图像增强应用
if self.augmentation:
sample = self.augmentation(image=image, mask=mask)
image, mask = sample['image'], sample['mask']
# 图像预处理应用
if self.preprocessing:
sample = self.preprocessing(image=image, mask=mask)
image, mask = sample['image'], sample['mask']
return image, mask
def __len__(self):
return len(self.ids)
# ---------------------------------------------------------------
### 图像增强
def get_training_augmentation():
train_transform = [
albu.HorizontalFlip(p=0.5),
albu.ShiftScaleRotate(scale_limit=0.5, rotate_limit=0, shift_limit=0.1, p=1, border_mode=0),
albu.PadIfNeeded(min_height=320, min_width=320, always_apply=True, border_mode=0),
albu.RandomCrop(height=320, width=320, always_apply=True),
albu.IAAAdditiveGaussianNoise(p=0.2),
albu.IAAPerspective(p=0.5),
albu.OneOf(
[
albu.CLAHE(p=1),
albu.RandomBrightness(p=1),
albu.RandomGamma(p=1),
],
p=0.9,
),
albu.OneOf(
[
albu.IAASharpen(p=1),
albu.Blur(blur_limit=3, p=1),
albu.MotionBlur(blur_limit=3, p=1),
],
p=0.9,
),
albu.OneOf(
[
albu.RandomContrast(p=1),
albu.HueSaturationValue(p=1),
],
p=0.9,
),
]
return albu.Compose(train_transform)
def get_validation_augmentation():
"""调整图像使得图片的分辨率长宽能被32整除"""
test_transform = [
albu.PadIfNeeded(384, 480)
]
return albu.Compose(test_transform)
def to_tensor(x, **kwargs):
return x.transpose(2, 0, 1).astype('float32')
def get_preprocessing(preprocessing_fn):
"""进行图像预处理操作
Args:
preprocessing_fn (callbale): 数据规范化的函数
(针对每种预训练的神经网络)
Return:
transform: albumentations.Compose
"""
_transform = [
albu.Lambda(image=preprocessing_fn),
albu.Lambda(image=to_tensor, mask=to_tensor),
]
return albu.Compose(_transform)
#$# 创建模型并训练
# ---------------------------------------------------------------
if __name__ == '__main__':
# 数据集所在的目录
DATA_DIR = './data/CamVid/'
# 如果目录下不存在CamVid数据集,则克隆下载
if not os.path.exists(DATA_DIR):
print('Loading data...')
os.system('git clone https://github.com/alexgkendall/SegNet-Tutorial ./data')
print('Done!')
# 训练集
x_train_dir = os.path.join(DATA_DIR, 'train')
y_train_dir = os.path.join(DATA_DIR, 'trainannot')
# 验证集
x_valid_dir = os.path.join(DATA_DIR, 'val')
y_valid_dir = os.path.join(DATA_DIR, 'valannot')
ENCODER = 'se_resnext50_32x4d'
ENCODER_WEIGHTS = 'imagenet'
CLASSES = ['car']
ACTIVATION = 'sigmoid' # could be None for logits or 'softmax2d' for multiclass segmentation
DEVICE = 'cuda'
# 用预训练编码器建立分割模型
# 使用FPN模型
# model = smp.FPN(
# encoder_name=ENCODER,
# encoder_weights=ENCODER_WEIGHTS,
# classes=len(CLASSES),
# activation=ACTIVATION,
# )
# 使用unet++模型
model = smp.UnetPlusPlus(
encoder_name=ENCODER,
encoder_weights=ENCODER_WEIGHTS,
classes=len(CLASSES),
activation=ACTIVATION,
)
preprocessing_fn = smp.encoders.get_preprocessing_fn(ENCODER, ENCODER_WEIGHTS)
# 加载训练数据集
train_dataset = Dataset(
x_train_dir,
y_train_dir,
augmentation=get_training_augmentation(),
preprocessing=get_preprocessing(preprocessing_fn),
classes=CLASSES,
)
# 加载验证数据集
valid_dataset = Dataset(
x_valid_dir,
y_valid_dir,
augmentation=get_validation_augmentation(),
preprocessing=get_preprocessing(preprocessing_fn),
classes=CLASSES,
)
# 需根据显卡的性能进行设置,batch_size为每次迭代中一次训练的图片数,num_workers为训练时的工作进程数,如果显卡不太行或者显存空间不够,将batch_size调低并将num_workers调为0
train_loader = DataLoader(train_dataset, batch_size=2, shuffle=True, num_workers=0)
valid_loader = DataLoader(valid_dataset, batch_size=1, shuffle=False, num_workers=0)
loss = smp.utils.losses.DiceLoss()
metrics = [
smp.utils.metrics.IoU(threshold=0.5),
]
optimizer = torch.optim.Adam([
dict(params=model.parameters(), lr=0.0001),
])
# 创建一个简单的循环,用于迭代数据样本
train_epoch = smp.utils.train.TrainEpoch(
model,
loss=loss,
metrics=metrics,
optimizer=optimizer,
device=DEVICE,
verbose=True,
)
valid_epoch = smp.utils.train.ValidEpoch(
model,
loss=loss,
metrics=metrics,
device=DEVICE,
verbose=True,
)
# 进行40轮次迭代的模型训练
max_score = 0
for i in range(0, 40):
print('\nEpoch: {}'.format(i))
train_logs = train_epoch.run(train_loader)
valid_logs = valid_epoch.run(valid_loader)
# 每次迭代保存下训练最好的模型
if max_score < valid_logs['iou_score']:
max_score = valid_logs['iou_score']
torch.save(model, './best_model.pth')
print('Model saved!')
if i == 25:
optimizer.param_groups[0]['lr'] = 1e-5
print('Decrease decoder learning rate to 1e-5!')#test.py
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import numpy as np
import cv2
import matplotlib.pyplot as plt
import albumentations as albu
import torch
import segmentation_models_pytorch as smp
from torch.utils.data import Dataset as BaseDataset
# ---------------------------------------------------------------
### 加载数据
class Dataset(BaseDataset):
"""CamVid数据集。进行图像读取,图像增强增强和图像预处理.
Args:
images_dir (str): 图像文件夹所在路径
masks_dir (str): 图像分割的标签图像所在路径
class_values (list): 用于图像分割的所有类别数
augmentation (albumentations.Compose): 数据传输管道
preprocessing (albumentations.Compose): 数据预处理
"""
# CamVid数据集中用于图像分割的所有标签类别
CLASSES = ['sky', 'building', 'pole', 'road', 'pavement',
'tree', 'signsymbol', 'fence', 'car',
'pedestrian', 'bicyclist', 'unlabelled']
def __init__(
self,
images_dir,
masks_dir,
classes=None,
augmentation=None,
preprocessing=None,
):
self.ids = os.listdir(images_dir)
self.images_fps = [os.path.join(images_dir, image_id) for image_id in self.ids]
self.masks_fps = [os.path.join(masks_dir, image_id) for image_id in self.ids]
# convert str names to class values on masks
self.class_values = [self.CLASSES.index(cls.lower()) for cls in classes]
self.augmentation = augmentation
self.preprocessing = preprocessing
def __getitem__(self, i):
# read data
image = cv2.imread(self.images_fps[i])
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
mask = cv2.imread(self.masks_fps[i], 0)
# 从标签中提取特定的类别 (e.g. cars)
masks = [(mask == v) for v in self.class_values]
mask = np.stack(masks, axis=-1).astype('float')
# 图像增强应用
if self.augmentation:
sample = self.augmentation(image=image, mask=mask)
image, mask = sample['image'], sample['mask']
# 图像预处理应用
if self.preprocessing:
sample = self.preprocessing(image=image, mask=mask)
image, mask = sample['image'], sample['mask']
return image, mask
def __len__(self):
return len(self.ids)
# ---------------------------------------------------------------
### 图像增强
def get_validation_augmentation():
"""调整图像使得图片的分辨率长宽能被32整除"""
test_transform = [
albu.PadIfNeeded(384, 480)
]
return albu.Compose(test_transform)
def to_tensor(x, **kwargs):
return x.transpose(2, 0, 1).astype('float32')
def get_preprocessing(preprocessing_fn):
"""进行图像预处理操作
Args:
preprocessing_fn (callbale): 数据规范化的函数
(针对每种预训练的神经网络)
Return:
transform: albumentations.Compose
"""
_transform = [
albu.Lambda(image=preprocessing_fn),
albu.Lambda(image=to_tensor, mask=to_tensor),
]
return albu.Compose(_transform)
# 图像分割结果的可视化展示
def visualize(**images):
"""PLot images in one row."""
n = len(images)
plt.figure(figsize=(16, 5))
for i, (name, image) in enumerate(images.items()):
plt.subplot(1, n, i + 1)
plt.xticks([])
plt.yticks([])
plt.title(' '.join(name.split('_')).title())
plt.imshow(image)
plt.show()
# ---------------------------------------------------------------
if __name__ == '__main__':
DATA_DIR = './data/CamVid/'
# 测试集
x_test_dir = os.path.join(DATA_DIR, 'test')
y_test_dir = os.path.join(DATA_DIR, 'testannot')
ENCODER = 'se_resnext50_32x4d'
ENCODER_WEIGHTS = 'imagenet'
CLASSES = ['car']
ACTIVATION = 'sigmoid' # could be None for logits or 'softmax2d' for multiclass segmentation
DEVICE = 'cuda'
preprocessing_fn = smp.encoders.get_preprocessing_fn(ENCODER, ENCODER_WEIGHTS)
# ---------------------------------------------------------------
#$# 测试训练出来的最佳模型
# 加载最佳模型
best_model = torch.load('./best_model.pth')
# 创建测试数据集
test_dataset = Dataset(
x_test_dir,
y_test_dir,
augmentation=get_validation_augmentation(),
preprocessing=get_preprocessing(preprocessing_fn),
classes=CLASSES,
)
# ---------------------------------------------------------------
#$# 图像分割结果可视化展示
# 对没有进行图像处理转化的测试集进行图像可视化展示
test_dataset_vis = Dataset(
x_test_dir, y_test_dir,
classes=CLASSES,
)
# 从测试集中随机挑选3张图片进行测试
for i in range(3):
n = np.random.choice(len(test_dataset))
image_vis = test_dataset_vis[n][0].astype('uint8')
image, gt_mask = test_dataset[n]
gt_mask = gt_mask.squeeze()
x_tensor = torch.from_numpy(image).to(DEVICE).unsqueeze(0)
pr_mask = best_model.predict(x_tensor)
pr_mask = (pr_mask.squeeze().cpu().numpy().round())
visualize(
image=image_vis,
ground_truth_mask=gt_mask,
predicted_mask=pr_mask
)
下面就讲解一下如何修改参数
首先修改train.py 29行的class这里,修改为自己设置的类别,修改完总的class,也需要修改需要网络识别的类别,在174行
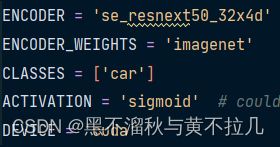
这里五个参数主要修改编码器、权重、类别、激活函数、cuda加速
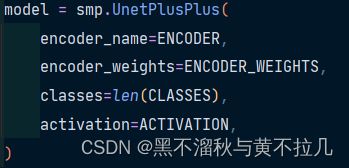
这个代码块主要时选择网络
![]()
smp可选的网络有以上几种,这行不在train.py里面,是封装好的代码,可以打开阅读
使用时,只需要根据需求把这个改了就可以,真的简单方便
网络中loss的选择有 JaccardLoss 、 DiceLoss、 L1Loss、 MSELoss、CrossEntropyLoss、NLLLoss、BCELoss、BCEWithLogitsLoss但是作者只写了前面两个的代码,后面的代码块都是pass,所以如果需要用到,那么就要自己去写代码(loss修改在218行)
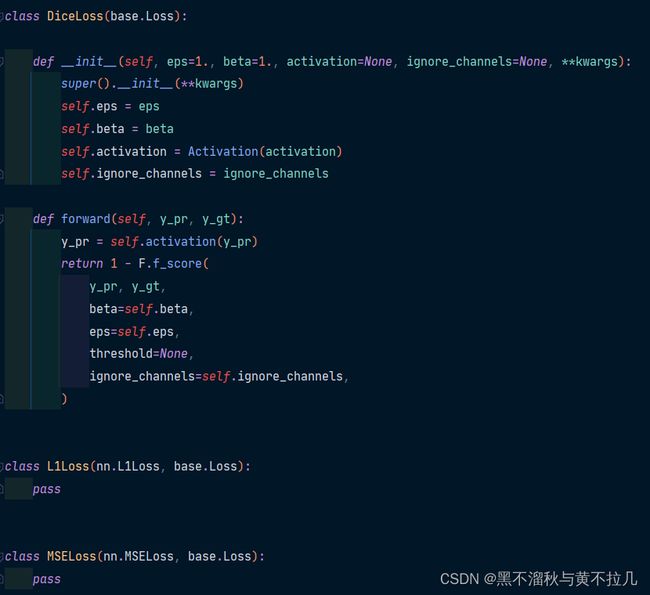
然后就是iou等这类评分标准,官方给出的有IoU、Fscore、Accuracy 、Recall(召回率)、Precision(精确率),具体的公式网上都有,这里不过多赘述
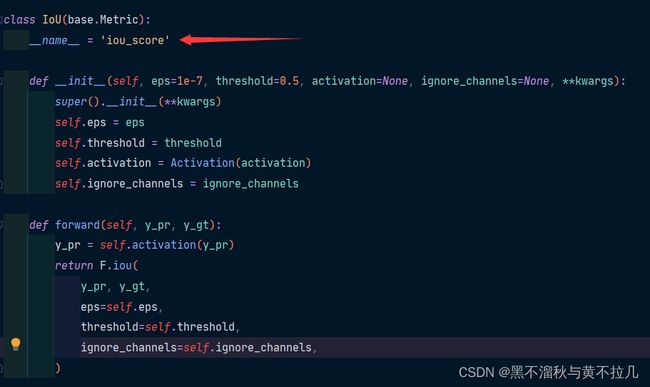
看到打箭头这一行没,下面几个代码块是没有这一行的,用的时候自己按照这个样子写一个上去,但别傻不愣登给名字都取一样,注意区分度
train.py再往下看,就到了迭代轮次的地方,就是常见的epoch,这里将epoch直接用一个for循环安排上,简单粗暴
for i in range(0, 40)直接修改这个for里面的参数就ok
test 和 train 大同小异,需要注意的是test测试数据是不保存的,如果你要保存数据需要自己编写代码
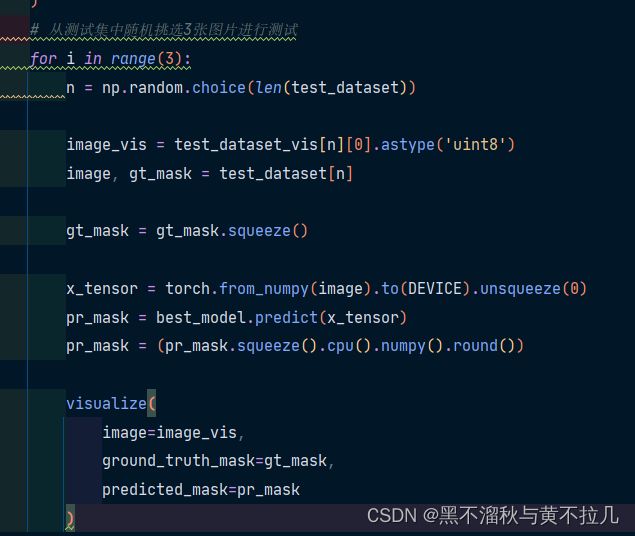
就这一块,这个for几就是测试几张图片,如果需要增加保存代码的话也是在for循环里面保存。
四、总结
以上就是对smp这个库使用的冰山一角的说明,smp是一个很神奇的库,功能很强大,作者在很多地方都留有空白可以让你自己发挥创意和想法,对初级使用起来也很友好。上述内容适合smp入门,很多地方也都是自己的理解,如果理解不到位或者理解错误也请及时指出。