【数据结构与算法】顺序表&手撕vector
一个人走得远了,就会忘记自己为了什么而出发,希望你可以不忘初心,不要随波逐流,一直走下去
欢迎关注点赞收藏留言
本文由 程序喵正在路上 原创,CSDN首发!
系列专栏:数据结构与算法
首发时间:2022年8月26日
✅ 如果觉得博主的文章还不错的话,希望小伙伴们三连支持一下哦
温馨提示:学完 C 和 C++,阅读起来更轻松哦
阅读指南
- 一、漫谈数据结构和算法
- 二、动态数组插入
- 三、代码优化
- 四、删除第一个和最后一个
- 五、删除中间的
- 六、空间换时间
- 七、空间换时间代码实现
- 八、类封装
- 九、类模板封装
一、漫谈数据结构和算法
曾经, 有一位图灵奖获得者说过这么一句话 —— 编程 == 数据结构 + 算法
意思就是,任何一门编程语言,它都是由数据结构和算法组成的。编程语言是用来描述事物的,而事情,就是流程,就是算法;物体呢,就是数据,就是数据结构
对于 C/C++ 程序员来说,数据结构和算法其实更为重要。为什么呢?因为对于其他的程序员来说,他们只需要学会一种编程思想就行了,要么是面向对象,要么是面向过程。但是对于 C/C++ 程序员来说,他们都要掌握,并且要能熟练运用
在学 C语言 的时候,我们将所有东西都看成是一个过程,敲代码都按照流程走,C语言 是面向过程的,不管是事还是物,都是以算法为主;到了 C++,我们发现是面向对象思维了,是以数据结构为主
算法其实是很繁杂的,任何的计算我们都可以将它归结到算法中,哪怕是 1 + 1 = 2
而数据结构,我们一般称之为管理数据的结构,本身无意义,但又不可或缺。举个例子,你到便利店去买一瓶水,这瓶水是用瓶子装着的,但是你并不是去买瓶子的,而瓶子又不能缺少
所以我们是需要东西去对数据进行管理,但是这样就会有一个问题,我们有多少种管理数据的方式呢?
管理数据的方式取决于数据本身的特性以及我们要对数据进行怎样的操作
接下来我们来聊聊数据本身的特性
| 数据特性 | 数据之间的关系 | 存储结构 |
|---|---|---|
| 离散 | 独立、没有关系 | 常量、变量、结构体、联合体、枚举 |
| 线性 | 一对一 | 数组、链表、栈、队列、线性表、顺序表 |
| 树 | 一对多 | 树、二叉树、有序二叉树、平衡二叉树、完全二叉树、23树、B、B+、RB树、哈夫曼树等等 |
| 图 | 多对多 |
还有 hash,可以说是一种数据结构,也可以说是一种算法
我们的数据结构与算法之旅就从顺序表开始了
博主所用开发工具 —— VS2013,当然,其他开发工具也可以
二、动态数组插入
下面我将带领你从 0 开始,去写一个标准模板库里面的容器 —— 手撕vector
那么什么是顺序表呢?
简单地说,顺序表就是数组,但是,数组的大小是固定的。一般我们说动态数组,说的就是顺序表了。而线性表,分为动态数组和链表两种
动态数组的实现其实很简单,为什么我们还要专门去学习它呢?
是因为我们做一个数据结构,我们简单实现肯定是不行的
向首地址中插入数据
#include "stdafx.h"
typedef int DATA_TYPE;
//顺序表
DATA_TYPE* pArr; //保存顺序表的首地址
size_t len; //顺序表元素个数
//顺序表初始化
void init();
//添加数据
//const & 传引用是为了不希望传参过程中产生临时对象
//const是限制函数中修改实参
void push_back(const DATA_TYPE& data);
int _tmain(int argc, _TCHAR* argv[])
{
init();
push_back(666);
while (1);
return 0;
}
void init(){
pArr = NULL;
len = 0;
}
void push_back(const DATA_TYPE& data){
//1. 开内存
DATA_TYPE* pNew = new DATA_TYPE;
//2. pArr指向新开内存
pArr = pNew;
//3. 数据进来,元素个数增长
pArr[len++] = data;
}
在主函数的 while (1); 这个语句打断点,接着运行程序,在调试菜单栏点击第一行的窗口,选择监视选项,鼠标双击首地址 pArr,将其拖到监视区域,接着查看其值,为 666,说明数据插入成功

向首地址中插入数据成功:
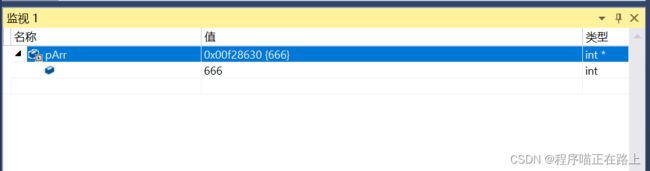
顺序表中元素是紧密相连的,也就是数组,但是它是动态的
如果我们想向下一个地址中插入数据,你觉得按照向首地址插入数据的方式,能成功吗?
实际上是不行的,这样做的话,当 pArr 指向另一块新开的内存后,刚才插入的数据 666 就会找不到了
那我们该怎么做呢?
思路:我们在开内存的时候,可以开一个存储两个数据的内存,然后先将原来的数据 666 拷贝进去,再插入新的数据
按照这样的思路,我们尝试对 push_back 函数进行改进,同时增加一个遍历顺序表的函数 travel:
#include "stdafx.h"
typedef int DATA_TYPE;
//顺序表
DATA_TYPE* pArr; //保存顺序表的首地址
size_t len; //顺序表元素个数
//顺序表初始化
void init();
//添加数据
//const & 传引用是为了不希望传参过程中产生临时对象
//const是限制函数中修改实参
void push_back(const DATA_TYPE& data);
//遍历顺序表
void travel();
int _tmain(int argc, _TCHAR* argv[])
{
init();
//push_back(666);
for (int i = 1; i < 12; i++){
push_back(i);
travel();
}
while (1);
return 0;
}
//顺序表初始化
void init(){
pArr = NULL;
len = 0;
}
//添加数据
void push_back(const DATA_TYPE& data){
if (NULL == pArr){
//1. 开内存
DATA_TYPE* pNew = new DATA_TYPE;
//2. pArr指向新开内存
pArr = pNew;
//3. 数据进来,元素个数增长
pArr[len++] = data;
}
else {
//1. 开内存
DATA_TYPE* pNew = new DATA_TYPE[len+1];
//2. 将pArr指向内存段中数据拷贝到pNew指向内存段
//内存拷贝,用循环效率太低
/*for (int i = 0; i < len; i++){
pNew[i] = pArr[i];
}*/
memcpy(pNew, pArr, sizeof(DATA_TYPE)*len);
//3. 释放pArr指向新开内存
delete[] pArr;
//4. pArr指向新开内存
pArr = pNew;
//5. 数据进来,元素个数增长
pArr[len++] = data;
}
}
//遍历顺序表
void travel(){
printf("pArr:");
for (int i = 0; i < len; i++)
printf("%d ", pArr[i]);
printf("\n");
}
数据插入成功:
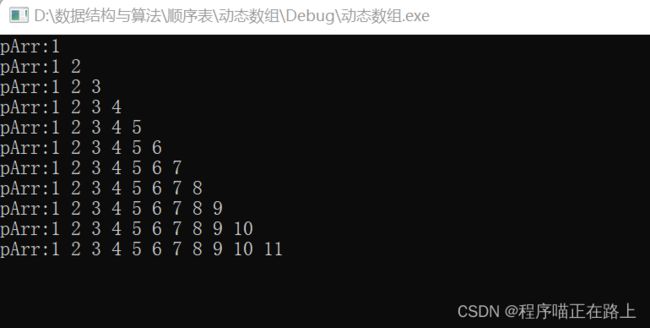
三、代码优化
我们可以发现,push_back() 函数里面的代码有些是重复的,所以应该进行优化
void push_back(const DATA_TYPE& data){
//1. 开内存
DATA_TYPE* pNew = new DATA_TYPE[len + 1];
if (pArr){
//2. 将pArr指向内存段中数据拷贝到pNew指向内存段
//内存拷贝,用循环效率太低
memcpy(pNew, pArr, sizeof(DATA_TYPE)*len);
//3. 释放pArr指向新开内存
delete[] pArr;
}
//4. pArr指向新开内存
pArr = pNew;
//5. 数据进来,元素个数增长
pArr[len++] = data;
}
四、删除第一个和最后一个
写完插入数据,接下来我们写一下怎么删除
有很多种删除方法,我们先来实现简单的,比如删除第一个、删除最后一个、删除中间的
我们先来将删除第一个的思路,新开一块大小为 len - 1 的内存,将 pArr 第 2 个到结尾的数据拷贝到新内存段中,再让 pArr 指向 pNew,删除 pArr,同时 len 减一,删除最后一个的思路相同
//删除第一个
void pop_front(){
if (NULL == pArr) return; //没有数据
if (1 == len){ //只有一个数据
delete[] pArr;
pArr = NULL;
len = 0;
return;
}
//1. 新开内存
DATA_TYPE* pNew = new DATA_TYPE[len - 1];
//2. 数据拷贝
memcpy(pNew, pArr + 1, sizeof(DATA_TYPE)*(len - 1));
//3. 释放原有内存段
delete[] pArr;
//4. pArr指向新开内存段
pArr = pNew;
//5. len减少
len--;
}
删除第一个成功:

//删除最后一个
void pop_back(){
if (NULL == pArr) return; //没有数据
if (1 == len){ //只有一个数据
delete[] pArr;
pArr = NULL;
len = 0;
return;
}
//1. 新开内存
DATA_TYPE* pNew = new DATA_TYPE[len - 1];
//2. 数据拷贝
memcpy(pNew, pArr + 0, sizeof(DATA_TYPE)*(len - 1));
//3. 释放原有内存段
delete[] pArr;
//4. pArr指向新开内存段
pArr = pNew;
//5. len减少
len--;
}
删除最后一个成功:
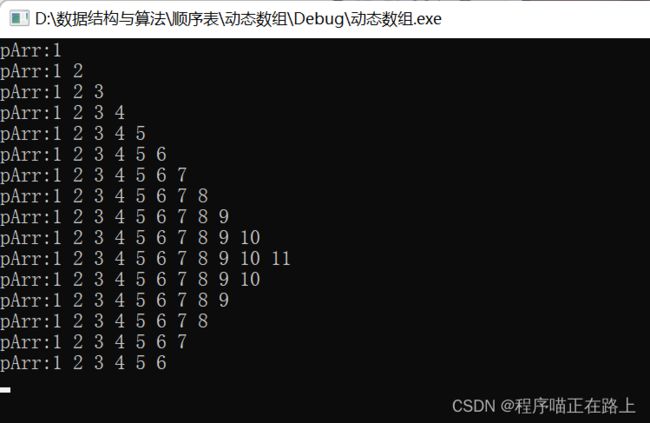
五、删除中间的
思路:开内存 ➔ 拷贝n前面的 ➔ 拷贝n后面的 ➔ 释放原有内存段 ➔ 原有内存段指向新开内存段 ➔ 长度减少
//删除下标为n的哪个
void delete_pos(size_t n){
if (NULL == pArr) return; //没有数据
if (n >= len) return;
if (0 == n){ //第一个
pop_front();
return;
}
if ((len - 1) == n){ //最后一个
pop_back();
return;
}
//n为中间的
//1. 新开内存
DATA_TYPE* pNew = new DATA_TYPE[len - 1];
//2. 数据拷贝
//先拷贝前面的
memcpy(pNew, pArr, sizeof(DATA_TYPE)*n);
//再拷贝后面的
memcpy(pNew + n, pArr + n + 1, sizeof(DATA_TYPE)*(len - n - 1));
//3. 释放原有内存段
delete[] pArr;
//4. pArr指向新开内存段
pArr = pNew;
//5. len减少
len--;
}

六、空间换时间
到这里,看上去我们是实现了一个顺序表,但是我们写一个数据结构,不仅仅是要去考虑它的功能,我们还要考虑两个东西 —— 性能和外观
前面我们只考虑了功能,而没有去考虑性能,而衡量代码的性能有两个标准:时间和空间
这个顺序表在空间层面上已经没办法优化了,但是在时间层面上还有很大的进步空间,比如程序每次插入数据都要开内存、拷贝,假如我们要保存 100000 个数据的话,那就得开 100000 次内存,这是很耗时间的,所以我们必须解决这个问题 —— 就是用空间来换时间
最好的解决方案就是 —— 每次需要申请内存的时候,申请当前内存大小的 1.5 倍,也就是 len 的 1.5 倍。需要特别注意的是,当前内存为 0 时,申请内存应该为 len + 1,而不是 len 的 1.5 倍
七、空间换时间代码实现
这里我们只对插入数据的函数进行改进,其他依样画葫芦即可
#include "stdafx.h"
typedef int DATA_TYPE;
//顺序表
DATA_TYPE* pArr; //保存顺序表的首地址
size_t len; //顺序表元素个数
size_t capacity; //当前容量
//顺序表初始化
void init();
//添加数据
//const & 传引用是为了不希望传参过程中产生临时对象
//const是限制函数中修改实参
void push_back(const DATA_TYPE& data);
//遍历顺序表
void travel();
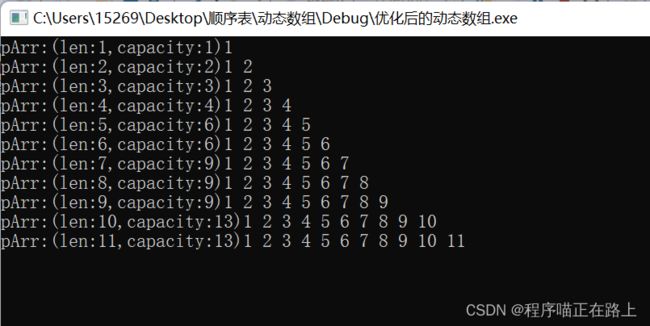
int _tmain(int argc, _TCHAR* argv[])
{
init();
//测试push_back
for (int i = 1; i < 12; i++){
push_back(i);
travel();
}
while (1);
return 0;
}
//顺序表初始化
void init(){
pArr = NULL;
capacity = len = 0;
}
//添加数据
void push_back(const DATA_TYPE& data){
//判断是否需要申请内存
if (capacity <= len){ //需要申请
//计算需要申请的内存大小
capacity += (((capacity >> 1) > 1) ? (capacity >> 1) : 1);
//1. 开内存
DATA_TYPE* pNew = new DATA_TYPE[capacity];
if (pArr){
//2. 将pArr指向内存段中数据拷贝到pNew指向内存段
//内存拷贝,用循环效率太低
memcpy(pNew, pArr, sizeof(DATA_TYPE)*len);
//3. 释放pArr指向新开内存
delete[] pArr;
}
//4. pArr指向新开内存
pArr = pNew;
}
//不需要申请内存的话直接存储数据
//5. 数据进来,元素个数增长
pArr[len++] = data;
}
//遍历顺序表
void travel(){
printf("pArr:(len:%d,capacity:%d)", len, capacity);
for (int i = 0; i < len; i++){
printf("%d ", pArr[i]);
}
printf("\n");
}
八、类封装
你以为优化了程序的运行时间后,就结束了吗?并没有,我们还可以用类将其封装起来
res.h
typedef int DATA_TYPE;
MyVector.h
#pragma once
#include "res.h"
#include MyVector.cpp
#include "MyVector.h"
MyVector::MyVector()
{
pArr = NULL;
capacity = len = 0;
}
MyVector::~MyVector()
{
if (pArr){
delete[] pArr;
}
pArr = NULL;
capacity = len = 0;
}
//添加数据
void MyVector::push_back(const DATA_TYPE& data){
//判断是否需要申请内存
if (capacity <= len){ //需要申请
//计算需要申请的内存大小
capacity += (((capacity >> 1) > 1) ? (capacity >> 1) : 1);
//1. 开内存
DATA_TYPE* pNew = new DATA_TYPE[capacity];
if (pArr){
//2. 将pArr指向内存段中数据拷贝到pNew指向内存段
//内存拷贝,用循环效率太低
memcpy(pNew, pArr, sizeof(DATA_TYPE)*len);
//3. 释放pArr指向新开内存
delete[] pArr;
}
//4. pArr指向新开内存
pArr = pNew;
}
//不需要申请内存的话直接存储数据
//5. 数据进来,元素个数增长
pArr[len++] = data;
}
//遍历顺序表
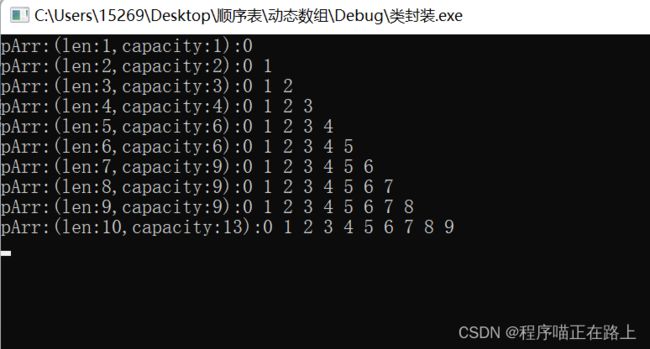
void MyVector::travel(){
cout << "pArr:(len:" << len << "," << "capacity:" << capacity << "):";
for (int i = 0; i < len; i++){
cout<<pArr[i]<<" ";
}
cout << endl;
}
test.cpp
#include "MyVector.h"
int main()
{
MyVector v;
for (int i = 0; i < 10; i++){
v.push_back(i);
v.travel();
}
while (1);
return 0;
}
类封装的好处就是,别人把代码拿过去就能使用,不用再修改,同时更安全一些
九、类模板封装
MyVector.h
#pragma once
#include test.cpp
#include "MyVector.h"
int main()
{
MyVector<int> vInt;
MyVector<double> vDouble;
for (int i = 0; i < 10; i++){
vInt.push_back(i);
vInt.travel();
}
for (int i = 0; i < 10; i++){
vDouble.push_back(i + 0.6);
vDouble.travel();
}
while (1);
return 0;
}

添加一个 MyPoint 类试试看
MyPoint.h
#pragma once
#include MyPoint.cpp
#include "MyPoint.h"
MyPoint::MyPoint()
{
x = y = 0;
}
MyPoint::MyPoint(int x, int y){
this->x = x;
this->y = y;
}
MyPoint::~MyPoint()
{
}
ostream& operator << (ostream& o, const MyPoint& p){
return o << "(" << p.x << "," << p.y << ")";
}
测试一下
test.cpp
#include "MyVector.h"
#include "MyPoint.h"
int main()
{
MyVector<int> vInt;
MyVector<double> vDouble;
for (int i = 0; i < 10; i++){
vInt.push_back(i);
vInt.travel();
}
for (int i = 0; i < 10; i++){
vDouble.push_back(i + 0.6);
vDouble.travel();
}
MyVector<MyPoint> vPoint;
for (int i = 0; i < 10; i++){
MyPoint p(i, i+3);
vPoint.push_back(p);
vPoint.travel();
}
while (1);
return 0;
}

写到这里,我只想说一句:太强了吧
顺序表的介绍到这里就结束了,你,学会了吗
下期预告:链表