SORT:基于检测的目标跟踪的鼻祖
本文来自公众号“AI大道理”
——————
SORT是一种多目标跟踪的经典算法,整个算法是一些常规技术的简单组合,却达到了非常好的效果。
Sort算法的核心是匈牙利匹配算法和卡尔曼滤波算法。
![]()
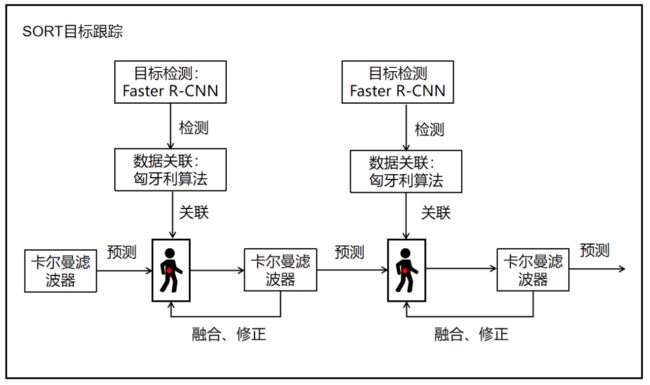
1、SORT简介
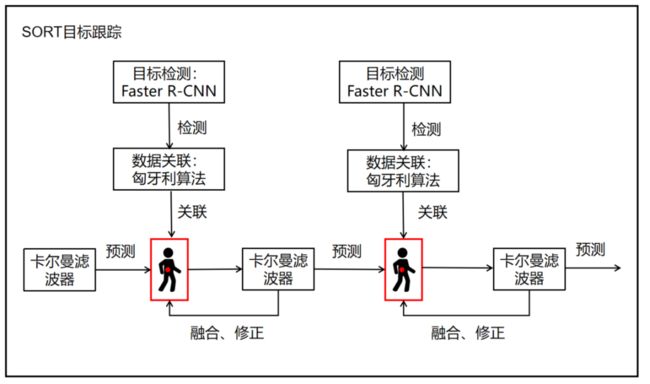
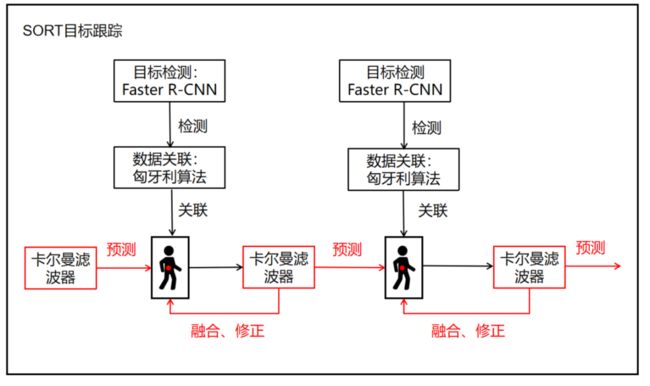
SORT(Simple Online and Realtime Tracking)是一种简单、在线和实时的目标跟踪算法,它的设计目标是在计算资源有限的情况下实现高效的目标跟踪。
SORT算法的核心思想是通过联合目标检测和运动预测来进行目标跟踪。
算法首先使用目标检测器(Faster R-CNN)在每一帧中检测出目标物体的位置和边界框。然后,通过卡尔曼滤波器来对目标的运动进行建模和预测。卡尔曼滤波器结合了目标的当前状态和运动模型,可以估计目标在下一帧中的位置和速度。
SORT算法还引入了一种基于匈牙利算法的数据关联方法,用于在当前帧和先前帧之间建立目标的关联关系。该方法通过最小化关联成本来匹配当前帧中的目标和先前帧中的已跟踪目标,从而确定目标的身份和轨迹。
![]()
2、SORT的目标检测算法
单目标跟踪的初始框是人为框定进行初始化的。
多目标跟踪中基于检测器的跟踪,检测器检测出来的框就是初始框,从而避免了人工初始化。
基于目标检测的基础,SORT利用了faster-RCNN检测框架。
faster-RCNN 是一个由两个阶段组成的端到端框架。
第一阶段提取特征并提供候选区域区域,第二阶段在提出的区域中对目标进行分类。
该框架的优点是参数在两个阶段之间共享,从而创建了用于检测的有效框架。此外,网络架构本身可以交换到任何能够快速试验不同架构以提高检测性能的设计中。
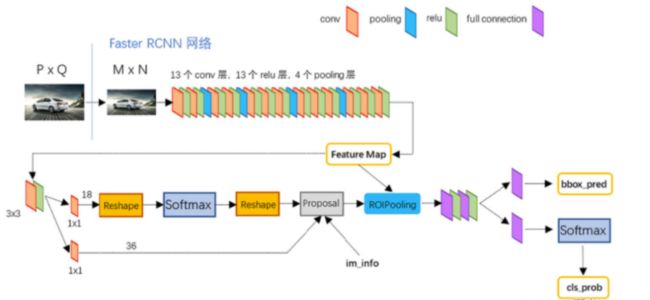
Faster-RCNN算法流程:
(1)conv layers:即特征提取网络,用于提取特征。通过一组conv+relu+pooling层来提取图像的feature maps,用于后续的RPN层和取proposal。
(2)RPN(Region Proposal Network):即区域候选网络,该网络替代了之前RCNN版本的Selective Search,用于生成候选框。这里任务有两部分,一个是分类:判断所有预设anchor是属于positive还是negative(即anchor内是否有目标,二分类);还有一个bounding box regression:修正anchors得到较为准确的proposals。因此,RPN网络相当于提前做了一部分检测,即判断是否有目标(具体什么类别这里不判),以及修正anchor使框的更准一些。
(3)RoI Pooling即兴趣域池化(SPP net中的空间金字塔池化):用于收集RPN生成的proposals(每个框的坐标),并从(1)中的feature maps中提取出来(从对应位置扣出来),生成proposals feature maps送入后续全连接层继续做分类(具体是哪一类别)和回归。
(4)Classification and Regression:利用proposals feature maps计算出具体类别,同时再做一次bounding box regression获得检测框最终的精确位置。
![]()
3、SORT的数据关联
数据关联其实就是一个沿着时间轴,将来自同一个物体的不同时刻的信号串联起来的过程。
数据关联通常在状态估计之前进行,只有获得准确的数据关联处理结果,才能保证后续处理的正确性。
SORT在将检测分配给现有目标时,通过预测每个目标在当前帧中的新位置来估计每个目标的边界框几何形状。然后,分配成本矩阵被计算为每个检测和来自现有目标的所有预测边界框之间的交集-并集(IOU)距离。使用匈牙利算法最优地解决分配问题。此外,至少当探测到的目标重叠小于IOUmin时,施加IOU来拒绝分配。

匈牙利算法:
依次进行数据关联是局部最优解,并不能代表全局最优解。
而匈牙利算法则在追求全局最优,是一种在多项式时间内求解分配问题的组合优化算法。
多目标跟踪数据关联问题可以转化为有权二分图最小权匹配问题,匈牙利算法就是解决数据关联问题的图算法。
匈牙利算法(Hungarian Algorithm),也称为Kuhn-Munkres算法,是一种解决指派问题(Assignment problem)的优化算法。指派问题是在给定的任务和资源之间建立最佳的一对一分配关系的问题。
具体来说,匈牙利算法解决的是一个二维的代价矩阵,其中每个元素表示将一个任务分配给一个资源的成本或代价。算法的目标是找到一种分配方式,使得总成本最小。
匈牙利算法的基本思想是通过不断寻找增广路径来找到最佳的分配方式。
匈牙利算法步骤:
步骤1:代价矩阵德每一行减去改行的最小值。
步骤2:代价矩阵德每一列减去该列的最小值。
步骤3:用尽量少的线覆盖矩阵中所有的0,判断线的数量是否小于n(矩阵行数列数)
步骤4:线的数量小于n,则需要继续减,未被线覆盖的行或者列继续减掉未被覆盖的最小值,被线覆盖一次的不参与减,被线覆盖两次的反而要加这个最小值。
步骤5:重复上面步骤4,直到找到线的个数等于n,则得到最终的匹配方案。
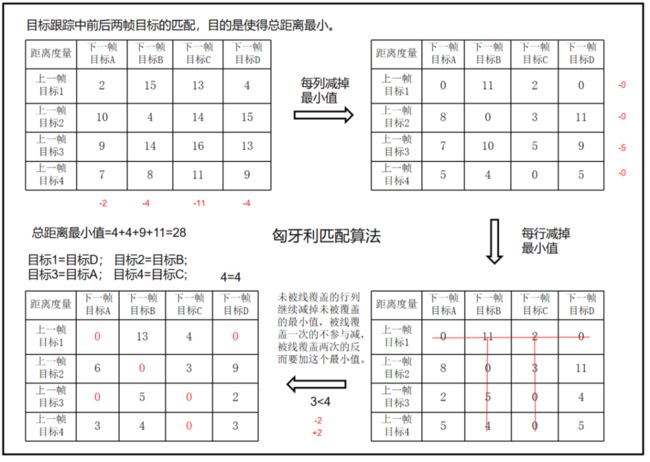
最后需要划 4 条线才能覆盖住矩阵中所有的 0 元素,迭代终止,根据矩阵中 0 元素的位置很容易得到最终的匹配关系:目标1→目标D,目标2→目标B,目标3→目标A,目标4→目标C。
这个匹配满足构成的二分图上的匹配边总权重最小,即总的匹配距离最小,代价最低。
若目标和下一帧目标个数不一致,则需要补0进行匈牙利算法。
![]()
4、SORT的运动模型
SORT描述一个对象模型,用于将目标的身份传播到下一帧的表示和运动模型。SORT用独立于其他物体和摄像机运动的线性恒速模型来近似每个物体的帧间位移。
每个目标的状态被建模为:
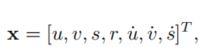
其中 u 和 v 代表目标中心的水平和垂直像素位置,而比例 s 和 r 分别代表目标边界框的比例(面积)和纵横比。纵横比被认为是常数。当检测与目标相关联时,检测到的边界框用于更新目标状态,其中速度分量经由卡尔曼滤波器框架最优地求解。如果没有检测与目标相关联,则简单地预测其状态,而不使用线速度模型进行校正。
SORT中将卡尔曼滤波器用于检测框运动的预测,描述一个检测框需要以下四个状态,即:
-
检测框中心的横坐标。
-
检测框中心的纵坐标。
-
检测框的大小(论文中叫做scale或者area)。
-
长宽比。
以上四个状态可以描述一个检测框的基本信息,但是不能完全描述一个状态的运动状态信息,所以需要引入上述的状态的变化量信息(可以看作变化速度)来进行运动状态信息的描述。
由于SORT假设一个物体在不同帧中检测框的长宽比不变,是个常数,所以变化量只考虑上面的前三点,即
-
检测框中心的横坐标的变化速度。
-
检测框中心的纵坐标的变化速度。
-
检测框的大小的变化速度。
所以SORT中共使用了7个参数,用来描述检测框的状态。
![]()
5、SORT的卡尔曼滤波
目标跟踪中,在数据关联后往往要进行卡尔曼滤波。
数据关联算法得到了每个目标的观测数据。
卡尔曼滤波使用关联的观测数据来估计目标的状态,并预测目标的未来位置和速度等信息。
卡尔曼滤波主要包括两个步骤:预测步骤和更新步骤。
-
预测步骤(Prediction):根据系统的动态模型,使用上一时刻的状态估计和控制输入,预测系统的下一时刻状态和状态协方差。
-
更新步骤(Update):通过比较系统的观测值和预测值,结合观测噪声和系统模型的不确定性,更新系统的状态估计和协方差。
卡尔曼滤波通过递归的方式进行状态估计,每个时刻的状态估计都会考虑前一时刻的估计结果和当前的观测值。
卡尔曼滤波适用于线性高斯系统。
卡尔曼滤波使用上一次的最优结果预测当前值,使用观测结果修正当前预测值,得到当前最优结果。


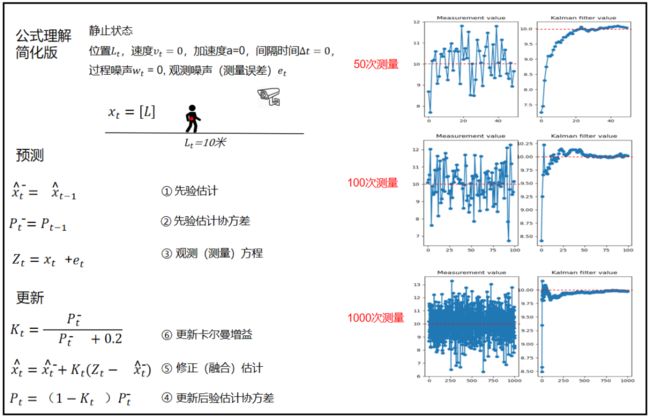
测量十次的时候卡尔曼滤波效果还不是很明显,当测量50次100次效果就出来了,在一定次数后的值明显不会偏离真实值很远。
这就是卡尔曼滤波达到的效果。
![]()
6、SORT的航迹标识
当对象进入和离开图像时,需要相应地创建或销毁唯一的身份。
为了创建跟踪器,SORT认为任何重叠小于IOUmin 的检测都表示存在未被跟踪的对象。
跟踪器使用速度设置为零的边界框的几何图形进行初始化。
由于在这一点上没有观察到速度,速度分量的协方差用大值初始化,反映了这种不确定性。
另外,新的跟踪器然后经历一个试用期,在此期间目标需要与检测相关联,以积累足够的证据,从而防止跟踪的误报。
如果对于 TLost 帧没有检测到轨道,则轨道被终止。
这防止了在没有来自检测器的校正的情况下由长时间的预测引起的跟踪器数量和定位误差的无限增长。
在所有实验中,TLost 设置为 1 有两个原因。首先,恒定速度模型是真实动态的不良预测器,其次,SORT主要关心帧到帧的跟踪,其中对象的重新识别超出了本工作的范围,如果一个物体再次出现,跟踪将隐含地以新的身份恢复。

![]()
7、总结
SORT是一个比较简单的算法,用FrRCNN做探测,卡尔曼滤波和匈牙利算法做跟踪。
缺点:
-
线性恒速运动模型可能并不精确,未考虑相机的非线性运动。
-
未考虑同一目标再次出现的重识别(Re-ID)问题。

——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

—————————————————————
投稿吧 | 留言吧