使用shell脚本批量curl调用接口
文章目录
-
- @[toc]
- 1. 批量调用接口的方式
-
- 1.1)方式一:业务代码 + curl
- 1.2)方式二 : shell + curl
- 2.curl和wget的使用
-
- 2.1)wget
- 2.2) curl
-
- 2.2.1) curl发送POST请求
- 2.2.2) curl发送GET请求
- 2.2.3) 参数有其他类型
- 3. shell脚本
- 4. 从windows到linux的shell脚本编码和格式
-
- 4.1) 设置模式
- 4.2) 查询编码
- 4.3) 转换编码
- 4.4) 显示指定编码
- 5. 总结
文章目录
-
- @[toc]
- 1. 批量调用接口的方式
-
- 1.1)方式一:业务代码 + curl
- 1.2)方式二 : shell + curl
- 2.curl和wget的使用
-
- 2.1)wget
- 2.2) curl
-
- 2.2.1) curl发送POST请求
- 2.2.2) curl发送GET请求
- 2.2.3) 参数有其他类型
- 3. shell脚本
- 4. 从windows到linux的shell脚本编码和格式
-
- 4.1) 设置模式
- 4.2) 查询编码
- 4.3) 转换编码
- 4.4) 显示指定编码
- 5. 总结
1. 批量调用接口的方式
上一篇文章数据同步后数据总条数对不上的问题解决
文章结尾留下了一个小小的悬念,
问题是:如何批量删除redis中的用户信息?
这种问题最简单粗暴的方式是直接删除那个库或者那个类型前缀的keys,但是是生产环境,不是测试环境,测试环境的话可以随便搞,生产环境还是的小心,可以在凌晨用户不活跃的时候清楚reids的库,清除reids的相关的用户数据,登录的时候检测到access_token过期会重新去走登录流程获取access_token,登录是基于springSecurity+oauther2.0实现的一套搞所有的认证授权的功能,用户信息过期会被打回登录页重新去认证授权登录,那种简单粗暴的方式直接删库的方式会给用户带来不好的体验,所以还是得使用其它稳妥的方式来解决这个问题。
假设用户相关信息存入redis中的key是如下格式,%s拼接的是用户的uid
String USER_REDIS_KEY = "member:info:openid:%s:unionid:%s";
首先需要把需要删除的用户的uid对应的相关数据找出来,将对应的数据存入数据库或者是文件中
1.1)方式一:业务代码 + curl
这种方式是将对应的数据存入数据库,写一个rest风格的接口,使用curl来触发接口执行批量删除redis的用户数据,这种方式就略过了。
1.2)方式二 : shell + curl
这种方式把需要删除的用户的openid、unionid参数放在一个txt的文件中,通过shell读取这个文件,解析组装curl的接口参数进行后端接口的方法调用,进行批量删除用户信息的操作。
上面的两种方法的思路大致的讲解了下,也很简单的,具体的实现就不做过多的分享,so easy!
2.curl和wget的使用
常用命令使用积累如下,还有很多丰富的参数可以加,可以上网参考学习,这个里只是记录工作中常见的用法使用分享记录
2.1)wget
使用wget断点续传下载一个网络上的mp3文件到本地,命令如下:
sudo wget ":"http://xxxxxx:8080/download/record?id=eyJrZXkiOiJiSExIMkkybl9ERF9EWVRaIiwiYWxnIjoiSFMyNTYifQ.eyJyZWNvcmRpbmdVUkwiOiJodHRwOi8vMTIxLjMxLjI1NS4xNzoxMjMwMS9WMi8yMDIxMTAxOTE0MzgwOS9IV05ZXzQ0NjE2ZTY3ZDEwMmZiNTFfMTg4NDk4NTQ1OTZfMTU4ODc0MTAzMTdfMjAyMTEwMTkxNDM4MDkubXAzIiwicmVjb3JkaW5nSWQiOiI0NDYxNmU2N2QxMDJmYjUxIiwiZXhwIjoxNjM0ODg0ODI0fQ.X_pp0VA7lagk9z8uQS8VKSC6dWfqR4gbyaL0USKSZ6k -c -O 123.mp3
2.2) curl
2.2.1) curl发送POST请求
参数内容
-H 请求头
-d POST内容
-X 请求协议
curl -H "Content-Type: application/json" -X POST -d '{"user_id": "123", "coin":100, "success":1, "msg":"OK!" }' "http://xxxxx:8001/test"
2.2.2) curl发送GET请求
参数都是字符串:
curl -H "Content-Type: application/json" -X GET "http://xxxx:8080/wxpay/wechatPay/billQuery?billDate=20220208&appId=wx7a834121bd13a024&channelCode=WECHAT_MINI_PAY&businessId=6"
2.2.3) 参数有其他类型
如下代码的一个参数是Long类型和BigDecimal类型的参数,只要不是字符串的参数,都需要如下处理,在参数的前面加上
--data-urlencode //url参数转义处理
比如有如下一个接口:
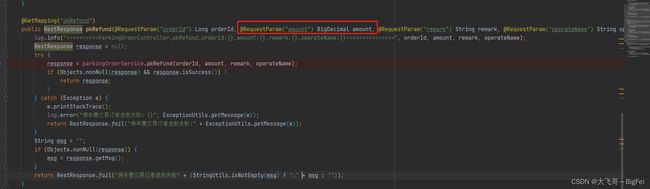
这个也是很坑的点,我也是上网查了好久才知道要这种干的,所以记录,下次需要了直接这种梭哈了:
curl -X GET -G --data-urlencode "orderId=2222400000007" --data-urlencode "amount=5.00" --data-urlencode "remark=测试退款" --data-urlencode "operateName=zlf" -i http://xxxx:8080/park/order/pkRefund
下面三种都是错误的:
curl http://xxxx:8080/park/order/pkRefund?orderId=2222400000007&amount=5&remark=测试退款&operateName=zlf
curl “http://xxxx:8080/park/order/pkRefund?orderId=2222400000007&amount=5&remark=测试退款&operateName=zlf”
curl -X GET “http://xxxx:8080/park/order/pkRefund?orderId=2222400000007&amount=5&remark=测试退款&operateName=zlf”
3. shell脚本
a.txt的内容如下:
openid1 unionid1
openid2 unionid2
openid3 unionid3
.................
openidn unionidn
a.txt的每一行的openid和unionid的值中间用空格隔开,shell解析读取一行,根据这个空格来解析参数的,脚本文件名a.sh
#!/bin/bash
url=$1
while read line
do
#echo $line
OLD_IFS="$IFS"
array=($line)
a=${array[0]}
b=${array[1]}
echo "$a"
echo "$b"
echo "${url}/${a}/${b}"
curl "${url}/${a}/${b}" # 这里使用GET或POST都可以,关键就是传参、解析拼装请求参数,然后调用接口
#echo "successfully"
done<a.txt
给文件授权和执行:
chmod 777 a.txt a.sh
./a.sh http://127.0.0.1:8080/delRedisUserInfor/
4. 从windows到linux的shell脚本编码和格式
从windows到linux的shell脚本编码和格式问题
异常问题 :set ff=unix
启动脚本在启动时报错比如执行sh start.sh,时会报Command not found等等的错误,因为我们在windows编写或修改后的脚本是dos编码,而正常的在Linux系统中执行的是unix编码,在写shell脚本的时候,在windows的上开发后,上传到服务器,可能会有文件格式不正确,通过:set ff unix可以将dos格式设置为unix下的文件格式.
解决方法:则在配置文件中非编辑模式中输入:
ff是fileencoding的简写,如下ff也可以写成fileencoding
#查看模式
:set ff
#修改模式
:set ff=unix
#保存
:wq
4.1) 设置模式
#查看模式,查看当前文本的模式类型,一般为dos,如果是dos需要修改为unix,否则linux运行文件错误
:set ff
#修改模式
:set ff=unix
#保存
:wq
4.2) 查询编码
#查询编码
:set fileencoding
4.3) 转换编码
#转换当前文本的编码为指定的编码,这里的“编码”常见为gbk utf-8 big5 cp936
#设置编码
:set fenc=编码 #比如下面的,注意要:w保存一下,
#设置UTF-8
:set fenc=utf-8
#保存
:wq!
4.4) 显示指定编码
#以指定的编码显示文本,但不保存到文件中。
#这里的“编码”常见为gbk utf-8 big5 cp936
:set enc=编码 #比如:
:set enc=utf-8
:%s/^M//g 这里是如果文本里面有^M结尾的话用此命令。
5. 总结
这也是一个总结做一个记录和分享,不然每次都得去现写和查,有点浪费时间的,所以我的分享希望对你有帮助,请一键三连,么么哒!