大模型技术实践(一)|ChatGLM2-6B基于UCloud UK8S的创新应用
近半年来,通过对多款主流大语言模型进行了调研,我们针对其训练方法和模型特点进行逐一分析,方便大家更加深入了解和使用大模型。本文将重点分享ChatGLM2-6B基于UCloud云平台的UK8S实践应用。
01各模型结构及特点
自从2017年6月谷歌推出Transformer以来,它已经成为自然语言处理领域的重要里程碑和核心模型之一。从2018年至今推出的主流模型GPT、BERT、T5、ChatGLM、LLaMA系列模型,都是以Transformer为基本架构实现的。
BERT
使用了Transformer中Encoder编码器。
特点:
1. 双向注意力,也就是说每个时刻的Attention计算都能够得到全部时刻的输入,可同时感知上下文。
2. 适合文本理解,但不适合生成任务。
GPT
使用Transformer中Decoder解码器。
特点:
1. 单向注意力,无法利用下文信息。
2. 适合文本生成领域。
T5
采用Transformer的Encoder-Decoder结构。
改动:
1. 移除了层归一化的偏置项。
2. 将层归一化放置在残差路径之外。
3. 使用了相对位置编码,且是加在Encoder中第一个自注意力的Query和Key乘积之后。
特点:
1. 编码器的注意力是双向的,解码器的注意力是单向的,所以可以同时胜任理解和生成任务。
2. 参数量大。
LLaMA
使用Transformer中Decoder解码器。
改动:
1. 预归一化。对每个Transformer子层的输入进行规范化,而不是对输出进行规范化。
2. SwiGLU激活函数。采用SwiGLU激活函数替换了ReLU。
3. 旋转嵌入。删除了绝对位置嵌入,而在网络的每一层增加了旋转位置嵌入。
特点:
1. LLaMA-13B比GPT-3(参数量为175B)小10倍,但在大多数基准测试中都超过了GPT-3。
2. 没有将中文语料加入预训练,LLaMA在中文上的效果很弱。
ChatGLM
ChatGLM是基于GLM-130B训练得到的对话机器人。GLM使用了一个单独的Transformer。
改动:
1. 自定义Mask矩阵。
2. 重新排列了层归一化和残差连接的顺序。
3. 对于输出的预测标记,使用了一个单独的线性层。
4. 将ReLU激活函数替换为GeLU函数。
5. 二维位置编码。
特点:
通过Mask矩阵,GLM把BERT、GPT、T5这3个模型优点结合起来:

1. 当整个的文本被Mask时,空白填充任务等价于无条件语言生成任务。
2. 当被掩码的片段长度为1时,空白填充任务等价于掩码语言建模任务。
3. 当文本1和文本2拼接在一起时,再将文本2掩码掉,空白填充任务等价于有条件语言生成任务。
随机从一个参数为3的泊松分布中采样片段的长度,直到至少遮盖了原始Token的15%。然后在文本中随机排布填空片段的位置,如Part B所示。另外,Position 1表示的是Mask后的文本中的位置,Position 2表示的是在Mask内部的相对位置。
02训练方法及训练目标
各大语言模型的训练基本都是基于大规模无标签语料来训练初始的语言模型,再利用下游任务的有标签训练语料,进行微调训练。
BERT
BERT使用了Transformer的Encoder作为Block,既参考了ELMo模型的双向编码思想,参考了GPT用Transformer作为特征提取器的方法,又参考了 Word2Vec所使用的CBOW方法。
BERT的训练方法
分为两个阶段,分别是多任务训练目标的预训练阶段和基于有标签语料的微调阶段。
BERT的预训练目标
• 掩码语言模型:Masked Language Model(MLM),目的是提高模型的语义理解能力,即对文本进行随机掩码,然后预测被掩码的词。
• 下句预测:Next Sentence Prediction(NSP),目的是训练句子之间的理解能力,即预测输入语句对(A,B)中,句子B是否为句子A的下一句。
T5
T5模型采用Transformer的Encoder和Decoder,把各种NLP任务都视为Text-to-Text任务。
T5的训练方法
同样采用了预训练和微调的训练策略。
T5模型采用了两个阶段的训练:Encoder-Decoder Pretraining(编码器-解码器预训练)和 Denoising Autoencoder Pretraining(去噪自编码器预训练)。
在Encoder-Decoder Pretraining阶段,T5模型通过将输入序列部分遮盖(用特殊的占位符替换)然后让模型预测被遮盖掉的词或片段。这可以帮助模型学习到上下文理解和生成的能力。
在Denoising Autoencoder Pretraining阶段,T5模型通过将输入序列部分加入噪声或随机置换,然后将模型训练为还原原始输入序列。这可以增强模型对输入的鲁棒性和理解能力。
T5的预训练目标
类似BERT的MLM。T5中可Mask连续多个Token,让模型预测出被Mask掉的Token到底有几个,并且是什么。

GPT
GPT采用两阶段式训练方法
第一阶段:在没有标注的数据集中进行预训练,得到预训练语言模型。
第二阶段:在有标注的下游任务上进行微调。(有监督任务上进行了实验,包括自然语言推理、问答、语义相似度和文本分类等。)
除了常规的有监督微调,引入RLHF(人类反馈强化学习)之后,还需要:
收集数据并训练奖励模型。
使用强化学习对语言模型进行微调。
GPT的训练目标
是从左到右的文本生成,无条件生成。
GPT2
在无Finetune的Zero-Shot场景下进行,也就是“无监督,多任务”。
在原始Input上加入任务相关Prompt,无需微调也可做任务。
GPT3
2020年5月模型参数规模增加到1750亿,大力出奇迹,预训练后不需要微调。
提出了In-Context Learning。
2020年9月,GPT3引入RLHF。
2022年3月的OpenAI发布InstructGPT,也就是GPT3+Instruction Tuning+RLHF+PPO。
GPT4
2023年3月,GPT4支持图片形式输入。
LLaMA
训练一系列语言模型,使用的更多的Token进行训练,在不同的推理预算下达到最佳的性能。
模型参数包括从7B到65B等多个版本:
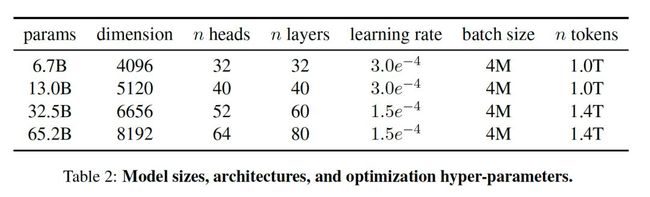
LLaMA的训练方法
无监督预训练。
有监督微调,训练奖励模型,根据人类反馈进行强化学习。
LLaMA的任务
零样本和少样本任务,并在总共20个基准测试上报告了结果:
零样本。提供任务的文本描述和一个测试示例。模型要么通过开放式生成提供答案,要么对提出的答案进行排名。
少样本。提供任务的几个示例(1到64个)和一个测试示例。模型将这个文本作为输入,并生成答案或对不同选项进行排名。
LlaMA2相比于LLaMA
1. 支持更长的上下文,是LLaMA的2倍。
2. 提出Grouped-Query Attention,加速推理。
3. 提出Ghost Attention让多回合对话前后一致。
ChatGLM
对话机器人ChatGLM是基于GLM-130B模型训练得到的。结合模型量化技术,得到可在普通显卡部署的ChatGLM-6B。
GLM的预训练目标
文档级别的目标:从原始本文长度的50%到100%之间均匀分布的范围中进行抽样,得到片段。该目标旨在生成较长的文本。
句子级别的目标:限制被Mask的片段必须是完整的句子。抽样多个片段(句子)来覆盖原始Tokens的15%。该目标旨在用于Seq2seq任务,其中预测通常是完整的句子或段落。
ChatGLM的训练方法
无标签预训练,有监督微调、反馈自助、人类反馈强化学习等技术。
大语言模型小结
大语言模型的训练方式基本是海量无标签数据预训练,下游再用有标签数据微调。从GPT3开始,ChatGLM、LLaMA系列模型也都引入了基于人类反馈的强化学习,让模型与人类偏好对齐,这是一个很酷的想法。
03ChatGLM2-6B在K8S上的实践
获取项目代码和模型文件,相关链接如下
(https://github.com/THUDM/ChatGLM2-6B/tree/main)。
基于UCloud云平台的K8S实践
可参照UCloud文档中心(https://docs.ucloud.cn),登录UCloud控制台(https://console.ucloud.cn/uhost/uhost/create),创建UFS、创建UK8S。
创建文件存储UFS
先创建文件系统,将模型文件存储到UFS中,之后记得添加挂载点。

这是可选项,UFS优点是可多节点挂载。如果不使用UFS,模型文件可放在其他位置,需要在后续的ufspod.yml文件中做相应修改。
创建容器云UK8S
首选创建集群:

可自由选择Node节点到配置:
创建好了之后,界面如下:

接下来可点击右侧的“详情”按钮,在跳转到的新页面左侧,点击“外网凭证”对应行的“查看”,可以看到如下图所示:

根据提示,保存文本内容到~/.kube/config文件中。
在UK8S中的Node节点:
安装Docker
安装英伟达GPU驱动
安装NVIDIA Container Toolkit
在UK8S中使用UFS
根据在UK8S中使用UFS(https://docs.ucloud.cn/uk8s/volume/ufs?id=在uk8s中使用ufs)的文档说明,创建PV和PVC。
登录UK8S的Node节点
首先参照文档安装及配置Kubectl(https://docs.ucloud.cn/uk8s/manageviakubectl/connectviakubectl?id=安装及配置kubectl)。
1. 先放上配置文件Ufspod.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: myfrontend
spec:
selector:
matchLabels:
app: myfrontend
replicas: 1
template:
metadata:
labels:
app: myfrontend
spec:
containers:
- name: myfrontend
image: uhub.service.ucloud.cn/yaoxl/chatglm2-6b:y1
volumeMounts:
- mountPath: "/app/models"
name: mypd
ports:
- containerPort: 7861
volumes:
- name: mypd
persistentVolumeClaim:
claimName: ufsclaim
---
apiVersion: v1
kind: Service
metadata:
name: myufsservice
spec:
selector:
app: myfrontend
type: NodePort
ports:
- name: http
protocol: TCP
port: 7861
targetPort: 7861
nodePort: 30619
2. 执行配置文件Ufspod.yml
kubectl apply -f ufspod.yml
3. 进入Pod
首先通过命令得到Pod Name:
kubectl get po
#NAME READY STATUS RESTARTS AGE
#myfrontend-5488576cb-b2wqw 1/1 Running 0 83m
在Pod内部启动一个Bash Shell:
kubectl exec -it
4. 打开网页版的Demo
执行:
python3 web_demo.py
得到:

UCloud将持续关注大语言模型的发展,并在后续发布有关LlaMA2实践、LangChain构建云上推理环境等方面的文章。欢迎大家保持关注并与我们进行更多交流探讨!