Hologres使用小记
1、Hologres 0.8 创建数组类型外部表采坑
ODPS:CREATE TABLE `test_clue` ( `id_c` array
Holo:
CREATE FOREIGN TABLE test_clue(
id int8[],
name text[])
SERVER odps_server
OPTIONS(project_name 'itsl_dev', table_name 'test_clue');
报错: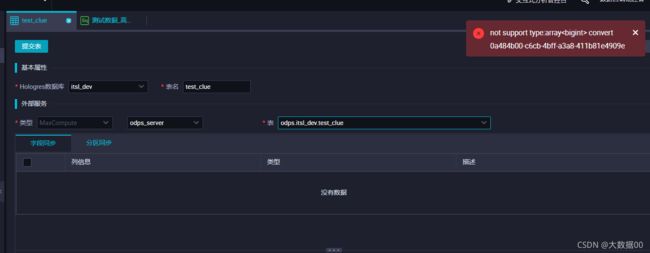
原因:odps文件类型不是orc
odps的文件类型有哪些:??aliorc
hive的文件存储类型:
||SequenceFile
Hadoop用来存储二进制形式的[Key,Value]对而设计的一种平面文件(Flat File)。
||TextFile文本格式
||RCFile一种列存储格式
||ORC ★一种列存储格式 进阶版RCFile
||Parquet ★一种列存储格式AVRO
||JsonFile(json文件)
||InputFormat
解决办法:
odps建表前加:
set odps.sql.default.file.format=aliorc;
set odps.storage.force.aliorc=true;
CREATE TABLE `test_clue` ( `id_c` array
2、Hologres 0.8 使用get_json_object函数
先用super账号设置开启hive函数支持:CREATE extension hive_compatible;
SELECT
get_json_object(message,'$.profileData.advertisingID') AS advertisingID
,get_json_object(message,'$.profileData.appKey') AS appkey
,get_json_object(message,'$.profileData.identityId') AS identityId
,get_json_object(message,'$.profileData.productid') AS productid
,get_json_object(message,'$.profileData.properties._td_mobile') AS td_mobile
,get_json_object(message,'$.profileData.properties._td_pixel') AS td_pixel
,get_json_object(message,'$.profileData.properties._td_platform') AS td_platform
,get_json_object(message,'$.profileData.properties._td_brand') AS td_brand
,get_json_object(message,'$.profileData.properties.tenantid') AS tenantid
,get_json_object(message,'$.profileData.properties._td_os') AS td_os
,get_json_object(message,'$.type') AS TYPE
,get_json_object(message,'$.version') AS version
,get_json_object(message,'$.profileData.properties._td_sdk_source') AS td_sdk_source
,get_json_object(message,'$.profileData.properties._td_browser') AS td_browser
,get_json_object(message,'$.profileData.properties._td_channel') AS td_channel
FROM ti_datahub_ae_collector_data_4h
;
3、hologres 优化查询设置
①analyze
②建表增加索引:
分布式键distribution_key:
call set_table_property('table1','distribution key','b');
指定分布列,数据将按照指定列,将数据shuffle到各个shard,同样的数值肯定会在同样的shrad中。
例:select count(1) from tmp1 join tmp2 on tmp1.a = tmp2.b
注:对于有pk的表,其分布键默认就是pk,如果不想pk字段作为分布键,可以指定pk字段的子集,但是不能随意指定。可以通过shard_count来指定表的shard数,如果不指定的话每个数据库都有一个默认的shard数,一旦指定了一个表的shard数,其他的表如果想要和这个表做local join,就必须指定colcate with这个表。
聚簇索引 Clustering key:对建立索引数据进行排序,建立聚簇索引能够加速用户在索引列上的range和filter查询;注:desc和asc表名构建索引时的排序方式,默认为asc。clustering key创建的时候数据类型不能为float/double,每个表最多只有一个clustering key:
如:call set_table_property('table1','clustering_key','a'); or call set_table_property('tbl', 'clustering_key', 'a:desc,b:asc');
比特编码列bitmap:指定比特编码列使Hologres会在这些列上构建比特编码,相当于把数据与对应的行号做一个映射;注:bitmap可以对segment内部的数据进行快速过滤,因此建议把filter条件的数据建成比特编码。目前Hologres会默认所有text列都会被隐藏式地设置到bitmap_columns中。但是只有列存表支持比特编码列
分段键Segment Key:分段键帮助Hologres进行一些文件的快速筛选和跳过。指定分段键,当查询条件包含分段列时,查询可以通过segment key快速找到相应数据对应的存储位置。注:segment key要求按照数据输入自增,一般只有时间类型的字段(timestamptz)适合设置为segment key,其他场景基本不需要设置。只有列存表支持分段键设置。
字典编码列设置:
call set_table_property('table1','dictionary_encoding_columns','b');
字典编码可以将字符串的比较转换成数字的比较,加速group by查询
例:select sum(a) from table1 group by b;
注:不建议将基数高的列建为字典编码列,会导致查询性能变差。目前Hologres会默认所有text列都会被隐藏式地设置到bitmap_columns中。但是只有列存表支持比特编码列
③存储类型:call set_table_property('table1','orientation','[row|colume]');
行存适用于高QPS的基于primary key的点查询,例如where pk=abc,其余场景都应该选用列存方式。
例如:
drop TABLE tags_humanbeings;
BEGIN;
CREATE TABLE public.tags_humanbeings (
"oneid" text,
"ssoid" text,
"uid" text,
"phone" text,
"name" text,
"idcard" text,
"action" int8,
"date_created" timestamptz,
"gender" int8,
"age_group" int8,
"constellation" int8,
"generation" int8,
"education" int8,
"birthday" text,
"marital_status" int8,
"occupation" int8,
"industry" int8,
"native_province" int8,
"native_city" int8,
"native_city_level" int8,
"material_cost" text,
PRIMARY KEY (oneid)
);
--分布式键
call set_table_property('public.tags_humanbeings', 'distribution_key', 'oneid');
--存储方式 列存 行存
CALL SET_TABLE_PROPERTY('public.tags_humanbeings', 'orientation', 'column');
CALL SET_TABLE_PROPERTY('public.tags_humanbeings', 'time_to_live_in_seconds', '3153600000');
--dictionary_encoding_columns
CALL SET_TABLE_PROPERTY('public.tags_humanbeings', 'dictionary_encoding_columns', 'oneid');
--CALL SET_TABLE_PROPERTY('public.tags_humanbeings', 'clustering_key','oneid'); 默认和主键一致
--bitmap_columns
CALL SET_TABLE_PROPERTY('', 'bitmap_columns', 'phone:on,name:on,birthday:off,material_cost:off');
call set_table_property('public.tags_humanbeings','segment key','date_created');
comment on table public.tags_humanbeings is '人标签表';
COMMIT ;4、调优
当表数据量较大时,可设置以下参数进行调优;
set hg_experimental_query_batch_size = 4096; --默认8192
set hg_experimental_foreign_table_executor_max_dop = 32; --默认64
5、BitmapRoaringRoaring
1、CREATE EXTENSION roaringbitmap;
Roaring Bitmap函数在使用之前,需要执行以下语句开启extension才可以调用。extension是DB级别的函数,一个DB只需执行一次即可,新建DB需要重新执行。
不支持将Roaring Bitmap设置为Bitmap或者Dictionary。
2、 建表
BEGIN;
CREATE TABLE public.user_tags (
"tag_key" text,
"tag_value" text,
"userlist" roaringbitmap
) ;
CALL SET_TABLE_PROPERTY('public.user_tags', 'orientation', 'column');
CALL SET_TABLE_PROPERTY('public.user_tags', 'bitmap_columns', 'tag_key,tag_value');
CALL SET_TABLE_PROPERTY('public.user_tags', 'dictionary_encoding_columns', 'tag_key:auto,tag_value:auto');
COMMIT;
3、写入数据
①MC中
INSERT OVERWRITE TABLE tm_tag_userprofile_attribute_all_d_roaringbitmap
SELECT *
,(
SELECT ROW_NUMBER() OVER(PARTITION BY 1 ORDER BY phone ASC)
FROM (SELECT DISTINCT phone FROM tm_tag_userprofile_attribute_all_d WHERE data_date=20220316 ) t
WHERE t.phone=t1.phone
) as rk
FROM tm_tag_userprofile_attribute_all_d t1
WHERE data_date = 20220316
;
由于是测试,所以用户ID通过RK来代替,如果实际使用,应该通过oneid表生成唯一的ID,生成ID的目的是为了配合roaringbitmap字段的使用,因为该字段只支持INT类型的数据。
4、写入数据
①一些基础操作
创建表组:CALL HG_CREATE_TABLE_GROUP ('mdp', 40);
修改表所属表组:CALL HG_UPDATE_TABLE_SHARD_COUNT('user_tags','mdp');
创建schema:create schema mdp;
切换schema :set search_path to mdp; --切换至目标Schema
②外表向内表写入数据
SET hg_experimental_query_batch_size = 4096;
SET hg_experimental_foreign_table_executor_max_dop = 32;
INSERT INTO mdp.user_tags
SELECT tag_id
,tag_value_code
,rb_build(array_agg(rk::INT))
FROM (SELECT *FROM public.tm_tag_userprofile_attribute_all_d_roaringbitmap
WHERE RK > 40000000
) t
GROUP BY tag_id
,tag_value_code
;
5、瓶颈
①MC窄表数据量1827194847/ bitmap表数据量: 106010293
测试环境:CPU: 50core, mem: 200GB;shard=40 ,新建的table_group=mdp
正式环境:CPU: 140core, mem: 560GB;shard=40,新建的table_group=mdp
正式环境:CPU: 140core, mem: 560GB;shard=80,新建的table_group=mdp
当前配置无法一次性写入数据,报错链接超时或内存溢出
测试环境shard=40每500W 写一次 会偶尔链接超时,多次尝试可以写入
正式环境shard=40每 2000W写一次 写入正常
正式环境shard=80每 可以全量写入 写入时长573898 ms:
②多次写入数据无法正常使用,因为位运算的原因
a)单次写入RK<20000000计算
SELECT Rb_cardinality(Rb_and(t1.r, t2.r))
FROM (
SELECT Rb_and_agg(userlist) AS r
FROM user_tags
WHERE tag_key = '100001'
AND tag_value = '男' ) AS t1,
(
SELECT rb_and_agg(userlist) AS r
FROM user_tags
WHERE tag_key = '100002'
AND tag_value = '30-35岁' ) AS t2
;
6、圈选测试
正式环境圈选测试:shard=80 时间20220323
①宽表圈选 性别男&年龄30-35岁
SELECT count(DISTINCT oneid) FROM tt_sl_tag_userprofile_attribute_all_mdp_holo_d WHERE gender=3 and age_group=7;
耗时: 867ms 统计值: 1574459
②Roaring Bitmap圈选
SELECT Rb_cardinality(Rb_and(t1.r, t2.r)) FROM (
SELECT Rb_and_agg(userlist) AS r
FROM user_tags1 WHERE tag_key = ‘100001’ AND tag_value = '男' ) AS t1,
(SELECT rb_and_agg(userlist) AS r FROM user_tags1 WHERE tag_key = '100002'
AND tag_value = '30-35岁' ) AS t2;
耗时: 506ms 统计值: 1574459
7、圈选测试
正式环境圈选测试:shard=80 时间20220323
①宽表圈选 是否车主:是&品牌:WWW
SELECT count(DISTINCT a.oneid)
FROM tt_sl_tag_userprofile_attribute_all_mdp_holo_d a join
tt_sl_tag_userprofile_vehicle_rel_all_mdp_holo_d b
ON a.oneid = b.oneid
WHERE (owner=3795 and car_brand=111);
耗时: 432ms 统计值: 412298
②Roaring Bitmap圈选
SELECT Rb_cardinality(Rb_and(t1.r, t2.r)) FROM
(SELECT Rb_and_agg(userlist) AS r FROM user_tags1 WHERE tag_key = '100270'
AND tag_value = '是' ) AS t1,
(SELECT rb_and_agg(userlist) AS r FROM vehicle_tagsWHERE tag_key = '100020'
AND tag_value = 'WWW' ) AS t2
;
耗时: 309ms 统计值: 412234
8、更新写入,必须有主键
如表tb1 数据
BEGIN;CREATE TABLE tbl_1 (a int NOT NULL PRIMARY KEY,b int,c int);
INSERT INTO tbl_1 VALUES (1, 1, 1), (2, 3, 4);
1、支持更新某个字段,如通过主键a更新字段b
INSERT INTO tbl_1 (a, b)SELECT d,e FROM tbl_2
ON CONFLICT (a) DO UPDATE SET b = excluded.b;
SELECT * FROM tbl_1;
2、支持更新整行,如通过主键a更新所有列
INSERT INTO tbl_1 (a, b, c) SELECT d,e,f FROM tbl_2
ON CONFLICT (a) DO UPDATE SET (a,b,c) = ROW (excluded.*)
3、支持主键不存在追加
INSERT INTO tbl_1 VALUES (3, 2, 3)
ON CONFLICT (a) DO UPDATE SET
(a, b, c) = ROW (excluded.*);
9、覆盖写入
1、刷新外表的Schema
IMPORT FOREIGN SCHEMA holo_demo LIMIT to ( odps_region_10g ) FROM SERVER odps_server INTO public OPTIONS(if_table_exist 'update',if_unsupported_type 'error');
2、清理潜在的临时表
BEGIN ; DROP TABLE IF EXISTS public.region_new;
3、创建临时表 SET hg_experimental_enable_create_table_like_properties=on; CALL HG_CREATE_TABLE_LIKE ('public.region_new', 'select * from public.region'); COMMIT ;
4、 向临时表插入数据 INSERT INTO public.region_new SELECT * FROM public.odps_region_10g; ANALYZE public.region_new;
5、 删除旧表 BEGIN ;DROP TABLE IF EXISTS public.region;
6、临时表改名 ALTER TABLE IF EXISTS public.region_new RENAME TO region; COMMIT ;
7、授权(MDP有权限问题,需要重新授权)
①用户授权
GRANT USAGE ON SCHEMA schema_name TO "云账号/云邮箱";
GRANT SELECT ON TABLE <tablename> TO "云账号/云邮箱";
GRANT SELECT ON ALL TABLES IN SCHEMA public TO "云账号/云邮箱";
②角色授权
CREATE USER "云账号ID/云邮箱";
CREATE ROLE <rolename>;
GRANT <rolename> TO "云账号/云邮箱";
ALTER TABLE <tablename> OWNER TO <rolename>;