Seaborn数据可视化,举例剖析
Seaborn数据可视化
单纯去使用matplotlib绘制图像,画出来是可以了,但是人们往往会去追求最佳实践,为了简化代码操作,所以就有了基于matplotlib的“装饰库”——seaborn。学这个之前一定要先学matplotlib哦,看我之前的博客。
文章目录
- Seaborn数据可视化
-
- Seaborn 介绍
- 快速优化图形
- Seaborn 绘图 API
-
- 关联图
- 类别图
- 分布图
- 回归图
-
- 矩阵图
- 写在最后
Seaborn 介绍
Matplotlib 应该是基于 Python 语言“最优秀”的绘图库了,但是它也有一个十分令人头疼的问题,那就是太过于复杂了。3000 多页的官方文档,上千个方法以及数万个参数,属于典型的你可以用它做任何事,但又无从下手。尤其是,当你想通过 Matplotlib 调出非常漂亮的效果时,往往会伤透脑筋,非常麻烦。
Seaborn 是基于 Matplotlib 进行了更高阶的 API 封装,可以更加轻松地画出更漂亮的图形。Seaborn 的漂亮主要体现在配色更加舒服、以及图形元素的样式更加细腻。
Seaborn 具有如下特点:
- 内置数个经过优化的样式效果。
- 增加调色板工具,可以很方便地为数据搭配颜色。
- 单变量和双变量分布绘图更为简单,可用于对数据子集相互比较。
- 对独立变量和相关变量进行回归拟合和可视化更加便捷。
- 对数据矩阵进行可视化,并使用聚类算法进行分析。
- 基于时间序列的绘制和统计功能,更加灵活的不确定度估计。
- 基于网格绘制出更加复杂的图像集合。
- 他的官方文档非常容易读懂,里面有许多例子,不信请点击查看
一起见证一下Seaborn吧。
环境:
Python 3.6.9
Matplotlib 3.1.0
Seaborn 0.9.0
快速优化图形
首先通过Matplotlib简单绘制一幅图像:
import matplotlib.pyplot as plt
%matplotlib inline
#定义绘图数据
x = [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
y_bar = [3, 8, 6, 8, 9, 10, 9, 11, 7, 8]
y_line = [2, 9, 5, 7, 8, 9, 8, 10, 6, 7]
plt.bar(x, y_bar)
plt.plot(x, y_line, '-o', color='y')
输出结果:
使用 Seaborn 完成图像快速优化的方法非常简单。只需要将 Seaborn 提供的样式声明代码在绘图前调用set() 即可。他会调用默认的参数来对图形进行格式上的优化:
import seaborn as sns
mport matplotlib.pyplot as plt
%matplotlib inline
#定义绘图数据
x = [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
y_bar = [3, 8, 6, 8, 9, 10, 9, 11, 7, 8]
y_line = [2, 9, 5, 7, 8, 9, 8, 10, 6, 7]
sns.set() # 声明使用 Seaborn 样式
plt.bar(x, y_bar)
plt.plot(x, y_line, '-o', color='y')
输出结果:
可以发现,相比于 Matplotlib 默认的纯白色背景,Seaborn 默认的浅灰色网格背景看起来的确要细腻舒适一些。而柱状图的色调、坐标轴的字体大小也都有一些变化。有没有觉得默认的东西都这么和谐,OK,接着往下继续探索吧!
set()里面的参数如下:
sns.set(context='notebook', style='darkgrid', palette='deep', font='sans-serif', font_scale=1, color_codes=False, rc=None)
其中:
context=''参数控制着默认的画幅大小,分别有{paper, notebook, talk, poster}四个值。其中,poster > talk > notebook > paper。style=''参数控制默认样式,分别有{darkgrid, whitegrid, dark, white, ticks},你可以自行更改查看它们之间的不同。palette=''参数为预设的调色板。分别有{deep, muted, bright, pastel, dark, colorblind}等,你可以自行更改查看它们之间的不同。font=''用于设置字体,font_scale=设置字体大小,color_codes=不使用调色板而采用先前的'r'等色彩缩写。
我们了解了set()的参数就可以在他的基础上去修改啦,直接在函数中传参即可。
举个例子:
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
#定义绘图数据
x = [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
y_bar = [3, 8, 6, 8, 9, 10, 9, 11, 7, 8]
y_line = [2, 9, 5, 7, 8, 9, 8, 10, 6, 7]
sns.set(context='poster',
style='white',
palette='dark',
font='sans-serif',
font_scale=0.55, color_codes='r', rc=None)
plt.bar(x, y_bar)
plt.plot(x, y_line, '-o', color='y')
输出结果:
Seaborn 绘图 API
Seaborn 一共拥有 50 多个 API 类,与matploblib相比较,他做到了短小精悍。其中,根据图形的适应场景,Seaborn 的绘图方法大致分类 6 类,分别是:
- 关联图
- 类别图
- 分布图
- 回归图
- 矩阵图
- 组合图
在这 6 大类下面又包含不同数量的绘图函数。
关联图
当我们需要对数据进行关联性分析时,可能会用到 Seaborn 提供的以下几个 API。
| 关联性分析 | 介绍 |
|---|---|
| relplot | 绘制关系图 |
| scatterplot | 多维度分析散点图 |
| lineplot | 多维度分析线形图 |
relplot 是 relational plots 的缩写,其可以用于呈现数据之后的关系,主要有散点图和条形图 2 种样式。
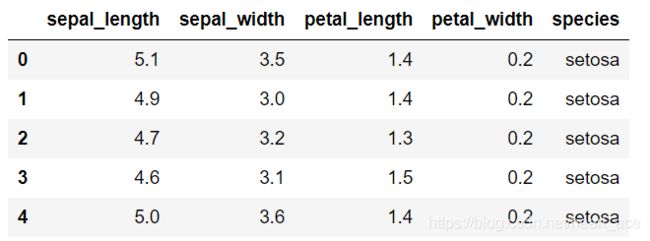
为了使得代码量少一点儿,这里使用著名的莺尾花数据集(学习数据分析你必定会遇到它的)进行数据可视化。
莺尾花数据集总共 150 行,由 5 列组成。分别代表:萼片长度、萼片宽度、花瓣长度、花瓣宽度、花的类别。其中,前四列均为数值型数据,最后一列花的分类为三种,分别是:Iris Setosa、Iris Versicolour、Iris Virginica。
iris = sns.load_dataset("iris")
iris.head()
此时,我们指定 x x x 和 y y y 的特征,默认可以绘制出散点图。为了更加容易看出数据之间的关系,我们加入类别特征对数据进行着色。
#hus指定类别
sns.relplot(x="sepal_length", y="sepal_width", hue="species", data=iris)

不只是散点图,该方法还支持线形图,指定 kind="line" 参数即可。线形图和散点图适用于不同类型的数据。线形态绘制时还会自动给出 95% 的置信区间。还有一个常用的就是 style 参数,它用于赋予不同类别的散点不同的形状。
sns.relplot(x="sepal_length", y="petal_length",
hue="species", style="species", kind="line", data=iris)
输出结果:
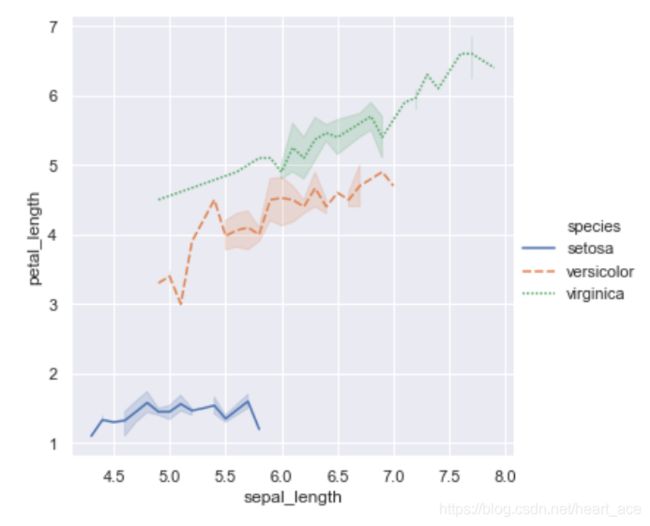
Seaborn 的函数都有大量实用的参数。要了解 更多的参数请通过阅读relplot文档
上面提到了 3 个 API,分别是:relplot,scatterplot 和 lineplot。
实际上,你可以把relplot 看作是 scatterplot 和 lineplot 的结合版本。
Seaborn 中的 API 分为
- Figure-level :
relplot就是一个 Figure-level 接口 - Axes-level :
scatterplot和lineplot属于Axes-level接口
Figure-level 和 Axes-level API 的区别在于,Axes-level 的函数可以实现与 Matplotlib 更灵活和紧密的结合,而 Figure-level 就是个“懒人函数”,适合于快速应用。
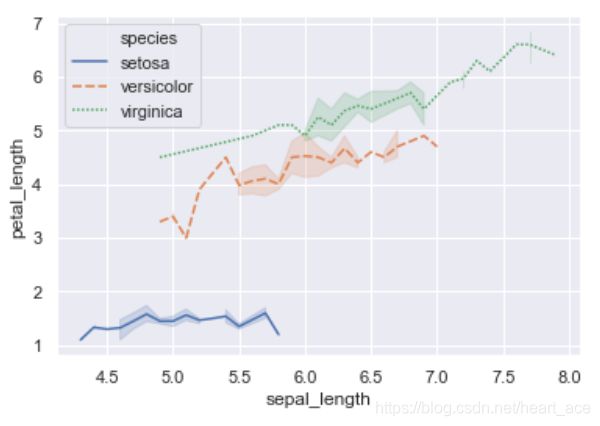
对于上方的图,我们也可以使用 lineplot 函数绘制,你只需要取消掉 relplot 中的 kind 参数即可。
sns.lineplot(x="sepal_length", y="petal_length",
hue="species", style="species", data=iris)
输出结果:
类别图
与关联图相似,类别图的 Figure-level 接口是 catplot,其为 categorical plots 的缩写。而 catplot 实际上是如下 Axes-level 绘图 API 的集合:
-
分类散点图:
stripplot()(kind="strip")swarmplot()(kind="swarm")
-
分类分布图:
boxplot()(kind="box")violinplot()(kind="violin")boxenplot()(kind="boxen")
-
分类估计图:
pointplot()(kind="point")barplot()(kind="bar")countplot()(kind="count")
下面,我们看一下 catplot 绘图效果。该方法默认是绘制 kind="strip" 散点图。
sns.catplot(x="sepal_length", y="species", data=iris)
kind="swarm" 可以让散点按照 beeswarm 的方式防止重叠,可以更好地观测数据分布。
sns.catplot(x="sepal_length", y="species", kind="swarm", data=iris)
输出结果:
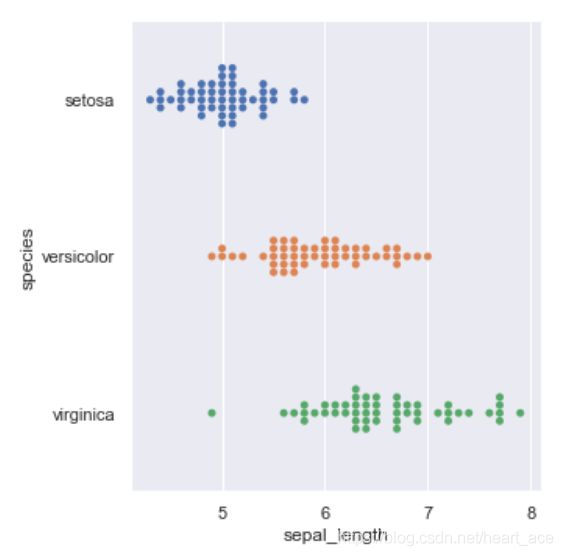
hue= 参数可以给图像引入另一个维度,由于 iris 数据集只有一个类别列,我们这里就不再添加 hue= 参数了。如果一个数据集有多个类别,hue= 参数就可以让数据点有更好的区分。
接下来,我们依次尝试其他几种图形的绘制效果。通过kind参数指定:
- box:箱型图
- boxen:增强箱型图
- violin:小提琴图
- point:点线图
- bar:条形图
- count:计数条形图
这里就不再把图家进行来展示了,快去动手试试吧。
分布图
分布图主要是用于可视化变量的分布情况,一般分为单变量分布和多变量分布。当然这里的多变量多指二元变量,更多的变量无法绘制出直观的可视化图形。
Seaborn 提供的分布图绘制方法一般有这几个:
- jointplot
- pairplot
- distplot
- kdeplot
接下来,我们依次来看一下这些绘图方法的使用。
Seaborn 快速查看单变量分布的方法是 distplot。默认情况下,该方法将会绘制直方图并拟合核密度估计图。
sns.distplot(iris["sepal_length"])
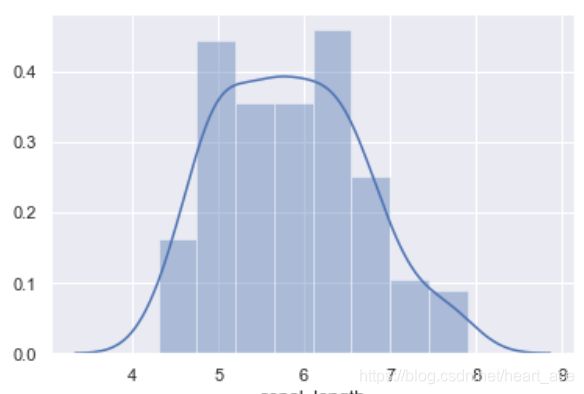
设置 kde=False 可以只绘制直方图,或者 hist=False 只绘制核密度估计图。当然,kdeplot 可以专门用于绘制核密度估计图,其效果和 distplot(hist=False) 一致,但 kdeplot 拥有更多的自定义设置。
jointplot 主要是用于绘制二元变量分布图。例如,当我们要探寻 sepal_length 和 sepal_width 二元特征变量之间的关系。
sns.jointplot(x="sepal_length", y="sepal_width", data=iris)
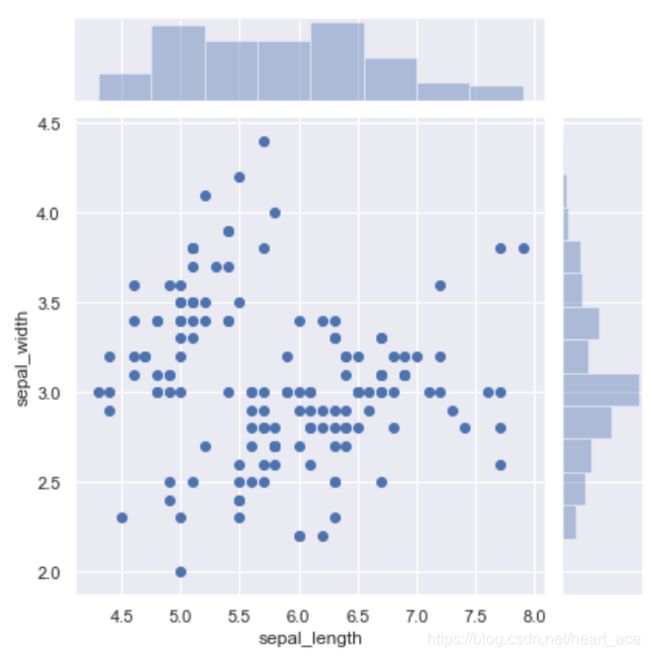
jointplot 并不是一个 Figure-level 接口,但其支持 kind= 参数指定绘制出不同样式的分布图。
- kde :绘制出核密度估计对比图
- hex:六边形计数图
- reg:回归拟合图
最后要介绍的 pairplot 更加强大,其支持一次性将数据集中的特征变量两两对比绘图。默认情况下,对角线上是单变量分布图,而其他则是二元变量分布图。
由于莺尾花数据集是一个类别数据,为了凸显类与类之间的关系,所以我们引入第三维度 hue="species" 会更加直观。
sns.pairplot(iris, hue="species")

回归图
回归图的绘制函数主要有:
- lmplot
- regplot
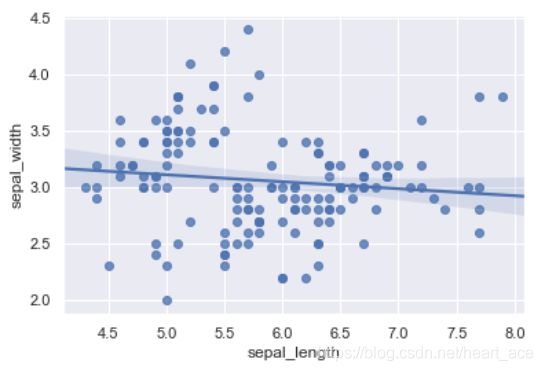
regplot 绘制回归图时,只需要指定自变量和因变量即可,regplot 会自动完成线性回归拟合。
sns.regplot(x="sepal_length", y="sepal_width", data=iris)
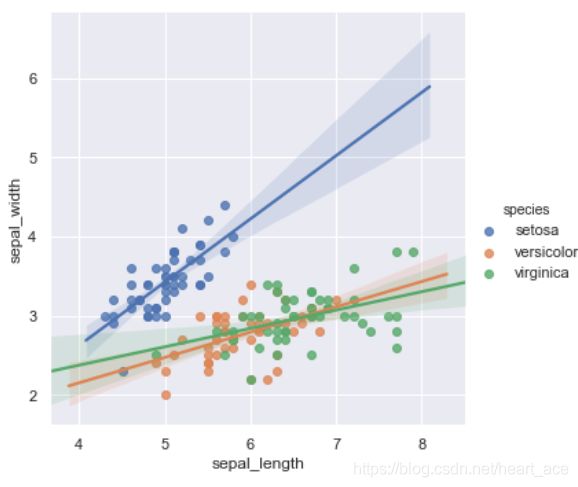
lmplot 同样是用于绘制回归图,但 lmplot 支持引入第三维度进行对比,例如我们设置 hue="species"。
sns.lmplot(x="sepal_length", y="sepal_width", hue="species", data=iris)
矩阵图
矩阵图中最常用的就只有 2 个,分别是:
- heatmap
- clustermap
意如其名,heatmap 主要用于绘制热力图。
import numpy as np
sns.heatmap(np.random.rand(10, 10))
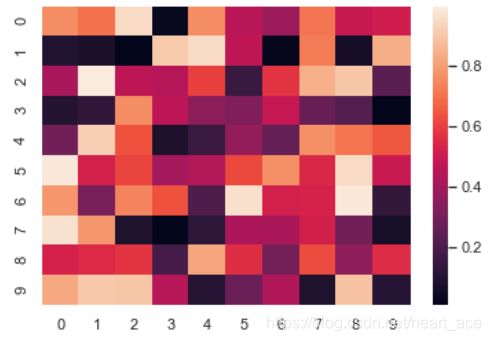
在绘制出变量相关性系数的图形时我们就可以使用这个更好地呈现变量之间的关系。
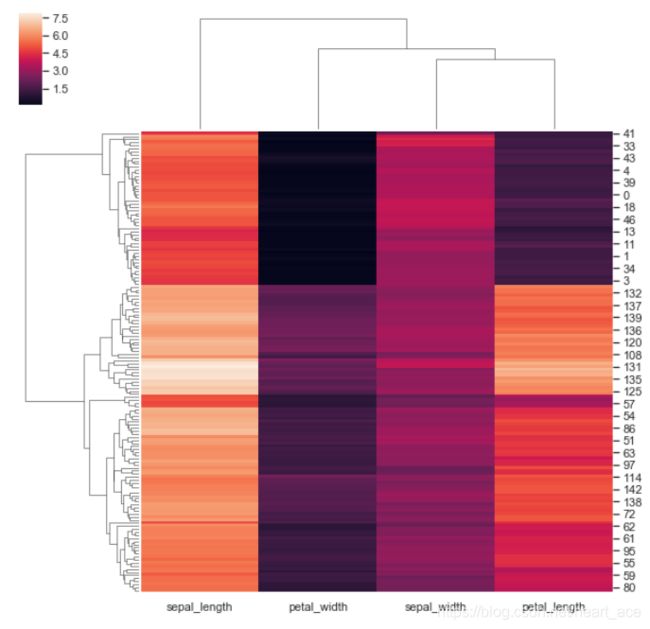
除此之外,clustermap 支持绘制 层次聚类 结构图。
需要先去掉原数据集中最后一个目标列,然后传入特征数据即可。
iris.pop("species")
sns.clustermap(iris)
写在最后
官方文档中有许多的案例,还有一些丰富的调色样式,可以多去参考一下。我就记录一下自己对seaborn的学习记录,发现需要补充的再补充。探索未知,分享知识,共同进步!祝大家2020新年新气象!