文本三剑客之sed编辑器
sed
- 一、sed简介
-
- 1.1 什么是sed?
- 1.2 sed原理
- 1.3 sed核心功能
- 二、sed命令格式详解
-
- 2.1 命令格式
- 2.2 常用选项
- 2.3 sed脚本语法
-
- 2.3.1 基本语法结构
- 2.3.2 地址部分-----指定匹配范围
- 2.3.3 命令部分-----要执行的命令
- 三、sed查找替换
-
- 3.1 基本语法
- 3.2 分组+后向引用
- 3.3 变量调用
- 四、sed练习
一、sed简介
1.1 什么是sed?
Sed是一个强大的文本处理工具,其名称是Stream Editor(流编辑器)的缩写。它被设计用于根据用户定义的规则对文本进行逐行处理和转换。
Sed通过从输入流中逐行读取文本,并根据用户指定的命令来对每一行进行处理
1.2 sed原理
sed的工作原理是逐行读取输入文本,并根据用户指定的命令对每一行进行处理,通过模式匹配和命令执行来实现文本的处理和转换。
Input Text Pattern Space Output Text
------------ -------------- -------------
| Line 1 | -----> | Pattern | -----> | |
| Line 2 | | Space | | Modified |
| Line 3 | | | | Text |
| ... | | | | |
------------ -------------- -------------
“Input Text” 是输入的文本,由多行组成,每一行都会依次进入 “Pattern Space”;
“Pattern Space”是 sed 使用的缓冲区。
sed 会根据用户指定的模式(例如,文本匹配规则)进行模式匹配,然后执行相关的命令来处理当前的行。
命令执行完成后,如果有修改操作,那么 “Modified Text” 将会保存修改后的文本,最后输出作为 Sed 的结果。
1.3 sed核心功能
sed的核心功能:增删改查(可配合正则表达式)
查: p
删: d
改: s(字符串替换)、c(整行替换)、y(对应字符进行替换,效果类似tr命令)
增: i(在行前插入内容)、a(在行后添加内容)、r(在行后读入文件的内容)
复制粘贴:H(复制)、d(删除)、G(粘贴到指定行下方)
二、sed命令格式详解
2.1 命令格式
sed [option]... 'script;script;...' [input file...]
选项 自身脚本语法 支持标准输入管道
2.2 常用选项
| 选项 | 功能 |
|---|---|
| -n | 不输出模式空间内容到屏幕,即不自动打印 |
| -e | 多点编辑 |
| -f FILE | 从指定文件中读取编辑脚本 |
| -r或者-E | 使用扩展正则表达式 |
| -i.bak | 备份文件并原处编辑 |
| -s | 将多个文件视为独立文件,而不是单个连续的长文件流 |
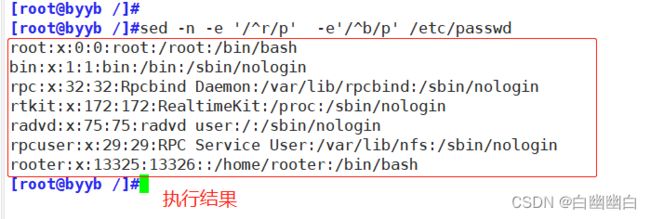
sed -n -e '/^r/p' -e'/^b/p' /etc/passwd
#把passwd文件中r为首和b为首的内容打印出来
2.3 sed脚本语法
2.3.1 基本语法结构
[address]<command>[options]
匹配范围 命令 选项
address 表示要匹配的行范围,可以是单个行号、行号范围或正则表达式。
command 表示要在匹配的行上执行的命令。
options 是一些可选的参数,用于修改命令的行为。
2.3.2 地址部分-----指定匹配范围
在 sed 脚本中,地址部分用于指定要匹配的行范围。
地址部分可以是单个行号、行号范围或正则表达式。
1)不指定范围
地址部分是可选的,如果不指定地址,Sed 将对所有行都执行命令
2)单个行号
#基本格式#
sed 'n' file #处理第n行的内容,n为具体正整数
#举个例子#
sed '2d' file #删除文件中的第 2 行。
3)行号范围
#基本格式#
sed 'x,y' file #处理x行到y行的内容,x和y为正整数且x
sed 'x,+y' file #处理x行和x行后y行的内容
#举个例子#
sed '2,5d' file #删除文件中第2行到第5行的内容
sed '2,+5d' file #删除文件中第2行到第7行的内容
4) 使用正则表达式匹配范围
#基本格式#
sed '/pattern/' file #根据正则表达式来匹配目标行
sed '/pattern1/,/pattern2/' file
#匹配正则表达式1和正则表达式2间的行,并根据command进行处理
sed 'x,/pattern/' file #x行到正则表达式匹配到的行之间的内容
sed '/pattern/,y' file #正则表达式匹配到的行到y行之间的内容
#举个例子#
sed -n '/^root/,/^byyd/p' test

5)步进
'~' 符号
#怎么表示奇数行?
sed -n '1~2p' #从第一行开始,步进为2打印,即1 3 5 7。。。
sed '0~2d'
#怎么表示偶数行?
sed -n '2~2p' #从第二行开始,步进为2打印,即2 4 6 8。。。
sed '1~2d'
6)最后一行和倒序匹配
`$` 符号用于表示最后一行
sed -n '$' file #对最后一行进行操作
sed -n '$,$-n' file #倒数第n行到最后一行
#补充知识
! 表示逻辑非操作,表示匹配不到指定的行使用 `
&& 逻辑与操作
|| 逻辑或操作
2.3.3 命令部分-----要执行的命令
| 命令 | 功能 |
|---|---|
| p | 将匹配到的行打印输出 |
| Ip | 忽略大小写输出 |
| d | 删除模式空间匹配的行,并立即启用下一轮循环 |
| a\ | 将指定的文本添加到匹配到的行后面 |
| i\ | 将指定的文本插入到匹配到的行前面 |
| c\ | 替换行为单行或多行文本 |
| w file | 保存模式匹配的行至指定文件 |
| r file | 读取指定文件的文本至模式空间中匹配到的行后 |
| = | 为模式空间中的行打印行号 |
| ! | 模式空间中匹配行取反处理 |
| q | 结束或退出sed |
面试题
1.用sed打印到第三行
sed -n '1,3p' 文件
sed '3q' 文件 #q是自动退出,打印到第三行就退出
2.打印从第三行开始,继续往后打印三行
sed -n '3,+3p'
特殊字符和转义序列
&: 表示与模式匹配的整个文本。
\1, \2, ...: 表示与模式中括号内的子表达式匹配的文本。
\n: 表示换行符。
\t: 表示制表符。
\\: 表示反斜杠。
三、sed查找替换
3.1 基本语法
sed 's/要查找的内容/替换的内容/修饰符' 文件名
# '/'为分隔符,可以用'@' 或者 '#'
# 要查找的内容可以用正则表达式
# 替换的内容无法用正则表达式
# 修饰符 #
g 行内全局替换
p 显示替换成功的行
w /PATH/FILE 将替换成功的行保存至文件中
I,i 忽略大小写
sed -i 's/r..t/&er/g' /etc/passwd
# &代指前面找到的内容
3.2 分组+后向引用
分组(Grouping)
通过将模式的一部分放入一个分组中,可以将这部分模式视为一个单元,后续可以通过引用该分组在替换中使用。
后向引用(Backreference)
在替换中使用前面定义的分组的内容。在sed命令中,可以使用 \数字的形式引用分组,其中数字表示分组的顺序。
在替换中使用\1来引用第一个分组的内容。如果有多个分组,可以使用\2、\3等来引用后续分组的内容。
#举个例子#
echo 123abcxyz | sed -nr 's/(123)(abc)(xyz)/\1/p'
# -n 关闭自动打印 -r 使用扩展正则表达式
# 123分成1组 abc分组第二组 xyz分成第三组
# \1/p 表示打印第一组

示例一:仅显示本机IP地址
ifconfig ens33 | sed -nr 's/.*inet (.*) netmask.*/\1/p'

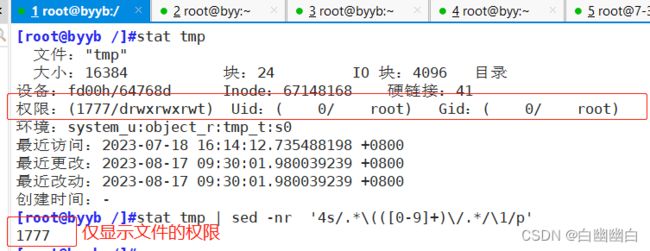
示例二:仅显示tmp文件的权限
stat tmp | sed -nr '4s/.*\(([0-9]+)\/.*/\1/p'
# ( 和 \ 需要转译
3.3 变量调用
sed允许使用变量来替代文本中的特定部分。
需要先定义变量。
name=root #定义变量
sed -nr '/'$name'/p' /etc/passwd #打印出包含root的内容
或者
sed -nr /"$name"/p /etc/passwd

四、sed练习
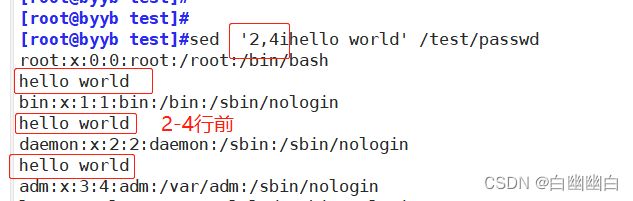
示例一:增加内容( a i c )
都是临时添加
sed '2,4ihello world' /test/passwd #在第2-4行前面添加
sed '2ahello wold\n' /test/passwd #在第二行后面添加并回车

sed '$ahello' /test/passwd #最后一行后

sed '/stu0/a hello world;3p;3i shell' /test/passwd
#a后面的内容都会被视为添加内容

示例二:多点编辑
sed -n -e '1p' -e '3p' /test/passwd

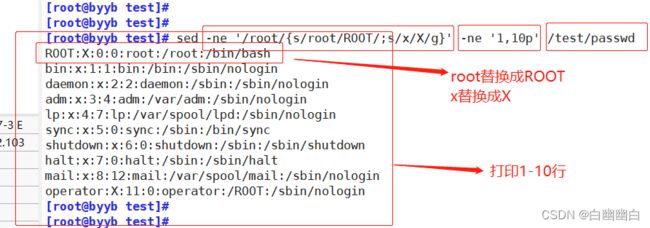
示例三:分组操作
sed -ne '/root/{s/root/ROOT/;s/x/X/g}' -ne '1,10p' /test/passwd
#/root所在行/ {将所在行的root替换成ROOT x替换成X} 打印1-10行
示例四:搜索替换
#1-5行的开头加上#
sed -n '1,5s/^/#/gp' /test/passwd
#g为全局替换

示例五:删除
sed '/nologin/d' /test/passwd #删除包含nologin的

示例六:仅提取日志文件中的IP地址和时间戳
cat log | sed -nr 's/(.*) - - \[(.*) +.*\] .*/\1 \2/p'
