C语言入门教程,C语言学习教程(非常详细)第四章 c语言输入输出
C语言数据输出大汇总以及轻量进阶
在C语言中,有三个函数可以用来在显示器上输出数据,它们分别是:
- puts():只能输出字符串,并且输出结束后会自动换行,在《第一个C语言程序》中已经进行了介绍。
- putchar():只能输出单个字符,在《在C语言中使用英文字符》中已经进行了介绍。
- printf():可以输出各种类型的数据,在前面的很多章节中都进行了介绍。
printf() 是最灵活、最复杂、最常用的输出函数,完全可以替代 puts() 和 putchar(),大家一定要掌握。前面的章节中我们已经介绍了 printf() 的基本用法,本节将重点介绍 printf() 的高级用法。
对于初学者,这一节的内容可能有些繁杂,如果你希望加快学习进度,尽早写出有趣的代码,也可以跳过这节,后面遇到不懂的 printf() 用法再来回顾。
首先汇总一下前面学到的格式控制符:
| 格式控制符 | 说明 |
|---|---|
| %c | 输出一个单一的字符 |
| %hd、%d、%ld | 以十进制、有符号的形式输出 short、int、long 类型的整数 |
| %hu、%u、%lu | 以十进制、无符号的形式输出 short、int、long 类型的整数 |
| %ho、%o、%lo | 以八进制、不带前缀、无符号的形式输出 short、int、long 类型的整数 |
| %#ho、%#o、%#lo | 以八进制、带前缀、无符号的形式输出 short、int、long 类型的整数 |
| %hx、%x、%lx %hX、%X、%lX |
以十六进制、不带前缀、无符号的形式输出 short、int、long 类型的整数。如果 x 小写,那么输出的十六进制数字也小写;如果 X 大写,那么输出的十六进制数字也大写。 |
| %#hx、%#x、%#lx %#hX、%#X、%#lX |
以十六进制、带前缀、无符号的形式输出 short、int、long 类型的整数。如果 x 小写,那么输出的十六进制数字和前缀都小写;如果 X 大写,那么输出的十六进制数字和前缀都大写。 |
| %f、%lf | 以十进制的形式输出 float、double 类型的小数 |
| %e、%le %E、%lE |
以指数的形式输出 float、double 类型的小数。如果 e 小写,那么输出结果中的 e 也小写;如果 E 大写,那么输出结果中的 E 也大写。 |
| %g、%lg %G、%lG |
以十进制和指数中较短的形式输出 float、double 类型的小数,并且小数部分的最后不会添加多余的 0。如果 g 小写,那么当以指数形式输出时 e 也小写;如果 G 大写,那么当以指数形式输出时 E 也大写。 |
| %s | 输出一个字符串 |
printf() 的高级用法
通过前面的学习,相信你已经熟悉了 printf() 的基本用法,但是这还不足以把它发挥到极致,printf() 可以有更加炫酷、更加个性、更加整齐的输出形式。
假如现在老师要我们输出一个 4×4 的整数矩阵,为了增强阅读性,数字要对齐,怎么办呢?我们显然可以这样做:
- #include
- int main()
- {
- int a1=20, a2=345, a3=700, a4=22;
- int b1=56720, b2=9999, b3=20098, b4=2;
- int c1=233, c2=205, c3=1, c4=6666;
- int d1=34, d2=0, d3=23, d4=23006783;
- printf("%d %d %d %d\n", a1, a2, a3, a4);
- printf("%d %d %d %d\n", b1, b2, b3, b4);
- printf("%d %d %d %d\n", c1, c2, c3, c4);
- printf("%d %d %d %d\n", d1, d2, d3, d4);
- return 0;
- }
运行结果:
20 345 700 22 56720 9999 20098 2 233 205 1 6666 34 0 23 23006783
矩阵一般在大学的《高等数学》中会讲到,m×n 的数字矩阵可以理解为把 m×n 个数字摆放成 m 行 n 列的样子。
看,这是多么地自虐,要敲那么多空格,还要严格控制空格数,否则输出就会错位。更加恶心的是,如果数字的位数变了,空格的数目也要跟着变。例如,当 a1 的值是 20 时,它后面要敲八个空格;当 a1 的值是 1000 时,它后面就要敲六个空格。每次修改整数的值,都要考虑修改空格的数目,逼死强迫症。
类似的需求随处可见,整齐的格式会更加美观,让人觉得生动有趣。其实,我们大可不必像上面一样,printf() 可以更好的控制输出格式。更改上面的代码:
- #include
- int main()
- {
- int a1=20, a2=345, a3=700, a4=22;
- int b1=56720, b2=9999, b3=20098, b4=2;
- int c1=233, c2=205, c3=1, c4=6666;
- int d1=34, d2=0, d3=23, d4=23006783;
- printf("%-9d %-9d %-9d %-9d\n", a1, a2, a3, a4);
- printf("%-9d %-9d %-9d %-9d\n", b1, b2, b3, b4);
- printf("%-9d %-9d %-9d %-9d\n", c1, c2, c3, c4);
- printf("%-9d %-9d %-9d %-9d\n", d1, d2, d3, d4);
- return 0;
- }
输出结果:
20 345 700 22 56720 9999 20098 2 233 205 1 6666 34 0 23 23006783
这样写起来更加方便,即使改变某个数字,也无需修改 printf() 语句,增加或者减少空格数目。%-9d中,d表示以十进制输出,9表示最少占9个字符的宽度,宽度不足以空格补齐,-表示左对齐。综合起来,%-9d表示以十进制输出,左对齐,宽度最小为9个字符。大家可以亲自试试%9d的输出效果。
printf() 格式控制符的完整形式如下:
%[flag][width][.precision]type
[ ] 表示此处的内容可有可无,是可以省略的。
1) type 表示输出类型,比如 %d、%f、%c、%lf,type 就分别对应 d、f、c、lf;再如,%-9d中 type 对应 d。
type 这一项必须有,这意味着输出时必须要知道是什么类型。
2) width 表示最小输出宽度,也就是至少占用几个字符的位置;例如,%-9d中 width 对应 9,表示输出结果最少占用 9 个字符的宽度。
当输出结果的宽度不足 width 时,以空格补齐(如果没有指定对齐方式,默认会在左边补齐空格);当输出结果的宽度超过 width 时,width 不再起作用,按照数据本身的宽度来输出。
下面的代码演示了 width 的用法:
- #include
- int main(){
- int n = 234;
- float f = 9.8;
- char c = '@';
- char *str = "http://c.biancheng.net";
- printf("%10d%12f%4c%8s", n, f, c, str);
- return 0;
- }
运行结果:
234 9.800000 @http://c.biancheng.net
对输出结果的说明:
- n 的指定输出宽度为 10,234 的宽度为 3,所以前边要补上 7 个空格。
- f 的指定输出宽度为 12,9.800000 的宽度为 8,所以前边要补上 4 个空格。
- str 的指定输出宽度为 8,"http://c.biancheng.net" 的宽度为 22,超过了 8,所以指定输出宽度不再起作用,而是按照 str 的实际宽度输出。
3) .precision 表示输出精度,也就是小数的位数。
- 当小数部分的位数大于 precision 时,会按照四舍五入的原则丢掉多余的数字;
- 当小数部分的位数小于 precision 时,会在后面补 0。
另外,.precision 也可以用于整数和字符串,但是功能却是相反的:
- 用于整数时,.precision 表示最小输出宽度。与 width 不同的是,整数的宽度不足时会在左边补 0,而不是补空格。
- 用于字符串时,.precision 表示最大输出宽度,或者说截取字符串。当字符串的长度大于 precision 时,会截掉多余的字符;当字符串的长度小于 precision 时,.precision 就不再起作用。
请看下面的例子:
- #include
- int main(){
- int n = 123456;
- double f = 882.923672;
- char *str = "abcdefghi";
- printf("n: %.9d %.4d\n", n, n);
- printf("f: %.2lf %.4lf %.10lf\n", f, f, f);
- printf("str: %.5s %.15s\n", str, str);
- return 0;
- }
运行结果:
n: 000123456 123456 f: 882.92 882.9237 882.9236720000 str: abcde abcdefghi
对输出结果的说明:
- 对于 n,.precision 表示最小输出宽度。n 本身的宽度为 6,当 precision 为 9 时,大于 6,要在 n 的前面补 3 个 0;当 precision 为 4 时,小于 6,不再起作用。
- 对于 f,.precision 表示输出精度。f 的小数部分有 6 位数字,当 precision 为 2 或者 4 时,都小于 6,要按照四舍五入的原则截断小数;当 precision 为 10 时,大于 6,要在小数的后面补四个 0。
- 对于 str,.precision 表示最大输出宽度。str 本身的宽度为 9,当 precision 为 5 时,小于 9,要截取 str 的前 5 个字符;当 precision 为 15 时,大于 9,不再起作用。
4) flag 是标志字符。例如,%#x中 flag 对应 #,%-9d中 flags 对应-。下表列出了 printf() 可以用的 flag:
| 标志字符 | 含 义 |
|---|---|
| - | -表示左对齐。如果没有,就按照默认的对齐方式,默认一般为右对齐。 |
| + | 用于整数或者小数,表示输出符号(正负号)。如果没有,那么只有负数才会输出符号。 |
| 空格 | 用于整数或者小数,输出值为正时冠以空格,为负时冠以负号。 |
| # |
|
请看下面的例子:
- #include
- int main(){
- int m = 192, n = -943;
- float f = 84.342;
- printf("m=%10d, m=%-10d\n", m, m); //演示 - 的用法
- printf("m=%+d, n=%+d\n", m, n); //演示 + 的用法
- printf("m=% d, n=% d\n", m, n); //演示空格的用法
- printf("f=%.0f, f=%#.0f\n", f, f); //演示#的用法
- return 0;
- }
运行结果:
m= 192, m=192 m=+192, n=-943 m= 192, n=-943 f=84, f=84.
对输出结果的说明:
- 当以
%10d输出 m 时,是右对齐,所以在 192 前面补七个空格;当以%-10d输出 m 时,是左对齐,所以在 192 后面补七个空格。 - m 是正数,以
%+d输出时要带上正号;n 是负数,以%+d输出时要带上负号。 - m 是正数,以
% d输出时要在前面加空格;n 是负数,以% d输出时要在前面加负号。 %.0f表示保留 0 位小数,也就是只输出整数部分,不输出小数部分。默认情况下,这种输出形式是不带小数点的,但是如果有了#标志,那么就要在整数的后面“硬加上”一个小数点,以和纯整数区分开。
printf() 不能立即输出的问题
printf() 有一个尴尬的问题,就是有时候不能立即输出,请看下面的代码:
- #include
- #include
- int main()
- {
- printf("C语言中文网");
- sleep(5); //程序暂停5秒钟
- printf("http://c.biancheng.net\n");
- return 0;
- }
这段代码使用了两个 printf() 语句,它们之间有一个 sleep() 函数,该函数的作用是让程序暂停 5 秒,然后再继续执行。sleep() 是 Linux 和 Mac OS 下特有的函数,不能用于 Windows。当然,Windows 下也有功能相同的暂停函数,叫做 Sleep(),稍后我们会讲解。
在 Linux 或者 Mac OS 下运行该程序,会发现第一个 printf() 并没有立即输出,而是等待 5 秒以后,和第二个 printf() 一起输出了,请看下面的动图演示:

我们不妨修改一下代码,在第一个 printf() 的最后添加一个换行符,如下所示:
printf("C语言中文网\n");
再次编译并运行程序,发现第一个 printf() 首先输出(程序运行后立即输出),等待 5 秒以后,第二个 printf() 才输出,请看下面的动图演示:

为什么一个换行符\n就能让程序的表现有天壤之别呢?按照通常的逻辑,程序运行后第一个 printf() 应该立即输出,而不是等待 5 秒以后再和第二个 printf() 一起输出,也就是说,第二种情形才符合我们的惯性思维。然而,第一种情形该如何理解呢?
其实,这一切都是输出缓冲区(缓存)在作怪!
从本质上讲,printf() 执行结束以后数据并没有直接输出到显示器上,而是放入了缓冲区,直到遇见换行符\n才将缓冲区中的数据输出到显示器上。更加深入的内容,我们将在本章的《进入缓冲区(缓存)的世界,破解一切与输入输出有关的疑难杂症》中详细讲解。
以上测试的是 Linux 和 Mac OS,我们不妨再测试一下 Windows,请看下面的代码:
- #include
- #include
- int main()
- {
- printf("C语言中文网");
- Sleep(5000); //程序暂停5秒钟
- printf("http://c.biancheng.net\n");
- return 0;
- }
在 Windows 下,想让程序暂停可以使用 Windows.h 头文件中的 Sleep() 函数(S要大写),它和 Linux 下的 sleep() 功能相同。不过,sleep() 要求的时间单位是秒,而 Sleep() 要求的时间单位是毫秒,1 秒等于 1000 毫秒。这段代码中,我们要求程序暂停 5000 毫秒,也即 5 秒。
编译并运行程序,会发现第一个 printf() 首先输出(程序运行后立即输出),等待 5 秒以后,第二个 printf() 才输出,请看下面的动画演示:

在第一个 printf() 的最后添加一个换行符,情况也是一样的,第一个 printf() 从来不会和第二个 printf() 一起输出。
你看,Windows 和 Linux、Mac OS 的情况又不一样。这是因为,Windows 和 Linux、Mac OS 的缓存机制不同。更加深入的内容,我们将在本章的《进入缓冲区(缓存)的世界,破解一切与输入输出有关的疑难杂症》中详细讲解。
要想破解 printf() 输出的问题,必须要了解缓存,它能使你对输入输出的认识上升到一个更高的层次,以后不管遇到什么疑难杂症,都能迎刃而解。可以说,输入输出的“命门”就在于缓存。
总结
对于初学者来说,上面讲到的 printf() 用法已经比较复杂了,基本满足了实际开发的需求,相信大家也需要一段时间才能熟悉。但是,受到所学知识的限制,本文也未能讲解 printf() 的所有功能,后续我们还会逐步深入。
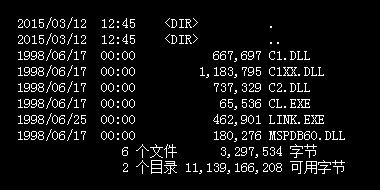
printf() 的这些格式规范不是“小把戏”,优美的输出格式随处可见,例如,dos 下的 dir 命令,会整齐地列出当前目录下的文件,这明显使用了右对齐,还指定了宽度。
C语言scanf:读取从键盘输入的数据(含输入格式汇总表)
程序是人机交互的媒介,有输出必然也有输入,第三章我们讲解了如何将数据输出到显示器上,本章我们开始讲解如何从键盘输入数据。在C语言中,有多个函数可以从键盘获得用户输入:
- scanf():和 printf() 类似,scanf() 可以输入多种类型的数据。
- getchar()、getche()、getch():这三个函数都用于输入单个字符。
- gets():获取一行数据,并作为字符串处理。
scanf() 是最灵活、最复杂、最常用的输入函数,但它不能完全取代其他函数,大家都要有所了解。
本节我们只讲解 scanf(),其它的输入函数将在下节讲解。
scanf()函数
scanf 是 scan format 的缩写,意思是格式化扫描,也就是从键盘获得用户输入,和 printf 的功能正好相反。
我们先来看一个例子:
- #include
- int main()
- {
- int a = 0, b = 0, c = 0, d = 0;
- scanf("%d", &a); //输入整数并赋值给变量a
- scanf("%d", &b); //输入整数并赋值给变量b
- printf("a+b=%d\n", a+b); //计算a+b的值并输出
- scanf("%d %d", &c, &d); //输入两个整数并分别赋值给c、d
- printf("c*d=%d\n", c*d); //计算c*d的值并输出
- return 0;
- }
运行结果:
12↙
60↙
a+b=72
10 23↙
c*d=230
↙表示按下回车键。
从键盘输入12,按下回车键,scanf() 就会读取输入数据并赋值给变量 a;本次输入结束,接着执行下一个 scanf() 函数,再从键盘输入 60,按下回车键,就会将 60 赋值给变量 b,都是同样的道理。
第 8 行代码中,scanf() 有两个以空格分隔的%d,后面还跟着两个变量,这要求我们一次性输入两个整数,并分别赋值给 c 和 d。注意"%d %d"之间是有空格的,所以输入数据时也要有空格。对于 scanf(),输入数据的格式要和控制字符串的格式保持一致。
其实 scanf 和 printf 非常相似,只是功能相反罢了:
- scanf("%d %d", &a, &b); // 获取用户输入的两个整数,分别赋值给变量 a 和 b
- printf("%d %d", a, b); // 将变量 a 和 b 的值在显示器上输出
它们都有格式控制字符串,都有变量列表。不同的是,scanf 的变量前要带一个&符号。&称为取地址符,也就是获取变量在内存中的地址。
在《数据在内存中的存储》一节中讲到,数据是以二进制的形式保存在内存中的,字节(Byte)是最小的可操作单位。为了便于管理,我们给每个字节分配了一个编号,使用该字节时,只要知道编号就可以,就像每个学生都有学号,老师会随机抽取学号来让学生回答问题。字节的编号是有顺序的,从 0 开始,接下来是 1、2、3……
下图是 4G 内存中每个字节的编号(以十六进制表示):
这个编号,就叫做地址(Address)。int a;会在内存中分配四个字节的空间,我们将第一个字节的地址称为变量 a 的地址,也就是&a的值。对于前面讲到的整数、浮点数、字符,都要使用 & 获取它们的地址,scanf 会根据地址把读取到的数据写入内存。
我们不妨将变量的地址输出看一下:
- #include
- int main()
- {
- int a='F';
- int b=12;
- int c=452;
- printf("&a=%p, &b=%p, &c=%p\n", &a, &b, &c);
- return 0;
- }
输出结果:
&a=0x18ff48, &b=0x18ff44, &c=0x18ff40%p是一个新的格式控制符,它表示以十六进制的形式(带小写的前缀)输出数据的地址。如果写作%P,那么十六进制的前缀也将变成大写形式。

图:a、b、c 的内存地址
注意:这里看到的地址都是假的,是虚拟地址,并不等于数据在物理内存中的地址。虚拟地址是现代计算机因内存管理的需要才提出的概念,我们将在《 C语言内存精讲》专题中详细讲解。
再来看一个 scanf 的例子:
- #include
- int main()
- {
- int a, b, c;
- scanf("%d %d", &a, &b);
- printf("a+b=%d\n", a+b);
- scanf("%d %d", &a, &b);
- printf("a+b=%d\n", a+b);
- scanf("%d, %d, %d", &a, &b, &c);
- printf("a+b+c=%d\n", a+b+c);
- scanf("%d is bigger than %d", &a, &b);
- printf("a-b=%d\n", a-b);
- return 0;
- }
运行结果:
10 20↙ a+b=30 100 200↙ a+b=300 56,45,78↙ a+b+c=179 25 is bigger than 11↙ a-b=14
第一个 scanf() 的格式控制字符串为"%d %d",中间有一个空格,而我们却输入了10 20,中间有多个空格。第二个 scanf() 的格式控制字符串为"%d %d",中间有多个空格,而我们却输入了100 200,中间只有一个空格。这说明 scanf() 对输入数据之间的空格的处理比较宽松,并不要求空格数严格对应,多几个少几个无所谓,只要有空格就行。
第三个 scanf() 的控制字符串为"%d, %d, %d",中间以逗号分隔,所以输入的整数也要以逗号分隔。
第四个 scanf() 要求整数之间以is bigger than分隔。
用户每次按下回车键,程序就会认为完成了一次输入操作,scanf() 开始读取用户输入的内容,并根据格式控制字符串从中提取有效数据,只要用户输入的内容和格式控制字符串匹配,就能够正确提取。
本质上讲,用户输入的内容都是字符串,scanf() 完成的是从字符串中提取有效数据的过程。
连续输入
在本节第一段示例代码中,我们一个一个地输入变量 a、b、c、d 的值,每输入一个值就按一次回车键。现在我们改变输入方式,将四个变量的值一次性输入,如下所示:
12 60 10 23↙
a+b=72
c*d=230
可以发现,两个 scanf() 都能正确读取。合情合理的猜测是,第一个 scanf() 读取完毕后没有抛弃多余的值,而是将它们保存在了某个地方,下次接着使用。
如果我们多输入一个整数,会怎样呢?
12 60 10 23 99↙
a+b=72
c*d=230
这次我们多输入了一个 99,发现 scanf() 仍然能够正确读取,只是 99 没用罢了。
如果我们少输入一个整数,又会怎样呢?
12 60 10↙
a+b=72
23↙
c*d=230
输入三个整数后,前两个 scanf() 把前两个整数给读取了,剩下一个整数 10,而第三个 scanf() 要求输入两个整数,一个单独的 10 并不能满足要求,所以我们还得继续输入,凑够两个整数以后,第三个 scanf() 才能读取完毕。
从本质上讲,我们从键盘输入的数据并没有直接交给 scanf(),而是放入了缓冲区中,直到我们按下回车键,scanf() 才到缓冲区中读取数据。如果缓冲区中的数据符合 scanf() 的要求,那么就读取结束;如果不符合要求,那么就继续等待用户输入,或者干脆读取失败。我们将在本章的《进入缓冲区(缓存)的世界,破解一切与输入输出有关的疑难杂症》《结合C语言缓冲区谈scanf函数》两节中详细讲解缓冲区。
注意,如果缓冲区中的数据不符合 scanf() 的要求,要么继续等待用户输入,要么就干脆读取失败,上面我们演示了“继续等待用户输入”的情形,下面我们对代码稍作修改,演示“读取失败”的情形。
- #include
- int main()
- {
- int a = 1, b = 2, c = 3, d = 4; //修改处:给变量赋予不同的初始值
- scanf("%d", &a);
- scanf("%d", &b);
- printf("a=%d, b=%d\n", a, b);
- scanf("%d %d", &c, &d);
- printf("c=%d, d=%d\n", c, d);
- return 0;
- }
运行结果:
12 60 a10↙
a=12, b=60
c=3, d=4
前两个整数被正确读取后,剩下了 a10,而第三个 scanf() 要求输入两个十进制的整数,a10 无论如何也不符合要求,所以只能读取失败。输出结果也证明了这一点,c 和 d 的值并没有被改变。
这说明 scanf() 不会跳过不符合要求的数据,遇到不符合要求的数据会读取失败,而不是再继续等待用户输入。
总而言之,正是由于缓冲区的存在,才使得我们能够多输入一些数据,或者一次性输入所有数据,这可以认为是缓冲区的一点优势。然而,缓冲区也带来了一定的负面影响,甚至会导致很奇怪的行为,请看下面的代码:
- #include
- int main()
- {
- int a = 1, b = 2;
- scanf("a=%d", &a);
- scanf("b=%d", &b);
- printf("a=%d, b=%d\n", a, b);
- return 0;
- }
输入示例:
a=99↙
a=99, b=2
输入a=99,按下回车键,程序竟然运行结束了,只有第一个 scanf() 成功读取了数据,第二个 scanf() 仿佛没有执行一样,根本没有给用户任何机会去输入数据。
如果我们换一种输入方式呢?
a=99b=200↙
a=99, b=200
这样 a 和 b 都能够正确读取了。注意,a=99b=200中间是没有任何空格的。
肯定有好奇的小伙伴又问了,如果a=99b=200两个数据之间有空格又会怎么样呢?我们不妨亲试一下:
a=99 b=200↙
a=99, b=2
你看,第二个 scanf() 又读取失败了!在前面的例子中,输入的两份数据之前都是有空格的呀,为什么这里不能带空格呢,真是匪夷所思。好吧,这个其实还是跟缓冲区有关系,我将在《结合C语言缓冲区谈scanf()函数》中深入讲解。
要想破解 scanf() 输入的问题,一定要学习缓冲区,它能使你对输入输出的认识上升到一个更高的层次,以后不管遇到什么疑难杂症,都能迎刃而解。可以说,输入输出的“命门”就在于缓冲区。
输入其它数据
除了输入整数,scanf() 还可以输入单个字符、字符串、小数等,请看下面的演示:
- #include
- int main()
- {
- char letter;
- int age;
- char url[30];
- float price;
- scanf("%c", &letter);
- scanf("%d", &age);
- scanf("%s", url); //可以加&也可以不加&
- scanf("%f", &price);
- printf("26个英文字母的最后一个是 %c。\n", letter);
- printf("C语言中文网已经成立%d年了,网址是 %s,开通VIP会员的价格是%g。\n", age, url, price);
- return 0;
- }
运行示例:
z↙
6↙
http://c.biancheng.net↙
159.9↙
26个英文字母的最后一个是 z。
C语言中文网已经成立6年了,网址是 http://c.biancheng.net,开通VIP会员的价格是159.9。
scanf() 和 printf() 虽然功能相反,但是格式控制符是一样的,单个字符、整数、小数、字符串对应的格式控制符分别是 %c、%d、%f、%s。
对读取字符串的说明
在《在C语言中使用英文字符》一节中,我们谈到了字符串的两种定义形式,它们分别是:
char str1[] = "http://c.biancheng.net";
char *str2 = "C语言中文网";
这两种形式其实是有区别的,第一种形式的字符串所在的内存既有读取权限又有写入权限,第二种形式的字符串所在的内存只有读取权限,没有写入权限。printf()、puts() 等字符串输出函数只要求字符串有读取权限,而 scanf()、gets() 等字符串输入函数要求字符串有写入权限,所以,第一种形式的字符串既可以用于输出函数又可以用于输入函数,而第二种形式的字符串只能用于输出函数。
另外,对于第一种形式的字符串,在[ ]里面要指明字符串的最大长度,如果不指明,也可以根据=后面的字符串来自动推算,此处,就是根据"http://c.biancheng.net"的长度来推算的。但是在前一个例子中,开始我们只是定义了一个字符串,并没有立即给它赋值,所以没法自动推算,只能手动指明最大长度,这也就是为什么一定要写作char url[30],而不能写作char url[]的原因。
读者还要注意第 11 行代码,这行代码用来输入字符串。上面我们说过,scanf() 读取数据时需要的是数据的地址,整数、小数、单个字符都要加&取地址符,这很容易理解;但是对于此处的 url 字符串,我们并没有加 &,这是因为,字符串的名字会自动转换为字符串的地址,所以不用再多此一举加 & 了。当然,你也可以加上,这样虽然不会导致错误,但是编译器会产生警告,至于为什么,我们将会在《数组和指针绝不等价,数组是另外一种类型》《数组到底在什么时候会转换为指针》中讲解。
关于字符串,后续章节我们还会专门讲解,这里只要求大家会模仿,不要彻底理解,也没法彻底理解。
最后需要注意的一点是,scanf() 读取字符串时以空格为分隔,遇到空格就认为当前字符串结束了,所以无法读取含有空格的字符串,请看下面的例子:
- #include
- int main()
- {
- char author[30], lang[30], url[30];
- scanf("%s %s", author, lang);
- printf("author:%s \nlang: %s\n", author, lang);
- scanf("%s", url);
- printf("url: %s\n", url);
- return 0;
- }
运行示例:
YanChangSheng C-Language↙
author:YanChangSheng
lang: C-Language
http://c.biancheng.net http://biancheng.net↙
url: http://c.biancheng.net
对于第一个 scanf(),它将空格前边的字符串赋值给 author,将空格后边的字符串赋值给 lang;很显然,第一个字符串遇到空格就结束了,第二个字符串到了本行的末尾结束了。
或许第二个 scanf() 更能说明问题,我们输入了两个网址,但是 scanf() 只读取了一个,就是因为这两个网址以空格为分隔,scanf() 遇到空格就认为字符串结束了,不再继续读取了。
scanf() 格式控制符汇总
| 格式控制符 | 说明 |
|---|---|
| %c | 读取一个单一的字符 |
| %hd、%d、%ld | 读取一个十进制整数,并分别赋值给 short、int、long 类型 |
| %ho、%o、%lo | 读取一个八进制整数(可带前缀也可不带),并分别赋值给 short、int、long 类型 |
| %hx、%x、%lx | 读取一个十六进制整数(可带前缀也可不带),并分别赋值给 short、int、long 类型 |
| %hu、%u、%lu | 读取一个无符号整数,并分别赋值给 unsigned short、unsigned int、unsigned long 类型 |
| %f、%lf | 读取一个十进制形式的小数,并分别赋值给 float、double 类型 |
| %e、%le | 读取一个指数形式的小数,并分别赋值给 float、double 类型 |
| %g、%lg | 既可以读取一个十进制形式的小数,也可以读取一个指数形式的小数,并分别赋值给 float、double 类型 |
| %s | 读取一个字符串(以空白符为结束) |
C语言输入字符和字符串(所有函数大汇总)
C语言有多个函数可以从键盘获得用户输入,它们分别是:
- scanf():和 printf() 类似,scanf() 可以输入多种类型的数据。
- getchar()、getche()、getch():这三个函数都用于输入单个字符。
- gets():获取一行数据,并作为字符串处理。
scanf() 是最灵活、最复杂、最常用的输入函数,上节我们已经进行了讲解,本节接着讲解剩下的函数,也就是字符输入函数和字符串输入函数。
输入单个字符
输入单个字符当然可以使用 scanf() 这个通用的输入函数,对应的格式控制符为%c,上节已经讲到了。本节我们重点讲解的是 getchar()、getche() 和 getch() 这三个专用的字符输入函数,它们具有某些 scanf() 没有的特性,是 scanf() 不能代替的。
1) getchar()
最容易理解的字符输入函数是 getchar(),它就是scanf("%c", c)的替代品,除了更加简洁,没有其它优势了;或者说,getchar() 就是 scanf() 的一个简化版本。
下面的代码演示了 getchar() 的用法:
- #include
- int main()
- {
- char c;
- c = getchar();
- printf("c: %c\n", c);
- return 0;
- }
输入示例:
@↙
c: @
你也可以将第 4、5 行的语句合并为一个,从而写作:
char c = getchar();
2) getche()
getche() 就比较有意思了,它没有缓冲区,输入一个字符后会立即读取,不用等待用户按下回车键,这是它和 scanf()、getchar() 的最大区别。请看下面的代码:
- #include
- #include
- int main()
- {
- char c = getche();
- printf("c: %c\n", c);
- return 0;
- }
输入示例:
@c: @
输入@后,getche() 立即读取完毕,接着继续执行 printf() 将字符输出,所以没有按下回车键程序就运行结束了。
注意,getche() 位于 conio.h 头文件中,而这个头文件是 Windows 特有的,Linux 和 Mac OS 下没有包含该头文件。换句话说,getche() 并不是标准函数,默认只能在 Windows 下使用,不能在 Linux 和 Mac OS 下使用。
3) getch()
getch() 也没有缓冲区,输入一个字符后会立即读取,不用按下回车键,这一点和 getche() 相同。getch() 的特别之处是它没有回显,看不到输入的字符。所谓回显,就是在控制台上显示出用户输入的字符;没有回显,就不会显示用户输入的字符,就好像根本没有输入一样。
回显在大部分情况下是有必要的,它能够与用户及时交互,让用户清楚地看到自己输入的内容。但在某些特殊情况下,我们却不希望有回显,例如输入密码,有回显是非常危险的,容易被偷窥。
getch() 使用举例:
- #include
- #include
- int main()
- {
- char c = getch();
- printf("c: %c\n", c);
- return 0;
- }
输入@后,getch() 会立即读取完毕,接着继续执行 printf() 将字符输出。但是由于 getch() 没有回显,看不到输入的@字符,所以控制台上最终显示的内容为c: @。
注意,和 getche() 一样,getch() 也位于 conio.h 头文件中,也不是标准函数,默认只能在 Windows 下使用,不能在 Linux 和 Mac OS 下使用。
对三个函数的总结
| 函数 | 缓冲区 | 头文件 | 回显 | 适用平台 |
|---|---|---|---|---|
| getchar() | 有 | stdio.h | 有 | Windows、Linux、Mac OS 等所有平台 |
| getche() | 无 | conio.h | 有 | Windows |
| getch() | 无 | conio.h | 无 | Windows |
关于缓冲区,我们将在下节《进入缓冲区(缓存)的世界,破解一切与输入输出有关的疑难杂症》中展开讲解。
输入字符串
输入字符串当然可以使用 scanf() 这个通用的输入函数,对应的格式控制符为%s,上节已经讲到了;本节我们重点讲解的是 gets() 这个专用的字符串输入函数,它拥有一个 scanf() 不具备的特性。
gets() 的使用也很简单,请看下面的代码:
- #include
- int main()
- {
- char author[30], lang[30], url[30];
- gets(author);
- printf("author: %s\n", author);
- gets(lang);
- printf("lang: %s\n", lang);
- gets(url);
- printf("url: %s\n", url);
- return 0;
- }
运行结果:
YanChangSheng↙
author: YanChangSheng
C-Language↙
lang: C-Language
http://c.biancheng.net http://biancheng.net↙
url: http://c.biancheng.net http://biancheng.net
gets() 是有缓冲区的,每次按下回车键,就代表当前输入结束了,gets() 开始从缓冲区中读取内容,这一点和 scanf() 是一样的。gets() 和 scanf() 的主要区别是:
- scanf() 读取字符串时以空格为分隔,遇到空格就认为当前字符串结束了,所以无法读取含有空格的字符串。
- gets() 认为空格也是字符串的一部分,只有遇到回车键时才认为字符串输入结束,所以,不管输入了多少个空格,只要不按下回车键,对 gets() 来说就是一个完整的字符串。
也就是说,gets() 能读取含有空格的字符串,而 scanf() 不能。
总结
C语言中常用的从控制台读取数据的函数有五个,它们分别是 scanf()、getchar()、getche()、getch() 和 gets()。其中 scanf()、getchar()、gets() 是标准函数,适用于所有平台;getche() 和 getch() 不是标准函数,只能用于 Windows。
scanf() 是通用的输入函数,它可以读取多种类型的数据。
getchar()、getche() 和 getch() 是专用的字符输入函数,它们在缓冲区和回显方面与 scanf() 有着不同的特性,是 scanf() 不能替代的。
gets() 是专用的字符串输入函数,与 scanf() 相比,gets() 的主要优势是可以读取含有空格的字符串。
scanf() 可以一次性读取多份类型相同或者不同的数据,getchar()、getche()、getch() 和 gets() 每次只能读取一份特定类型的数据,不能一次性读取多份数据。