多模态生成模型ERNIE-VILG
前言
多模态现在可真谓是一大研究热点,之前我们已经介绍了比较多的多模态模型,感兴趣的小伙伴可以穿梭看之前笔者微信公众号的文章:
多模态预训练模型综述紧跟研究热点,快来打卡多模态知识点吧~ https://mp.weixin.qq.com/s/r95blN2q9OAr7wUfJBxTNQ最新图文大一统多模态模型:FLAVA新年第一弹:最新多模态大一统模型FLAVA来咯~https://mp.weixin.qq.com/s/HxL-bJmM934a9SmVM3xBdw今天我们来介绍一篇最新百度出品的多模态生成模型,名字叫做ERNIE-VILG,话不多说,先上几张文字生成图片的效果
https://mp.weixin.qq.com/s/r95blN2q9OAr7wUfJBxTNQ最新图文大一统多模态模型:FLAVA新年第一弹:最新多模态大一统模型FLAVA来咯~https://mp.weixin.qq.com/s/HxL-bJmM934a9SmVM3xBdw今天我们来介绍一篇最新百度出品的多模态生成模型,名字叫做ERNIE-VILG,话不多说,先上几张文字生成图片的效果




是不是很棒,当然这应该是挑出了效果比较好的几张,大家可以自己亲自去尝试一下:
https://wenxin.baidu.com/wenxin/ernie-vilg
论文地址:
https://arxiv.org/pdf/2112.15283.pdf
不论体验效果好与不好,技术出身的我们还是要去虚心学习一下~
那开始吧~
数据集收集
(1)Chinese Webpages
从各种Webpages收集带有文字的配图
(2)Image Search Engine
通过query-clicked这个逻辑去收集
(3)Public image-text Datase
一些公开数据比如CC、CC12M等等
框架
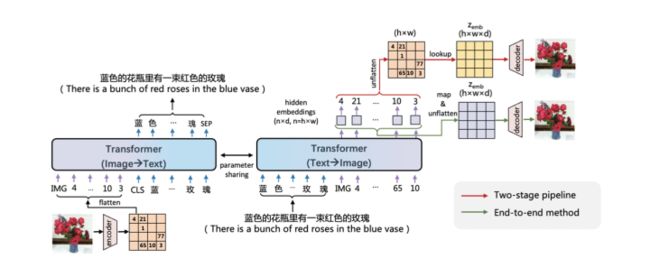
这里采用的框架还是大家熟知的transformer,再具体点就是UniLM即没有将encoder和decoder分开,而是通过mask来达到生成,说白了就是encoder端是bidirectional的,而decoder通过对角线mask来实现单向。
如果大家不熟悉上面说的,可以看下UniLM,由于不是本篇paper的创新点,这里就不多述了。
从上面图中我们看到对于image-to-text任务(左边图),encoder就是图片,decoder生成的就是text,相反亦然。实际过程中两个UniLM参数是共享的。下面我们详细说说各个模型单元细节。
(1)Image Discrete Representation
我们要进行表征,首先要做的就是将image和text进行量化,text大家都比较熟悉了,就是类似bert的tokenizer,而image这里采用的是VQVAE进行编码。
(2)Bidirectional Generative Model
这里本来没什么好说的,就是个常见的生成loss,只不过是两个即image-to-text和text-to-image如下:

t表示text,z表示image
但是这里需要提一下的是sparse attention,这个是一个专门的研究方向,说白了就是transformer在attention的时候是全局attention,导致复杂度是二次方,所以能不能在attention的时候只attention部分?那attention哪部分呢?针对这个问题有很多paper,这里作者采用的方案如下:

大家可以看到不论是在text-to-image中的IMG + img_tokens还是image-to-text 中的CLS + txt_tokens + SEP都是一个上三角MASK,这就是我们之前说的UniLM通过这种方式来完成生成任务,至于其他的MASK就是sparse attention部分,尤其大家可以看到在image-to-text中在对image encoder的时候,采取了一些特殊的MASK。
(3) Text-to-Image Synthesis
这一节着重提了一下文字生成图片的时候一般都采用的是两阶段任务即discrete representation sequence generation和image reconstruction。先生成特征表征![]() ,然后再将其送到reconstructed decoder生成最终的图片。这两部分任务是单独训练的。区别于上述two-stage pipeline的方式,这里作者提出了一种end-to-end的方式。
,然后再将其送到reconstructed decoder生成最终的图片。这两部分任务是单独训练的。区别于上述two-stage pipeline的方式,这里作者提出了一种end-to-end的方式。
具体的这里我们再把框架拿来看一下

红线就是two-stage pipeline,可以看到其有一步是先要得到non-derivable ID即右上角那个带数字的矩阵,然后第二步通过第一步生成的ID去 looked up得到 ![]() ,然后送到decoder生成图片。
,然后送到decoder生成图片。
而作者采用的是绿色的方案即直接将transformer最后一个layer的embedding通过一个MLP层直接映射成 ![]() ,这样整个网络就可以直接梯度回传进而实现end-to-end。
,这样整个网络就可以直接梯度回传进而实现end-to-end。
效果
直观的效果就是开头展示的,关于一些指标的对比如下


对比了一些之前的图文生成模型比如DALL-E 和CogView,总之上就是有提升吧。
总结
关注百度很长时间了,ERNIE系列真的是百花齐放,多模态、跨语种等等都拿到过SOTA,各大榜单频频可见ERNIE,屠榜届的扛霸子。
从其一些列发布的模型不难看出,一个大的基调就是:大力出奇迹。模型越做越大,包括最近其发布的文心大模型,更是史无前例的中文大模型,效果一次次刷新。但是真心希望还是能够全面落地,笔者自己也在ERNIE项目组实习过很长时间,大家确实不易,希望通过落地让这些做技术的同学也可以切实地体会到所做研究的价值。
总之加油~
关注

github:
Mryangkaitong · GitHubhttps://github.com/Mryangkaitong
知乎
小小梦想 - 知乎
知乎: