lab3 pgtbl
Pre
在这个lab中,你将探索页表,并且修改它们以简化从用户空间拷贝数据到内核空间的函数
在开始之前,需要完成
- 阅读xv6 book的第3章
kern/memlayout.h有关内存的布局kern/vm.c包含大部分虚拟内存的代码kernel/kalloc.c分配和释放虚拟内存的代码
内存布局

Print a page table
task
-
定义一个叫做
vmprint(pagetable_t)的函数,用下面的格式打印页表 -
添加
if(p->pid==1) vmprint(p->pagetable)到exec.c中return argc语句前面,这将会打印第一个进程的页表 -
通过
make grade的pte printout进行测试,也可以./grade-lab-pgtbl pte printout
打印的格式如下
- 首先从根页表开始从上到下地递归地打印,并且只打印有效的页表项
- 具体到每一个页表项
- 加入是第
x级的页表,那就先打印x个.. - 然后打印这个页表项在这个页表中的索引
- pte后面紧跟着的内容是这个页表项的所有内容,总共64bit
- pa后面紧跟着的就是这个页表项指向的地址,假设pte页表项的内容是
val,那么pa=((val>>10)<<12),xv6中已经定义了一个宏来实现
- 加入是第
page table 0x0000000087f6e000
..0: pte 0x0000000021fda801 pa 0x0000000087f6a000
.. ..0: pte 0x0000000021fda401 pa 0x0000000087f69000
.. .. ..0: pte 0x0000000021fdac1f pa 0x0000000087f6b000
.. .. ..1: pte 0x0000000021fda00f pa 0x0000000087f68000
.. .. ..2: pte 0x0000000021fd9c1f pa 0x0000000087f67000
..255: pte 0x0000000021fdb401 pa 0x0000000087f6d000
.. ..511: pte 0x0000000021fdb001 pa 0x0000000087f6c000
.. .. ..510: pte 0x0000000021fdd807 pa 0x0000000087f76000
.. .. ..511: pte 0x0000000020001c0b pa 0x0000000080007000
hints
- 在
kernel/vm.c中完成这个函数 - 使用
kernel/riscv.h中定义的宏 freewalk将给你灵感- 记得在
kernel/defs.h中声明你的函数,这样才可以在exec函数中使用它 - 使用
%p去打印64bit的pte和address
思路
- 先看看
freewalk中是如何遍历这三级页表的,思路就比较清晰了 - 这里用了一个depth控制当前位于第几级页表,方便打印和控制递归的终点
int depth = 0;
void print_prefix(int i) {
for (int i = 0; i <= depth; i++) {
printf("..");
if (i < depth) {
printf(" ");
}
}
printf("%d: ", i);
}
void vmprint(pagetable_t pagetable) {
printf("page table %p\n", pagetable);
for (int i = 0; i < 512; i++) {
pte_t pte = pagetable[i];
// 如果这一项有效
if (pte & PTE_V) {
print_prefix(i);
printf("pte %p ", pte);
printf("pa %p", PTE2PA(pte));
printf("\n");
if (depth < 2) {
depth++;
vmprint((pagetable_t)PTE2PA(pte));
depth--;
}
}
}
}

A kernel page table per process
这个task和下一个task的目标就是使得内核可以直接解引用进程传递的指针
task
- 在这个task中,你先修改kernel,使得每个进程在内核态的时候都可以用它自己对内核页表的拷贝
- 修改
struct proc为每个进程都维护一个内核页表 - 修改
scheduler使得进程切换的时候切换内核的页表 - 完成到这一步时,每个进程中的内核页表都应该和现在的全局内核页表相同
- 如果你能通过
usertests就说明完成了这个task
hints
-
在
struct proc中增加一个字段表示这个进程独有的内核页表 -
为一个新进程创造一个内核页表的合理的方法是
实现一个
kvminit的新版本,这个新版本会创建一个新的页表,而不是修改已有的页表你需要在
allocproc中调用这个新的函数 -
保证每个进程的内核页表都有一个映射,这个映射可以找到进程的内核栈
在未修改的xv6中,所有的内核栈都在
procinit中被创造你需要去移动
procinit中的部分或者全部到allocproc中 -
修改
scheduler()去将进程的内核页面加载到satp寄存器, 可以通过kvminithart学习这个的用法不要忘记在调用
w_satp之后调用sfence_vma -
调度器应该在没有进程运行时使用
kernal_pagetable -
在
freeproc中释放一个进程的内核页表 -
你将需要一个方法,这个方法在释放页表的同时不会释放真正的物理页面
-
vmprint可以在debug页表的时候办法
思路
可以说,跟着hint一步一步走,就成功了,但是我个人觉得hint或者说这个文档没有说的非常清楚,导致有一点歧义,接下来一个hint一个hint分析
- 在
proc中增加一个字段,这个就不用说了
pagetable_t kernel_pgtbl;
- 这是创建内核页表的关键。我之前以为是要把现在的内核页表给复刻一遍,结果写了个递归函数去copy当前的内核页表。但是实际上,只需要我们创建一个和
kvminit创建出来的的内核页表一样的就行了,也就是最原始的那种,只有内核的代码和数据以及一些外设,这些代码都在kvminit代码中,所以直接抄一份就行了
通过这个代码可以发现,创建一个最原始的内核页表,就三步
- 先申请一个物理页
- 将这个物理页清空
- 写入固定的一系列地址到页表中(大量的
kvmmap操作)
最后在allocproc中进程被正确创建之后,给这个进程的内核页表赋值p->kernel_pgtbl = new_kernel_pgtbl();
void init_kernel_pgtbl(pagetable_t pgtbl) {
memset(pgtbl, 0, PGSIZE);
// uart registers
kvmmap(pgtbl, UART0, UART0, PGSIZE, PTE_R | PTE_W);
// virtio mmio disk interface
kvmmap(pgtbl, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);
// CLINT
kvmmap(pgtbl, CLINT, CLINT, 0x10000, PTE_R | PTE_W);
// PLIC
kvmmap(pgtbl, PLIC, PLIC, 0x400000, PTE_R | PTE_W);
// map kernel text executable and read-only.
kvmmap(pgtbl, KERNBASE, KERNBASE, (uint64)etext - KERNBASE, PTE_R | PTE_X);
// map kernel data and the physical RAM we'll make use of.
kvmmap(pgtbl, (uint64)etext, (uint64)etext, PHYSTOP - (uint64)etext, PTE_R | PTE_W);
// map the trampoline for trap entry/exit to
// the highest virtual address in the kernel.
kvmmap(pgtbl, TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);
}
pagetable_t new_kernel_pgtbl() {
pagetable_t pgtbl = (pagetable_t)kalloc();
init_kernel_pgtbl(pgtbl);
return pgtbl;
}
/*
* create a direct-map page table for the kernel.
*/
void kvminit() {
kernel_pagetable = new_kernel_pgtbl();
}
需要注意的是,我们在这里修改了kvmmap函数的声明,因为之前它是默认使用内核页表的,现在需要用每个进程自己的内核页表,这里主要要修改两个函数,分别是kvmmap和kvmpa,注意要将修改更新到defs.h文件以及所有用到这两个函数的地方,有个比较隐秘的是在virtio_disk.c
- 内核栈相关的修改
正常来说,内核栈是在procinit的时候对proc数组的所有进程进行初始化,然后将地址映射放到唯一的内核页表中
而我们现在只需要在allocproc中申请内存栈并将这个地址变换写到这个进程的内存页表即可
具体步骤如下
-
将
procinit函数中和内存栈相关的代码给剪切 -
将代码复制到
allocproc的合适位置,放在进程内核页表被初始化的后面就不错
char *pa = kalloc();
if (pa == 0)
panic("kalloc");
uint64 va = KSTACK((int)(0));
kvmmap(p->kernel_pgtbl, va, (uint64)pa, PGSIZE, PTE_R | PTE_W);
p->kstack = va;
- hints的第4和第5点一起考虑
第4点就是要求我们在进程获得cpu的时候把它自己的内核栈给切换上去,即修改寄存器satp
第5点则是要求在没有进程使用的时候,切换到内核唯一的那个页表,这个可以通过在进程执行完之后就切换satp寄存器为唯一的内存页表
具体实现如下,在swtch函数执行前后进行切换即可
w_satp(MAKE_SATP(p->kernel_pgtbl));
sfence_vma();
swtch(&c->context, &p->context);
kvminithart();
- 最后一步,在进程被终止的时候,回收这个进程的内核页表
首先补充一个hints没有说的,我们还需要回收这个进程的内核栈的那个页面,否则会造成内存浪费
在freeproc函数中加入如下代码
if (p->kernel_pgtbl) {
free_kernel_stack(p->kernel_pgtbl, p->kstack);
p->kstack = 0;
free_kernel_pgtbl(p->kernel_pgtbl, 0);
p->kernel_pgtbl = 0;
}
其中free_kernel_stack就是通过栈的虚拟地址,经过内核页表,找到物理地址,将其free
void free_kernel_stack(pagetable_t pgtbl, uint64 stack_p) {
void *real_p = (void *)kvmpa(pgtbl, stack_p);
kfree(real_p);
}
其中free_kernel_pgtbl就复杂一些,需要递归地删除这个内核页表,并且不能真正地删除物理页面
void free_kernel_pgtbl(pagetable_t pgtbl, int depth) {
if (depth == 2) {
kfree((void *)pgtbl);
return;
}
for (int i = 0; i < 512; i++) {
pte_t *pte = &pgtbl[i];
if (*pte & PTE_V) {
free_kernel_pgtbl((pagetable_t)(PTE2PA(*pte)), depth + 1);
}
}
kfree((void *)pgtbl);
}
至此,第二个task结束,可以运行
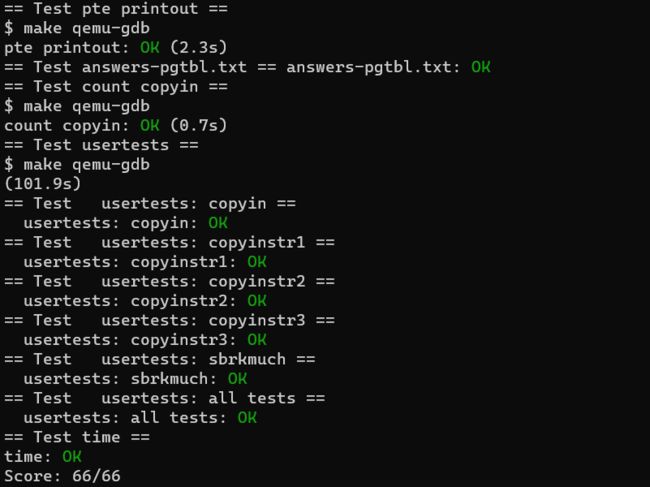
./grade-lab-pgtbl usertests检查这个检查的过程非常长,在我这运行了100s,一度以为是死锁了写错了

Simplify
task
- 将用户的映射都加入到进程的内核页表中
- 将
vm.c中的copyin函数的函数体替换成对copyin_new的调用,对copyinstr也是一样的处理 make grade通过就说明成功了- 你需要修改xv6使得用户进程的虚拟地址不会超过
PLIC寄存器的地址
hints
-
先确定
copyin正确,再去尝试copyinstr -
每次内核改变用户的映射时,都要同步修改到这个用户的内核页表
包括
forkexecsbrk -
不要忘记了在
userinit中将第一个进程的用户也更新到他的内核页表 -
PTE_U不要也拷贝到了kernel的内核页表中 -
不要忘记了
PLIC的限制

错误之路
- 如何控制用户进程申请的最大虚拟地址,在
umalloc.c文件的morecore函数中对sbrk函数的返回值进行判断 - 修改
fork函数,主要是修改uvmcopy函数,在它使用mappages给new增加页表项时,成功后给kernal也增加页表项 - 修改
exec函数,有好多地方需要修改,一个一个来- 调用了
proc_pagetable去创建一个只有顶部两个和trap相关的页面,其他的都为空,这应该相当于清空,内核该怎么办呢?也清空自己吗。目前是清空原有的内核页表,然后生成一个新的内核页表,最后将内核栈的映射加上去 uvmalloc中增加对kernel的操作uvmclear中增加对kernel的操作,这个好像不需要
- 调用了
第二次尝试
-
在
vm.c中创造函数copy_to_kernal和dealloc_kernal,其中的copy函数会将用户标志位给取消copy_to_kernel函数如下有几个细节,或者说是有点坑的地方
- 不要忽略了
mappages函数失败的情况,这个函数失败,说明walk失败,进一步说明是kalloc失败,这本质上就是没有空闲页面了。这时候也不应该用panic报错,而是返回一个特殊值,表示内存不够用了,并且将已经记录的地址映射删除。如果不处理这种情况,会在sbrkmuch这个测试点过不去。 - 为什么要用
PGROUNDUP,可以不用吗?或者可以用PGROUNDDOWN吗- 首先,如果每次给的地址都是页面大小的倍数,那用不用都可以
- 之所以使用向上取整,而不是向下取整,个人认为是因为
oldsz在的那个页面本来就存在于内核页表中,不需要复制,所以就从向上取整的那个开始
uint64 copy_to_kernal(pagetable_t user, pagetable_t kernel, uint64 oldsize, uint64 newsize) { uint64 va, pa; pte_t *pte; uint flags; for (va = PGROUNDUP(oldsize); va < newsize; va += PGSIZE) { pte = walk(user, va, 0); pa = PTE2PA(*pte); flags = PTE_FLAGS(*pte); flags &= ~PTE_U; if (mappages(kernel, va, PGSIZE, pa, flags) != 0) { uvmunmap(kernel, PGROUNDUP(oldsize), (va - PGROUNDUP(oldsize)) / PGSIZE, 0); return -1; } } return newsize; }dealloc_kernal函数如下,基本照抄uvmdealloc函数,只需要将uvmunmap最后的dofree参数改成0就行了这个函数的本质就是将用户进程的虚拟地址给free掉了,没有影响内核本身的那些外设和代码数据
uint64 dealloc_kernal(pagetable_t kernel, uint64 oldsz, uint64 newsz) { if (newsz >= oldsz) return oldsz; if (PGROUNDUP(newsz) < PGROUNDUP(oldsz)) { int npages = (PGROUNDUP(oldsz) - PGROUNDUP(newsz)) / PGSIZE; uvmunmap(kernel, PGROUNDUP(newsz), npages, 0); } return newsz; } - 不要忽略了
-
fork,在父进程拷贝内存到子进程之后,调用copy_to_kernel函数注意,也要判断是否失败
// Copy user memory from parent to child. // 将child的用户态页表复制到child的内核页表 if (uvmcopy(p->pagetable, np->pagetable, p->sz) < 0 || copy_to_kernal(np->pagetable, np->kernel_pgtbl, 0, p->sz) < 0) { freeproc(np); release(&np->lock); return -1; }exec,找个合适的位置(进程的页表被初始化完之后就行),先释放再拷贝dealloc_kernal(p->kernel_pgtbl, oldsz, 0); copy_to_kernal(p->pagetable, p->kernel_pgtbl, 0, sz);sbrk应该是在sys_sbrk中调用的growproc函数,分别在分配和释放的情况下调用函数。其中在分配的时候,如果我们的copy函数失败了,还需要将进程的用户态页表的映射给抹去再返回-1if (n > 0) { if ((sz = uvmalloc(p->pagetable, sz, sz + n)) == 0) { return -1; } // 内核页表 if (copy_to_kernal(p->pagetable, p->kernel_pgtbl, oldsz, oldsz + n) < 0) { uvmdealloc(p->pagetable, sz, oldsz); return -1; } } else if (n < 0) { sz = uvmdealloc(p->pagetable, sz, sz + n); // 内核页表 dealloc_kernal(p->kernel_pgtbl, oldsz, oldsz + n); }userinit,在uvminit之后调用拷贝函数copy_to_kernal(p->pagetable, p->kernel_pgtbl, 0, PGSIZE); -
PLIC的限制-
将
CLINT变成只有最初的内核页表才分配,后面申请的内核页表都不用,这样每个进程的内核页表就不会在PLIC下面还有虚拟地址了。至于这这个CLINT为什么在只需要在最初的内核页表需要,现在还不太清楚,好像后面会讲的,就当个黑盒子使用了具体实现就是将
kvmmap(kernel_pagetable, CLINT, CLINT, 0x10000, PTE_R | PTE_W);从task2中定义的init_kernel_pgtbl中移到kvminit -
控制用户进程的地址空间,不要超过了
PLIC,我觉得这里需要在两个地方进行控制,第一个是exec函数,即进程初始的虚拟地址空间大小,第二个是sbrk函数,即进程在运行的过程中动态申请内存空间,也不能超过PLIC,这个就体现在sbrk调用的growproc函数了-
在
exec中,是在一个for循环里不断通过uvmalloc给这个进程的用户页表建议映射的,因此在这个函数后面加上一个判断即可if ((sz1 = uvmalloc(pagetable, sz, ph.vaddr + ph.memsz)) == 0) goto bad; if (sz1 >= PLIC) { goto bad; } -
在
growproc中,先判断一下当前的大小加上n是否超过了PLICif (PGROUNDUP(sz + n) >= PLIC) { return -1; }
-
至此,硬核的内容结束了
但是如果想拿到满分,还需要在项目根目录下创建两个txt文件,一个叫
time.txt,一个叫answers-pgtbl,一个用来记录完成lab的总耗时,一个用来回答问题,可以直接乱填 -