Redis集群(读写分离、哨兵机制、Cluster集群)
文章目录
-
- 概念概述
-
- 一、主从复制
-
- 原理
- 优点
- 缺点
- 同步原理
- 二、哨兵(Sentinel)机制
-
- 原理
- 哨兵的三大工作任务
- 优点
- 缺点
- 三、Redis内置集群(Cluster模式)
-
- 原理
- 集群搭建(实践出真知嘛,加油!朋友们)
-
- 需要的环境
- 主从复制模式搭建
- 哨兵机制集群搭建
- 内置集群搭建(Cluster集群)
- Cluster集群维护
-
- 分片重哈希
- 移除节点
- 添加节点
概念概述
- 首先我们要知道的是,Redis实际上有三种集群方案:
主从复制模式、哨兵机制(又称为Sentinel模式)、集群模式(又称为Cluster模式) - 其次我们得知道为什么需要集群模式
实际上,单机Redis的读写速度非常快,可以支持大量用户的访问,虽然Redis的性能很高,但是对于大型网站来说,每秒钟所需要获取的数据远远超过单台redis服务所能承受的压力
所以我们需要一种方案来解决单台Redis服务性能不足的问题
一、主从复制
原理
- 主从复制方案:对读写能力扩展,采用读写分离的方式解决性能瓶颈。
- 即运行一个新的服务器(简称为从服务器),从服务器与主服务器进行连接,然后主服务器发送数据副本,从服务器通过网络根据主服务器的数据副本进行准实时更新(具体的更新速度取决于网络带宽),主服务器可以进行读写操作,当写操作导致数据发生变化时会自动将数据同步给从数据库。而从数据库一般是只读的,并接受主数据库同步过来的数据。
- !!注意,一个主服务器可以有多个从服务器,但一个从服务器只能有一个主服务器。这就像一个老大可以有很多小弟,但一个小弟不能同时跟多个老大一样。
- 这样我们就有额外的从服务器来处理读请求,通过将读请求分散到不同的从服务器上面进行处理,用户可以从新添加的从服务器上获得额外的读查询处理能力
- 并且Redis通过持久化功能,保证了即使服务器宕机或重启的情况下也不会丢失数据,因为持久化会把内存中的数据保存到硬盘上,重启会从硬盘上加载数据。
优点
- 主从复制,主机会自动将数据同步到从机,实现了读写分离
- 从服务器提供只读操作,主服务器提供读读写操作
- 从服务器同样可以接受其他从服务器的连接和同步请求,这样可以有效的分载主服务器的同步压力
- 主服务器是以非阻塞的方式为从服务器提供服务,所以在主从同步期间,客户端依然可以提交查询或修改请求
- 从服务器也是以非阻塞的方式完成数据同步的,在同步期间,如果有客户端提供查询请求,Redis则返回同步之前的数据
缺点
- Redis不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或手动切换前端的IP才能恢复(即人工介入)
- 主机宕机后如果有部分数据没有及时同步到从机,更换主机IP后会导致数据不一致的问题
- 如果多个从机断线,需要重启的时候,如果在同一时间段进行重启,多个slave重启,都会发送sync请求并进行主机全量同步,那就会导致主机 IO剧增从而主机宕机
- Redis较难支持在线扩容,在集群容量达到上限时在线扩容就会变得艰难
同步原理
redis2.8之前使用的是sync同步命令,redis2.8之后使用的是psync命令
两者的不同在于:sync仅支持全量复制过程,psync支持全量和部分复制
- 更改命令的原因在于,如果服务器在主从复制的过程中出现了断线,重连之后需要全量同步一次,但如果断线时间非常短,可能会出现主从之间数据还是一致的,简单的进行了全量同步,就造成了主从服务器之间cpu,内存,网络带宽方面的浪费
- 使用psync命令,对于服务器断线重连主服务器这种情景,从服务器重连之后,发送psync命令给主服务器,主服务器会根据该从服务器的同步情况,决定是只需将断线期间的写入同步给该服务器,还是需要进行全量同步
因为本文重点不是这个,所以具体的PYSNC核心设计改日再写,
二、哨兵(Sentinel)机制
原理
- 主从复制这种同步模式,只有一个节点,那么当该主节点宕机后,需要手动切换从服务器为主服务器,这就造成不但需要人工干预,还会造成一段时间内的服务不可用,哨兵机制的集群模式就可以有效的改善这个问题
- 用能听的懂的话来说,就是用一个哨兵来监控所有的服务器状态,一旦发现某个主服务器宕机或故障了,就自动让从服务器顶上去
- 哨兵是一个独立的进程,会独立运行,哨兵进程通过发送命令,让Redis服务器返回监控其运行状态,包括主服务器和从服务器
当哨兵进程检测到某个主机宕机后,会自动将slave切换为master,然后通过发布订阅模式同之其他从服务器,修改配置文件,让他们切换主机 - 那么哨兵是知晓服务器是否下线呢,主要分为主观下线和客观下线
主观下线(SDOWN): 就是说单个哨兵对服务器做出的下线判断,我愿称之为”君主式哨兵”,也就是王说你下线了,你就是下线了
如果一个服务器没有在master-down-after-milliseconds选项所指定的时间内,对向它发送PING命令的哨兵返回一个有效的回复,那么哨兵就会将这个服务器标记为主观下线
客观下线(ODOWN): 客观下线的评判由多个哨兵完成,我称之为"民主式哨兵“,也就是说一个主机是否下线,由多个哨兵投票完成,当多个哨兵说该主机下线了,那么它就是下线了
从主观下线切换为客观下线状态使用的不是法定人数算法,而是流言传播,即如果哨兵在给定范围内,从其他哨兵那里接收到了足够数量的主服务器下线报告,那么哨兵就会将主服务器的状态从主观下线切换为客观下线
PS:客观下线只适用于主服务器,对于其他类型的Redis实例,哨兵在将它们判断为下线前不需要进行协商,所以从服务器或其他哨兵不会达到客观下线条件。
并且只要一个哨兵发现了某个主服务器进入了客观下线状态,那么这个哨兵就可能会被其他哨兵推选出,并对失效的服务器执行自动故障迁移操作。 - 当然下线状态的标记是可以被去除的,如果没有足够的哨兵进程同意主服务器下线,那么主服务器的客观下线状态标记就会被移除
如果主服务器重新向哨兵发送的PING命令返回了有效的回复,主服务器的主观下线状态就会被移除
哨兵的三大工作任务
- 其实在上述原理中已经讲过了,只是这里更精简一点
- 监控(Monitoring): 哨兵会不断检查主服务器和从服务以及其他哨兵是否运作正常
- 提醒(Notification): 当被监控的某个服务器出现问题时,哨兵可以通过API向管理员或其他应用程序发送通知
- 自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时,哨兵会开始一次自动故障转移操作,它会将失效的主服务器的其中一个从服务器升级为新的主服务器,并让失效的主服务器的其他从服务器知晓新的主服务器。
当客户端试图连接失效的主服务器时,集群也会向客户端返回新主服务器的地址,使得集群可以使用新主服务器代替失效服务器。
优点
- 从上文可以看出,哨兵机制集群模式是基于主从复制模式的,所以它有主从复制的所有优点
- 主从服务器可以自动切换,系统更加健壮,可用性更高
缺点
- Redis较难支持在线扩容,在集群容量达到上限时在线扩容就会变得很复杂
三、Redis内置集群(Cluster模式)
原理
- Redis Cluster是一种服务器Sharding技术,3.0版本开始正式提供
- 哨兵机制的集群已经基本可以实现高可用,读写分离,但是在这种模式下,每台Redis服务器都存储了相同的数据,非常浪费内存,所以在Redis3.0上加入了Cluster集群模式,实现了Redis的分布式存储,即每台Redis节点上存储了不同的内容
- 以下是原理图(图源网络)

解释一下,上图中每一个蓝色圆圈代表着一个Redis的服务器节点,可以看到的是,任意两个节点之间都是相互连通的(采用的是PING-PONG机制),内部使用二进制协议优化传输速度和带宽。客户端可以与任意一个节点相连,然后就可以访问集群中的任何一个节点。对其进行存取和其他操作 - Redis集群使用的是哈希槽的概念,Redis集群有16384个哈希槽,每个Key通过CRC16校验后对16384取模来决定放置在那个槽。集群中的每个节点负责一部分的hash槽,意思是无论有多少个节点,都只有16384个槽来分。
- 使用这种架构很容易添加或删除节点,比如如果想删除某个节点,那么就将该节点的槽移动到其他节点上,然后将没有任何槽的节点移除
- 同时为了保证高可用,Redis-Cluster集群引入了主从复制模型,一个主节点对应一个或多个从节点,当主节点宕机后,就会启用从节点
- 对于主机的宕机判断,采用的是投票方式,当其它主节点ping一个主节点时,如果半数以上的主节点与A通信超时,那么就认为该主节点宕机了,为了得出投票结果,主节点个数一般是奇数。
集群搭建(实践出真知嘛,加油!朋友们)
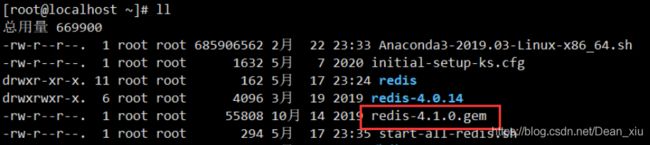
需要的环境
- redis-4.0.14
- redis-4.1.0.gem
- Centos7
主从复制模式搭建
-
Redis已经发现了读写分离这个场景的普遍性,所以自身集成了读写分离供用户使用,我们只需要在redis的配置文件里面加上一条slaveof host port语句进行配置即可。
-
之前已经在Centos里安装了redis了,所以我们直接开始搭建配置
1、停止运行的Redis
查找正在运行的redis服务
ps -ef | grep redis
在redis的bin目录下停止对应端口的redis服务
./redis-cli -h 127.0.0.1 -p 6379 shutdown

2、删除bin文件夹下的数据文件,并修改bin文件名为bin7001,同时更改bin7001中的redis.conf文件
首先我们看一下bin文件夹下的内容
其次删除数据文件
rm -rf appendonly.aof dump.rdb

更改文件夹名称后,修改redis.conf文件
(这里使用的是idea进行更改文件,之前的文章里也有过介绍)

更改成功后如下

3、修改bin文件夹为bin7001,并复制为一个bin7002
复制文件夹

修改bin7002的文件夹的redis.conf
port 7002
slaveof 192.168.100.129 7001


4、分别启动7001和7002
以下显示7001的启动过程,7002是一样的,记得7002再开一个Xhsell界面进行连接

可以通过如下命令可以看到启动的redis服务

启动服务器后,还需要启动客户端,才可以进行数据操作
-p 后的参数是redis服务所对应的端口号

5、置入数值看一下
这里我们看到7001是主节点,7002是从节点,也就是说如果在主节点里放入值,就可以在从节点中查到
当我们尝试在7002节点中放入值时就会报错

但是如果在7001放入值就不会出现这种错误


这就实现了读写分离
6、一个主节点可以有多个节点
所以我们再复制一个bin7003,并删除复制的数据文件,方便它生成自己的数据文件

记得更改端口号

因为是复制的7002,所以redis.conf中已经有,说明7003是7001的从节点
slaveof 192.168.100.129 7001
启动7003服务
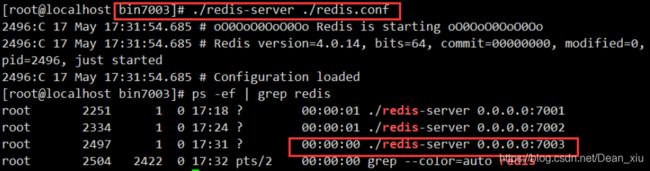
可以看到7003中可以获得7001中的值
ps:可以使用info命令查看当前节点的信息
如下是7003的信息,可以看到是从节点
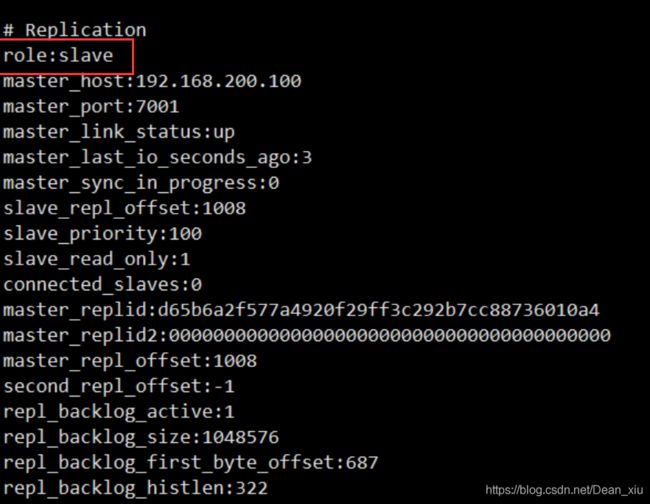
高可用演示
高可用是分布式系统架构中必须考虑的因素之一,它可以减少系统所不能提供服务的时间。我理解它为如果一个挂掉了,还有其他的来自动补位,减少系统的宕机时间。
保证高可用通常遵循以下几点:
单点是系统高可用最大的敌人,在系统设计中应该避免单点
通过架构设计而保证系统高可用的核心准则是冗余
每次出现故障时需要人工介入恢复,会增加系统的不不可用时间,实现自动故障转移
我们将7001主节点手动停止

进入从节点使用info查看状态,可以看到主节点宕机
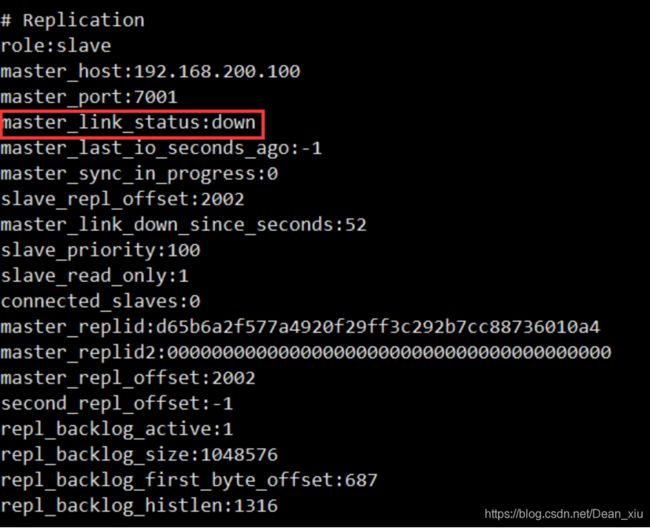
然后我们通过命令slaveof no one将7002升级主节点
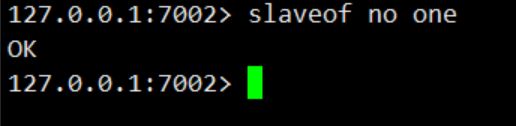
使用info可以看到7002节点状态

可以看到当前节点无从节点,这是因为7003还不知道主节点成为了7002,那我们限制告诉它

查看状态

主节点升级后我们进行数据置入,看看效果
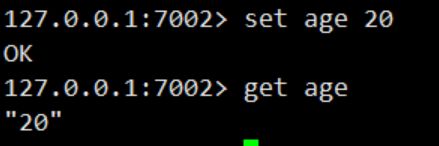
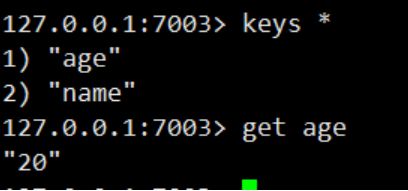
哨兵机制集群搭建
1、复制哨兵机制的配置文件并进行更改
在redis解压包解压后的文件中找到哨兵机制的配置文件
进入到redis文件夹中,将sentinel.conf配置文件复制到该文件夹
更改sentinel.conf文件中的如下字段
bind 0.0.0.0
# 设定主节点名和地址,1 为失效的投票数
sentinel monitor mymaster 192.168.200.129 7001 1
# 设置Sentinel认为服务器已经断线所需的毫秒数。
sentinel down-after-milliseconds mymaster 10000
# 设置failover(故障转移)的过期时间。当failover开始后,在此时间内仍然没有触发任何failoer操作,当前sentinel 会认为此次failoer失败。
sentinel failover-timeout mymaster 60000
# 设置在执行故障转移时, 最多可以有多少个从服务器同时对新的主服务器进行同步
sentinel parallel-syncs mymaster 1
2、关闭所有redis服务并重新启动redis服务,同时启动sentinel
进入到最原始的文件夹的src,即redis-4.0.14解压后的文件夹
![]()

redis-sentinel就是哨兵服务,然后启动
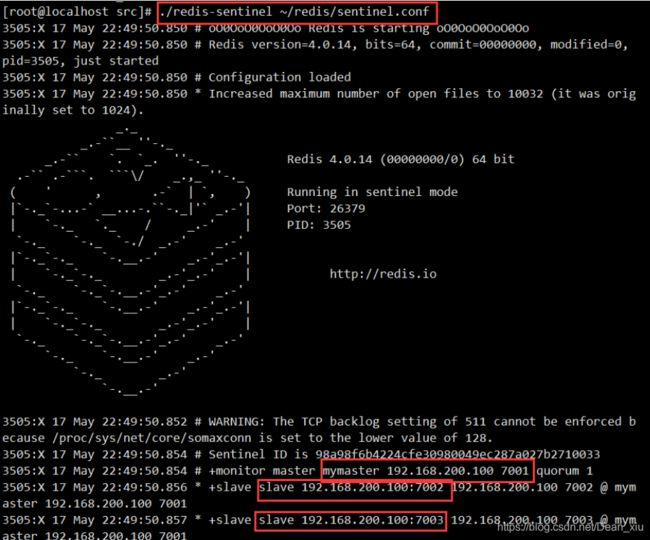
3、关闭主节点后的哨兵服务
进入7001主节点结束服务

哨兵机制会将从节点中的一个推选为主节点
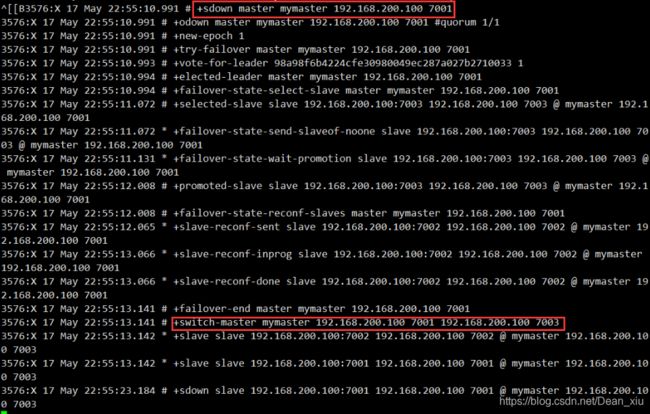
重新启动7001

可以看到哨兵机制中7001已经重新加入集群,并且以7003作为主节点

我们使用info查看7001节点状态,会发现7001变成了从节点
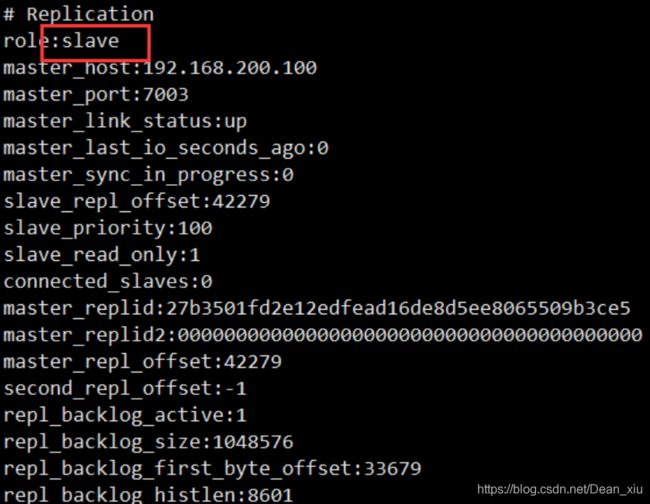
内置集群搭建(Cluster集群)
为了保证节点之间可以进行投票,所以集群的节点最好为奇数
因此集群最少需要三个主节点,每个主节点至少一个从节点,所以至少需要3个从节点
我们以下一共使用6个redis实例,端口号为8001-8006
1、准备节点,拷贝redis到cluster,删除不需要的配置文件
首先停掉所有的redis
![]()
然后复制一个8001节点,删除复制过来的数据文件

修改节点的redis.conf文件
# 不能设置密码,否则集群启动时会连接不上
# Redis服务器可以跨网络访问
bind 0.0.0.0
# 修改端口号
port 8001
# Redis后台启动
daemonize yes
# 开启aof持久化
appendonly yes
# 开启集群
cluster-enabled yes
# 集群的配置 配置文件首次启动自动生成
cluster-config-file nodes.conf
# 请求超时
cluster-node-timeout 5000
记得同时删除slaveof信息以及修改dir为对应的节点的目录,非常重要,如果修改不正确,整个集群会跑不起来,非常痛苦
dir修改的东西如下,会将node.conf放在每个节点的这个目录下
![]()
然后复制五份,一共生成六个节点,记得修改每个节点对应的redis.conf文件中的port信息和dir信息

2、编写启动脚本启动集群
启动脚本内容如下,保存为文件start-all-redis.sh
# 如果你的路径和我不一致,改为自己bin8001-bin8006所在的地址
cd /root/redis/bin8001
./redis-server redis.conf
cd /root/redis/bin8002
./redis-server redis.conf
cd /root/redis/bin8003
./redis-server redis.conf
cd /root/redis/bin8004
./redis-server redis.conf
cd /root/redis/bin8005
./redis-server redis.conf
cd /root/redis/bin8006
./redis-server redis.conf
编写好启动脚本后,进行启动

启动完成后,我们查看当前起动的redis服务,确保集群真正启动了

如果出现了问题,使用如下命令查看一下集群的配置文件是否正确

如果是这样的,就说明是正确的,否则可能是上面的配置信息不正确,那就暂时不要往下进行了,回到上面进行检查
3、安装ruby环境
redis集群的管理工具使用的是ruby脚本语言,安装集群需要ruby环境,所以我们先来安装ruby
安装ruby的命令如下
yum -y install ruby ruby-devel rubygems rpm-build

安装完毕后,我们查看一下版本确保正确安装了

需要知道的是,redis4.0.14集群需要2.2.2以上的ruby版本,我们当前安装的版本过低,所以需要升级ruby版本
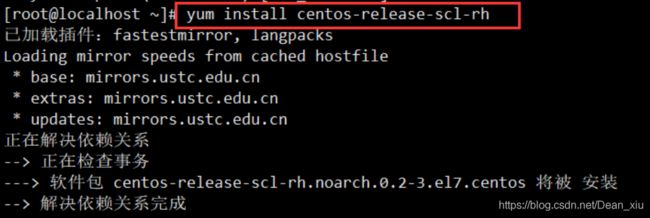
命令如下:
yum install centos-release-scl-rh
yum install rh-ruby23 -y
scl enable rh-ruby23 bash


4、安装ruby的安装工具gem
将准备好的redis-4.1.0.gem上传到虚拟机环境中
![]()
执行命令安装gem
gem install redis-4.1.0.gem

进入到目录

5、编写脚本启动集群
使用集群管理脚本启动集群
# 改换成自己的ip
./redis-trib.rb create --replicas 1 \
192.168.100.129:8001 \
192.168.100.129:8002 \
192.168.100.129:8003 \
192.168.100.129:8004 \
192.168.100.129:8005 \
192.168.100.129:8006

运行期间可以看到如下信息
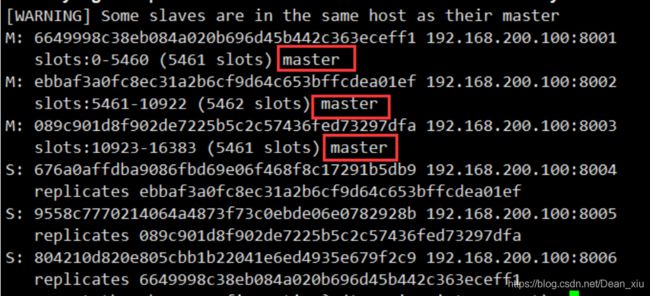
上述信息的意思是为各个节点分配了槽值,记得吗。cluster集群会划分16384个哈希槽,会分配给主节点们

这个的意思是询问我们是否使用上述的配置,我们选择“是”
然后就会看到建立完成的集群环境,主从节点都自动分配了

至此,集群配置完毕
6、通过客户端连接集群,放入值进行测试

我们在8001中放入值,它会自动分配槽值,不一定会是在当前节点,比如下述信息,显示存入的值被重定向到8002节点

那么8004作为8002的从节点就可以查到该信息,而其他节点则查不到



Cluster集群维护
- 大多时候,我们需要对集群进行维护,调整数据的存储,其实就是对哈希槽和节点的调整
- Redis内置的集群支持动态调整,可以在集群不停机的情况下,改变槽值,添加或删除节点
分片重哈希
分片重哈希,可以连接任意节点
./redis-trib.rb reshard 192.168.100.129:8001
执行该命令,会提示该节点需要移动多少个hash槽,直接输入需要移动的hash槽数量即可

记得移动不含有数据的槽,否则就需要停掉所有节点,并删除数据文件,重新创建集群环境
可以将停掉所有节点也写成一个启动脚本
cd /root/redis/bin8001
./redis-cli -p 8001 shutdown
rm -rf appendonly.aof dump.rdb nodes.conf
cd /root/redis/bin8002
./redis-cli -p 8002 shutdown
rm -rf appendonly.aof dump.rdb nodes.conf
cd /root/redis/bin8003
./redis-cli -p 8003 shutdown
rm -rf appendonly.aof dump.rdb nodes.conf
cd /root/redis/bin8004
./redis-cli -p 8004 shutdown
rm -rf appendonly.aof dump.rdb nodes.conf
cd /root/redis/bin8005
./redis-cli -p 8005 shutdown
rm -rf appendonly.aof dump.rdb nodes.conf
cd /root/redis/bin8006
./redis-cli -p 8006 shutdown
rm -rf appendonly.aof dump.rdb nodes.conf
重哈希后,也就是将槽值移动后,可以使用如下命令查看一下当前集群的状况
./redis-cli -p 8001 cluster nodes

通过槽值的区域划分就可以看到其是否重哈希成功
移除节点
移除主节点:
在移除主节点前,需要确保这个主节点是空的,如果不是空的,就需要将这个节点的数据重新分片到其他主节点上
移除从节点:
直接移除即可
移除节点的命令如下:
./redis-trib.rb del-node 节点ip 节点id
该命令的第一个参数是任意节点的地址,第二个参数是想要移除的节点id
接下来演示的是一个含有数据的主节点的移除
当我们直接执行该命令时,会发现失败了
![]()
那么我们首先创建end-all-redis.sh,内容如下:
cd /root/redis/bin8001
./redis-cli -p 8001 shutdown
rm -rf appendonly.aof dump.rdb nodes.conf
cd /root/redis/bin8002
./redis-cli -p 8002 shutdown
rm -rf appendonly.aof dump.rdb nodes.conf
cd /root/redis/bin8003
./redis-cli -p 8003 shutdown
rm -rf appendonly.aof dump.rdb nodes.conf
cd /root/redis/bin8004
./redis-cli -p 8004 shutdown
rm -rf appendonly.aof dump.rdb nodes.conf
cd /root/redis/bin8005
./redis-cli -p 8005 shutdown
rm -rf appendonly.aof dump.rdb nodes.conf
cd /root/redis/bin8006
./redis-cli -p 8006 shutdown
rm -rf appendonly.aof dump.rdb nodes.conf

然后启动该结束脚本
![]()
结束所有节点后,重新启动集群

这个时候,由于我觉得已经好了,所以又尝试删除了一次,现实告诉我,我想多了
![]()
所以一定要进行重哈希

完成重哈希后,查看集群信息

可以看到8002的所有槽都被移除了,这个时候我们再进行移除节点

哈哈哈哈,已经可以成功移除了
然后再看一下集群信息


已经没有8002了,哦耶,移除成功
添加节点
- 添加新的主节点时,主节点默认没有哈希槽,需要手动分配哈希槽
- 添加新的从节点,集群默认自动分配对应的主节点
添加节点前需要保证一个新的节点是干净的,空的redis,意思是我们需要删除持久化文件和节点配置文件
以下以将8002添加为主节点,将8006添加为从节点为例进行操作说明
删除持久化和节点配置文件

启动新的节点

查看集群信息

这里有个问题:
我们之前删除8002节点的时候,其从节点还是认为8002是其主节点,所以我们也要移除8002的从节点8006

移除8006后重新启动8006节点
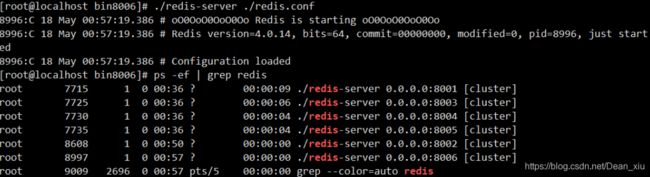
添加新的主节点8002
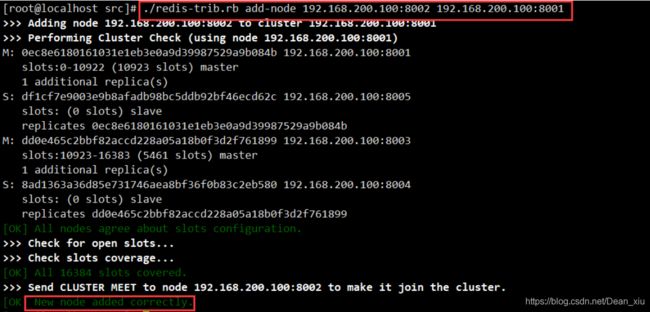
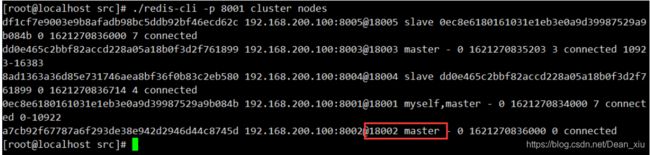
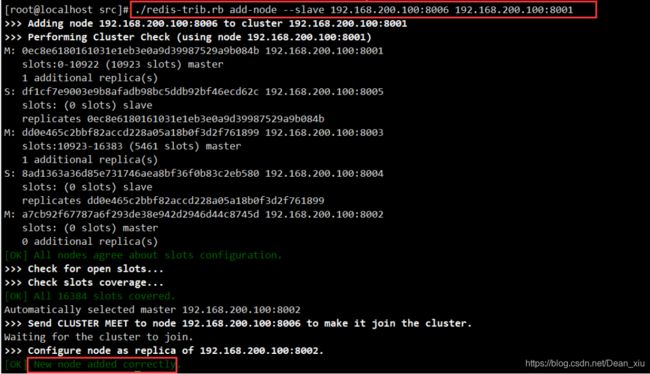
添加新的从节点8006

然后对8002节点添加槽值,最终结果如下

好了!结束,睡觉