时间序列(七): 高冷贵族: 隐马尔可夫模型
目录
- 高冷贵族: 隐马尔可夫模型
- 引言
- 例子
- 描述模型
- 基本概念*
- 定义
- 基本假设
- 基本问题
- 前向,后向算法
- 前向算法
- 后向算法
- 举例计算
- 学习问题
- 已知观测序列及隐序列
- 已知观测序列
- 预测问题
- Viterbi 算法
- 举例计算
- 升华
- 参考文献
高冷贵族: 隐马尔可夫模型
引言
大家都用过Siri,Cortana之类的语音助手吧? 当你对着手机说出'我的女朋友温柔吗?',Siri 或Cortana就会根据你说的这句话翻译成一段文字,然后再作应答. 先不管应答部分, 你可曾想过: Siri是如何将你说的话翻译成一段文字的?嗯,猜对了, 这里就用到了隐马尔可夫模型(Hiden Markov Model, HMM).
例子
假设你有三个女朋友(嘿~,现实不可以,想想总可以吧~,/躲拖鞋…), 你每周末只能选择陪其中一位(为了世界和平…). 而作为程序员的你,也没有什么情调,只会与女朋友做二种事情: 吃饭,看电影, 而因为工作繁忙,你每周也只能做其中一件事,三位美丽的女士也很理解,体谅你,也都很配合,很高兴.
那么问题来了, 你是如何选择周末去陪哪个女朋友呢? 三位女士都很可爱,你不想冷落每一个人,但第一个女朋友(记为A女朋友)有点聒噪,因此你会稍微少去一点她那里. 第二,第三个女朋友去都比较安静(分别记为B,C). 于是,你在心里默默地(或者是潜意识地)定下了去陪三位女朋友的概率:
| 女朋友 | A | B | C |
|---|---|---|---|
| 概率 | 0.2 | 0.4 | 0.4 |
比如,陪A女朋友的概率是0.2,可简单的理解为十次大约有二次会去陪她. 然而这只是你刚开始考虑的事,因为当你周末陪女朋友结束之后,你会根据本次的约会体验选择下一周要陪伴的女朋友.之前初始的'选择'概率就不再起作用了.
那约会结束后你是如何选择下一周的女士呢? 因为三位女士的性格比较稳定,因此每次的体验都会差不多,于是你的内心又有了一个下周去哪个女朋友的概率了:
| 本周陪伴\下周陪伴 | A | B | C |
|---|---|---|---|
| A | 0.5 | 0.2 | 0.3 |
| B | 0.3 | 0.5 | 0.2 |
| C | 0.2 | 0.3 | 0.5 |
什么意思呢? 比如你本周陪伴A了,那下周你继续陪A的概率是0.5, 而下周去陪B的概率则为0.2, 而去陪伴C的为0.3.
还没完~, 因为每个女朋友的喜好不一样,因此你们在一起做的事也不一样: A比较随意,吃饭,看电影都可没,没差; B比较文艺,则喜欢看电影会稍微多一些; C 则是个吃货,比较喜欢吃饭,但也会看电影.于是,你的心里又有谱了:
| 女朋友 | 吃饭 | 看电影 |
|---|---|---|
| A | 0.5 | 0.5 |
| B | 0.4 | 0.6 |
| C | 0.7 | 0.3 |
也就是说,比如对于C来说, 你们在一起呢,0.7的概率会去吃饭,也即十次大约有7次会去吃饭, 而有约三次会去看电影.
有一天,你在朋友圈发了个状态: 吃,吃,看,看,吃.
这引起了你朋友圈的三个人的兴趣:
你老妈, 你老妈对你的情况比较了解,她知道你对这三位女朋友的想法(即知道上面三张表), 她现在比较感兴趣的是,下周她儿子去干嘛(也比较八卦~).
你表姐, 你表姐因为住在另一个城市,所以沟通比较少,因而你对三位女朋友的感觉(上面三张表)她并不知道,只知道你同时和三位女生谈恋爱,所以她现在想根据你的发出的状态判断出你对三位女生的感觉(上面三张表).
你同事, 你同事也是你的基友,因此对你的事比较了解,没事你会跟说说三个女生在你心里的感受(上面三张表),但为防止他八卦,你并没有把每周去哪位女朋友那里告诉他.这下可勾起了他的好奇心,于是想根据你的状态猜出你每周都是陪伴的谁.
好了,隐马尔可夫模型讲完了~
什么? Are you kidding me ?
没有,真的,这就是马尔可夫模型. 下面个图来表示下.
描述模型

这张图表示的就是你这五周以来与女朋友们的互动情况. 在隐马尔可夫模型中, 粉色圈圈那一行代表的是女朋友的情况,从微信状态的角度,它是一个隐藏在后面的状态(没有发在状态里啊~). 因此称为(隐)状态序列(这就是HMM中'隐'字的意思),而且这个状态链呢么是一个马尔可夫模型或叫做马尔可夫链. 什么是马尔可夫链? 就是说当前状态只决定于前一个状态. 在本本例中,你本周去哪个女朋友那里,完全由你上周在哪个女朋友那里来决定. 而绿色框框则被称为观测序列, 即别人从朋友圈能看到你什么都做了什么.
上面的三张表,即是描述模型的变量,第一张表我们称为初始状态向量,第二张表称为转移概率矩阵,第三张表则是观测概率矩阵.
而后面三个人的想要知道的东西就是HMM的三个基本问题:概率计算问题,学习问题,以及预测问题.
(三个问题的求解方式在后面~~~)
HMM 应用非常广泛,特别是在自然语言处理,语音识别,信号处理,生物序列分析(DNA, 蛋白质等)等等大放异彩.HMM是时间序列模型,处理时间序列是其本职工作.
PS: 一如既往, 只做了解的,读到这里就可停下了,想深入一些的,请继续~
基本概念*
HMM是一个时序概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程.具体请看上图.
现在咱们一般化地讨论一下, 设:
(y1,y2,…,yn),(x1,x2,…,xn)(y1,y2,…,yn),(x1,x2,…,xn)
分别为状态序列与观测序列, 因状态序列是一个马尔可夫链,故 所有变量的联合概率分布为:
P(x1,y1,…,xn,yn)=P(y1)P(x1|y1)Πni=2P(yi|yi−1)P(xi|yi)P(x1,y1,…,xn,yn)=P(y1)P(x1|y1)Πi=2nP(yi|yi−1)P(xi|yi)
欲得到联合概率分布,其需要右边三个部分,P(y1)P(x1|y1)P(y1)P(x1|y1) 为初始条件; P(yi|yi−1)P(yi|yi−1) 为转移条件; P(xi|yi)P(xi|yi) 则为观测条件. 因此,
设:
Q 是所有可能的状态集合, V 是所有可能的观测集合.
Q={q1,q2,…,qN},V={v1,v2,…,vM}Q={q1,q2,…,qN},V={v1,v2,…,vM}
其中,N 是所有可能的状态数, M 是所有可能的观测数.
I 是长度为T 的状态序列, O 是对应的观测序列:
I={i1,i2,…,iT}O=(o1,o2,…,oT)I={i1,i2,…,iT}O=(o1,o2,…,oT)
A 是状态转移概率矩阵:
A=[aij]NXNA=[aij]NXN
其中,
aij=P(ii+1=qj|it=qi),i=1,2,…,N,j=1,2,…,Naij=P(ii+1=qj|it=qi),i=1,2,…,N,j=1,2,…,N
是在 t 时刻 处于状态 qi 的条件下在 时间 t+1 转移到状态 qj 的概率.
B 是观测概率矩阵
B[bj(k)]NXMB[bj(k)]NXM
其中
bj(k)=P(ot=vk|it=qj),k=1,2,…,M,j=1,2,…,Nbj(k)=P(ot=vk|it=qj),k=1,2,…,M,j=1,2,…,N
是在 t 时刻 处于状态 q_j 的条件下生成观测数 vk 的概率.
ππ 是初始状态概率向量
π=(πi)π=(πi)
其中
πi=P(i1=qi),i=1,2,…,Nπi=P(i1=qi),i=1,2,…,N
是时刻 t = 1处于状态 qi 概率.
有了上述准确, HMM就基本上搞定了:
定义
λ=(A,B,π)λ=(A,B,π)
这就是HMM,其中括号内的三个部分称为HMM三元素.
基本假设
-
齐次马尔可夫性假设, 即假设 在任意时刻 t 的状态 只有前一状态有关,与其他任何状态,观测都无关:
P(it|it−1,ot−1,…,i1,o1)=P(it|it−1)P(it|it−1,ot−1,…,i1,o1)=P(it|it−1)
-
观测独立性假设, 即假设任意时刻的观测 只与该时刻的马尔可夫链状态有关,与其他任何时刻状态,观测都无关:
P(ot|iT,oT,,˙it+1,ot+1,it−1,ot−1,…,i1,o1)=P(ot|it)P(ot|iT,oT,,˙it+1,ot+1,it−1,ot−1,…,i1,o1)=P(ot|it)
基本问题
- 概率计算问题, 给定定 λ=(A,B,π)λ=(A,B,π) 和观测序列O=(o1,o2,…,oT)O=(o1,o2,…,oT) , 计算在模型 λλ 下 观测序列 O 出现的概率P(O|λ)P(O|λ), 也可说是HMM与观测的匹配程度.
- 学习问题, 给定观测序列 O=(o1,o2,…,oT)O=(o1,o2,…,oT) ,估计模型 λ=(A,B,π)λ=(A,B,π) 使得在该模型下, P(O|λ)P(O|λ) 最大.
- 预测问题,也称解码问题, 给定定 λ=(A,B,π)λ=(A,B,π) 和观测序列O=(o1,o2,…,oT)O=(o1,o2,…,oT) , 求使 P(O|λ)P(O|λ) 最大的状态序列 I=(i1,i2,…,iT)I=(i1,i2,…,iT),即最有可能的状态序列.
接下来,对于这三个问题,我们将各个击破.
前向,后向算法
对于第一个问题, 最简单的方法就是暴力计算,把每种情况都考虑一遍, 不用我说,你也知道这不可行. 倒不是因为复杂,是因为算不起,它的时间复杂度是恐怖的 O(TNT)O(TNT) .
不过还真有比较不错的算法,而且还有两种!
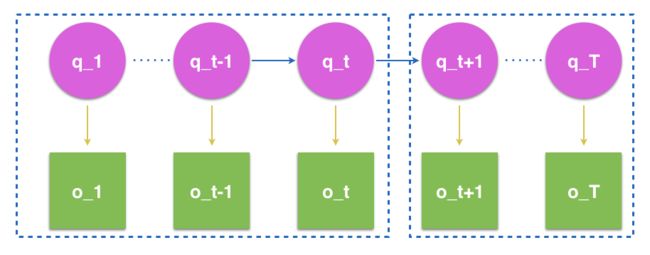
上图可表示为一HMM列.左,右两边虚线内我们分别用αt(j),βt(j)αt(j),βt(j)来表示,其中
αt(j)=P(o1,o2,…,ot,it=qj|λ);βt(j)=P(ot+1,ot+2,…,oT|it=qj,λ)αt(j)=P(o1,o2,…,ot,it=qj|λ);βt(j)=P(ot+1,ot+2,…,oT|it=qj,λ)
这两个就是我们分别用于前向,后向算法的关键因子.
再明确一下,我们的目标是求解 P(O|λ)P(O|λ) .
前向算法
-
初始状态 o1o1, 考虑出现o1o1 概率:
P(o1|λ)=∑j=1NP(o1,i1=qj|λ)=∑j=1Nα1(j)=∑j=1Nπjbj(o1)P(o1|λ)=∑j=1NP(o1,i1=qj|λ)=∑j=1Nα1(j)=∑j=1Nπjbj(o1)
-
当得到 P(o1,o2,…,ot|λ)P(o1,o2,…,ot|λ) , 现在要求P(o1,o2,…,ot,ot+1|λ)P(o1,o2,…,ot,ot+1|λ) ,可以先从αt+1(j)αt+1(j) 出发:
αt+1(j)=====P(o1,o2,…,ot,ot+1,it+1=qj|λ)∑Nk=1P(o1,o2,…,ot,ot+1,it+1=qj,it=qk|λ)∑Nk=1P(o1,o2,…,ot,it=qj|λ)ajkbj(ot+1)∑Nk=1αt(j)ajkbk(ot+1)bj(ot+1)∑Nk=1αt(j)ajkαt+1(j)=P(o1,o2,…,ot,ot+1,it+1=qj|λ)=∑k=1NP(o1,o2,…,ot,ot+1,it+1=qj,it=qk|λ)=∑k=1NP(o1,o2,…,ot,it=qj|λ)ajkbj(ot+1)=∑k=1Nαt(j)ajkbk(ot+1)=bj(ot+1)∑k=1Nαt(j)ajk
而:
P(o1,o2,…,ot,ot+1|λ)=∑j=1Nαt+1(j)P(o1,o2,…,ot,ot+1|λ)=∑j=1Nαt+1(j)
- 最终:
P(O|λ)=∑j=1NαT(j)P(O|λ)=∑j=1NαT(j)
这就是前向算法.
后向算法
前向算法是从前向后, 后向算法则是从后向前的. 回顾:
βt(j)=P(ot+1,ot+2,…,oT|it=qj,λ)βt(j)=P(ot+1,ot+2,…,oT|it=qj,λ)
-
第一步,由 ββ 定义,可知 当t = T时,
βT(j)=1βT(j)=1
也就是说,目前的观测序列到时刻T,而βTβT 则关注的是 T+1 时刻, 这从现有已知条件中,对T+1 时刻没有任何限制的,即oT+1oT+1 的任何取值都可接受,显然在这情况下, 上式(概率)值为1. -
当已知 t+1时刻, 推导 t 时刻:
βt(j)====P(ot+1,ot+2,…,oT|it=qj,λ)∑Nk=1P(ot+2,…,oT|ot,it=qj,it+1=qk,λ)∑Nk=1P(ot+2,…,oT|it+1=qk,λ)ajkbk(ot+1)∑Nk=1ajkbk(ot+1)βt+1(j)βt(j)=P(ot+1,ot+2,…,oT|it=qj,λ)=∑k=1NP(ot+2,…,oT|ot,it=qj,it+1=qk,λ)=∑k=1NP(ot+2,…,oT|it+1=qk,λ)ajkbk(ot+1)=∑k=1Najkbk(ot+1)βt+1(j)
-
因此:
P(O|λ)=∑j=1Nπjbj(o1)β1(j)P(O|λ)=∑j=1Nπjbj(o1)β1(j)
举例计算
现在咱们来计算上面'三个女朋友'的例子,老妈想知道的问题. 现在我们简化一下问题,你的微信状态变成'吃,看,吃'. 计算方式一模一样,只是简化了一点,方便我行文. 这里要计算的是'吃,看,吃'的概率正常应该是多少(有些人可能要疑惑:这个跟大妈的问题不太一样啊~,其实是一样的, 因为我们可以假设这'吃,看,吃'与下周出现的活动组成一个序列,并求出概率,概率最大的情况,就是你下周最有可能的活动:
前向计算
概率上面三个表:
- 初始状态
α1(1)=π1b1(o1)=0.2∗0.5=0.1α1(2)=π2b2(o1)=0.4∗0.4=0.16α1(3)=π1b3(o1)=0.4∗0.7=0.28α1(1)=π1b1(o1)=0.2∗0.5=0.1α1(2)=π2b2(o1)=0.4∗0.4=0.16α1(3)=π1b3(o1)=0.4∗0.7=0.28
-
递推计算
α2(1)=[∑3i=1α1(i)ai1]b1(o2)=0.154∗0.5=0.077α2(1)=[∑i=13α1(i)ai1]b1(o2)=0.154∗0.5=0.077
同理可算法其他,这里就不全写了, -
最后
P(O|λ)=∑i=1Na3(i)=0.13022P(O|λ)=∑i=1Na3(i)=0.13022
后向计算
-
β3(j)=1β3(j)=1
-
递推计算:
β2(1)=∑j=13ai1bi(o3)β3(1)=0.51β2(1)=∑j=13ai1bi(o3)β3(1)=0.51
其他同理. -
最终: P(O|λ)=∑3i=1πibi(o1)β1(i)=0.13022P(O|λ)=∑i=13πibi(o1)β1(i)=0.13022
前向,后向算法结果是一样的!
至此,第一个问题解决了. 这个问题可以用于时间序列预测问题,应用方式同上.
学习问题
有时我们并不知道HMM模型的具体形态,因此需要一些手段得到它.
在做此类问题时也可大致分为两种情:
已知观测序列及隐序列
这里了也必须已知,N 是所有可能的状态数, M 是所有可能的观测数.
比如,对于中文分词,我们手上有数据集, 而且我们可以很容易地定义每个字隐状态(隐状态: 起始字,中间字,终止字,及独立字等等),这样, 在两序列已知的情况下,根据大数定律,应用最大似然求出各状态转移矩阵,观测矩阵及一个初始向量.
已知观测序列
这里了也必须已知,N 是所有可能的状态数, M 是所有可能的观测数.
这里的方法就是 EM 算法, 不过因为在HMM中,因此有个别名叫 Baum-Welch 算法.
预测问题
第三个问题是预测问题.预测的是给定观测序列,背后最有可能的马尔可夫链.
这个问题目前有两种方法,第一种称为近似算法.此算法寻找各个时刻的最优解,最后连成一列. 为什么会被称为近似算法? 因为这样得到的每个时刻的最优,最终并不一定是整个序列的最优解.
因此目前最好的方法是维特比(Viterbi)算法.
Viterbi 算法
此算法是用动态规划的方式解决HMM的预测问题.即把隐状态列看成是最优路径上的每一步,找最大概率路径,即转化成寻找最优路径.
在动态规划中, 最优路径具有这样的特性: 最优路径在 t 时刻通过 结点 i, 那么 这一路径对于从 i 到 最后的剩余路径也是最优的.否则必有另一路径比此更优,这是矛盾的.基于此 Viterbi 算法 递推的计算在 t 时刻的最优路径,直至最后.根据最后的最优路径反向确定最优路径上的各点隐状态.
设 t 时刻的最优路径是
δt(j)=maxi1,i2,…,it−1P(it=qj,it−1,…,i1,ot,…,o1|λ),j=1,2,…,Nδt(j)=maxi1,i2,…,it−1P(it=qj,it−1,…,i1,ot,…,o1|λ),j=1,2,…,N
于是
δt+1(k)==maxi1,i2,…,itP(it=qj,it−1,…,i1,ot,…,o1|λ)max1≤j≤N[δt(j)ajk]bk(ot+1)δt+1(k)=maxi1,i2,…,itP(it=qj,it−1,…,i1,ot,…,o1|λ)=max1≤j≤N[δt(j)ajk]bk(ot+1)
这样,
-
最初状态:
δ1(j)=πjbj(o1)δ1(j)=πjbj(o1)
-
已知 δt(j)δt(j) 递推 δt+1(k)δt+1(k)
δt+1(k)=max1≤j≤N[δt(j)ajk]bk(ot+1)δt+1(k)=max1≤j≤N[δt(j)ajk]bk(ot+1)
-
最后状态,得到全局最优路径
pathbest=max1≤j≤NδT(j)pathbest=max1≤j≤NδT(j)
-
反向推导 最优隐状态序列, 令在 t+1 时刻 状态在qkqk 的最优路径中,第 t 个结点:
ψt+1(k)=argmax1≤j≤N[δt(j)ajk]ψt+1(k)=argmax1≤j≤N[δt(j)ajk]
于是最终列:k∗1,k∗2,…,k∗Tk1∗,k2∗,…,kT∗
其中k∗t=ψt+1(j)kt∗=ψt+1(j)
举例计算
还是'三个女朋友的例子',还是'吃,看,吃',
首先,
δ1(1)=0.1,δ1(2)=0.16,δ1(3)=0.28δ1(1)=0.1,δ1(2)=0.16,δ1(3)=0.28
递推 t = 2,
δ2(1)=max1≤j≤3[δ1(j)aj1]b1(o2)=0.028δ2(1)=max1≤j≤3[δ1(j)aj1]b1(o2)=0.028
同理:
δ2(2)=0.0504,δ2(3)=0.042δ3(1)=0.00756,δ3(2)=0.01008,δ3(3)=0.0147δ2(2)=0.0504,δ2(3)=0.042δ3(1)=0.00756,δ3(2)=0.01008,δ3(3)=0.0147
最终状态:
pathbest=max1≤j≤3δ3(j)=0.0147pathbest=max1≤j≤3δ3(j)=0.0147
即 i3=3i3=3
反向推断:
i2=ψ2+1(3)=argmax1≤j≤N[δ2(j)aj3]=3i2=ψ2+1(3)=argmax1≤j≤N[δ2(j)aj3]=3
最后
i1=ψ1+1(3)=argmax1≤j≤N[δt(j)aj3]=3i1=ψ1+1(3)=argmax1≤j≤N[δt(j)aj3]=3
因此最终状态[3,3,3], 也就是说你这三周一直在陪C 女朋友的概率最大.
升华
思考,机器学习的算法哲学是什么? 是根据有限的已知去推断未知. 这又可分为两种, 一种是根据知识,对未来给出一个确定性判断,比如decision tree; 还有一是对未来的不确定性怀敬畏,对未知只做概率性预测,如果一定要给出个结果,那只好用最大化概率法给出. 两种方法没有孰优孰劣,只是适用范围,场景,数据不同而已.
本文分享的HMM 是贝叶斯网络的一个特例. 在推导过程中用到了一些贝叶斯网络相关的知识.贝叶斯网络是用有向无环图来表示变量间的依赖关系.
贝叶斯网络则属于更大范畴的概率图模型(Probabilistic Graphical Model, PGM). 而概率图模型则是概率模型的一种具体实现.
概率模型就是上面所说的,对未知进行概率性预测. 其核心是对未知进行概率分布预测,这右可分为两种: '生成(generative)模型'与'判别(discriminative)模型'.具体地, 可观测变量集 O, 兴趣变量集 Y(即所要求解的变量),其他相关变量 R.
生成式关心的是联合概率分布: P(Y, R, O); 而 判别式则关注条件概率 P(Y, R | O).
参考文献
-
Artificial Intelligence: A modern approach, 3rd edition, 2010, Stuart Russell and Peter Norvig.
- 统计学方法,2012,李航.(注: 文中例子根据本书中例子改编~)
- 机器学习, 2016, 周志华.
- Pattern Recognition and Machine Learning, 2006 ,Christopher M. Bishop.
-
HMM, 2017,Wikipedia.