C开源项目-TinyHttp解读(上)
项目简介
此项目可以自行在GitHub上进行下载,作者的ReadMe文档也写得是比较详细的。这里用到了较多的Unix编程,不会的可以一点一点去查。
(实名感谢我们家杰佬发给我的APUE,可以当字典查)
项目内容
其实就是实现了一个轻量级服务器的功能,同时源代码也包含了一个simpleclient的文件,用于生成一个用户端。这和计网课上的用Java写TCP/UDP很像,但C会显得更麻烦一些,但总认为基于Unix给人一种高大上的感觉。
代码分析
我这儿就直接按照作者在README中给出的阅读顺序来浏览了。
由于下边都是我没动过的源码,是存在一些问题的,比如我用Ubuntu21打开文件时就提示我说u_short已经不能用啦,全部改为unsigned short即可哈。
- main函数分析
int main(void)
{
int server_sock = -1;
u_short port = 4000;
int client_sock = -1;
struct sockaddr_in client_name;
socklen_t client_name_len = sizeof(client_name);
pthread_t newthread;
server_sock = startup(&port);
printf("httpd running on port %d\n", port);
while (1)
{
client_sock = accept(server_sock,
(struct sockaddr *)&client_name,
&client_name_len);
if (client_sock == -1)
error_die("accept");
/* accept_request(&client_sock); */
if (pthread_create(&newthread , NULL, (void *)accept_request, (void *)(intptr_t)client_sock) != 0)
perror("pthread_create");
}
close(server_sock);
return(0);
}
这里面直接来定义一些东西实际上是难以理解的,但总体来看还是可以根据英语,结合计算机网络的知识来进行解读。
大家都知道socket是套接字,我们的计算机网络通信机制用的就是socket编程,socket是留给我们开发人员的一个接口。这个接口之强大就在于其帮助我们屏蔽了计算机网络底层的内容,我们无需和那些繁琐的协议(虽然等会一些参数会用到)甚至是那些底层物理结构直接打交道。
先来看变量申明:
int server_sock = -1;
u_short port = 4000;
int client_sock = -1;
struct sockaddr_in client_name;
socklen_t client_name_len = sizeof(client_name);
pthread_t newthread;
server_sock = startup(&port);
printf("httpd running on port %d\n", port);
可以看到我们分别为服务器和客户端都申请了一个套接字并且初始化的时候都为-1,等会我们会用了另外的值替换。
申明端口号4000,这个不难理解。
下述牵扯到地址格式的问题,可以翻阅APUE的16.3.2直接进行学习。
随后我们申明了一个结构体,sockaddr_in,这个可能有必要需查看一下他的定义。
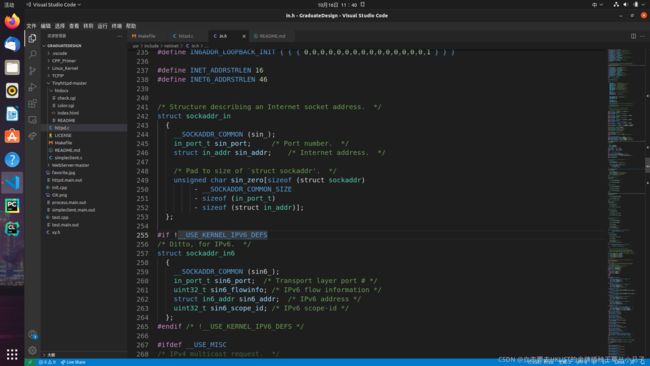
首先官方就交代了,这是一个拿来描述Internet Socket Address的结构体。这就需要发挥计算机网络的知识了,如何来确定这么一个socket的地址呢?
它需要你的IP地址,端口号,协议族,同时此结构体的最后还声明了要针对结构体sockaddr来进行补齐‘0’操作。
那么这俩地址间的关系是什么呢,根据我们的“字典”,sockaddr_in是ipv4域的一个地址结构,sockaddr就是一个统一的可以传入套接字使用的通用地址结构!
所以,综上,应该可以明白为什么有一个padding填充值了吧!
多线程你那个pthread可以先不予理睬,因为作者已经说了这个是需要comment out的!所以我们在Linux环境下make的时候需要先注释掉!
最后就会发现我们调用了一个startup函数用以决定服务器的socket字了,其为int型的主要原因就是unix视万物为文件,这个套接字实际上就是一个文件描述符。
有了套接字就好办了,我们来分析剩下的内容:
while (1)
{
client_sock = accept(server_sock,
(struct sockaddr *)&client_name,
&client_name_len);
if (client_sock == -1)
error_die("accept");
/* accept_request(&client_sock); */
if (pthread_create(&newthread , NULL, (void *)accept_request, (void *)(intptr_t)client_sock) != 0)
perror("pthread_create");
}
close(server_sock);
不难看出这是一个死循环,原因也很简单,服务器需要一直处于打开状态监听客户端的请求并且与其建立连接。
这段代码中主要就是几个函数的理解。
1.error_die函数,这个不是什么内置api,是作者自己手写的一个函数,定义如下:
/* Print out an error message with perror() (for system errors; based
* on value of errno, which indicates system call errors) and exit the
* program indicating an error. */
/**********************************************************************/
void error_die(const char *sc)
{
perror(sc);
exit(1);
}
很清晰明了,就是打印出错误信息然后退出程序,就那么简单。
2.accept函数

首先还是看用途,我就用自己拙劣的英语翻译一下:
就是说等待到(服务器)套接字的一个连接。当一个连接请求到达时,会开辟一个新的套接字用于进行通信。所以这个函数最后就会返回一个新的套接字(描述符),也就是我们的客户端套接字。
然后就是参数设置问题,第一个就是我们的服务器套接字描述符,也就是server_sock,第二第三个参数就应该是客户端本身的地址和长度。
结束后我们就会进行一个判断,因为如果套接字仍旧是-1的,说明出错了!
哦对了,我们看README文件会发现需要把pthread多线程这一块注释掉的,我只是单纯把源文件拷贝过来,其实这个函数就无需分析了哈!
3.accept_request()函数。
这个函数有点长们我们等会再来细细看。
- startup()函数。
在上面我们已经讲过,startup函数为服务器指定了一个套接字,我们就来看看这是如何来生成的吧!
/* This function starts the process of listening for web connections
* on a specified port. If the port is 0, then dynamically allocate a
* port and modify the original port variable to reflect the actual
* port.
* Parameters: pointer to variable containing the port to connect on
* Returns: the socket */
/**********************************************************************/
int startup(u_short *port)
{
int httpd = 0;
int on = 1;
struct sockaddr_in name;
httpd = socket(PF_INET, SOCK_STREAM, 0);
if (httpd == -1)
error_die("socket");
memset(&name, 0, sizeof(name));
name.sin_family = AF_INET;
name.sin_port = htons(*port);
name.sin_addr.s_addr = htonl(INADDR_ANY);
if ((setsockopt(httpd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on))) < 0)
{
error_die("setsockopt failed");
}
if (bind(httpd, (struct sockaddr *)&name, sizeof(name)) < 0)
error_die("bind");
if (*port == 0) /* if dynamically allocating a port */
{
socklen_t namelen = sizeof(name);
if (getsockname(httpd, (struct sockaddr *)&name, &namelen) == -1)
error_die("getsockname");
*port = ntohs(name.sin_port);
}
if (listen(httpd, 5) < 0)
error_die("listen");
return(httpd);
}
作者的代码思路也很清晰了,就是说这个函数启动了监听某个特定端口的过程。
端口号如果为0,就动态地分配一个然后要修正原端口的信息以体现实际端口。
httpd就是充当了server_sock,它是由socket函数生成的,最后会返回此值。
接下来就可以来学习一下socket函数。
第一个参数是domain,其实就是协议族,我们在这里指定了PF_INET = AF_INET指定的是IPV4网域,还有一些其他的选项可以找另外的博客借鉴哈。
第二个参数是type,套接字类型,我们选择STREAM其实就是字节流传输,这种方式的特点就是我们说的TCP传输的特点。
第三个参数是协议类型,这个和第一个不大一样,指的是domain和type之间的protocol。设为0的话就会有一个默认值,我们这样的设置基本会默认为“TCP”。
最后如果此函数返回了-1说明失败了。
然后就是对我们上面认识过的ipv4地址的结构体进行设置。设置协议族,端口号,地址。这里涉及了htons和htonl函数都是和地址有关的,htons是将传入的参数返回“网络字节序”的16位整数,htonl是返回“网络字节序”的32位整数。
这里涉及的就是大小端表示法,而我们的网络字节序基本就是用大端法来处理。所谓大端法就是说低有效字节存放于高内存地址,给张计系(CSAPP)用的图:

其次就是setsockopt函数,这个函数用于设置socket的状态。如果只是想了解这个函数怎么设置的话可以看这篇,setsockopt参数设置。这个函数自己也没仔细了解过就先不画蛇添足了。
接下来就是bind函数,用于关联套接字和地址。这个通常只是服务器需要的步骤,绑定一个ip地址+端口号,客户端并不需要如上步骤。原因很简单,服务器需要处于一个众所周知的位置,绑定就能很好的实现这一点,而客户端只需主机随机分配即可。
此函数的参数也并不困难,socket描述符 + 地址结构体(由ipv4的sockaddr_in进行转换得到) + socket长度。
随后就到了端口号为0时的情景,此时我们会动态分配一个端口号。
用到的是getsockname函数。
最后就让其处于listen(监听)状态,第二个参数的含义是可排队的最大连接个数。我们自己的电脑垃圾,大公司的服务器可接受的连接数那肯定是远远大于这个5的。
- accept_request()函数分析
/**********************************************************************/
/* A request has caused a call to accept() on the server port to
* return. Process the request appropriately.
* Parameters: the socket connected to the client */
/**********************************************************************/
void accept_request(void *arg)
{
int client = (intptr_t)arg;
char buf[1024];
size_t numchars;
char method[255];
char url[255];
char path[512];
size_t i, j;
struct stat st;
int cgi = 0; /* becomes true if server decides this is a CGI
* program */
char *query_string = NULL;
numchars = get_line(client, buf, sizeof(buf));
i = 0; j = 0;
while (!ISspace(buf[i]) && (i < sizeof(method) - 1))
{
method[i] = buf[i];
i++;
}
j=i;
method[i] = '\0';
if (strcasecmp(method, "GET") && strcasecmp(method, "POST"))
{
unimplemented(client);
return;
}
if (strcasecmp(method, "POST") == 0)
cgi = 1;
i = 0;
while (ISspace(buf[j]) && (j < numchars))
j++;
while (!ISspace(buf[j]) && (i < sizeof(url) - 1) && (j < numchars))
{
url[i] = buf[j];
i++; j++;
}
url[i] = '\0';
if (strcasecmp(method, "GET") == 0)
{
query_string = url;
while ((*query_string != '?') && (*query_string != '\0'))
query_string++;
if (*query_string == '?')
{
cgi = 1;
*query_string = '\0';
query_string++;
}
}
sprintf(path, "htdocs%s", url);
if (path[strlen(path) - 1] == '/')
strcat(path, "index.html");
if (stat(path, &st) == -1) {
while ((numchars > 0) && strcmp("\n", buf)) /* read & discard headers */
numchars = get_line(client, buf, sizeof(buf));
not_found(client);
}
else
{
if ((st.st_mode & S_IFMT) == S_IFDIR)
strcat(path, "/index.html");
if ((st.st_mode & S_IXUSR) ||
(st.st_mode & S_IXGRP) ||
(st.st_mode & S_IXOTH) )
cgi = 1;
if (!cgi)
serve_file(client, path);
else
execute_cgi(client, path, method, query_string);
}
close(client);
}
此函数意图很明显,就是用于处理连接请求的。
那些变量可以通过推导获取其含义,直接对着关键函数进行分析即可。
1.get_line函数。
/**********************************************************************/
/* Get a line from a socket, whether the line ends in a newline,
* carriage return, or a CRLF combination. Terminates the string read
* with a null character. If no newline indicator is found before the
* end of the buffer, the string is terminated with a null. If any of
* the above three line terminators is read, the last character of the
* string will be a linefeed and the string will be terminated with a
* null character.
* Parameters: the socket descriptor
* the buffer to save the data in
* the size of the buffer
* Returns: the number of bytes stored (excluding null) */
/**********************************************************************/
int get_line(int sock, char *buf, int size)
{
int i = 0;
char c = '\0';
int n;
while ((i < size - 1) && (c != '\n'))
{
n = recv(sock, &c, 1, 0);
/* DEBUG printf("%02X\n", c); */
if (n > 0)
{
if (c == '\r')
{
n = recv(sock, &c, 1, MSG_PEEK);
/* DEBUG printf("%02X\n", c); */
if ((n > 0) && (c == '\n'))
recv(sock, &c, 1, 0);
else
c = '\n';
}
buf[i] = c;
i++;
}
else
c = '\n';
}
buf[i] = '\0';
return(i);
}
注释里也说了,就是从socket套接字获取一行内容,这个一行可以是以【“换行\n”,可以是“回车\r”也可以是CRLF(回车换行)】结尾的。
这个函数其实主要就是做逻辑上的处理,但要完全阅读还得先看看recv究竟干了些啥。recv就是从传入的socket套接字处[客户端套接字,因为这个get_line函数是服务器端在调用的]取内容,存于缓冲区buffer处,大小为size,最后一个参数是读取的模式标志。此函数有一个整型返回值,若为0则说明已无可用数据或者连接已结束,-1代表出错,其他情况代表了真正读取到的字符数。
再回过头来看get_line的逻辑,循环体内,先读取一个字节的内容。
<=0说明失败,将c设为换行符下一轮就可以直接退出。
否则就对读取到的内容进行判定:
不是回车符就直接写入缓冲区,指针右移,这种情况如果读到的是换行符那么下一轮也同样直接就结束了。
若是回车符的话,仍旧是接收一个字节的内容只不过此处用了标志MSG_PEEK,这样一来可以做到只是查看下一个要读取的数据内容而不是真正取走它!
接下来我们继续进行判断如果下一个又是\n或者说没有下一个了那么下一轮也是会直接退出的!
其实作者写那么多,大家好好理解一下,就是把我们的三种行结尾方式均进行了判定,其余情况才会在缓冲区进行写入,就那么简单!
tinyhttp项目阅读(上)小结
以上分析的内容并没有太多花里胡哨的技巧,没有什么高深莫测的算法,但需要编程人员熟悉Unix环境下的网络编程,需要扎实的C语言功底和一定的计算机网络的知识!
一篇写太多有点难以阅读,(下)晚上更完!