c++使用Trie 树实现动态路由(dynamic route)
文章目录
- 前言
- 一、为什么可以使用前缀树来实现动态路由
- 二、动态路由规则
- 三、前缀树的构建
- 四、路由Router
- 五、测试
- 六、与正则化实现的动态路由进行性能比较
-
- 正则
- 前缀树
前言
**所谓动态路由,**即一条路由规则可以匹配某一类型而非某一条固定的路由。例如/hello/:name,可以匹配/hello/geektutu、hello/jack等。
动态路由有很多种实现方式,支持的规则、性能等有很大的差异。例如开源的路由实现httplib支持在路由规则中嵌入正则表达式,例如/p/[0-9A-Za-z]+,即路径中的参数仅匹配数字和字母;
前缀树作为一种高效的数据结构,可以快速进行前缀匹配,逐级匹配字符,从而实现动态路由的灵活性和高性能。相比之下,使用正则表达式进行动态路由匹配可能会引入更复杂的模式匹配和性能开销,不如前缀树简洁高效。
对于动态路由中的参数匹配,使用前缀树可以更灵活地处理不同类型的参数。前缀树可以支持在节点中存储参数信息,
因此,前缀树在实现动态路由时具有必要性,并能够满足灵活的路由匹配需求。
一、为什么可以使用前缀树来实现动态路由
**实现动态路由最常用的数据结构,被称为前缀树(Trie树)。**看到名字你大概也能知道前缀树长啥样了:每一个节点的所有的子节点都拥有相同的前缀。这种结构非常适用于路由匹配。
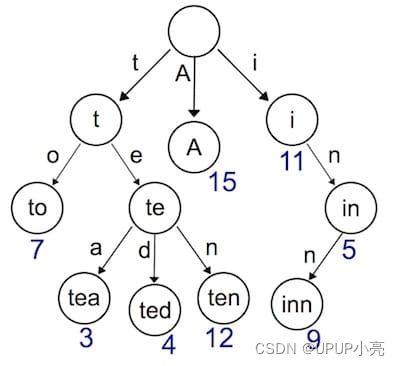
使用前缀树实现动态路由的优点如下:
前缀匹配:前缀树的一个重要特性是可以进行前缀匹配。在路由查找中,可以使用前缀树找到最长匹配的前缀,从而确定应该采取哪个路由。这对于路由的选择和路由表的压缩都是非常有用的。
高效的查找:前缀树可以在O(m)的时间复杂度内查找到匹配给定前缀的节点,其中m是前缀的长度。这使得路由查找非常快速,无论路由表的大小如何。
动态更新:前缀树支持动态更新,可以方便地插入、删除或修改节点。这意味着在路由表发生变化时,可以快速地更新前缀树,而不需要重新构建整个路由表。
相比于使用正则表达式实现动态路由,使用前缀树(Trie树)的方式具有以下几个优势:
**简化的路由规则:**使用前缀树,路由规则可以更加简化和直观。每个节点代表一个字符或字符序列,可以直接映射到相应的路由路径。相比之下,使用正则表达式实现动态路由可能需要编写更复杂的模式匹配规则,难以直观地表示路由结构。
**更好的可读性和可维护性:**前缀树的结构更易于理解和维护。路由规则以树的形式展示,可以清晰地表示路由层次和结构。这使得代码更易于阅读、理解和调试,也方便进行路由的添加、删除和修改操作。
**灵活的路由匹配:**前缀树支持多种灵活的路由匹配方式,如通配符匹配、参数化路由等。这使得在路由规则中引入一些灵活性变得更加容易,而在正则表达式中可能需要更复杂的模式匹配。
**参数提取:**上述方法通过将路由模式中的冒号后的字符串作为参数名,将路径中对应位置的实际值提取出来。而正则表达式路由可以使用具有捕获组的正则表达式来直接提取参数值,不需要手动解析路径。
性能:基于前缀树的路由匹配在大规模路由规则和高并发请求的情况下性能较好,因为它使用了数据结构来加速匹配过程。而正则表达式匹配相对较慢,特别是在复杂的正则表达式模式和大量请求的情况下。
二、动态路由规则
实现动态路由最常用的数据结构,被称为前缀树(Trie树)。看到名字你大概也能知道前缀树长啥样了:每一个节点的所有的子节点都拥有相同的前缀。这种结构非常适用于路由匹配,比如我们定义了如下路由规则:
/:lang/doc
/:lang/tutorial
/:lang/intro
/about
/p/blog
/p/related
HTTP请求的路径恰好是由/分隔的多段构成的,因此,每一段可以作为前缀树的一个节点。我们通过树结构查询,如果中间某一层的节点都不满足条件,那么就说明没有匹配到的路由,查询结束。
接下来我们实现的动态路由具备以下两个功能。
参数匹配:。例如 /p/:lang/doc,可以匹配 /p/c/doc 和 /p/go/doc。
通配*。例如 /static/*filepath,可以匹配/static/fav.ico,也可以匹配/static/js/jQuery.js,这种模式常用于静态服务器,能够递归地匹配子路径。
三、前缀树的构建
类实现思路:
通过构建一个路由树来实现路由匹配。路由树是一个多叉树,每个节点代表一个路径的一部分。根节点表示空路径,每个子节点表示一个路径的部分。通过在树中插入模式,可以构建一个完整的路由树。
在插入模式时,根据路径的部分将模式插入到合适的节点中。如果节点不存在,则创建一个新节点,并将其添加到父节点的子节点列表中。如果路径的部分是通配符(以":“或”*"开头),则将iswild标志设置为true。
在搜索时,根据路径的部分逐级向下搜索匹配的节点。如果节点的部分路径与给定部分路径匹配,或者节点是通配符节点,则继续向下搜索。如果找到与路径完全匹配的节点,则返回该节点。如果没有找到匹配的节点,则返回nullptr。
class Node {
private:
string pattern;
string part;
vector<Node*> children;
bool iswild;
public:
Node(string part, bool iswild = false) {
this->part = part;
this->iswild = iswild;
}
string getPattern() const {
return pattern;
}
void setPattern(const string& pattern) {
this->pattern = pattern;
}
string getPart() const {
return part;
}
bool isWild() const {
return iswild;
}
成员变量:
**pattern:**存储该节点对应的路由模式,仅叶子节点才会存储具体的路由模式。
**part:**存储该节点的字符或字符序列,代表路径中的一部分。
**children:**存储该节点的子节点列表。
**iswild:*标识该节点是否是通配符节点(如参数化路由中的:或通配符路由中的)。
Node* matchChild(const string& part) const {
for (Node* child : children) {
if (child->getPart() == part || child->isWild()) {
return child;
}
}
return nullptr;
}
这个函数用于在当前节点的子节点列表中匹配指定的字符或字符序列 part。它遍历当前节点的子节点列表,对于每个子节点,检查其存储的字符或字符序列是否与 part 相等,或者该子节点是否为通配符节点(使用 isWild() 方法判断)。如果找到匹配的子节点,则返回该子节点指针;如果没有找到匹配的子节点,则返回 nullptr。
vector<Node*> matchChildren(const string& part) const {
vector<Node*> nodes;
for (Node* child : children) {
if (child->getPart() == part || child->isWild()) {
nodes.push_back(child);
}
}
return nodes;
}
这个函数用于在当前节点的子节点列表中匹配指定的字符或字符序列 part,并返回匹配到的所有子节点。它遍历当前节点的子节点列表,对于每个子节点,检查其存储的字符或字符序列是否与 part 相等,或者该子节点是否为通配符节点。如果找到匹配的子节点,则将该子节点添加到 nodes 向量中。最后,返回包含所有匹配子节点的向量。
void insert(const string& pattern, const vector<string>& parts, int height) {
if (parts.size() == height) {
setPattern(pattern);
return;
}
string part = parts[height];
Node* child = matchChild(part);
if (child == nullptr) {
child = new Node(part, part[0] == ':' || part[0] == '*');
children.push_back(child);
}
child->insert(pattern, parts, height + 1);
}
这个函数用于向前缀树中插入路由模式和路径部分。它接受一个路由模式 pattern、路径部分的字符串向量 parts,以及当前路径部分的高度 height。如果当前路径部分已经达到了最后(parts 的大小等于 height),则将当前节点的路由模式设置为 pattern。否则,获取当前路径部分的字符串 part,并调用 matchChild() 方法来匹配子节点。如果没有找到匹配的子节点,则创建一个新的子节点,并根据 part 的首字符是否为 ':' 或 '*' 来确定该子节点是否为通配符节点。最后,递归调用 insert() 方法,将剩余的路由模式和路径部分插入到子节点中,同时将高度增加1。
Node* search(const vector<string>& parts, int height) {
if (parts.size() == height || getPart()[0] == '*') {
if (getPattern().empty()) {
return nullptr;
}
return this;
}
string part = parts[height];
vector<Node*> matchedChildren = matchChildren(part);
for (Node* child : matchedChildren) {
Node* result = child->search(parts, height + 1);
if (result != nullptr) {
return result;
}
}
return nullptr;
}
这个函数用于在前缀树中搜索与给定路径部分匹配的节点。它接受一个路径部分的字符串向量 parts,以及当前路径部分的高度 height。首先,检查当前路径部分的高度是否已经达到了最后(parts 的大小等于 height),或者当前节点的路径部分的首字符是否为 '*'(通配符节点)。如果当前节点的路由模式为空,说明该节点不是一个完整的路由,返回 nullptr;否则,返回当前节点指针。
如果续上:
当前节点不满足上述条件,则获取当前路径部分的字符串 part,然后调用 matchChildren() 方法来获取与 part 匹配的子节点列表。然后,对于每个匹配的子节点,递归调用 search() 方法,将剩余的路径部分和高度加一作为参数传递给子节点的 search() 方法。如果子节点返回的结果不为空,则说明找到了匹配的节点,直接返回该结果。
如果遍历完所有的匹配子节点后仍然没有找到匹配的节点,则返回 nullptr,表示没有找到与给定路径部分匹配的节点。
四、路由Router
using Handler = std::function<void(const string &, string &)>;
定义了一个函数类型 Handler,该类型接受两个参数,一个是 const string& 类型的请求字符串,另一个是 string& 类型的响应字符串。模拟响应类与请求类
class Router {
private:
std::unordered_map<std::string, Node*> roots;
std::unordered_map<std::string, Handler> handlers;
// ...
public:
Router() {}
// ...
};
这个类 Router 用于管理路由和处理请求。它包含了两个私有成员变量:roots 和 handlers。roots 是一个无序映射,用于存储不同请求方法(如 GET、POST)的根节点,每个根节点都是一个 Node 类型的指针。handlers 是一个无序映射,用于存储路由处理函数,其中键是请求方法和路由模式的组合,值是对应的处理函数。
std::vector<std::string> parsePattern(const std::string& pattern) {
std::vector<std::string> parts;
std::istringstream iss(pattern);
std::string item;
while (std::getline(iss, item, '/')) {
if (!item.empty()) {
parts.push_back(item);
if (item[0] == '*') {
break;
}
}
}
return parts;
}
这个函数用于解析路由模式,将其拆分为路径部分的字符串向量。它接受一个路由模式的字符串 pattern,然后使用 std::istringstream 将 pattern 按照 / 进行拆分。每个非空的拆分部分被添加到 parts 向量中。如果遇到以 '*' 开头的部分,则停止拆分,将其作为最后一个部分添加到 parts 向量中。最后,返回拆分后的路径部分的字符串向量。
std::string join(const std::vector<std::string>& parts, size_t start, const std::string& delimiter) {
std::string result;
for (size_t i = start; i < parts.size(); i++) {
result += parts[i];
if (i != parts.size() - 1) {
result += delimiter;
}
}
return result;
}
这个函数用于将路径部分的字符串向量连接为一个字符串。它接受一个路径部分的字符串向量 parts,一个起始索引 start,和一个连接符 delimiter。从 start 索引开始,将 parts 向量中的字符串依次连接起来,并使用 delimiter 进行分隔。返回连接后的字符串。
void addRoute(const std::string& method, const std::string& pattern, Handler handler) {
std::vector<std::string> parts = parsePattern(pattern);
std::string key = method + "-" + pattern;
if (roots.find(method) == roots.end()) {
roots[method] = new Node("", false);
}
roots[method]->insert(pattern, parts, 0);
handlers[key] = std::move(handler);
}
这个函数用于向路由中添加新的路由规则。它接受一个请求方法 method、一个路由模式 pattern 和一个处理函数 handler。首先,通过调用 parsePattern() 函数解析 pattern,得到路径部分的字符串向量 parts。然后,将 method 和 pattern 组合成一个唯一的键 key。接下来,检查 roots 中是否存在与 method 相对应的根节点,如果不存在,则创建一个新的根节点并插入到 roots 中。然后,调用根节点的 insert() 方法,将路由模式和路径部分插入到根节点的前缀树中。最后,将键 key 和处理函数 handler 存储到 handlers 中。
std::pair<Node*, std::map<std::string, std::string>> getRoute(const std::string& method, const std::string& path) {
std::vector<std::string> searchParts = parsePattern(path);
std::map<std::string, std::string> params;
auto it = roots.find(method);
if (it == roots.end()) {
return { nullptr, params };
}
Node* root = it->second;
Node* n = root->search(searchParts, 0);
if (n != nullptr) {
std::vector<std::string> parts = parsePattern(n->getPattern());
for (size_t i = 0; i < parts.size(); i++) {
if (parts[i][0] == ':') {
params[parts[i].substr(1)] = searchParts[i];
}
if (parts[i][0] == '*' && parts[i].length() > 1) {
params[parts[i].substr(1)] = join(searchParts, i, "/");
break;
}
}
return { n, params };
}
return { nullptr, params };
}
这个函数用于根据请求方法和路径查找匹配的路由规则。它接受一个请求方法 method 和一个路径 path。首先,调用 parsePattern() 函数解析 path,得到路径部分的字符串向量 searchParts。然后,通过查找 roots 中与 method 对应的根节点,获取根节点的指针 root。接下来,调用根节点的 search() 方法,根据 searchParts 在前缀树中查找匹配的节点,并返回该节点的指针 n。如果找到了匹配的节点,将其路由模式再次解析为路径部分的字符串向量 parts。然后,遍历 parts,如果某个部分以 ':' 开头,将其作为参数名,与 searchParts 中对应位置的字符串建立映射并存储到 params 中。如果某个部分以 '*' 开头且长度大于1,将其作为通配符参数名,将 searchParts 中从当前位置开始到最后的路径部分连接起来作为参数值,并存储到 params 中。最后,返回匹配的节点指针 n 和参数映射 params。
inline bool dispatch_request(const string &req, string &res,const std::string& method, const std::string& path) {
auto route = getRoute(method, path);
if (route.first != nullptr) {
string path=method+'-'+route.first->getPattern();
std::cout << "path:" <<path<< std::endl;
for (const auto& param : route.second) {
std::cout << param.first << ": " << param.second << std::endl;
}
auto it = handlers.find(path);
if (it != handlers.end()) {
// 调用处理函数处理请求
it->second(req, res);
} else {
cout<<" 404 not found"<<endl;
}
} else {
cout<<" 404 not found"<<endl;
}
}
这个函数用于调度请求,根据请求方法和路径查找匹配的路由规则,并调用对应的处理函数处理请求。它接受一个请求字符串 req、一个响应字符串 res、一个请求方法 method 和一个路径 path。首先,调用 getRoute() 函数查找匹配的路由规则,并返回匹配的节点指针和参数映射。如果找到了匹配的节点,将请求方法和路由模式组合成一个唯一的路径 path,并打印路径和参数信息。然后,在 handlers 中查找对应的处理函数,并调用该函数处理请求,传递请求字符串 req 和响应字符串 res。如果未找到对应的处理函数,则打印 “404 not found”。如果没有找到匹配的节点,则同样打印 “404 not found”。
五、测试
中创建了一个名为 router 的 Router 实例,并向其添加了一个路由规则。该路由规则使用 POST 请求方法和 /dhy/:age/:name/asd 路径模式,并定义了一个处理函数,该处理函数在调用时会输出一些信息。
int main() {
Router router;
router.addRoute("POST", "/dhy/:age/:name/asd", [](const string& req, string& resp) {
cout << "//" << endl;
cout << " do handle" << endl;
/ req.get_param("");
});
string res;
string req;
router.dispatch_request(req,res,"POST", "/dhy/123/hhh/asd");
return 0;
}
结果如下

六、与正则化实现的动态路由进行性能比较
正则
// 注册路由处理程序
Post("/products/(\\w+)/(\\w+)/asd/(\\w+)/(\\w+)/(\\w+)", [](const string& req, string& resp) {
cout << " do handle" << endl;
/ req.get_param("");
});
string request ;
string response;
// 调度请求并处理
auto start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < 1000000; ++i) {
dispatch_request(request, response, "/products/123/hhh/asd/asf/asd/afad", post_handlers_);
}
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);
std::cout << "总共使用的时间:" << duration.count() << " 毫秒" << std::endl;
匹配100万次一共用时34秒左右
![]()
前缀树
Router router;
router.addRoute("POST", "/products/:age/:name/asd", [](const string& req, string& resp) {
// cout << "//" << endl;
cout << " do handle" << endl;
/ req.get_param("");
});
string res;
string req;
auto start = std::chrono::high_resolution_clock::now();
for (int i = 0; i < 1000000; ++i) {
router.dispatch_request2(req, res, "POST", "/products/123/hhh/asd");
}
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);
std::cout << "总共使用的时间:" << duration.count() << " 毫秒" << std::endl;
![]()
基于前缀树的路由匹配在大规模路由规则和高并发请求的情况下性能较好,因为它使用了数据结构来加速匹配过程。而正则表达式匹配相对较慢,特别是在复杂的正则表达式模式和大量请求的情况下。