Redis主从复制搭建
Redis主从复制搭建
Redis虽然拥有非常高的性能,但是在实际的生产环境中,使用单机模式还是会产生不少问题的,比如说容易出现
单机故障,容量瓶颈,以及QPS瓶颈等问题。通常环境下,主从复制、哨兵模式、Redis Cluster是3种比较常见
的解决方案,本文将通过实例演示如何搭建Redis主从复制环境,并对其原理进行分析。
1、搭建主从复制
1、创建3个目录redis8000,redis8001,redis8002目录下。
将默认配置文件redis.conf拷贝到redis8000下,将redis8000指定为主机,修改以下参数:
bind 0.0.0.0
port 8000
pidfile /var/run/redis_8000.pid
logfile "redis8000.log"
dbfilename dump8000.rdb
dir /home/hydra/files/redis/slave/redis8000/
requirepass 123456
daemonize yes
masterauth 123456
2、将修改后的redis.conf文件拷贝到redis8001和redis8002目录下,然后进行修改:
bind 0.0.0.0
port 8001
pidfile /var/run/redis_8001.pid
logfile "redis8001.log"
dbfilename dump8001.rdb
dir /home/hydra/files/redis/slave/redis8001/
# replicaof 127.0.0.1 8000
slaveof 127.0.0.1 8000
requirepass 123456
masterauth 123456
# 从机开启aof持久化
appendonly yes
daemonize yes
bind 0.0.0.0
port 8002
pidfile /var/run/redis_8002.pid
logfile "redis8002.log"
dbfilename dump8002.rdb
dir /home/hydra/files/redis/slave/redis8002/
# replicaof 127.0.0.1 8000
slaveof 127.0.0.1 8000
requirepass 123456
masterauth 123456
# 从机开启aof持久化
appendonly yes
daemonize yes
3、分别启动3个redis实例
./redis-5.0.4/src/redis-server ./slave/redis8000/redis.conf
./redis-5.0.4/src/redis-server ./slave/redis8001/redis.conf
./redis-5.0.4/src/redis-server ./slave/redis8002/redis.conf
查看进程,启动成功:

4、通过redis客户端连接主机redis8000:
./redis-5.0.4/src/redis-cli -p 8000 -a 123456
登录成功后,使用指令查看主从架构:
info replication
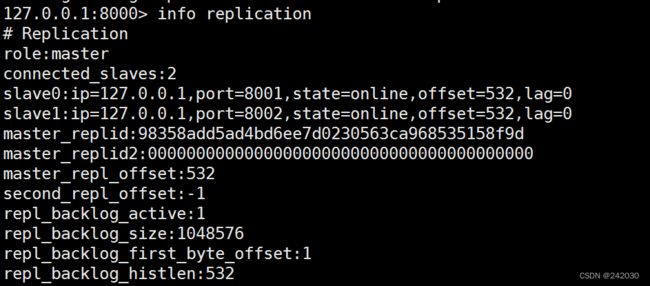
可以看出,主机8000拥有两台从机,从机8001和8002连接成功。
5、通过redis客户端连接从机redis80001,同样通过指令查看主从状态:

可以看出8001的角色为slave从机,并且可以查看主机8001的相关信息。
6、此外,还可以通过指令的模式动态分配主从。复制一个redis8000的配置文件至redis8003下,修改端口为
8003,其他配置不做改动。
bind 0.0.0.0
port 8003
pidfile /var/run/redis_8003.pid
logfile "redis8003.log"
dbfilename dump8003.rdb
dir /home/hydra/files/redis/slave/redis8003/
requirepass 123456
daemonize yes
使用redis客户端登录8003后,输入指令指定主机:
slaveof 127.0.0.1 8000
动态指定主机后,如果主机设置了密码,还需要通过指令配置主机密码:
config set masterauth 123456
配置完成后,查看8003从机状态:
查看8000主机状态:

新添加的从机8003已经被添加到8000的从机当中。
需要注意的是,使用命令动态指定的主从状态,在从机重启后会失效。
首先使用kill命令杀死8003进程,然后查看主从状态:

可以发现,现在从机只剩下两台,为8001和8002。
然后重启8003并再次查看状态:

仍然为8001和8002两台从机,证明了指令指定主从在重启后会失效。
7、进行读写测试,首先测试主机,读写均能正常:

测试从机,发现可以正常读数据,但是写数据失败:

这是因为在主从复制的架构下,只有主机能够写数据,从机为只读模式,这是在配置文件中指定的。在Redis2.6版
本以后,默认从机为只读模式:
replica-read-only yes
需要注意这里不能将这个配置改为no,因为主机不会监听到从机的写数据事件,因而造成主从数据的不一致。
二、全量复制
用于初次复制或其它无法进行部分复制的情况,将主节点中的所有数据都发送给从节点。
当数据量过大的时候,会造成很大的网络开销,流程如下:

1、从机发送:
psync ? -1
这里的 “?” 是因为从机暂时不知道主机的runId, -1代表全量复制
2、主机发送指令,把自己的runid和offset传给从机:
fullresync{runid,offset}
可以通过命令查看这两个参数:
#可以查看runid
info server
#可以查看offset
info replication
从机之后会上报自己的偏移量offset给主机,当主机的offset和从机的offset不一样时,说明数据不一致。
3、从机保存主机数据:
save master info
4、主机执行bgsave,全量复制会触发rdb持久化。
bgsave
主机在生成rdb文件时,可能会有新的数据写入。这时redis把新写入的数据写入一个缓冲区repl_back_buffer,默
认大小1M。可以通过repl-backlog-size设置缓冲区大小
5、主机发送rdb给从机:
send rdb
6、主机发送缓冲区数据给从机:
send buffer
7、从机把从机本身上的数据清空:
flush old data
8、从机加载主机发送过来的rdb和buffer数据:
load rdb&buffer
在全量复制中,消耗的时间包括:
-
执行bgsave进行持久化的时间
-
rdb文件网络传输时间
-
从节点请求请求数据时间
-
从机加载rdb的时间
-
如果从节点开启了aof持久化,可能进行aof重写的时间
三、部分复制
部分复制主要是Redis针对全量复制过高的开销进行的一种优化措施。Redis 希望能够在主机出现抖动或连接断开
的时候,可以通过部分复制机制将损失降低到最低。

具体流程如下:
1、出现网络抖动,连接断开 connection lost
2、主机继续写复制缓冲区repl_back_buffer
3、从机继续尝试连接主机
4、从机slave 会把自己当前 runid 和偏移量传输给主机 master,并且执行 pysnc 命令同步
5、如果 master 发现偏移量是在缓冲区的范围内,就会返回 continue 命令
6、同步了 offset 的部分数据,所以部分复制的基础就是偏移量 offset。
那么在正常的情况下,Redis是如何决定全量复制还是部分复制的呢?从机将自己的offset发送给主机后,主机
根据offset和缓冲区大小决定能否执行部分复制:
-
如果offset偏移量之后的数据,仍然都在复制积压缓冲区里,则执行部分复制
-
如果offset偏移量之后的数据已不在复制积压缓冲区中,则执行全量复制
四、主从复制架构缺点
1、由于所有的写操作都是先在主机上操作,然后同步更新到从机上,所以同步过程有一定的延迟,当系统很繁忙
的时候,延迟问题会更加严重。从机数量增加时,会使这个问题更加严重。
2、当主机宕机之后,将不能进行写操作,需要手动将从机升级为主机,从机需要重新指定主机。
手动在一台从机上执行下面命令,将它升级为主机:
slave of no one
再在其他从机上执行slave of指令,将自身变成新主机的从机:
slave of 192.168.0.1 port
可以看出这种情况下,当主机宕机后,后续的修复流程由人工操作,非常麻烦,因此在这种情况下Redis引入了哨
兵模式,来完成主机宕机后的自动故障转移。