03-信息收集
信息搜集(全面了解系统)
什么是信息收集?
信息收集是指通过各种方式获取所需要的信息。信息收集是信息得以利用的第一步,也是关键的一步。信息收集工作的好坏,会影响整个渗透测试流程的进行。收集的信息越多后期可进行测试的目标就越多。信息收集包含资产收集但不限于资产收集。
进入信息收集阶段。
在这个阶段,渗透人员需要使用各种公共资源尽可能地获取测试目标的相关信息。他们从互联网上搜集信息的渠道主要有:
| @ | 论坛 |
|---|---|
| @ | 公告板 |
| @ | 新闻组 |
| @ | 媒体文章 |
| @ | 博客 |
| @ | 社交网络 |
| @ | 其他商业或非商业性网站 |
| @ | GitHub等 |
一、收集域名信息
域名的分类
顶级域名:.com .org .cn .net
- 二级域名:baidu.com google.com
- 三级域名:www.baidu.com www.google.com
- 政府域名:.gov
- 商业域名:.com
- 教育域名:.edu
1.whois命令查询
-
默认 Windows 下是没有 whois 这个命令的(废话),因此需要安装 whoiscl 这个小工具。
官方网站:http://nirsoft.net/utils/whoiscl.html
这个工具默认支持顶级通用域名以及国别域名,但目前还有很多奇葩的新域名后缀则不支持,不过没关系,这个可以通过修改配置文件来支持的。 -
whois查询的重要性::
通过whois查询可以获得域名注册者邮箱地址等信息。一般情况下对于中小型网站,域名注册者就是网站管理员。利用搜索引擎对whois查询到的信息进行搜索,获取更多域名注册者的个人信息。
功能:
用来查找并显示指定用户账号、域名相关信息,包括域名注册时间、拥有者邮箱等,类似命令:tracepath、host、nslookup、who、pwd.
-
语法
whois [参数] [域名/账户] 查询 实例: 1. 查询域名注册信息。 whois [domain] whois testfire.net //以[testfire.net]为目标,testfire.net 是IBM 公司为了演示旗下比较有名的Web 漏洞扫描器AppScan 的强大功能所搭建的模拟银行网站,所以上面会有很多常见的Web 安全漏洞 类似的测试网站 [http://vulnweb.com/]
2. 网址查询
也可以通过站长之家进行whois 查询[http://whois.chinaz.com]
查询方法:可通过以下网站进行在线查询:
https://whois.chinaz.com/ 站长之家查询接口
https://whois.aliyun.com/ 阿里云查询接口
https://www.whois.com/cn/ 全球whois查询
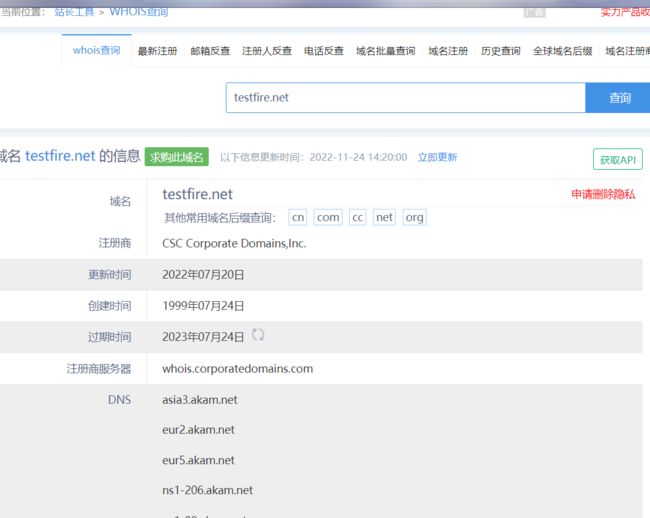
查询结果解析:
Domain Name: BAIDU.COM(域名)
Registry Domain ID: 11181110_DOMAIN_COM-VRSN(注册域名ID)
Registrar WHOIS Server: whois.markmonitor.com(注册whois服务器)
Registrar URL: http://www.markmonitor.com(注册者URL)
Updated Date: 2022-01-25T09:00:46Z(更新时间)
Creation Date: 1999-10-11T11:05:17Z(创建时间)
Registry Expiry Date: 2026-10-11T11:05:17Z(过期时间)
Registrar: MarkMonitor Inc.(注册者)
Registrar IANA ID: 292(注册者IANA ID)
Registrar Abuse Contact Email: [email protected](注册滥用电子邮箱联系人)
Registrar Abuse Contact Phone: +1.2083895740(注册者滥用电话号码)
Domain Status: clientDeleteProhibited https://icann.org/epp#clientDeleteProhibited(域名状态)
Domain Status: clientTransferProhibited https://icann.org/epp#clientTransferProhibited
Domain Status: clientUpdateProhibited https://icann.org/epp#clientUpdateProhibited
Domain Status: serverDeleteProhibited https://icann.org/epp#serverDeleteProhibited
Domain Status: serverTransferProhibited https://icann.org/epp#serverTransferProhibited
Domain Status: serverUpdateProhibited https://icann.org/epp#serverUpdateProhibited
Name Server: NS1.BAIDU.COM(域名服务器)
Name Server: NS2.BAIDU.COM
Name Server: NS3.BAIDU.COM
Name Server: NS4.BAIDU.COM
Name Server: NS7.BAIDU.COM
DNSSEC: unsigned
URL of the ICANN Whois Inaccuracy Complaint Form: https://www.icann.org/wicf/
>>> Last update of whois database: 2022-04-13T09:32:10Z <<<(最后更新whois库时间)
(最后一段是web的whois信息)
备案信息查询
网站备案是国家根据法律规定,需要网站的所有者向国家有关部门进行申请的,主要针对国内网站,网站在国外则不需要备案。
常用的备案查询网站:
ICP备案查询网,天眼查。
3.DMitry命令工具
Dmitry工具同样是用来查询ip或域名whois信息的
语法如下:
dmitry -w 查询的域名(-w表示对指定的域名实施whois查询)
4.收集敏感信息
通过BurpSuite
通过BurpSuite工具同样可以获取一些服务器的信息,如运行的Server类型及版本、PHP的版本信息等。针对不同的Server ,可以利用不同的漏洞进行测试。

通过google收集敏感信息
Google是世界上最强大的搜索引擎之一,对每一个渗透着而言,他是最佳的黑客工具。
| 关键字 | 说明 |
|---|---|
| Site | 指定域名 |
| Inurl | URL中存在关键字的网页 |
| Intext | 网页正文中的关键字 |
| Filetype | 指定文件类型 |
| Intitle | 网页标题中的关键字 |
| link | link:baidu.com 即表示返回所有和baidu.com做了连接的URL |
| Info | 查找指定站点的一些基本信息 |
| cache | 搜素Google里某些内容的缓存 |
举个例子,我们尝试搜素一些学校网站的后台,语法为“site:edu intext:后台管理”,意思就是去搜素网页正文中含有“后台管理
“,并且域名后缀是edu.cn的网站
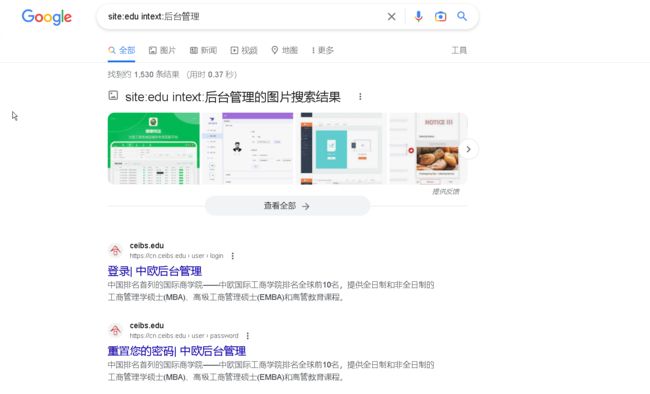
5.子域名查询
简介:
子域名也就是二级域名,是指顶级域名下的域名。假设我们的目标网络规模比较大,直接从主域入手显然是很不理智的,因为对于这种规模的目标,一般其主域都是重点防护区域,所以不如先进入目标的某个子域,然后再想办法迂回接近真正的目标,这无疑是个比较好的选择。那么问题来了,怎样才能尽可能多地搜集目标的高价值子域呢?常用的方法有以下这几种。
1.子域名检测工具
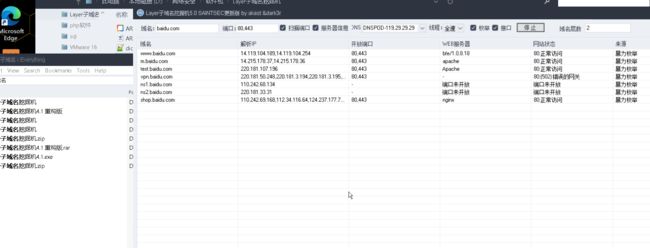
用子域名检测的工具主要有Layer子域名挖掘机、K8、wydomain、Sublist3r、dnsmaper、subDomainsBrute、Maltego CE等。笔者重点推荐Layer子域名挖掘机、Sublist3r和subDomainsBrute。
-
Layer子域名挖掘机的使用方法比较简单,在域名对话框中直接输入域名就可以进行扫描,它的显示界面比较细致,有域名、解析IP、CDN列表、Web服务器和网站状态,如图1-4所示,这些对安全测试人员来说非常重要。
-
下载地址
百度网盘
链接: https://pan.baidu.com/s/1n8_eh0_tD8Nrtc_GpAu3zg?pwd=y2ef
提取码: y2ef
2.域传送漏洞
简介:
DNS区域传送指的是一台备用服务器使用来自主服务器的数据刷新自己的域数据库。这为运行中的DNS 服务提供了一定的冗余度,其目的是为了防止主域名服务器因为意外故障变得不可用时影响到整个域名的解析。一般来说,
DNS 区域传输漏洞用于攻击的信息收集阶段, 目的是尽可能多地收集有关目标受害者的信息,以识别潜在的漏洞。
DNS 区域信息可能包括有关给定系统或网络的内部基础设施的敏感信息。
检测域传输漏洞方法:
可以使用dig 工具来检测域传送漏洞,命令如下
dig (选项) (参数)
//
选项:
@<服务器地址>:指定进行域名解析的域名服务器;
x——:执行逆向域名查询;;
f——指定dig以批处理的方式运行,指定的文件中保存着需要批处理查询的DNS任务信息;
参数:
1 主机:指定要查询域名主机;
2 查询类型:指定DNS查询的类型;
3 查询类:指定查询DNS的class;
4 查询选项:指定查询选项。
例如:
1.如果想要使用一些公共域名服务器(比如Google public DNS 8.8.8.8)就可以这样使用:
dig @8.8.8.8 www.baidu.com
子域名挖掘机漏洞工具使用
1)启动Layer
该软件为绿色软件无需安装双击即可运行。


2)开始扫描
在域名右侧的文本框输入想要搜索的域名,比如http://ke.qq.com

其他配置默认,点击启动即可。
3)扫描结果
接下来是一个漫长的等待过程。从已收集到的子域名,可以查看80和443端口的开放状态、WEB服务器和网站状态。

右键单击某个域名可以打开网站、复制域名、复制IP
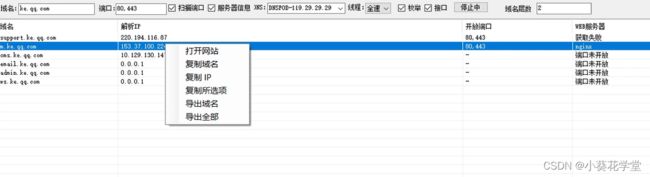
点击 导出域名 可以导出所有暴出的域名。

3.自动枚举工具dnsrecon
dnsrecon工具支持多种DNS记录查询、域传送漏洞检测、对IP范围查询、检测DNS服务器缓存、结果可保存为多种格式的工具。
语法:
dnsrecon 【参数】 【选项】
案例:
1.对域名进行子域名查找
dnsrecon -d vulnweb.com -D /root/tmp/dic/dns.dic -t brt
-d 指定域名 -D 指定字典
-t, type 指定枚举类型:
brt类型: 使用指定的字典爆破域名与主机名
goo : 对子域名和host进行Google搜索
.....等
详细可以查看网址:
https://blog.51cto.com/executer/1976057
对域名进行子域名查找
准备一个字典写上所有的域名(4个字母左右别超过10个)。字典中的每个单词,依次去尝试
工具不重要,重要的是字典
实战二:对给定的IP范围进行域名反查
dnsrecon -r 110.129.8.1-110.129.8.30 -t rvl--lifetime 30 -v
4.搜索引擎枚举
可以查询子域名的网站[https://searchdns.netcraft.com/],这种方法查询大型网站比较有优势。
也可以利用DNSdumpster网站(https://dnsdumpster.com/)、在线DNS侦查和搜索的工具挖掘出指定域潜藏的大量子域。

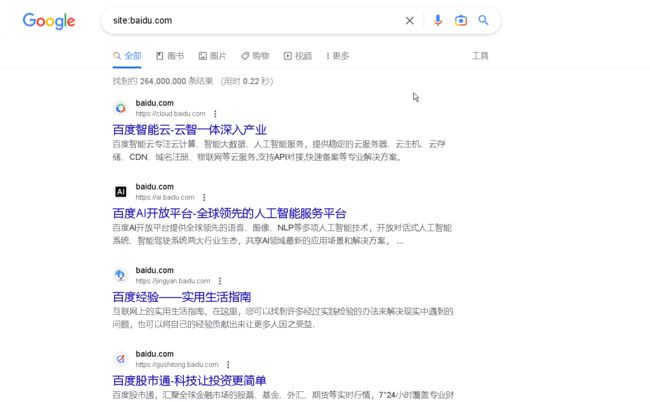
也可以使用google语法
如:”site:baidu.com“
二、IP及端口信息收集
简介:
在渗透测试过程中,目标服务器可能只有一个域名,那么如何通过这个域名来确定目标服务器的真实IP对渗透测试来说就很重要。如果目标服务器不存在CDN,可以直接通过www.ip138.com获取目标的一些IP及域名信息。这里主要讲解在以下这几种情况下,如何绕过CDN寻找目标服务器的真实IP。
1. DNS2IP
通过DNS 解析找到IP地址
ping 域名
//都是非权威解答
返回结果有多个,说明启用了CND技术
或者命令
nslookup 域名
CDN技术概述
- 定义:CDN的全称是Content DeliveryNetwork,即内容分发网络。
- 简介:CDN是构建在现有网络基础之上的智能虚拟网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。
- 基本原理:CDN的基本思路是尽可能避开互联网上有可能影响数据传输速度和稳定性的瓶颈和环节,使内容传输的更快、更稳定。通过在网络各处放置节点服务器所构成的在现有的互联网基础之上的一层智能虚拟网络,CDN系统能够实时地根据网络流量和各节点的连接、负载状况以及到用户的距离和响应时间等综合信息将用户的请求重新导向离用户最近的服务节点上。
- 目的:是使用户可就近取得所需内容,解决 Internet网络拥挤的状况,提高用户访问网站的响应速度。
2.dnsenum工具
DNSenum是一款dns查询工具。它能够通过Google或字典文件猜测可能存在的域名,并对一个网段进行反向查询。
dnsenum testfire.net
此处推荐dnsenum,此工具在解析域名的时候
会自动检测域传送漏洞
示例
1.对sina.com(新浪) 实现dns查询
命令: dnsenum --enum sina.com
//-常用选项:
-–enum 相当于–threads 5 -s 15 -w.
-v 详细显示所有进度和所有错误消息,加上-v会很慢,会动态的进行记录扫描,产生消息过多
-w 执行whois查询
-o [file] 以XML格式输出到指定文件中,方便之后查询
-t/ --timeout 超时设置,可以提高速度但可能会影响查询结果
2. 使用字典文件进行dns查询
dnsenum --noreverse -f /usr/share/dnsenum/dns.txt sina.com
在kali Linux中/usr/share/dnsenum/中
基本的域名IP信息。
IN:INTERNET,表示资源都在Internet上
A记录代表"主机名称"与"IP"地址的对应关系, 作用是把名称转换成IP地址,意思是说该主机的IP对应之意!DNS使用A记录来回答"某主机名称所对应的IP地址是什么?"主机名必须使用A记录转译成IP地址,网络层才知道如何选择路由,并将数据包送到目的地.你要知道的是A就代表了将域名转换成ip,现在好多的工具都有这个功能。

端口扫描工具:
在渗透测试中,对端口的信息收集是一个很重要的过程,通过扫描服务器开放的端口以及从该端口判断服务器上存在的服务,就可以对症下药。
最常见的扫描端口工具就是nmap
其他:无状态扫描端口 Masscan、ZMap和御剑高速TCP端口扫描工具。
御剑高速TCP端口扫描工具
三、绕过CDN寻找目标服务器的真实IP。
1、简介:
CDN的全称是Content Delivery Network,即内容分发网络。CDN是构建在现有网络基础之上的智能虚拟网络,依靠部署在各地的边缘服务器,通过中心平台的负载均衡、内容分发、调度等功能模块,使用户就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。但在安全测试过程中,若目标存在CDN服务,将会影响到后续的安全测试过程
2、不同访问服务器过程:
1.传统访问:用户访问域名–>解析服务器IP–>访问目标主机
2.普通CDN:用户访问域名–>CDN节点–>真实服务器IP–>访问目标主机
3.带WAF的CDN:用户访问域名–>CDN节点(WAF)–>真实服务器IP–>访问目标主机
因此:
如果渗透目标购买了CDN服务,可以直接ping目标的域名,但得到的并非真正的目标Web服务器,只是离我们最近的一台目标节点的CDN服务器,这就导致了我们没法直接得到目标的真实IP段范围。
3、如何判断目标是否存在CDN
-
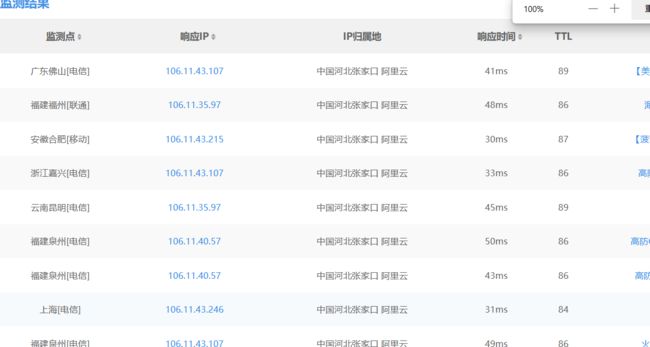
方法一:使用网站:超级ping
连接
https://ping.chinaz.com/
https://www.boce.com/ping/
可以看到不同地区访问出来的IP时不相同的,
可以判断出开启CDN。
- 方法二、使用命令nslookup
若结果存在多个IP则存在CDN,反之不存在
4.目前常见CDN绕过技术
1.子域名
在线查询网站
域名Whois查询 - 站长之家 (chinaz.com)
-
CDN很贵,多数网站只会给主站用CDN,而子域名很少用。
-
子域名可能会跟主站在同一个服务器上,可以先搜集子域名,根据子域名的IP地址,推断主站的IP地址
演示案例:
- 利用子域名请求真实的IP
采用网址:https://www.xueersi.com/
-
使用https://www.xueersi.com超级ping后ip不一致
-
通常网站管理员将两个地址解析至同一个IP,但搭建CDN服务器的时候,可能存在网站管理员只将其中一个设置解析至DNS服务器,也就是说两种访问方式访问的IP可能并不相同。

-
使用xueersi.com超级ping后
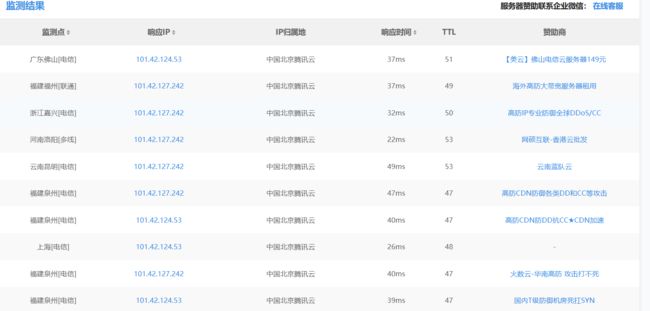
2.利用邮件服务系统
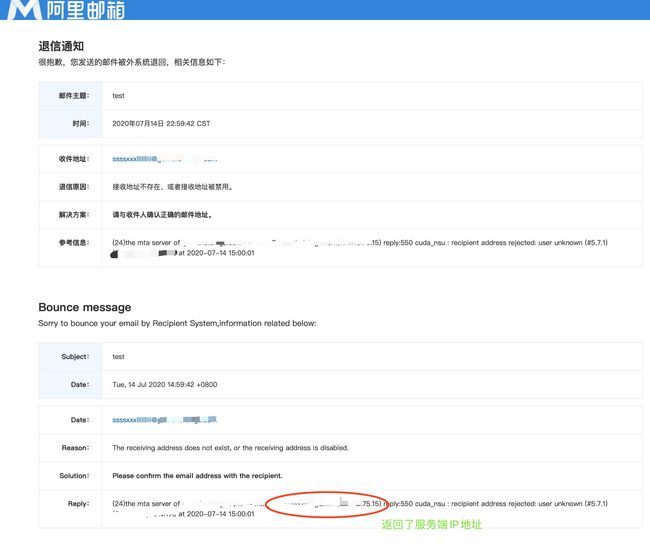
利用网站中有用到邮件的位置,例如注册发邮件、找回密码发邮件等等,查看邮件原文寻找真实IP。
找出邮件源码,分析ip地址,参考对比备案号的公司地址,ping这个邮件的服务器的域名,获取真实ip。
如目前域名存在邮箱系统,可尝试向任意一个不存在的邮箱账号发邮件,触发其报错,通常在报错信息里会有提示
3.使用国外地址获取真实ip
(有些偏远地区可能不存在cdn节点)
站长之家的多地Ping:https://tool.chinaz.com/,输入框中输入 xxx.com,点击 Ping检测

地址栏输入:https://check-host.net/check-ping?,输入框中输入 xxx.com,点击下方的 Ping 按钮。

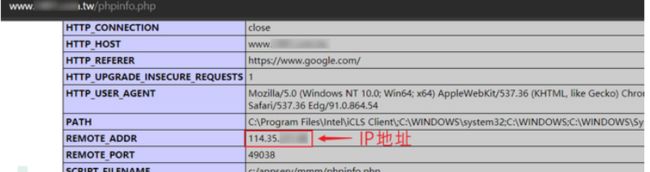
4.遗留文件,扫描文件
扫描网站测试文件,如phpinfo、test等,从而找到目标的真实IP。
一些站点在搭建之初,会用一些文件测试站点,例如“phpinfo()”文件,此类文件里就有可能包含了真实的IP地址。可以利用Google搜索引擎搜索关键字“site:xxx.com inurl:phpinfo.php”,搜索站点是否有遗留文件。
5.黑暗引擎搜索特定文件
-
这里的特定文件,指的是站点的icon文件,也就是网站的图标,一般查看网页源代码可以找到,
格式大致“http://www.xx.com/favicon.ico”。
-
在shodan搜索网站icon图标的语法为:http.favicon.hash:hash值,hash是一个未知的随机数,我们可以通过shodan语法来查看一个已经被shodan收录的网站的hash值,来进一步获取到所有带有某icon的网站。
-
如何获取icon的hash值呢?
第一种、python工具 #Python2 开发别搞错了执行环境 #安装 mmh3 失败记得先安装下这个Microsoft Visual C++ 14.0 import mmh3 import requests response = requests.get('http://www.xx.com/favicon.ico') favicon = response.content.encode('base64') hash = mmh3.hash(favicon) print 'http.favicon.hash:'+str(hash)第二种
利用FOFA间接获取
FOFA高级会员可以直接搜索icon,但是一般用户可以直接搜索icon,它会返回icon的hash值
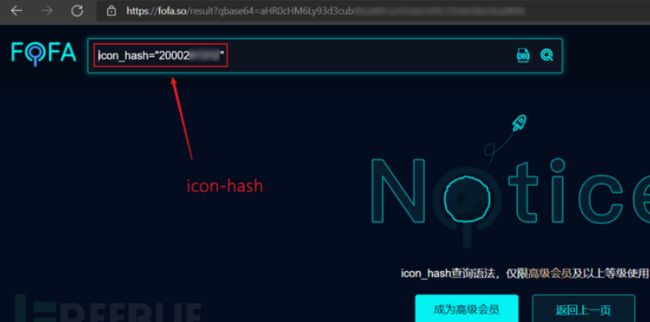
然后再利用shodan的语法:http.favicon.hash:hash值,就可以进行搜索啦

6.DNS 历史记录
站点在使用CDN服务之前,也就是也许目标很久之前并未使用过CDN,它的真实IP地址可能被DNS服务器所记录到,此时我们就可以通过DNS历史记录找到目标真实IP。
相关查询网站有:
https://dnsdb.io/zh-cn/ ###DNS查询
https://x.threatbook.cn/ ###微步在线
http://toolbar.netcraft.com/site_report?url= ###在线域名信息查询
http://viewdns.info/ ###DNS、IP等查询
https://tools.ipip.net/cdn.php ###CDN查询IP
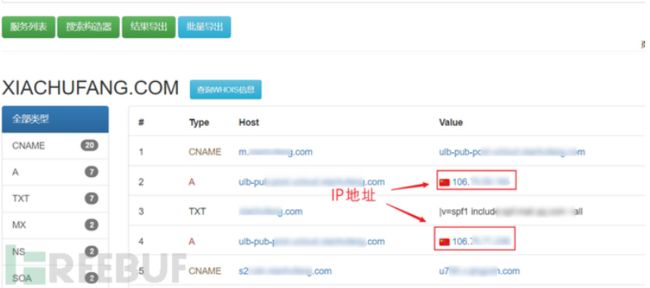
通过网站来观察域名的IP历史记录,也可以大致分析出目标的真实IP段。
注意:使用DDOS攻击可以耗尽CDN流量,违法
案例:
采用网址:https://get-site-ip.com
微步在线X情报社区-威胁情报查询_威胁分析平台_开放社区 (threatbook.com)
历史dns记录

7.app
如果目标网站有自己的app,可以尝试利用burpsuite或fiddler抓取app的请求,从里面找到目标的真实ip。

三、信息收集-架构,搭建,WAF
一、 站点搭建分析
1. 搭建习惯-目录型站点
简单的理解就是主站上面存在其他的cms程序
例如:
学生网站的上面通过后台扫描探针发现有一个bbs的目录一点击发现是一个bbs的论坛网站如:www.xxx.com/bbs
我们把这个成为目录型网站、可以有两种找到漏洞的思路一个是主站的漏洞另外的一个是bbs上面的漏洞
演示案例:
sti.blcu-bbs-目录型站点分析
sti.blcu.edu.cn和sti.blcu.edu.cn/bbs/原则上是一个网站,但是区别在于目录下的差异
这两个网站使用的是两套程序,一个网站出现问题,另一个网站也会遭殃,就相当于有了两套漏洞两个方案
可以通过目录扫描来获取相关信息
2. 搭建习惯-端口类站点
通过不同的端口将两个网站分开,一个网站出了问题,另一个网站也会出现问题
演示案例:
web.0516jz-8080-端口类站点分析:
web.0516jz.com:80 和 web.0516jz.com:8080分开两套程序搭建,一个端口对应一个不同网站
原网站界面:
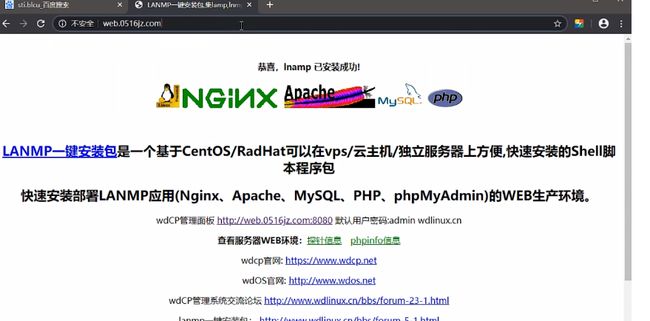
加了端口8080后发现进入了管理员登录界面

3. 搭建习惯-子域名站点
通过子域名将两个网站分开,可能在一起,也可能不在一起,就是两个网站可能不在同一个服务器上
演示案例:
goodlift-www.bbs-子域名两套 CMS
www.goodlift.net 和 bbs.goodlift.net 是两套网站
可能是同ip也可能是同网段
备注:现在的主流网站都是采用的这种模式且子域名和网站之间很有可能是不在同一台的服务器上面。
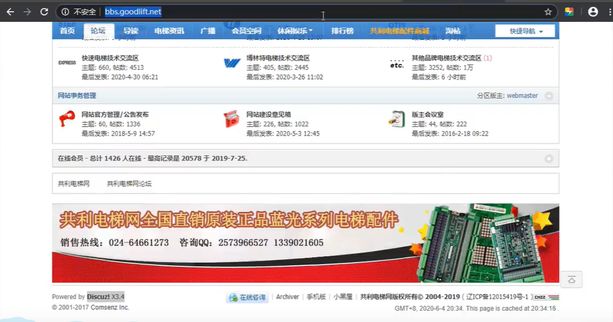
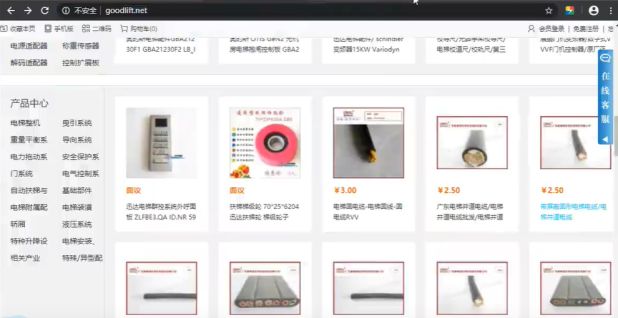
4. 搭建习惯-类似域名站点
有些公司由于业务的发展将原来的域名弃用、选择了其他的域名但是我们访问他的旧的域名还是能够访问、有的是二级域名的更换而有的是顶级域名的更换
可以通过他的旧的域名找到一些突破口。
也可以通过中间的域名去找类似域名(在其中添加123等)
.com,商业通用域名
.gov,政府网站域名
.edu,教育网站域名
.org,非盈利组织域名
.net,网络服务商域名
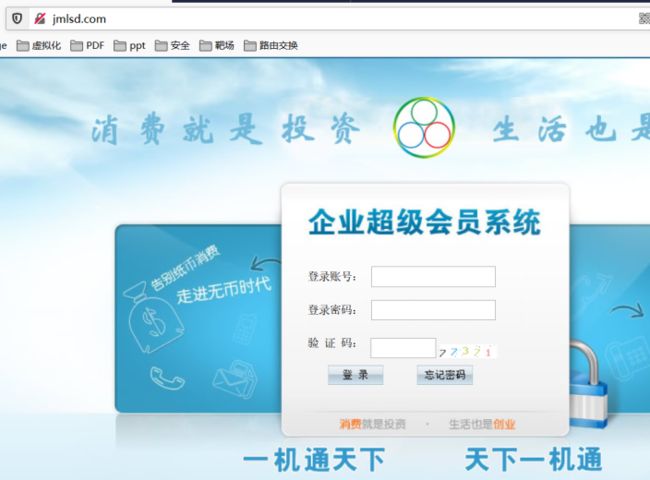
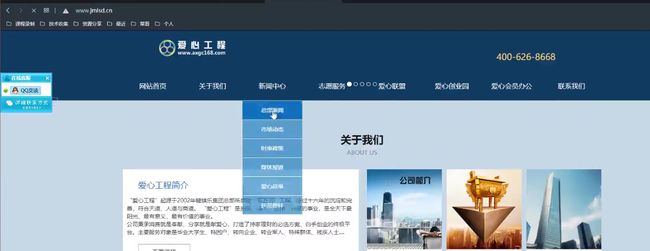
案例:jmlsd-cn.com.net 等-各种常用域名后缀
jmlsd.com 与 jmlsd.cn
网站后缀的域名访问的站点不同,渗透选择的机会就多
5. 搭建习惯-旁注, c段站点
-
旁注:两个域名同服务器不同站点
-
同一个服务器上面存在多个站点、但是你要攻击的是A网站由于各种原因不能完成安全测试。就通过测试B网站进入服务器然后在攻击A网站最终实现目的 比如: 服务器:192.168.1.100 下面两个站点 www.ba.com www.cd.com .....
-
-
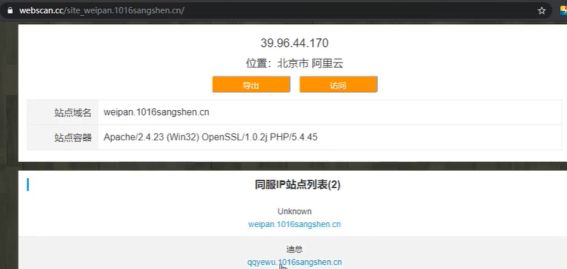
C段站点:两个域名同一个网段不同服务器不同站点
-
不同服务器上面存在不同的网站,通过扫描发现与你渗透测试的是同一个网段最终拿下服务器、然后通过内网渗透的方式拿下渗透服务器。 服务器:192.168.1.100 www.a.com 服务器:192.168.1.101 www.b,com a.com和b.com属于同一个网段
-
案例:weipan-qqyewu-查询靶场同服务器站点
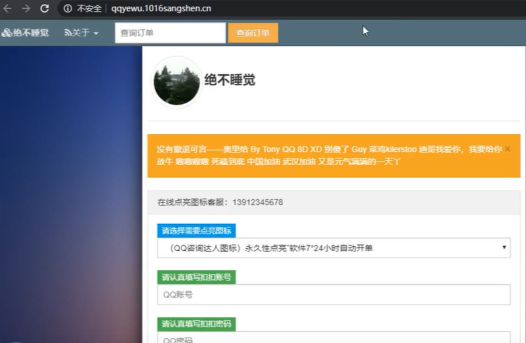
在线网站工具:https://www.webscan.cc/
通过旁注查询可以发现同一个服务器上面有两个站点可以通过对另外的一个站点进行突破。
6. 搭建习惯-搭建软件特征站点
有的网站是借助于第三方的集成搭建工具实现例如:PHPstudy、宝塔等环境这样的集成环境搭建的危害就是泄露了详细的版本信息。
phpstudy搭建了之后在默认的站点安装了phpmyadmin有的网站没有做安全性直接可以通过用户名:root密码:root 登录进入
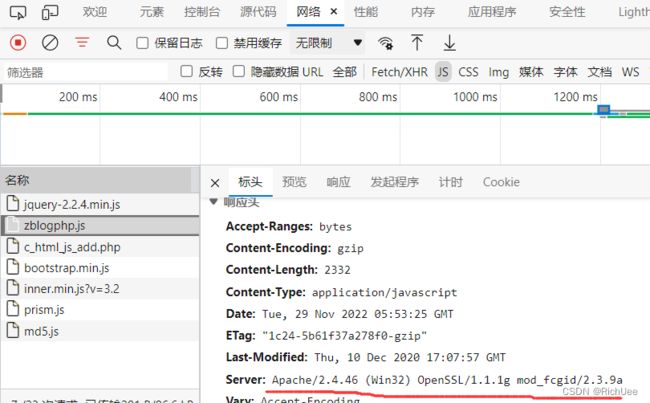
案例:weipan-phpstudy-查询特定软件中间件等
- 通过浏览器抓包判断中间件,用搭建平台,显示的服务器信息比较多。
- 用中间件搭建:内容少[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uscwEphU-1683345060554)(03-%E4%BF%A1%E6%81%AF%E6%94%B6%E9%9B%86.assets/a048fd3eac53408a98bb7a0bfeb2d52a.png)]
二、WAF防火墙防护分析
1、什么是wAF应用?
Web应用防护系统(也称为:网站应用级入侵防御系统。英文:Web Application Firewall,简称: WAF)。利用国际上公认的一种说法:Web应用防火墙是通过执行一系列针对HTTP/HTTPS的安全策略来专门为Web应用提供保护的一款产品。
分为软件和硬件,在安全公司单位购买的防火墙都是硬件,个人网站和小企业搭建都是软件。
2、如何快速识别WAF?
注意:对方有waf的时候不要用扫描工具直接扫,容易被拉黑
1)windows下wafw00f安装使用
- 采用工具wafwoof,kali自带
wins获取下载地址:https://codeload.github.com/EnableSecurity/wafw00f/zip/refs/heads/master
安装之前一定要有python的环境不然安装不上
wafw00f的缺点判断的不是特别的准确存在误报或识别不出的情况。
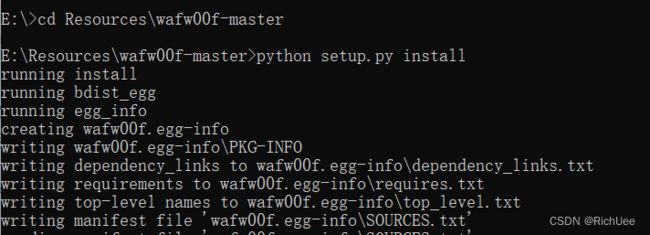
安装命令:
- python setup.py intall
- 安装完成执行main.py
python main.py

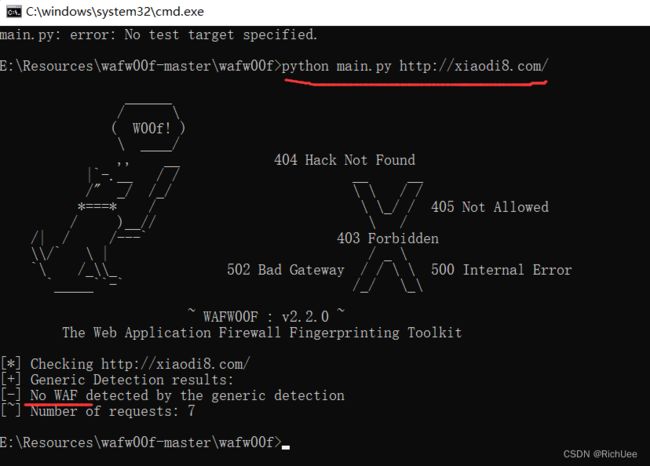
- 测试无waf的网站:
pyhon mian.py 网站
- 测试有waf的网站:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AenEO2IL-1683345060555)(03-%E4%BF%A1%E6%81%AF%E6%94%B6%E9%9B%86.assets/81f8929e41b04840a578c31f8a020483.png)]
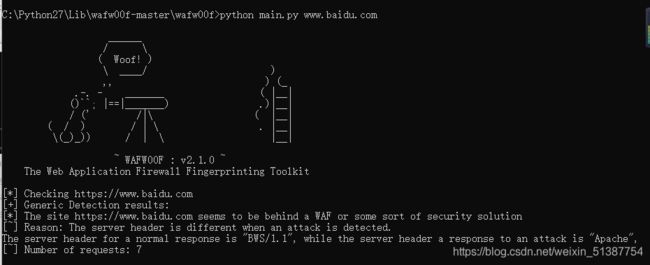
- 探测网站是否存在WAF
执行python main.py www.baidu.com
2)kali自带wafw00f使用
-
查看wafw00f支持检测的WAF类型
wafw00f -l -
测试单个 URL
wafw00f ip(或网址)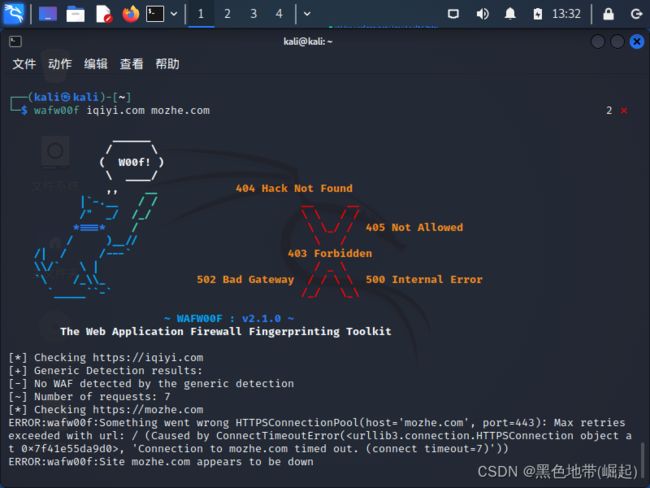
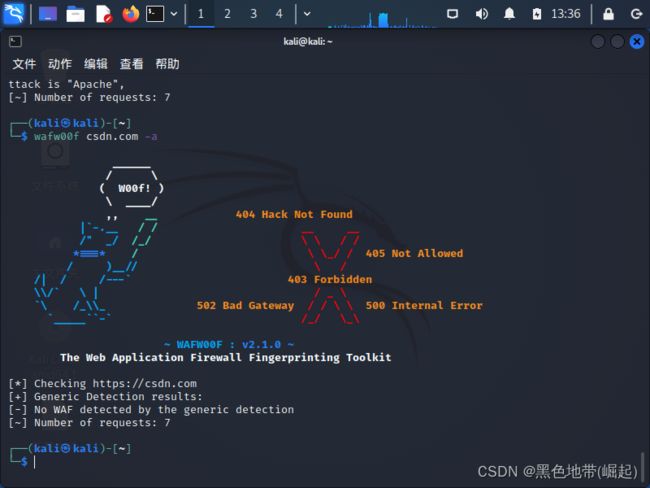
-
wafw00f ip -a 匹配所有签名特征的WAFS
-p 设置代理
-r 不遵循3xx状态的重定向
-t 测试一个指定的WAF
-o 输出文件,文件类型取决于文件名后缀,支持csv、json、文本
-i 从文件中读取目标。输入格式可以是csv,json或文本。
-l 显示支持探测的所有WAF列表
-H 设定一个头文件信息,用以覆盖默认的头信息
3)手工识别waf
1.http请求包分析响应数据
在有些网站的请求信息当中有的网站没有做安全信息上面留下了waf的相关信息。
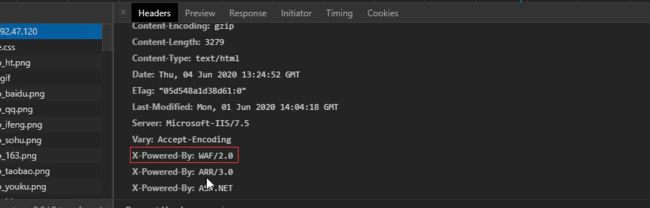
奇安信安域WAF标识,对网站进行正常访问,查看响应的头部信息,在X-Powered-By内显示“anyu.qianxin.com”的标识,代表安装了奇安信安域WAF
HTTP/1.1 200 OK
Server: CWAP-waf
Date: Mon, 10 May 2021 03:56:22 GMT
Content-Type: text/html; charset=UTF-8
Connection: close
X-Powered-By: anyu.qianxin.com
X-Powered-By: PHP/7.3.10
WZWS-RAY: 1129-1620647782.725-s3zzuc
Content-Length: 94142
云盾:响应头包含yundun关键字;页面源代码有errors.aliyun.com
安全狗:响应头包含waf2.0、Safedog等字样
腾讯云:阻止响应页面,包含waf.tencent-clound.com
阻止响应代码405 method not allow
安全宝:恶意请求时返回405恶意代码 响应头包含X-Powered-by:Anquanbao
百度云加速:响应头包含Yunjiasu-ngnix
创宇盾:恶意请求时页面URL:365cyd.com、365cyd.net
2.通过访问不存在的页分析页面
3.请求恶意字符分析响应或敏感页面
and 1=1
cat…/…/…/…/passwd
访问phpinfo.php
4)使用nmap指纹检测
是否存在防火墙检测
root@kali:~# nmap --script=firewalk --traceroute www.csdn.net
root@kali:~# nmap --traceroute --script firewalk --script-args firewalk.recv-timeout=60000,firewalk.max-active-probes=3,firewalk.max-retries=3,firewalk.probe-timeout=600 www.csdn.net
root@kali:~# nmap -p80 --script http-waf-detect www.csdn.net
root@kali:~# nmap -p80 --script http-waf-detect --script-args="http-waf-detect.detectBodyChanges" www.csdn.net
5)identYwaf软件
地址:https://github.com/stamparm/identywaf
与wafwoof相比运行速度慢,比较稳定推荐还是使用这一款工具。
3、识别wAF对于安全测试的意义?
对于一个网站要是使用了waf而渗透人员没有识别直接使用工具进行扫描有可能会导致waf将你的ip地址拉入黑名单而不能访问。而识别waf在于有针对性行的绕过各个厂商的waf可能存在着不同的绕过思路。
四、APP信息收集
简介:
在安全测试中,若 WEB 无法取得进展或无 WEB 的情况下,我们需要
借助 APP 或其他资产在进行信息收集,从而开展后续渗透,那么其中的
信息收集就尤为重要,这里我们用案例讲解试试如何!
1 .APE提取一键反编译提取
- 使用反编译工具,尝试获取包了里的源码
漏了个大洞工具:
安装连接:
https://blog.csdn.net/qq_53079406/article/details/124508679
下载:
漏了个大洞(APP到网站的逆向工具)
链接:https://pan.baidu.com/s/1-fdA0YQ8VhD_Lf_9XARS5w
提取码:hj12
Dex2jar工具:
(1)Dex2jar安装:
dex2jar 是 Android 中的一个反编译工具,它可以将 Android 程序安装包 Apk 文件中的 .dex 文件反编译成一个 .jar 文件,也可以将反编译后的 .jar 文件重新编译成 .dex 文件。反编译以后的 .jar 文件可以直接通过 JD-GUI 查看源代码(源码是混淆的)。
dex2jar 下载地址: https://sourceforge.net/projects/dex2jar/
-
将下载的 dex2jar-2.0.zip 压缩文件直接解压到任意文件夹下。
-
将 dex2jar-2.0 文件夹的路径配置到 PATH 环境变量中去。
-
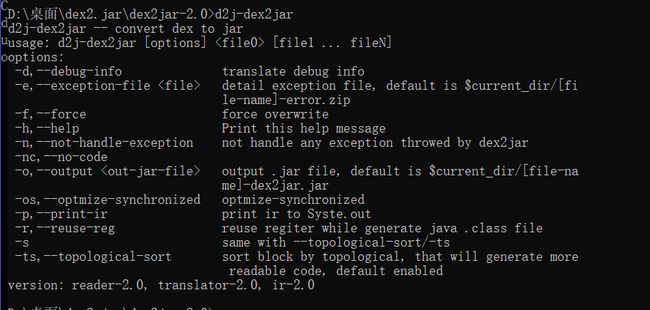
在命令行窗口输入 d2j-dex2jar 命令按回车键后,打印如下图信息,表示安装成功
(2)dex2jar 反编译的使用
简介:
将 Android Apk 文件后缀名 .apk 改成 .zip 文件并解压,获取到它的 .dex 文件(解压后有可能有多个 dex 文件),dex2jar 主要对该 .dex 文件反编译。
(3)dex2jar 反编译命令
d2j-dex2jar -o
参数:
dexFilePath: 要反编译的 .dex 文件的文件路径。
outputJarFilePath: 反编译后输出的 .jar 文件的文件路径。
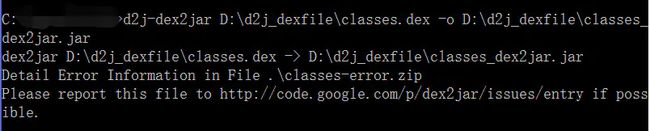
示例: d2j-dex2jar D:\d2j_dexfile\classes.dex -o D:\d2j_dexfile\classes_dex2jar.jar
(4)dex2jar 重编译命令
d2j-jar2dex -o
参数:
- jarFilePath: 要重新编译的 .jar 文件的文件路径。
- outputDexFilePath: 重编译后输出的 .dex 文件的文件路径。
**示例: **
d2j-jar2dex D:\d2j_dexfile\classes_dex2jar.jar -o D:\d2j_dexfile\classes_dex.dex

2.bp抓取手机数据包
手机IP地址:192.168.1.3
kali:192.168.1.9
- 配置:

- 抓包测试:
- 配置证书:
在浏览器中输入192.168.1.9:8888下载证书并重名为ca.cer 然后导入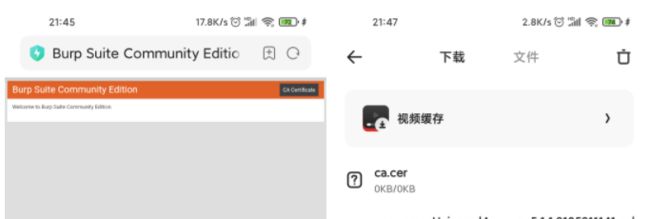
导入证书:设置-密码与安全-系统安全-加密与凭证-从sd卡安装-然后搜索ca.cer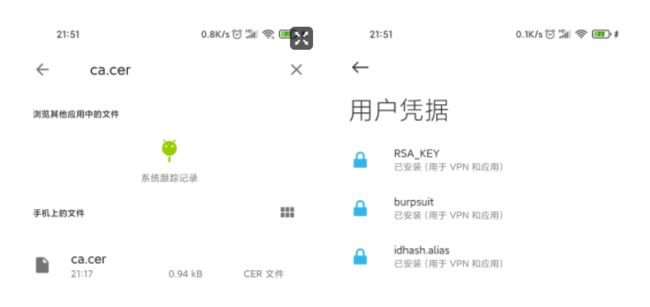
抓包测试:
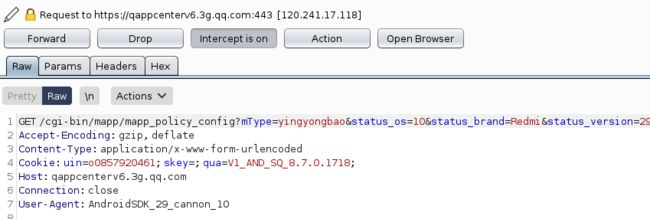
-
对抓取的数据包进行分析
各种第三方应用相关探针技术
各种端口一顿乱扫
接口部分一顿测试实例:
黑暗引擎扫描该ip,依次进入可疑端口,查找有效信息
http://45.33.42.112/
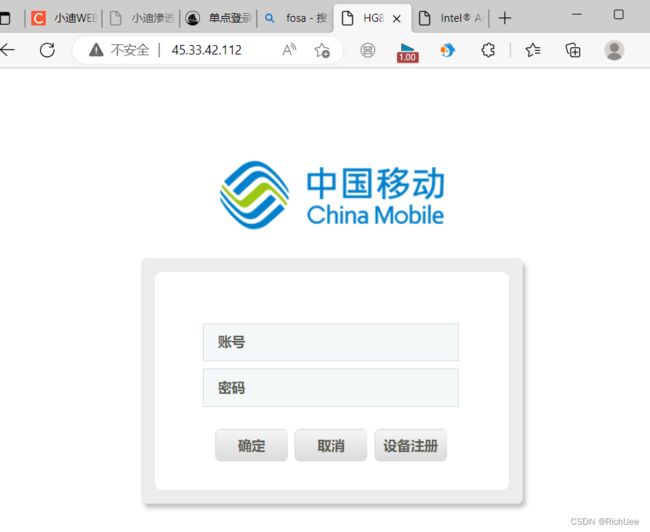
进入628端口,发现要登陆,输入用户名:admin,密码root,居然登陆进去了!!!!!!!

点击Log On
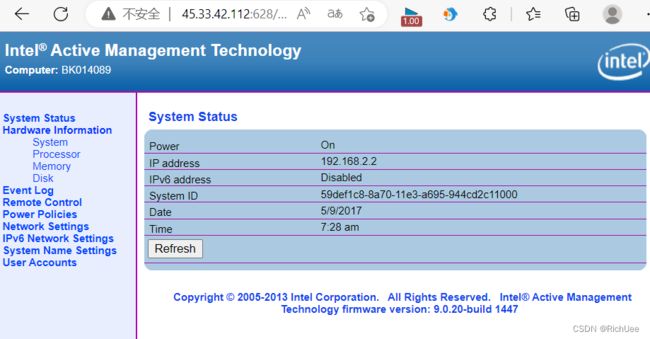
也有可能是蜜罐。
五、资产监控收集
1.常见的域名收集思维导图

(1).在线网站
-
通过http证书日志收集
-
用cloudflare
-
通过解析记录
DNS,备案,证书
(2) . 搜索引擎实现域名端口等收集
- 谷歌,百度…等
- fofa:https://fofa.so/
- zoomeye:https://www.zoomeye.org/
(3).枚举
-
枚举爆破
使用字典不断更换域名
比如 baidu.com
可以试试 baidu.cn
baidu.net …
(4). 使用主站爬取
-
爬虫工具
-
在一些网站的下面会有一些导航,这个导航可能会把一些网站的子域名导航出来

-
使用工具提莫:下载连接
运行环境:python 2.7.*
https://github.com/bit4woo/teemo
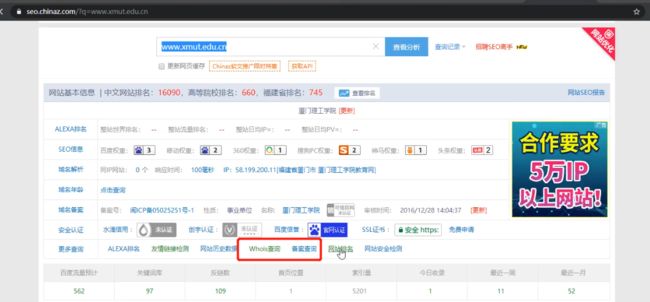
(5). whois查询和备案查询
-
通过网站查询
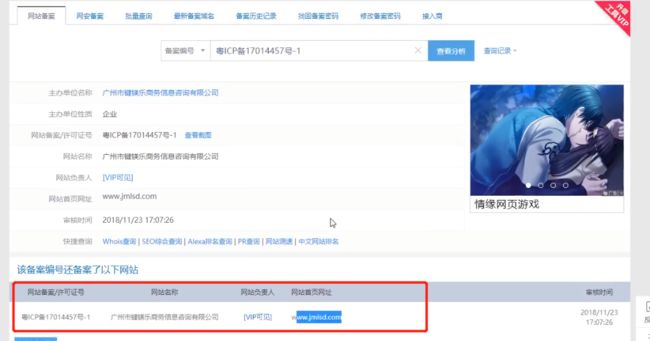
-
备案查询
通过备案号看到其关联的网站
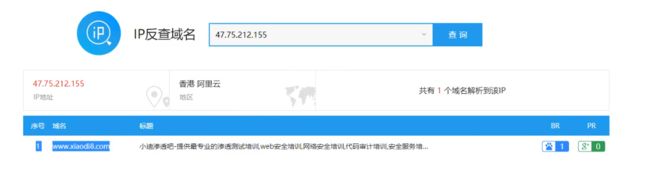
-
-
IP反查域名
通过网站
2.Github监控
简介:
GitHub是一个面向开源及私有软件项目的托管平台,因为只支持Git作为唯一的版本库格式进行托管,故名GitHub。
GitHub是搞计算机使用较多的平台,有很多项目
目的:
-
收集相关漏洞信息
-
便于发现相关测试目标的资产
-
便于收集整理最新exp或poc
(POC全称是Proof of Concept,中文译作概念验证。它是专门为了验证漏洞是否真的存在的脚本。而EXP全称是Exploit,中文译作漏洞利用程序。它是对POC验证结果的一种漏洞利用脚本。)
演示案例:
-
监控最新的 EXP 发布及其他 – 便于发现相关测试目标的资产
server酱:http://sc.ftqq.com/3.version
GitHub项目监控地址:https://github.com/weixiao9188/wechat_push
python代码爬取数据看看能不能爬取到对应的源码信息:
# Title: wechat push CVE-2020 # Date: 2020-5-9 # Exploit Author: weixiao9188 # Version: 4.0 # Tested on: Linux,windows # coding:UTF-8 import requests import json import time import os import pandas as pd time_sleep = 20 #每隔20秒爬取一次 while(True): headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400"} #判断文件是否存在 datas = [] response1=None response2=None if os.path.exists("olddata.csv"): #如果文件存在则每次爬取10个 df = pd.read_csv("olddata.csv", header=None) datas = df.where(df.notnull(),None).values.tolist()#将提取出来的数据中的nan转化为None response1 = requests.get(url="https://api.github.com/search/repositories?q=CVE-2020&sort=updated&per_page=10", headers=headers) response2 = requests.get(url="https://api.github.com/search/repositories?q=RCE&ssort=updated&per_page=10", headers=headers) else: #不存在爬取全部 datas = [] response1 = requests.get(url="https://api.github.com/search/repositories?q=CVE-2020&sort=updated&order=desc",headers=headers) response2 = requests.get(url="https://api.github.com/search/repositories?q=RCE&ssort=updated&order=desc",headers=headers) data1 = json.loads(response1.text) data2 = json.loads(response2.text) for j in [data1["items"],data2["items"]]: for i in j: s = {"name":i['name'],"html":i['html_url'],"description":i['description']} s1 =[i['name'],i['html_url'],i['description']] if s1 not in datas: #print(s1) #print(datas) params = { "text":s["name"], "desp":" 链接:"+str(s["html"])+"\n简介"+str(s["description"]) } print("当前推送为"+str(s)+"\n") print(params) requests.get("https://sc.ftqq.com/XXXX.send",params=params,timeout=10) #time.sleep(1)#以防推送太猛 print("推送完成!") datas.append(s1) else: pass #print("数据已处在!") pd.DataFrame(datas).to_csv("olddata.csv",header=None,index=None) time.sleep(time_sleep)