负载均衡下的 WebShell 连接
目录
- 负载均衡简介
-
- 负载均衡的分类
- 网络通信分类
- 负载均衡下的 WebShell 连接
-
- 场景描述
- 难点介绍
- 解决方法
-
- **Plan A** **关掉其中一台机器**(作死)
- **Plan B** **执行前先判断要不要执行**
- **Plan C** 在Web 层做一次 HTTP 流量转发 (重点)
负载均衡简介
负载均衡(Load Balance,简称 LB)是高并发、高可用系统必不可少的关键组件,目标是 尽力将网络流量平均分发到多个服务器上,以提高系统整体的响应速度和可用性。
负载均衡的主要作用如下:
高并发:负载均衡通过算法调整负载,尽力均匀的分配应用集群中各节点的工作量,以此提高应用集群的并发处理能力(吞吐量)。
伸缩性:添加或减少服务器数量,然后由负载均衡进行分发控制。这使得应用集群具备伸缩性。
高可用:负载均衡器可以监控候选服务器,当服务器不可用时,自动跳过,将请求分发给可用的服务器。这使得应用集群具备高可用的特性。
安全防护:有些负载均衡软件或硬件提供了安全性功能,如:黑白名单处理、防火墙,防 DDos 攻击等。
负载均衡的分类
硬件负载均衡
硬件负载均衡,一般是在定制处理器上运行的独立负载均衡服务器,价格昂贵,土豪专属。硬件负载均衡的主流产品有:F5 和 A10。
硬件负载均衡的 优点:
功能强大:支持全局负载均衡并提供较全面的、复杂的负载均衡算法。
性能强悍:硬件负载均衡由于是在专用处理器上运行,因此吞吐量大,可支持单机百万以上的并发。
安全性高:往往具备防火墙,防 DDos 攻击等安全功能。
硬件负载均衡的 缺点:
成本昂贵:购买和维护硬件负载均衡的成本都很高。
扩展性差:当访问量突增时,超过限度不能动态扩容。
软件负载均衡
软件负载均衡,应用最广泛,无论大公司还是小公司都会使用。
软件负载均衡从软件层面实现负载均衡,一般可以在任何标准物理设备上运行。
软件负载均衡的 主流产品 有:Nginx、HAProxy、LVS。
LVS 可以作为四层负载均衡器。其负载均衡的性能要优于 Nginx。
HAProxy 可以作为 HTTP 和 TCP 负载均衡器。
Nginx、HAProxy 可以作为四层或七层负载均衡器。
软件负载均衡的 优点:
扩展性好:适应动态变化,可以通过添加软件负载均衡实例,动态扩展到超出初始容量的能力。
成本低廉:软件负载均衡可以在任何标准物理设备上运行,降低了购买和运维的成本。
软件负载均衡的 缺点:
性能略差:相比于硬件负载均衡,软件负载均衡的性能要略低一些。
网络通信分类
软件负载均衡从通信层面来看,又可以分为四层和七层负载均衡。
- 七层负载均衡:就是可以根据访问用户的 HTTP 请求头、URL 信息将请求转发到特定的主机。
DNS 重定向
HTTP 重定向
反向代理
- 四层负载均衡:基于 IP 地址和端口进行请求的转发。
修改 IP 地址
修改 MAC 地址
负载均衡下的 WebShell 连接
其中像 HTTP 重定向方式、DNS方式等能够直接访问到单一机器的情况,不在我们本文讨论范围内。连接的时候,URL处按 IP 格式来填,然后把域名加在 Host 头处,就完事了。我们重点讨论不能直接访问到跑着具体业务的某个节点的情况,比如说「反向代理方式」。
反向代理方式其中比较流行的方式是用 nginx 来做负载均衡。我们先简单的介绍一下 nginx 支持的几种策略:
| 名称 | 策略 |
|---|---|
| 轮询(默认) | 按请求顺序逐一分配 |
| weight | 根据权重分配 |
| ip_hash | 根据客户端IP分配 |
| least_conn | 根据连接数分配 |
| fair (第三方) | 根据响应时间分配 |
| url_hash (第三方) | 根据URL分配 |
其中 ip_hash、url_hash 这种能固定访问到某个节点的情况,我们也不讨论,跟单机没啥区别么不是。
我们以默认的「轮询」方式来做演示。
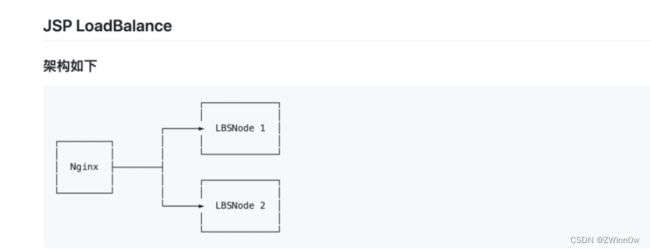
为了方便解释,我们只用两个节点,启动之后,看到有 3 个容器(你想像成有 3 台服务器就成)。

Node1 和 Node2 均是 tomcat 8 ,在内网中开放了 8080 端口,我们在外部是没法直接访问到的。
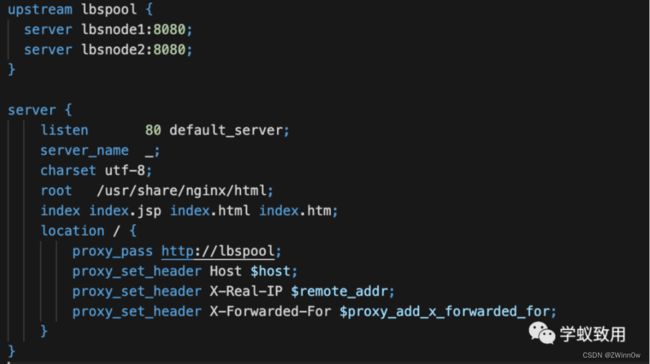
我们只能通过 nginx 这台机器访问。nginx 的配置如下:
场景描述
OK,我们假定在真实的业务系统上,存在一个 RCE 漏洞,可以让我们获取 WebShell。
我们先按常规操作在蚁剑里添加 Shell
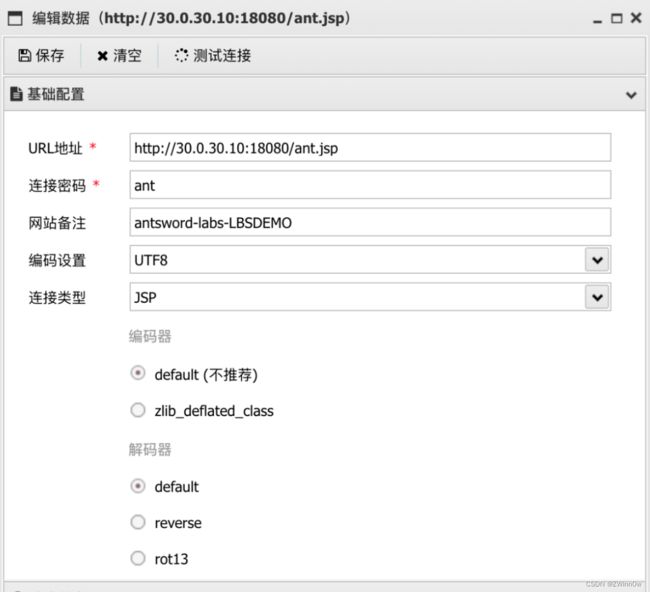
然后连接目标,因为两台节点都在相同的位置存在 ant.jsp,所以连接的时候也没出现什么异常。
难点介绍
难点一:我们需要在每一台节点的相同位置都上传相同内容的 WebShell
一旦有一台机器上没有,那么在请求轮到这台机器上的时候,就会出现 404 错误,影响使用。是的,这就是你出现一会儿正常,一会儿错误的原因。
难点二:我们在执行命令时,无法知道下次的请求交给哪台机器去执行。
我们执行 ip addr 查看当前执行机器的 ip 时,可以看到一直在飘,因为我们用的是轮询的方式,还算能确定,一旦涉及了权重等其它指标,就让你好好体验一波什么叫飘乎不定。
难点三:当我们需要上传一些工具时,麻烦来了:
我们本地的 111.png 大小是 2117006, 由于 antSword 上传文件时,采用的分片上传方式,把一个文件分成了多次HTTP请求发送给了目标,所以尴尬的事情来了,两台节点上,各一半,而且这一半到底是怎么组合的,取决于 LBS 算法,这可怎么办?
难点四:由于目标机器不能出外网,想进一步深入,只能使用 reGeorg/HTTPAbs 等 HTTP Tunnel,可在这个场景下,这些 tunnel 脚本全部都失灵了。
如果说前面三个难点还可以忍一忍,那第四个难点就直接劝退了。这还怎么深入内网?
解决方法
Plan A 关掉其中一台机器(作死)
是的,首先想到的第一个方案是关机/停服,只保留一台机器,因为健康检查机制的存在,很快其它的节点就会被 nginx 从池子里踢出去,那么妥妥的就能继续了。
但是这个方案实在是饮鸩止渴,影响业务,还会造成灾难,直接 Pass 不考虑。(实验环境下,权限够的时候是可以测试可行性的)。
*综合评价*:真实环境下千万不要尝试!!!!
Plan B 执行前先判断要不要执行
我们既然无法预测下一次是哪台机器去执行,那我们的 Shell 在执行 Payload 之前,先判断一下要不要执行不就行了?
以执行命令时 Bash 为例,在执行前判断一下 IP:
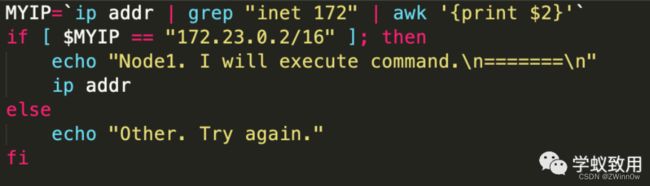
效果大概就是这个样子:

这样一来,确实是能够保证执行的命令是在我们想要的机器上了,可是这样执行命令,不够丝滑,一点美感都没有。另外,上传文件、HTTP 隧道 这些要怎么解决?
综合评价:该方案 「勉强能用**」**,仅适合在执行命令的时候用用,不够优雅。
Plan C 在Web 层做一次 HTTP 流量转发 (重点)
没错,我们用 AntSword 没法直接访问 LBSNode1 内网IP(172.23.0.2)的 8080 端口,但是有人能访问呀,除了 nginx 能访问之外,LBSNode2 这台机器也是可以访问 Node1 这台机器的 8080 端口的。
还记不记得 「PHP Bypass Disable Function」 这个插件,我们在这个插件加载 so 之后,本地启动了一个 httpserver,然后我们用到了 HTTP 层面的流量转发脚本 「antproxy.php」, 我们放在这个场景下看:
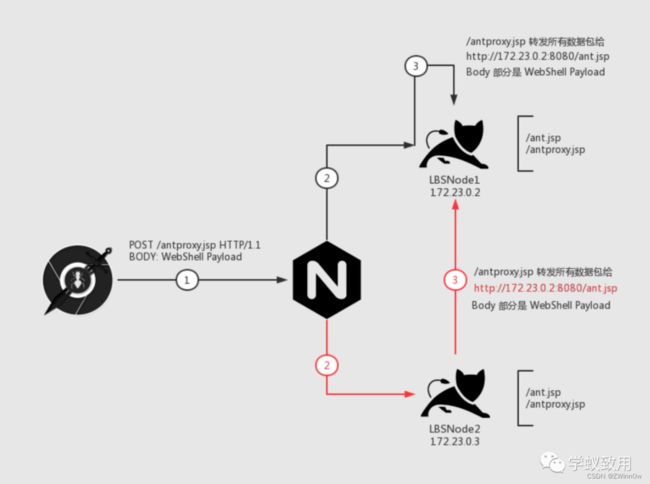
我们一步一步来看这个图,我们的目的是:所有的数据包都能发给「LBSNode 1」这台机器。
首先是 第 1 步,我们请求 /antproxy.jsp,这个请求发给 nginx
nginx 接到数据包之后,会有两种情况:
我们先看黑色线,第 2 步把请求传递给了目标机器,请求了 Node1 机器上的 /antproxy.jsp,接着 第 3 步,/antproxy.jsp 把请求重组之后,传给了 Node1 机器上的 /ant.jsp,成功执行。
再来看红色线,第 2 步把请求传给了 Node2 机器, 接着第 3 步,Node2 机器上面的 /antproxy.jsp 把请求重组之后,传给了 Node1 的 /ant.jsp,成功执行。
优点:
- 低权限就可以完成,如果权限高的话,还可以通过端口层面直接转发,不过这跟 Plan A 的关服务就没啥区别了
- 流量上,只影响访问 WebShell 的请求,其它的正常业务请求不会影响。
- 适配更多工具
缺点:
- 该方案需要「目标 Node」和「其它 Node」 之间内网互通,如果不互通就凉了