MakeFile编译流程介绍
1. 通常情况下GNU makefile工作流程如下:
1.查找当前目录下的makefile文件。
2.初始化文件中的变量。
3.分析makefile中的所有规则。
4.为所有目标文件创建依赖关系。
5.根据依赖关系决定哪些文件需要依赖重新生成。
6.执行生成命令。
为了比较形象的说明make工具的原理,通过一个简单的例子来做介绍。
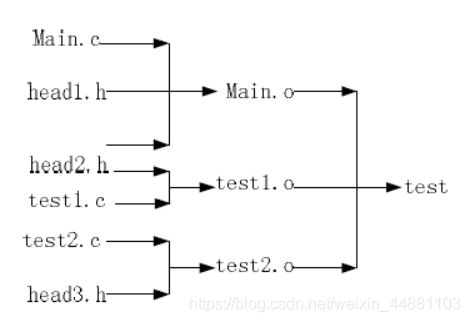
针对以上流程的说明:
main.o的依赖文件为main.c head1.h head2.h
test1.o的依赖文件为head2.h test1.c
…
最红可执行文件test的依赖关系为main.o test1.o test2.o
执行make命令后首先处理test程序的所有依赖文件(*).o的更新规则,针对.o文件首先会检查.c和.h文件是否有更新,判断依赖文件是否有更新,只要是通过查看文件的修改时间来做判断。
最终检查.o文件时间是否有更新,有更新则重新编译,没有更新就不编译了。
所以make管理工具是从底层开始,是一个逆序遍历的过程。
执行make命令时,只需要到MakeFile文件所在的那个目录下,执行make命令即可,
make还可以带一些参数进行编译。
make -f 指定MakeFile的文件名。
make -n 打印所有执行命令。
make -s 执行时不打印命令名。
make -d 打印调试信息。
make -I 指定所有makefile所在的目录。
make -h 帮助信息打印。
2.MakeFile规则语法介绍
makefile的作用就是让编译器知道编译一个文件需要依赖那些文件,同时那些依赖文件有了改变,编译器可以重新更新和编译出新的可执行文件。
makefile的规则主要有两个方面: 一,说明文件之间的依赖关系。二,告诉make如何生成目标文件的命令。
示例如下:
begin -----------------------------------------

end -----------------------------------------
开头用tab键隔开,在以上文件中目标文件(target)即为:最终的可执行文件test和中间的目标文件例如test1.o 每个目标文件和依赖文件中间用:隔开,依赖文件列表之间用空格隔开。
3.makefile变量中文件的使用
linux下makefile文件中可能使用很多的变量,定义一个变量,
makefile一些特殊变量的说明如下:
$@ : 指当前规则下的目标文件列表。
$< : 指依赖文件列表中的第一个文件。
$^: 指依赖文件列表中的所有文件。
$? : 指代依赖文件中新于对应目标文件的文件列表。
定义变量书写格式-----------示例如下所示:

从以上的修改例子可以看出,引入了变量OBJ和CC,这样简化makefile文件的编写,增加了文件的可读性,而且便于修改。举个例子来说,假定项目中还需要增加另外一个新的目标文件test4.o,那么该文件中两处需要进行添加。但是如果使用变量的话,只需要在OBJ变量的列表中添加一次即可,这对于更复杂的makefile文件来说,减轻了工作量。
4.makefile应用优势说明
1.代表一个文件列表。
通过引用文件中的变量,给makefile编写和维护带来了便利。
2.代表编译命令选项。
当所有编译命令都带有相同的命令时候( -O2 -wall),可以将该编译选项赋给一个变量,这样方便了引用,同时如果想改变编译选项时,可以改变变量的值即可。
5.make clean 和make install的介绍:
make clean 当make执行到clean时,会先查看对应的依赖关系,由于伪目标没有任何依赖文件,所以make命令会认为该目标是最新的而不会执行任何操作,为了执行这个目标体系,必须手动执行make clean命令。
make install命令:执行此命令时,系统会提醒 cp test1 /home /tmp,也就是把test1拷贝到系统目录下。事实上许多makefile都是这样写的,这样便于程序在编译后 可以被安装到正确的目录下。