Redis持久化
持久化是什么
额 就是永久化的保存数据呗
有两种持久化方式RDB和AOF
1.RDB (Redis Database),记录Redis某 个时刻的全部数据,这种方式本质就是数据快照,直接保存二进制数据到磁盘,后续通过加载RDB文件恢复数据。
2.AOF (Append Only File) ,记录执行的每条命令,重启之后通过重放命令来恢复数据,AOF本质是记录操作日志,后续通过日志重放恢复数据。
仅从他们的性质来看
RDB是快照恢复,AOF是日志恢复
体积方面:相同数据量下,RDB体积更小,因为RDB是记录的二进制紧凑型数据
恢复速度: RDB是数据快照,可以直接加载,而AOF文件恢复,相当于重放情况,RDB显然会更快
数据完整性: AOF记录了每条日志,RDB是间隔一段时间记录一次,用AOF恢复数据通常会更为完整。
如果业务本身只是缓存数据且并不是一个海 量访问,可以不用开持久化。
如果对数据非常重视,可以同时开启RDB和AOF, 注意一点,同时开启的情况下,只会用AOF来加载,同时开启了AOF和RDB表示对数据要求强一致 如果AOF不存在 那就回启动空库 不会用RDB恢复数据 因为RDB可能会缺少很多数据
如果可以接受丢几分钟级别的数据,那么建议只开RDB。
Redis官方不建议单独开AOF,因为如果决定要走数据备份,那么镜像保存始终是数据库领域非常行之有效的解决方案,所以在配置中RDB是默认打开的,而AOF不是。(有比没有强)
细说RDB
触发RDB的条件
每900s,有1条写数据操作;
每300s,有10条写数据操作;
每60s,有10000写数据操作。
写数据操作指增加、删除、更新
他们之间是并集关系,即只要满足其中一个条件,就达到了RDB持久化的条件,这里用的bgsave不是save 省的阻塞
什么时候进行持久化
1.主动执行save
执行了save 命令,就会在主线程生成RDB文件由于和执行操作命令在同一个线程,所以如果写入RDB文件的时间太长,会阻塞主线程,这个命令慎用。
2.主动执行bgsave
和save不同,会创建一个子 进程来生成RDB文件,这样可以避免主线程的阻塞。
3.达到持久化配置阈值
上面有提到,Redis可以配置持久化策略,达到策略就会触发持久化,这里的持久化使用的方式是后台save,从这可以看到Redis比较推荐的方式也是后台执行持久化,尽可能减少对主流程影响。达到阈值之后,是由周期函数触发持久化。
4.还会在程序正常关闭的时候执行
在关闭时,Redis会启动- -次阻塞式持久化,以记录更全的数据
RDB具体做了什么
就是这样,Redis使用bgsave对当前内存中的所有数据做快照,这个操作是由bgsave子进程在后台完成的,执行时不会阻塞父进程中的主线程,这就使得主线程同时可以修改数据。
这样的目的是为了减少创建子进程时的性能损耗,从而加快创建子进程的速度,毕竟创建子进程的过程中,是会阻塞主线程的。
可以看到,复制期间,读数据互不影响,如果有写操作发生,则主进程复制一-份内存,在这个复制的内存基础上,主进程再修改原来的数据,子进程持久化的依然是修改之前的数据。
1.RDB本质是什么?
RDB本质是二进制形式的快照。
2.如何开始RDB
RDB可以通过配置定时触发,触发时用的是后台持久化方式。
也可以save命令,bgsave命令 主动触发,save底层用的是阻塞式持久化,bgsave用的是后台持久化。
实际生产中,很少会自己主动执行命令(这句话实力强点,有底气才说)
最后,如果Redis正常关闭,是会执行阻塞式持久化的。
3.RDB对主流程有什么影响?
当执行阻塞式持久化的时候,由主进程进行RDB快照保存,会阻塞主进程
当执行后台持久化时,由fork出的子进程来进行RDB快照保存
。如果数据量比较大的时候,会导致fork子进程这个操作比较耗时,从而阻塞主进程
。由于采用了写时复制技术,如果在进行RDB快照保存的时候,有大量的写入操作执行,会导致主进程多拷贝一份数据,消耗大量额外的内存
4.RDB执行流程是怎样的?
首先,Fork出-个子进程来专门做RDB持久化
接着,子进程写数据到临时的RDB文件
最后,用新RDB文件替换旧的RDB文件
具体来讲
打开一个临时的RDB文件(c语 言库函数fopen)
将执行命令这一 时刻数据库数据写入到I0缓冲区(c语言库函数fwrite) 会将这一时刻的数据按照RDB对应的版本格式进行写入
执行fush (将IO缓冲区里的数据刷新到内核缓冲区)
执行fsync (可以将内核缓冲区里的数据刷到磁盘)
执行fclose (关闭这个临时文件)
修改临时文件名字,并让咱们的后台线程BIO_ _LAZY_ FREE去删除旧的RDB (到此一次RDB过程结束)
简单来说RDB的流程就是 触发RDB持久化时,让主进程或子进程(区分条件)来将这一-时刻的数据库数据写到一个新的RDB文件中.
细说AOF
刚才说了 RDB是默认打开的 AOF要自己手动开启
打开Redis的配置文件
/usr/local/etc/redis.conf
打开之后,Redis每条更改数据的操作都会记录到AOF文件中,当你重启,AOF会助你重建状态,相当于就是请求全部重放一次,所以AOF恢复起来会比较慢。
AOF写入流程

这不免会让人担心,是否会影响Redis的执行性能,答案是肯定的,多了一步操作,或多或少都会带来些损耗,但是Redis实际是提供了不同的策略来选择不同程度的损耗。这里我们先从比较的宏观视角,介绍Redis提供的3种刷盘
策略,以便根据需要进行不同的选择。
1.appendfsync always, 每次请求都刷入AOF,用官方的话说,非常慢,非常安全
2.appendfsync everysec,每秒刷一次盘,用官方的话来说就是足够快了,但是在崩溃场景下你可能会丢失1秒的数据。
3.appendfsync no,不主动刷盘,让操作系统自己刷,一般情况Linux会每30秒刷一 -次盘,这种策略下,可以说对性能的影响最小,但是如果发生崩溃,可能会丢失相对比较多的数据。

经典给三种选择 然后推荐使用中间的
写入操作具体行为
写入AOF,其实是分了好几步来的。
第一步:其实是将数据写入AOF缓存中,这个缓存名字是aof_ _buf, 其实就是一个sds数据
第二步: aof_ buf对应数据刷入磁盘缓冲区,什么时候做这个事情呢?事实上,Redis源码中一共有4个时机,会调用一个叫flushAppendOnlyFile的函数,这个函数会使用write函数来将数据写入操作系统缓冲区:
1.处理完事件处理后,等待下一次事件到来之前,也就是beforeSleep中 。
2.周期函数serverCron中,这也是我们打过很多次交道的老朋友了
3.服务器退出之前的准备I作时
4.通过配置指令关闭AOF功能时
第三步:刷盘,即调用系统的flush函数,刷盘其实还是在flushAppendOnlyFile函数中,是在write之后, 但是不一定调用了flushAppendOnlyFile,flush就一定会被调用,这里其实是支持一个刷盘时机的配置, 这一 步受 刷盘策略影响是最深的,如下面代码所示,如果是appendfsync always策略,那么就立刻调用redis_ fsync刷盘, 如果是AOF_ FSYNC_ EVERYSEC策略,满足条件后会用aof_ background_ fsync使用后 台线程异步刷盘。

AOF重写
AOF是不断写入的,这很容易带来一个疑问, 如此下去AOF不是会不断膨胀吗?
针对这个问题,Redis采用了重写的方式来解决:
Redis可以在AOF文件体积变得过大时,自动地在后台Fork-个子进程,专门对AOF进行重写。说白了,就是针对相同Key的操作,进行合并,比如同一个Key的set操作,那就是后面要盖前面。
在重写过程中,Redis不但将新的操作记录在原有的AOF缓冲区,而且还会记录在AOF重写缓冲区。一旦新AOF文件创建完毕,Redis 就会将重写缓冲区内容,追加到新的AOF文件,再用新AOF文件替换原来的AOF文件。
达到多大开始重写是配置文件决定的
超过64M的情况下,相比上次重写时的数据大一倍,则触发重写,很明显,最后实际上还是在周期函数来检查和触发的。
这两个参数可以修改
简述AOF重写流程
可以将AOF重写流程记为"一次拷贝,两处日志”
一次拷贝:重写发生时,主进程会fork出一个子进程, 让子进程将这些Redis数据写入重写日志
两处日志:重写发生时,我们需要注意AOF缓冲和AOF重写缓冲;当重写时,有新的写入命令执行,会由主进程分别写入AOF缓冲和AOF重写缓冲; AOF缓冲用于保证此时发生宕机,原来的AOF日志也是完整的,可用于恢复。AOF重写缓冲 用于保证新的AOF文件也不会丢失最新的写入操作。
额外补充:在重写时AOF重写缓冲会通过管道传送给子进程,再由子进程刷入新的AOF日志(此时,AOF重写完成)
AOF混合持久化
混合部署听名字似乎是同时开启RDB和AOF,实际上不是的,混合部署实际发生在AOF重写阶段,将当前状态保存为RDB二进制内容,写入新的AOF文件,再将重写缓冲区的内容追加到新的AOF文件,最后替代原有的AOF文件。此时的AOF文件,就不再单纯的是日志数据,而是二进制数据+日志数据的混合体,所以叫混合持久化。(流程没变 只是日志文件变了)
它解决了什么问题
混合持久化是是发生在原有的AOF流程,如果从这个视角来看,其实本质还是AOF,只是重写时使用了RDB进行了优化。
混合持久化是对AOF重写的优化,这种方式可以大大降低AOF重写的性能损耗。以及降低AOF文件的存储空间,付出的代价则是降低AOF文件的读写行,但是实际生产中,很少有真正需要去人肉读AOF数据的情况,这点从5.0之后默认打开AOF混合持久化模式也能看出。
在我看来,如果是考虑到对Redis核心处理性能的影响,那还是需要用RDB,如果是为了相对更可靠的数据记录,也就是尽可能丢失更少的数据,那还是得用AOF,同时,如果对可读性没有太大执念,那进一步开启混合持久化。 是一个很好的选择,毕竟其实生产上,关注AOF可读性的情况实际比较少。
混合持久化开启之后,服务启动时如何加载持久化数据
之前有说过,如果同时启用了AOF和RDB,Redis 重新启动时,会使用AOF文件来重建数据集,因为通常来说,
AOF的数据会更完整,那这里其实是一样的, 混合持久化还是属于AOF,所以如果有混合持久化,那肯定是优先使用混合持久化的数据。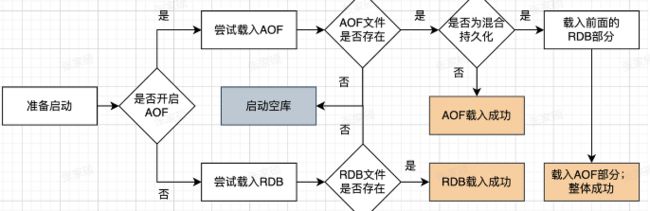
混合持久化的A0F文件里开头有REDIS这个标记,加载时候通过这个标记来进行的判断