开放网关架构演进
作者:庄文弘(弘智)
淘宝开放平台是阿里与外部生态互联互通的重要开放途径,通过开放的产品技术把阿里经济体一系列基础服务,像水、电、煤一样输送给我们的商家、开发者、社区媒体以及其他合作伙伴,推动行业的定制、创新、进化, 并最终促成新商业文明生态圈。
开放网关诞生于07年,到现在已经有15年的历史,流量从日两千万到到现在几百亿,支撑的业务也从淘系扩展到集团内多BU。随着流量上涨,网关的技术架构也在持续升级迭代,以支撑更大的流量和更广的业务。本文把网关近些年来的技术架构变迁做梳理和总结,回顾下网关的发展过程。
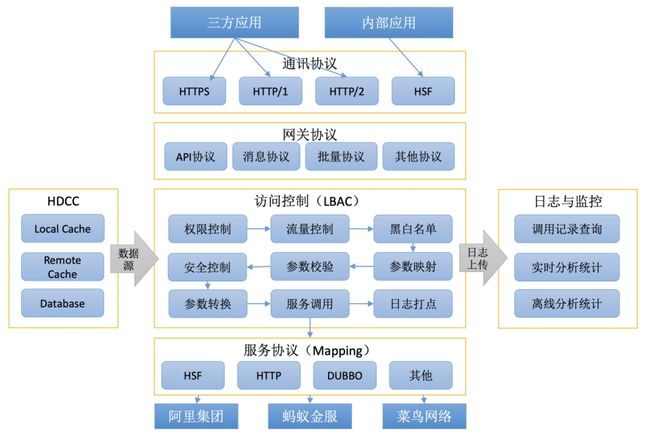
一、系统架构
先简单浏览下网关整体的技术架构。网关的主要职责在于访问控制,有权限控制、流量控制、映射打点等基础能力,外通讯协议主要为http协议,而服务协议支持HSF、http等。
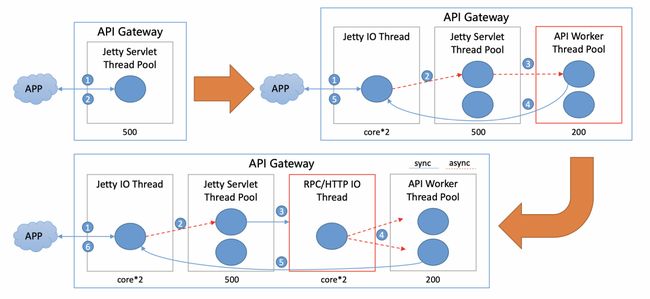
二、从线程池隔离到全异步化与多集群
作为一个业务网关,不可避免会遇到API质量参差不齐的情况,高RT的API会占用较多的线程资源。为减少API调用占用线程导的互相影响,最早网关使用了线程池分组的方式来维护,但线程池分组也带来了问题:
-
线程池分组维护成本较高。
-
分组内的api之间依旧会互相影响,而api抖动是个高概率的事件,当分组较大时候互相影响现象更明显。
为此,网关做了全异步化的升级改造。全异步化包括两部分:
-
容器层异步化:避免了容器在业务处理过程处理线程一直被占用的情况,提升容器的线程利用率。
-
请求后端异步化:通过HSF请求后端异步化调用方式,提升HSF线程池利用率,避免出现HSF线程池打满的情况。
通过升级改造,释放网络等待引起的线程占用,线程数不再成为网关的瓶颈。彻底隔离API请求之间的影响,慢API不会引起网关的不稳定。
另外网关也在业务上整体对流量做了划分,把流量区分为不稳定的流量(可能带来安全风险)、重保业务流量以及公共流量,根据不同的流量类型划分了不同的业务集群。
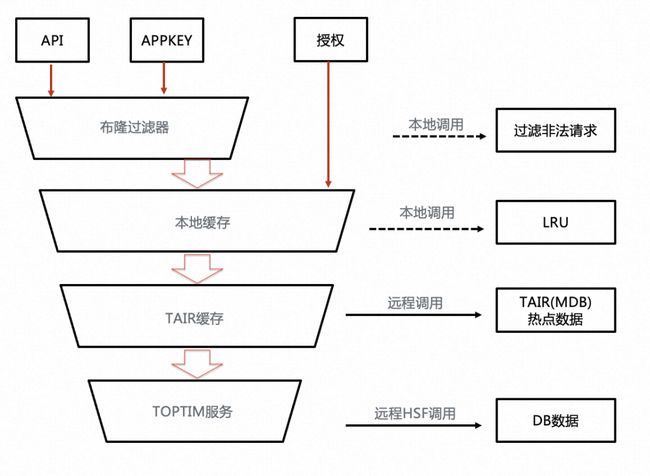
三、元数据多级缓存演变
网关请求流量一个特点是元数据较少变更,流量却非常大。为此,网关的缓存设计成多级缓存模式,布隆过滤器过滤非法请求,接着经过本地缓存与Tair缓存,最后访问到DB的流量已非常少了。
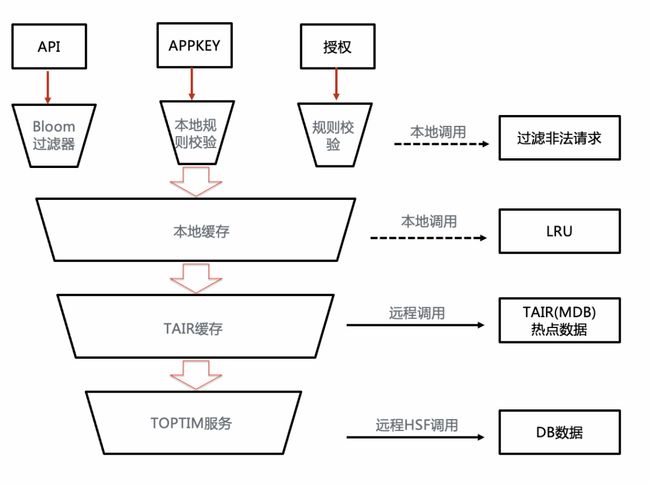
3.1 Appkey元数据存储去布隆过滤器
随着业务发展,Appkey数据量快速上涨,目前的哈希算法构建appkey bloomfilter占用60M内存,在序列化时瞬间内存byte copy会有100M左右,经常引起fgc导致业务抖动,这个对服务端和客户端都是埋雷。另外富客户端在拉到bloomfilter完成一系列构建过程中如果有异常,会直接忽略bloomfilter;这也导致前端时间用增依赖TOP去中心化包构建bloomfilter失败,从而部分流量直接击穿到元数据服务。
可以看到,布隆过滤器模式只适用于元数据没那么大的情况,否则过重模式会带来不可预期的其他问题。
由于Appkey规则固定,我们把非法请求逻辑从bloomfilter切换成规则校验模式,优化完后网关fgc抖动的现象消失。由于API元数据较少,所以API的布隆过滤器逻辑继续保留。
四、端侧异地多活
为配合菜鸟南通异地多活,网关提供了异地多活能力,支持SDK端侧灾备切换。服务商只需要使用多活client即可,SDK保证了使用的透明性。为保证南通链路链路可用性,日常保持配置小流量切换状态。当某个机房不可访问时,SDK支持从另一个机房拉取配置,同时支持把流量完全切到另一个存活机房上。

五、去中心化
随着业务发展,部分API QPS达到一二十万,这部分流量需要大量网关机器来支撑,另外大流量可能对线上集群稳定性带来一定挑战。所以,网关支持了去中心化,并对部分高QPS的API做去中心化改造。部分高流量的API在同意接入直接分流到业务服务的HSF扩展端口上,网关对HSF接口做了扩展,经过网关的一定校验逻辑后再打到业务HSF接口上。

六、报表架构升级
开放平台每天能产生几百亿的数据,而开放平台的报表是实时产生的,告警也是基于实时产生的报告人来执行。原报表架构如下:
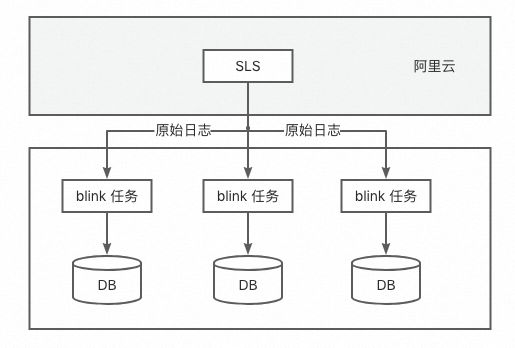
该架构会带来如下问题:
-
流量浪费,从SLS拉取日志流量需要消耗大量带宽资源,有高额的成本费用消耗;
-
SLS出口瓶颈。目前虽然是自动扩容,但之前出现过自动分裂后报表异常的情况;同时在大促期间会会出现带宽不够用的情况。
-
由于数据量大,每个任务需要计算的内容多,高峰期容易出现资源升高以及可能出现任务瓶颈。
blink理论上支持对所有的报表进行合并,多个任务变成单个任务,但这样会导致报表异常复杂,节点之间相互影响,调优或者问题定位更不可控。为了解决这个问题,对部分相关性高的报表做了合并,但是这样只能缓解问题。
所以,在此基础上我们对报表架构进一步优化,合并部分报表同时添加Blink临时聚合节点,以最细粒度的方式对blink资源做聚合,即使以api*appkey方式聚合,合并后的量级对比原始日志依旧是降低了好几个量级(每分钟千万级别压缩到3w左右)。所有blink节点不再依赖原始日志,而是依赖聚合节点,调整后的架构如下:
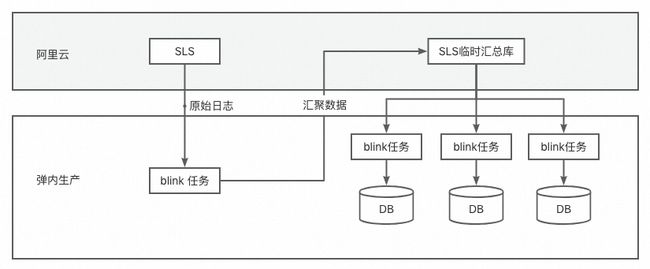
调整后架构报表产出会延迟2~3分钟,但延迟的成本在可接受范围内,同时调整后带来的收益更大:
-
减轻了每个blink子任务的压力,并且对流量消耗也可以大大减轻
-
减轻运维成本,只需要维护好上游的汇聚任务即可,下游的任务因为数据量大幅减少导致运维起来特别轻松。
七、端侧调用
为保护消费者的隐私信息,目前服务商从开放平台获取到的订单信息默认情况下无法获取获取到收货人的敏感信息。但商家在作业时查看订单收货人信息又是一个高频的场景,为了同时能解决敏感信息不被服务商获取以及同时满足商家作业的诉求,平台需要有一个方案能解决数据能直接从商家浏览器来获取消费者信息的能力。
为此,开放平台与安全部展开合作,共建了一套端侧查看消费者敏感数据的安全体系。
调用开放平台的所有接口都需要有服务商的业务身份,也就是ak/sk,但这种模式显然不适用于端直接调用模式,容易存在sk泄露的风险。为此,我们通过token模式来替代sk模式,通过isv的服务端来换取平台token。
同时,为了防止黑客通过该组件来刷数据,我们还引入霸下等风控组件来完成人机识别的操作。
整个过程通过封装成js sdk方式透出给服务商使用,降低服务商接入成本。
整体调用过程如下:

八、探索:打通阿里云售卖区与弹内的网络链路
目前与开放网关互通的服务商服务有很大一部分部署在聚石塔上,为解决服务商的安全以及网络带宽问题,开放网关与聚石塔尝试打磨一整套方案,以奇门网关(开放网关访问服务商链路)为例,服务商仅在聚石塔AppEngine上部署,并开启对奇门组件即可,服务接口无需暴露到公网,整个访问链路走内网通道,节省服务商网络带宽同时提升网络访问链路的整体稳定性。
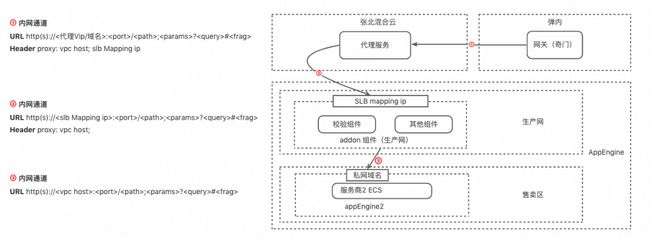
九、总结与展望
过去网关在保持架构简单的基础上增加了安全、隐私保护等能力,而架构的演进也是朝着简单化发展,节点精简却带来了更大的收益。在云化的时代,我们也跟会向"云"靠拢,与聚石塔的基建、产品打通,赋能塔内服务商同时降低服务商成本,同时更好地服务业务。