Oracle DG 自动故障转移 —— Fast-Start Fail Over(FSFO)
前面介绍了 Oracle DG 手动 SwitchOver & Failover及Failover后利用闪回恢复主从同步 和 Oracle DG Broker 进行 SwitchOver & Failover及Failover后恢复主从同步
这篇来看下DG的自动切换方法 —— Fast-Start Fail Over。
FSFO允许代理在主库故障的情况下自动故障转移到先前选择的备库,无需手动执行任何步骤,以便快速可靠地恢复业务。FSFO只能在代理配置中使用,并且只能通过DGMGRL或OEM进行配置。
FSFO支持在最高可用性与最高性能模式下使用。最大可用性模式保证不会丢失任何数据,最高性能模式可保证丢失的数据量不超过FastStartFailoverLagLimit属性指定的数据量(单位为秒)。
一、 何时会进行FSFO
配置完成后,FSFO将在以下情况下起作用:
- 主库与 Observer和目标备库 失联时间均超过
FastStartFailoverThreshold属性配置阈值(单位为秒) - 单实例数据库中主实例崩溃
- RAC中所有主实例崩溃
- shutdown abort主库
- 应用程序通过调用DBMS_DG.INITIATE_FS_FAILOVER函数启动FSFO
- Oracle 错误:可以指定启动 FSFO 故障切换的 ORA 错误列表(默认为空)
- Broker 可配置为遇到以下任一条件时启动FSFO:
| Health Condition | Description | 默认启用 |
|---|---|---|
| Datafile Offline | 数据文件由于写错误脱机 | Yes |
| Corrupted Dictionary | 关键数据库对象的字典损坏,该状态可在数据库open时被检测到 | Yes |
| Corrupted Controlfile | 控制文件由于写入错误永久损坏 | Yes |
| Inaccessible Logfile | 由于IO错误,LGWR无法写入日志组的任何成员 | No |
| Stuck Archiver | 由于设备已满或不可用,归档进程无法归档redo log | No |
二、 Observer
Observer是一个OCI(Oracle Call Interface)客户端组件,通常运行在独立服务器并监视主库可用性。
Observer 应安装在独立的服务器上,与主、备服务器分开。DGMGRL包含Observer 软件,因此要在独立的服务器上安装DGMGRL。安装方法有以下两种:
- 通过选择Oracle Universal Installer中的Administrator选项来安装完整的Oracle Client Administrator。此安装包括DGMGRL,但不包括OEM代理。这种安装方式可以使用DGMGRL命令但无法使用OEM来管理Observer。
- 安装完整的Oracle数据库软件包,这种安装方式包括DGMGRL。
- 安装步骤参考 https://www.jianshu.com/p/55fd93a81150
顾名思义,Observer可以观察主备库之间的活动,决定是否进行FSFO,因此我们需要在连接性最高的服务器上安装Observer。FSFO可能会导致错误的故障转移,即使主库正在运行并且可以在本地访问,也可能会发生FSFO;如果客户端无法访问主库,也可能不发生FSFO。
三、 FSFO过程
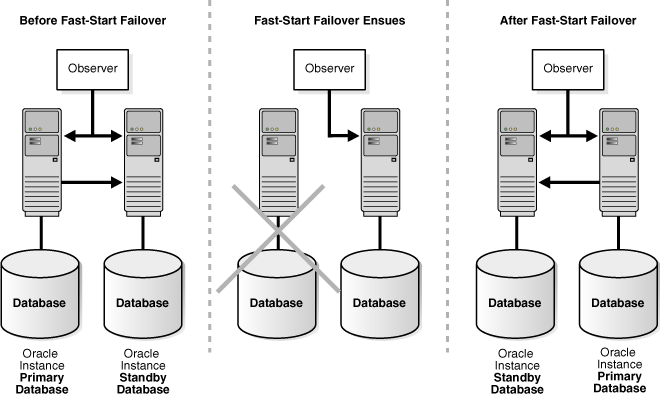
1. FSFO之前
DG稳定运行,主库将REDO数据传输到备库,Observer监视整体状态。
2. FSFO期间
主库遇到灾难,并且它与Observer和目标备库均失联。在检测到通信中断后,Observer在FastStartFailoverThreshold指定时间内尝试重连主库,如果还是无法连接,且目标备库已准备好进行FSFO,则将发生FSFO。
3. FSFO之后
FSFO已完成,并且目标备库以主库角色运行。在修复了原主库之后,Observer将重建与该数据库的连接,并将其恢复为新主库的备库。新主库开始将重做数据传输给它。
四、 FSFO配置前提条件
- 直到11g为止,数据库保护模式应为“最大可用性”或“最大性能”
- 已配置 Oracle DG Broker,配置方法参考 Oracle DG Broker 进行 SwitchOver & Failover及Failover后恢复主从同步
- LOGXPTMODE属性在最大可用性模式下应为SYNC,在最大性能模式下应为ASYNC,主备库LOGXPTMODE设置必须相同
- 主库和作为FSFO目标的备库必须都启用闪回数据库
- 在Observer上配置tnsnames.ora文件,使其能连接到主库和作为FSFO目标的备库
- 创建一个静态服务名称,以便Observer可以在恢复时自动重启数据库
五、 配置
最简单的方法只需要配置Observer并enable fast_start failover; 即可。
参考 https://blog.csdn.net/shiyu1157758655/article/details/55504518
下面是按照官方文档配置推荐的主要参数。
1. 连接到dgmgrl并检查配置
DGMGRL> connect sys/oracle
Connected.
DGMGRL> show configuration;
Configuration - dgconfig1
Protection Mode: MaxPerformance
Databases:
testdb - Primary database
std_testdb - Physical standby database
Fast-Start Failover: DISABLED
Configuration Status: SUCCESS
2. 设置故障转移目标
只能为当前主库设置一个目标转移备库,若只有一个备库,此步骤可忽略。若要修改目标转移备库,需要先禁用FSFO,改完后再启用。
DGMGRL> EDIT DATABASE TESTDB SET PROPERTY FASTSTARTFAILOVERTARGET=STD_TESTDB;
Property "faststartfailovertarget" updated
DGMGRL> EDIT DATABASE STD_TESTDB SET PROPERTY FASTSTARTFAILOVERTARGET=TESTDB;
Property "faststartfailovertarget" updated
3. 设置保护模式与LogXptMode
LOGXPTMODE属性在最大可用性模式下应为SYNC,在最大性能模式下应为ASYNC,主备库LOGXPTMODE设置必须相同
DGMGRL> EDIT CONFIGURATION SET PROTECTION MODE AS MaxAvailability;
DGMGRL> edit database orcl set property 'LogXptMode'='ASYNC';
DGMGRL> edit database orcl_dg set property 'LogXptMode'='ASYNC';
4. 设置FSFO阈值
如果主库与 Observer和目标备库 失联时间均超过FastStartFailoverThreshold属性配置阈值(单位为秒),将启动FSFO。
换句话说,FastStartFailoverThreshold表示,Observer和目标备库 在检测到主库不可用后、希望等多少秒才启动FSFO。再此期间,它们会尝试重连主库。
默认值为30秒,最小6秒。
DGMGRL> edit configuration set property faststartfailoverthreshold=300;
5. 设置最大可接受延迟时间
FastStartFailoverLagLimit表示,自动故障转移允许的最大数据丢失量(单位为秒),仅在最高性能保护模式时才可使用。
FastStartFailoverLagLimit作为DG可接受的最大延迟时间,备库的apply lag只有在此限制之内,才允许FSFO。
如果无法维持已配置的数据丢失保证,主库上的redo生成将停止。为了避免长时间停顿,Observer或者目标备库可能会在第一次记录到无法发生FSFO之后,允许主库继续生成redo。此时若主库故障,将无法发生FSFO。
默认值为30秒,最小值为10秒。
DGMGRL> edit configuration set property faststartfailoverlaglimit=50;
6. 设置FastStartFailoverPmyShutdown属性
默认为true,表示在FastStartFailoverThreshold属性指定的秒数过去之后,使用ABORT选项关闭主数据库。
如果不希望由于 主库redo生成停止 或 主库与Observer和目标备库 失联时间超过FastStartFailoverThreshold指定时间而在触发FSFO后关闭主库,需要将其设置为假。
DGMGRL> edit configuration set property FastStartFailoverThreshold=false;
7. 设置自动恢复数据库属性
如果FastStartFailoverAutoReinstate属性设置为TRUE,在原主库故障修复后,会自动尝试将其恢复为新主库的备库。
DGMGRL> EDIT CONFIGURATION SET PROPERTY FASTSTARTFAILOVERAUTOREINSTATE=TRUE;
Property "faststartfailoverautoreinstate" updated
8. 启动Observer
ObserverConnectIdentifier用于指定Observer应如何连接并监视主备库。如果希望Observer使用不同于发送重做数据连接串的连接标识符,请为主库和目标备库设置此属性(可选)。
配置Observer(可选)
dgmgrl sys/xxxx@OBSRV_ORCL_DGMGRL
DGMGRL>edit database orcl set property ObserverConnectIdentifier='OBSRV_ORCL_DGMGRL';
DGMGRL>edit database orcl_dg set property ObserverConnectIdentifier='OBSRV_ORCL_DG_DGMGRL';启动Observer
[oracle@localhost oradata]$ dgmgrl
...
DGMGRL> connect sys/oracle@testdb
Connected.
DGMGRL> start observer;
Observer started
9. 启用fast_start故障转移
DGMGRL> enable fast_start failover;
Enabled.启用Fast_Start Failover时alert日志如下:
Fast-Start Failover (FSFO) has been enabled between:
Primary = "testdb"
Standby = "std_testdb"
Sat Jun 23 15:49:22 2018
FSFP started with pid=69, OS id=17552
10. 查看FSFO配置
DGMGRL> show fast_start failover;
Fast-Start Failover: ENABLED
Threshold: 50 seconds
Target: std_testdb
Observer: test1.localdomain
Lag Limit: 50 seconds (not in use)
Shutdown Primary: TRUE
Auto-reinstate: TRUE
Observer Reconnect: (none)
Observer Override: FALSE
Configurable Failover Conditions
Health Conditions:
Corrupted Controlfile YES
Corrupted Dictionary YES
Inaccessible Logfile NO
Stuck Archiver NO
Datafile Offline YES
Oracle Error Conditions: (none)也可以从v$database视图检查
SELECT fs_failover_status,
fs_failover_current_target,
fs_failover_threshold,
fs_failover_observer_present,
fs_failover_observer_host
FROM v$database;
六、 FSFO测试
| 测试环境描述: | ||||
| 1 | 操作系统: | SUSE Linux 11 | ||
| 2 | Oracle Cluster版本: | N/A | ||
| 3 | Oracle数据库版本: | 12.1.0.2 | ||
| 4 | 架构: | Dataguard+FSFO | ||
| 编号 | 描述 | 测试动作 | 预期结果 | 实际结果/备注 |
| 1 | 计划外主库实例挂掉 | kill -9 pid_of_smon 或者 SQL > shutdown abort |
Primary instance crash,standby instance进行切换。 切换后,原standby instance成primary instance. 在dgmgrl控制台可以看到ORA-16829: fast-start failover configuration is lagging,且原primary instance可以看到ORA-16661: the standby database needs to be reinstated |
2分钟左右完成切换 |
| 2 | 计划外备库实例挂掉 | kill -9 pid_of_smon 或者 SQL > shutdown abort |
dgmgrl控制台主库报错ORA-16810: multiple errors or warnings detected for the database,备库报错ORA-01034: ORACLE not available | 备库挂掉,应用不受影响 |
| 3 | 计划内关闭主库 | SQL > shutdown immediate | 主备库不切换,在dgmgrl控制台可以看到主库报错:Error: ORA-01034: ORACLE not available,备库提示信息:(*) Physical standby database | 计划内维护 |
| 4 | 计划内关闭备库 | SQL > shutdown immediate | 主备库不切换,在dgmgrl控制台可以看到主库报错:ORA-16829: fast-start failover configuration is lagging,备库提示信息:(*) Physical standby database (disabled) | 计划内维护 |
| 5 | 重新启动失败数据库实例 | SQL > startup | 启动原primary库之后,自动变成physical standby角色。在完成Clearing online log之后,进行mrp的介质恢复。 在dgmgrl控制台,看到原primary状态从ORA-16661: the standby database needs to be reinstated,变成ORA-16657: reinstatement of database in progress,继而变成ORA-16829: fast-start failover configuration is lagging,待lag补齐之后最终变成Physical standby database |
重启的原primary库恢复正常大约5~10分钟,重启期间应用完全不受影响。 |
| 6 | 主库监听挂掉 | kill -9 pid_of_listener | 应用无法连接。 主库和备库之间如果没有lag,处于standby redolog的recovery,则不受影响。 主库和备库之间如果有lag,则当备库启动时,需要使用archivelog的recovery,就会报错 ORA-01196: file n is inconsistent due to a failed media recovery session。Dgmgrl控制台报错备库 ORA-16664: unable to receive the result from a database |
监听挂掉,应用无法连接数据库,需要手工启动监听。 注:已经添加自动重启监听脚本,发现监听宕掉,自动拉起监听。 |
| 7 | 备库监听挂掉 | kill -9 pid_of_listener | 应用正常连接。 主库和备库之间如果没有lag,处于standby redolog的recovery,则不受影响。 主库和备库之间如果有lag,dgmgrl控制台主库报错:ORA-16810: multiple errors or warnings detected for the database,备库报错:ORA-12541: TNS:no listener 备库启动时,需要使用archivelog的recovery,就会报错 ORA-01196: file n is inconsistent due to a failed media recovery session。Dgmgrl控制台报错备库 ORA-16664: unable to receive the result from a database |
应用连接正常,需要手工启动备库监听 注:已经添加自动重启监听脚本,发现监听宕掉,自动拉起监听。 |
| 8 | 计划内切换主备库 | DGMGRL> switchover to 'fltrec_dg'; | 在切换期间,应用连接报错ORA-16456: switchover to standby in progress or completed。 切换后,应用恢复正常。 |
大约2分钟左右完成切换 |
参考
https://docs.oracle.com/cd/E11882_01/server.112/e40771/sofo.htm#DGBKR390
https://www.oracle.com/technetwork/cn/tutorials/smiley-fsfo-088047-zhs.html
http://oracle-help.com/dataguard/configuring-fast-start-fail-over/
https://blog.csdn.net/Hehuyi_In/article/details/94384431
https://blog.csdn.net/Hehuyi_In/article/details/105258110
How to run Observer process as a background process (文档 ID 1084681.1)