【Kubernetes】记录一次基于ucloud/redis-cluster-operator的可行性测试
文章目录
- 准备工作
-
- 集群信息
- 环境准备
- 重启k8s node
- 大量pod重建
-
- operator正常
-
- 遇到的问题
- 解决方法
- operator停止
- 结论
准备工作
集群信息
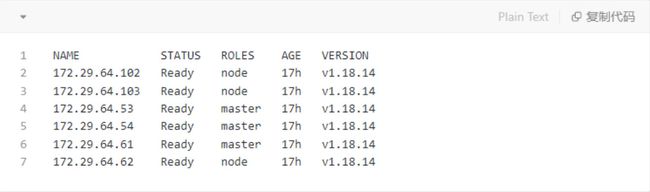
-
该集群使用了calico vxlan网络模式,每个node上面都有calicoctlo工具,可用于管理网络配置;
-
master节点没有设置污点,所以master节点也可以分配pod;
-
集群中redis集群使用的ip池数量改为256,模拟ip池紧张的情况。
[root@172 ~]# calicoctl ipam show +----------+---------------+-----------+------------+--------------+ | GROUPING | CIDR | IPS TOTAL | IPS IN USE | IPS FREE | +----------+---------------+-----------+------------+--------------+ | IP Pool | 172.20.0.0/16 | 65536 | 0 (0%) | 65536 (100%) | | IP Pool | 172.21.0.0/24 | 256 | 256 (100%) | 0 (0%) | +----------+---------------+-----------+------------+--------------+ [root@172 ~]# [root@172 ~]#
环境准备
- 新搭建一个6个节点的k8s集群
- 存储使用ceph,集群安装redis-cluster-operator
- 部署Prometheus、Alertmanager(部署参考)
- 模拟测试环境负载,每个k8s节点上创建100个pod
- 部署redis-cluster-operator(Git地址)
- 创建20个3主3从的redis集群(每个集群6个节点)
- 每次测试完一个项目之后,使用命令:kubectl -n redis delete pod --all删除所有redis pod,此时operator会重新组建所有redis集群,使状态归零
重启k8s node
该步骤主要是模拟k8s集群中节点故障的情况,主要场景有:
- k8s机器故障(重启、关机)
- k8s机器网络故障
将172.29.64.102关机:
[root@172 ~]#
[root@172 ~]# kubectl get no
NAME STATUS ROLES AGE VERSION
172.29.64.102 NotReady 153m v1.18.14
172.29.64.103 Ready 34m v1.18.14
172.29.64.53 Ready 45h v1.18.14
172.29.64.54 Ready 6d18h v1.18.14
172.29.64.61 Ready 2d23h v1.18.14
172.29.64.62 Ready 47h v1.18.14
[root@172 ~]#
[root@172 ~]#
关机之后,该node上的redis集群pod变成Terminating状态:

如果有master节点在当前重启的机器上,会自动failover,当前master转为fail状态,如果为replica,则不做处理。
对于statefulset管理的pod,在宿主机故障后,并不会飘走,会在宿主机恢复之后,继续在当前宿主机上重建。

在此将该node开机,pod会在该node上重建:

集群拓扑恢复:

禁用k8s主机网卡(ifdown eth0)后,现象和关机、重启效果是一致的,并且operator启用或者停止并不影响结论。所以对于这类故障,只要保证同一个redis集群中,少于半数的master不分配到同一个node,以及同一组master和replica不被分配到统一个node即可。
大量pod重建
在operator正常和停止两种情况下,模拟pod大量重建的情况,主要的测试方法有:
- 手动删除k8s node,使该node上的pod全部飘走
- 使用命令kubectl drain命令驱逐pod
operator正常
准备删除的node:172.29.64.61,记录当前node上的redis集群pod
[root@172 ~]# kubectl get pod -n redis -o wide |grep 172.29.64.61
drc-redis-1jndu3-2-1 2/2 Running 0 3d19h 172.21.0.29 172.29.64.61
drc-redis-98ehc7-0-1 2/2 Running 0 3d19h 172.21.0.22 172.29.64.61
drc-redis-ak8sh2-0-1 2/2 Running 0 3d19h 172.21.0.26 172.29.64.61
drc-redis-c9mws6-0-1 2/2 Running 0 3d19h 172.21.0.17 172.29.64.61
drc-redis-ghs8a2-0-1 2/2 Running 0 3d19h 172.21.0.43 172.29.64.61
drc-redis-gosm29-2-1 2/2 Running 0 3d19h 172.21.0.24 172.29.64.61
drc-redis-iu9sh3-2-1 2/2 Running 0 3d19h 172.21.0.232 172.29.64.61
drc-redis-j3dhc8-0-1 2/2 Running 0 3d19h 172.21.0.27 172.29.64.61
drc-redis-j7dn5b-0-1 2/2 Running 0 3d19h 172.21.0.42 172.29.64.61
drc-redis-k93ks7-1-1 2/2 Running 0 3d19h 172.21.0.31 172.29.64.61
drc-redis-l092sh-0-0 2/2 Running 0 3d19h 172.21.0.7 172.29.64.61
drc-redis-ls927h-2-0 2/2 Running 0 3d19h 172.21.0.4 172.29.64.61
drc-redis-m92j3c-1-1 2/2 Running 0 3d19h 172.21.0.18 172.29.64.61
drc-redis-n82sk2-1-1 2/2 Running 0 3d19h 172.21.0.16 172.29.64.61
drc-redis-n82sk2-2-0 2/2 Running 0 3d19h 172.21.0.5 172.29.64.61
drc-redis-nsh38d-2-1 2/2 Running 0 3d19h 172.21.0.23 172.29.64.61
drc-redis-ois92k-0-0 2/2 Running 0 3d19h 172.21.0.20 172.29.64.61
drc-redis-qw8js2-0-1 2/2 Running 0 3d19h 172.21.0.30 172.29.64.61
drc-redis-qw8js2-1-1 2/2 Running 0 3d19h 172.21.0.28 172.29.64.61
drc-redis-su7cm2-0-1 2/2 Running 0 3d19h 172.21.0.25 172.29.64.61
drc-redis-v92ks7-2-0 2/2 Running 0 3d19h 172.21.0.10 172.29.64.61
drc-redis-xw8dn2-1-1 2/2 Running 0 3d19h 172.21.0.38 172.29.64.61
drc-redis-xw8dn2-2-0 2/2 Running 0 3d19h 172.21.0.19 172.29.64.61
drc-redis-z8w2km-0-0 2/2 Running 0 3d19h 172.21.0.6 172.29.64.61
drc-redis3yphqg3p4a-2-0 2/2 Running 0 3d19h 172.21.0.2 172.29.64.61
[root@172 ~]#
选择一个pod,查看当前集群的信息:drc-redis-1jndu3-2-1
172.21.0.29:6379: bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 172.21.0.29:6379@16379 myself,slave e46663ae4a145083e48a499071d26062a7ed7b4d 0 1657002760000 27 connected
e46663ae4a145083e48a499071d26062a7ed7b4d 172.21.0.86:6379@16379 master - 0 1657002761000 30 connected 5461-10922
f7aef53b45415f54aefca34a3d1f66fe875f175f 172.21.0.114:6379@16379 master - 0 1657002760000 31 connected 10923-16383
c43bf83866789ce61af36781054c5a68ddb0da39 172.21.0.255:6379@16379 slave 725e267685d4ad18fe92d686c917294f4e972295 0 1657002761847 29 connected
725e267685d4ad18fe92d686c917294f4e972295 172.21.0.90:6379@16379 master - 0 1657002761000 29 connected 0-5460
b1d2ac39655e91ef5f2c993062cd580ce5b213fd 172.21.0.164:6379@16379 slave f7aef53b45415f54aefca34a3d1f66fe875f175f 0 1657002760000 31 connected
172.21.0.29:6379: cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:31
cluster_my_epoch:30
cluster_stats_messages_ping_sent:323215
cluster_stats_messages_pong_sent:341985
cluster_stats_messages_meet_sent:6
cluster_stats_messages_sent:665206
cluster_stats_messages_ping_received:341979
cluster_stats_messages_pong_received:323220
cluster_stats_messages_meet_received:6
cluster_stats_messages_received:665205
执行删除node的操作:
systemctl stop kubelet 过一会之后 该node变为NotReady状态,该node上的pod状态变为Terminating
[root@172 ~]# kubectl get no
NAME STATUS ROLES AGE VERSION
172.29.64.102 Ready 3d21h v1.18.14
172.29.64.103 Ready 3d20h v1.18.14
172.29.64.53 Ready 6d18h v1.18.14
172.29.64.54 Ready 3d18h v1.18.14
172.29.64.61 NotReady master 20d v1.18.14
172.29.64.62 Ready 6d23h v1.18.14
[root@172 ~]#
[root@172 ~]# kubectl get pod -n redis -o wide |grep 172.29.64.61
drc-redis-1jndu3-2-1 2/2 Terminating 0 3d19h 172.21.0.29 172.29.64.61
drc-redis-98ehc7-0-1 2/2 Terminating 0 3d19h 172.21.0.22 172.29.64.61
drc-redis-ak8sh2-0-1 2/2 Terminating 0 3d19h 172.21.0.26 172.29.64.61
drc-redis-c9mws6-0-1 2/2 Terminating 0 3d19h 172.21.0.17 172.29.64.61
drc-redis-ghs8a2-0-1 2/2 Terminating 0 3d19h 172.21.0.43 172.29.64.61
drc-redis-gosm29-2-1 2/2 Terminating 0 3d19h 172.21.0.24 172.29.64.61
drc-redis-iu9sh3-2-1 2/2 Terminating 0 3d19h 172.21.0.232 172.29.64.61
drc-redis-j3dhc8-0-1 2/2 Terminating 0 3d19h 172.21.0.27 172.29.64.61
drc-redis-j7dn5b-0-1 2/2 Terminating 0 3d19h 172.21.0.42 172.29.64.61
drc-redis-k93ks7-1-1 2/2 Terminating 0 3d19h 172.21.0.31 172.29.64.61
drc-redis-l092sh-0-0 2/2 Terminating 0 3d19h 172.21.0.7 172.29.64.61
drc-redis-ls927h-2-0 2/2 Terminating 0 3d19h 172.21.0.4 172.29.64.61
drc-redis-m92j3c-1-1 2/2 Terminating 0 3d19h 172.21.0.18 172.29.64.61
drc-redis-n82sk2-1-1 2/2 Terminating 0 3d19h 172.21.0.16 172.29.64.61
drc-redis-n82sk2-2-0 2/2 Terminating 0 3d19h 172.21.0.5 172.29.64.61
drc-redis-nsh38d-2-1 2/2 Terminating 0 3d19h 172.21.0.23 172.29.64.61
drc-redis-ois92k-0-0 2/2 Terminating 0 3d19h 172.21.0.20 172.29.64.61
drc-redis-qw8js2-0-1 2/2 Terminating 0 3d19h 172.21.0.30 172.29.64.61
drc-redis-qw8js2-1-1 2/2 Terminating 0 3d19h 172.21.0.28 172.29.64.61
drc-redis-su7cm2-0-1 2/2 Terminating 0 3d19h 172.21.0.25 172.29.64.61
drc-redis-v92ks7-2-0 2/2 Terminating 0 3d19h 172.21.0.10 172.29.64.61
drc-redis-xw8dn2-1-1 2/2 Terminating 0 3d19h 172.21.0.38 172.29.64.61
drc-redis-xw8dn2-2-0 2/2 Terminating 0 3d19h 172.21.0.19 172.29.64.61
drc-redis-z8w2km-0-0 2/2 Terminating 0 3d19h 172.21.0.6 172.29.64.61
drc-redis3yphqg3p4a-2-0 2/2 Terminating 0 3d19h 172.21.0.2 172.29.64.61
但是集群的信息还是正常的
[root@172 ~]# kubectl -n redis exec drc-redis-1jndu3-0-0 -- redis-cli -a 123456 --cluster call 172.21.0.114:6379 cluster nodes
Defaulting container name to redis.
Use 'kubectl describe pod/drc-redis-1jndu3-0-0 -n redis' to see all of the containers in this pod.
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Calling cluster nodes
172.21.0.114:6379: b1d2ac39655e91ef5f2c993062cd580ce5b213fd 172.21.0.164:6379@16379 slave f7aef53b45415f54aefca34a3d1f66fe875f175f 0 1657003838667 31 connected
725e267685d4ad18fe92d686c917294f4e972295 172.21.0.90:6379@16379 master - 0 1657003835000 29 connected 0-5460
c43bf83866789ce61af36781054c5a68ddb0da39 172.21.0.255:6379@16379 slave 725e267685d4ad18fe92d686c917294f4e972295 0 1657003837665 29 connected
e46663ae4a145083e48a499071d26062a7ed7b4d 172.21.0.86:6379@16379 master - 0 1657003835661 30 connected 5461-10922
f7aef53b45415f54aefca34a3d1f66fe875f175f 172.21.0.114:6379@16379 myself,master - 0 1657003836000 31 connected 10923-16383
bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 172.21.0.29:6379@16379 slave e46663ae4a145083e48a499071d26062a7ed7b4d 0 1657003837000 30 connected
172.21.0.164:6379: e46663ae4a145083e48a499071d26062a7ed7b4d 172.21.0.86:6379@16379 master - 0 1657003837000 30 connected 5461-10922
f7aef53b45415f54aefca34a3d1f66fe875f175f 172.21.0.114:6379@16379 master - 0 1657003836000 31 connected 10923-16383
c43bf83866789ce61af36781054c5a68ddb0da39 172.21.0.255:6379@16379 slave 725e267685d4ad18fe92d686c917294f4e972295 0 1657003838113 29 connected
b1d2ac39655e91ef5f2c993062cd580ce5b213fd 172.21.0.164:6379@16379 myself,slave f7aef53b45415f54aefca34a3d1f66fe875f175f 0 1657003835000 28 connected
bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 172.21.0.29:6379@16379 slave e46663ae4a145083e48a499071d26062a7ed7b4d 0 1657003837112 30 connected
725e267685d4ad18fe92d686c917294f4e972295 172.21.0.90:6379@16379 master - 0 1657003837000 29 connected 0-5460
172.21.0.90:6379: b1d2ac39655e91ef5f2c993062cd580ce5b213fd 172.21.0.164:6379@16379 slave f7aef53b45415f54aefca34a3d1f66fe875f175f 0 1657003836901 31 connected
e46663ae4a145083e48a499071d26062a7ed7b4d 172.21.0.86:6379@16379 master - 0 1657003838903 30 connected 5461-10922
f7aef53b45415f54aefca34a3d1f66fe875f175f 172.21.0.114:6379@16379 master - 0 1657003836000 31 connected 10923-16383
725e267685d4ad18fe92d686c917294f4e972295 172.21.0.90:6379@16379 myself,master - 0 1657003837000 29 connected 0-5460
c43bf83866789ce61af36781054c5a68ddb0da39 172.21.0.255:6379@16379 slave 725e267685d4ad18fe92d686c917294f4e972295 0 1657003837902 29 connected
bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 172.21.0.29:6379@16379 slave e46663ae4a145083e48a499071d26062a7ed7b4d 0 1657003837000 30 connected
172.21.0.255:6379: f7aef53b45415f54aefca34a3d1f66fe875f175f 172.21.0.114:6379@16379 master - 0 1657003836708 31 connected 10923-16383
725e267685d4ad18fe92d686c917294f4e972295 172.21.0.90:6379@16379 master - 0 1657003837709 29 connected 0-5460
c43bf83866789ce61af36781054c5a68ddb0da39 172.21.0.255:6379@16379 myself,slave 725e267685d4ad18fe92d686c917294f4e972295 0 1657003838000 24 connected
bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 172.21.0.29:6379@16379 slave e46663ae4a145083e48a499071d26062a7ed7b4d 0 1657003837000 30 connected
b1d2ac39655e91ef5f2c993062cd580ce5b213fd 172.21.0.164:6379@16379 slave f7aef53b45415f54aefca34a3d1f66fe875f175f 0 1657003838712 31 connected
e46663ae4a145083e48a499071d26062a7ed7b4d 172.21.0.86:6379@16379 master - 0 1657003835000 30 connected 5461-10922
172.21.0.86:6379: bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 172.21.0.29:6379@16379 slave e46663ae4a145083e48a499071d26062a7ed7b4d 0 1657003837672 30 connected
f7aef53b45415f54aefca34a3d1f66fe875f175f 172.21.0.114:6379@16379 master - 0 1657003836000 31 connected 10923-16383
725e267685d4ad18fe92d686c917294f4e972295 172.21.0.90:6379@16379 master - 0 1657003837000 29 connected 0-5460
b1d2ac39655e91ef5f2c993062cd580ce5b213fd 172.21.0.164:6379@16379 slave f7aef53b45415f54aefca34a3d1f66fe875f175f 0 1657003835669 31 connected
c43bf83866789ce61af36781054c5a68ddb0da39 172.21.0.255:6379@16379 slave 725e267685d4ad18fe92d686c917294f4e972295 0 1657003838676 29 connected
e46663ae4a145083e48a499071d26062a7ed7b4d 172.21.0.86:6379@16379 myself,master - 0 1657003835000 30 connected 5461-10922
172.21.0.29:6379: bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 172.21.0.29:6379@16379 myself,slave e46663ae4a145083e48a499071d26062a7ed7b4d 0 1657003837000 27 connected
e46663ae4a145083e48a499071d26062a7ed7b4d 172.21.0.86:6379@16379 master - 0 1657003837808 30 connected 5461-10922
f7aef53b45415f54aefca34a3d1f66fe875f175f 172.21.0.114:6379@16379 master - 0 1657003836000 31 connected 10923-16383
c43bf83866789ce61af36781054c5a68ddb0da39 172.21.0.255:6379@16379 slave 725e267685d4ad18fe92d686c917294f4e972295 0 1657003835000 29 connected
725e267685d4ad18fe92d686c917294f4e972295 172.21.0.90:6379@16379 master - 0 1657003837000 29 connected 0-5460
b1d2ac39655e91ef5f2c993062cd580ce5b213fd 172.21.0.164:6379@16379 slave f7aef53b45415f54aefca34a3d1f66fe875f175f 0 1657003838809 31 connected
[root@172 ~]#
接下来删除node
[root@172 ~]# kubectl delete node 172.29.64.61
node "172.29.64.61" deleted
[root@172 ~]#
[root@172 ~]# kubectl get no
NAME STATUS ROLES AGE VERSION
172.29.64.102 Ready 3d21h v1.18.14
172.29.64.103 Ready 3d20h v1.18.14
172.29.64.53 Ready 6d18h v1.18.14
172.29.64.54 Ready 3d18h v1.18.14
172.29.64.62 Ready 6d23h v1.18.14
[root@172 ~]#
这个node上的节点,开始漂移到别的node上
[root@172 ~]# kubectl get pod -n redis -o wide |grep ContainerCreating
drc-redis-1jndu3-2-1 0/2 ContainerCreating 0 25s 172.29.64.54
drc-redis-98ehc7-0-1 0/2 ContainerCreating 0 24s 172.29.64.54
drc-redis-ak8sh2-0-1 0/2 ContainerCreating 0 24s 172.29.64.54
drc-redis-c9mws6-0-1 0/2 ContainerCreating 0 23s 172.29.64.54
drc-redis-ghs8a2-0-1 0/2 ContainerCreating 0 24s 172.29.64.54
drc-redis-gosm29-2-1 0/2 ContainerCreating 0 23s 172.29.64.54
drc-redis-iu9sh3-2-1 0/2 ContainerCreating 0 23s 172.29.64.54
drc-redis-j3dhc8-0-1 0/2 ContainerCreating 0 25s 172.29.64.54
drc-redis-j7dn5b-0-1 0/2 ContainerCreating 0 25s 172.29.64.54
drc-redis-k93ks7-1-1 0/2 ContainerCreating 0 25s 172.29.64.54
drc-redis-l092sh-0-0 0/2 ContainerCreating 0 23s 172.29.64.54
drc-redis-ls927h-2-0 0/2 ContainerCreating 0 23s 172.29.64.54
drc-redis-m92j3c-1-1 0/2 ContainerCreating 0 23s 172.29.64.54
drc-redis-n82sk2-1-1 0/2 ContainerCreating 0 24s 172.29.64.54
drc-redis-n82sk2-2-0 0/2 ContainerCreating 0 25s 172.29.64.54
drc-redis-nsh38d-2-1 0/2 ContainerCreating 0 25s 172.29.64.54
drc-redis-ois92k-0-0 0/2 ContainerCreating 0 23s 172.29.64.54
drc-redis-qw8js2-0-1 0/2 ContainerCreating 0 25s 172.29.64.54
drc-redis-qw8js2-1-1 0/2 ContainerCreating 0 24s 172.29.64.54
drc-redis-su7cm2-0-1 0/2 ContainerCreating 0 25s 172.29.64.54
drc-redis-v92ks7-2-0 0/2 ContainerCreating 0 23s 172.29.64.54
drc-redis-xw8dn2-1-1 0/2 ContainerCreating 0 25s 172.29.64.54
drc-redis-xw8dn2-2-0 0/2 ContainerCreating 0 25s 172.29.64.54
drc-redis-z8w2km-0-0 0/2 ContainerCreating 0 25s 172.29.64.54
drc-redis3yphqg3p4a-2-0 0/2 ContainerCreating 0 24s 172.29.64.54
[root@172 ~]#
此时从redis的集群拓扑来看,pod对应的节点状态为fail
[root@172 ~]# kubectl -n redis exec drc-redis-1jndu3-0-0 -- redis-cli -a 123456 --cluster call 172.21.0.114:6379 cluster nodes
Defaulting container name to redis.
Use 'kubectl describe pod/drc-redis-1jndu3-0-0 -n redis' to see all of the containers in this pod.
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Calling cluster nodes
Could not connect to Redis at 172.21.0.29:6379: Connection refused
172.21.0.114:6379: b1d2ac39655e91ef5f2c993062cd580ce5b213fd 172.21.0.164:6379@16379 slave f7aef53b45415f54aefca34a3d1f66fe875f175f 0 1657004264774 31 connected
725e267685d4ad18fe92d686c917294f4e972295 172.21.0.90:6379@16379 master - 0 1657004263769 29 connected 0-5460
c43bf83866789ce61af36781054c5a68ddb0da39 172.21.0.255:6379@16379 slave 725e267685d4ad18fe92d686c917294f4e972295 0 1657004262767 29 connected
e46663ae4a145083e48a499071d26062a7ed7b4d 172.21.0.86:6379@16379 master - 0 1657004261000 30 connected 5461-10922
f7aef53b45415f54aefca34a3d1f66fe875f175f 172.21.0.114:6379@16379 myself,master - 0 1657004262000 31 connected 10923-16383
bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 172.21.0.29:6379@16379 slave,fail e46663ae4a145083e48a499071d26062a7ed7b4d 1657003994975 1657003990000 30 disconnected
172.21.0.164:6379: e46663ae4a145083e48a499071d26062a7ed7b4d 172.21.0.86:6379@16379 master - 0 1657004264196 30 connected 5461-10922
f7aef53b45415f54aefca34a3d1f66fe875f175f 172.21.0.114:6379@16379 master - 0 1657004263000 31 connected 10923-16383
c43bf83866789ce61af36781054c5a68ddb0da39 172.21.0.255:6379@16379 slave 725e267685d4ad18fe92d686c917294f4e972295 0 1657004262000 29 connected
b1d2ac39655e91ef5f2c993062cd580ce5b213fd 172.21.0.164:6379@16379 myself,slave f7aef53b45415f54aefca34a3d1f66fe875f175f 0 1657004261000 28 connected
bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 172.21.0.29:6379@16379 slave,fail e46663ae4a145083e48a499071d26062a7ed7b4d 1657003992385 1657003990000 30 disconnected
725e267685d4ad18fe92d686c917294f4e972295 172.21.0.90:6379@16379 master - 0 1657004263193 29 connected 0-5460
172.21.0.90:6379: b1d2ac39655e91ef5f2c993062cd580ce5b213fd 172.21.0.164:6379@16379 slave f7aef53b45415f54aefca34a3d1f66fe875f175f 0 1657004264965 31 connected
e46663ae4a145083e48a499071d26062a7ed7b4d 172.21.0.86:6379@16379 master - 0 1657004263962 30 connected 5461-10922
f7aef53b45415f54aefca34a3d1f66fe875f175f 172.21.0.114:6379@16379 master - 0 1657004263000 31 connected 10923-16383
725e267685d4ad18fe92d686c917294f4e972295 172.21.0.90:6379@16379 myself,master - 0 1657004263000 29 connected 0-5460
c43bf83866789ce61af36781054c5a68ddb0da39 172.21.0.255:6379@16379 slave 725e267685d4ad18fe92d686c917294f4e972295 0 1657004262000 29 connected
bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 172.21.0.29:6379@16379 slave,fail e46663ae4a145083e48a499071d26062a7ed7b4d 1657003994180 1657003991177 30 disconnected
172.21.0.255:6379: f7aef53b45415f54aefca34a3d1f66fe875f175f 172.21.0.114:6379@16379 master - 0 1657004263814 31 connected 10923-16383
725e267685d4ad18fe92d686c917294f4e972295 172.21.0.90:6379@16379 master - 0 1657004264818 29 connected 0-5460
c43bf83866789ce61af36781054c5a68ddb0da39 172.21.0.255:6379@16379 myself,slave 725e267685d4ad18fe92d686c917294f4e972295 0 1657004262000 24 connected
bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 172.21.0.29:6379@16379 slave,fail e46663ae4a145083e48a499071d26062a7ed7b4d 1657003993057 1657003990053 30 disconnected
b1d2ac39655e91ef5f2c993062cd580ce5b213fd 172.21.0.164:6379@16379 slave f7aef53b45415f54aefca34a3d1f66fe875f175f 0 1657004261807 31 connected
e46663ae4a145083e48a499071d26062a7ed7b4d 172.21.0.86:6379@16379 master - 0 1657004261000 30 connected 5461-10922
172.21.0.86:6379: bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 172.21.0.29:6379@16379 slave,fail e46663ae4a145083e48a499071d26062a7ed7b4d 1657003994010 1657003990000 30 disconnected
f7aef53b45415f54aefca34a3d1f66fe875f175f 172.21.0.114:6379@16379 master - 0 1657004263000 31 connected 10923-16383
725e267685d4ad18fe92d686c917294f4e972295 172.21.0.90:6379@16379 master - 0 1657004263860 29 connected 0-5460
b1d2ac39655e91ef5f2c993062cd580ce5b213fd 172.21.0.164:6379@16379 slave f7aef53b45415f54aefca34a3d1f66fe875f175f 0 1657004261000 31 connected
c43bf83866789ce61af36781054c5a68ddb0da39 172.21.0.255:6379@16379 slave 725e267685d4ad18fe92d686c917294f4e972295 0 1657004264865 29 connected
e46663ae4a145083e48a499071d26062a7ed7b4d 172.21.0.86:6379@16379 myself,master - 0 1657004261000 30 connected 5461-10922
几分钟之后,pod全部重建完毕,集群恢复正常
此时集群的拓扑为:
[root@172 ~]# kubectl -n redis exec drc-redis-1jndu3-0-0 -- redis-cli -a 123456 --cluster call 172.21.0.114:6379 cluster nodes
Defaulting container name to redis.
Use 'kubectl describe pod/drc-redis-1jndu3-0-0 -n redis' to see all of the containers in this pod.
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
>>> Calling cluster nodes
172.21.0.114:6379: b1d2ac39655e91ef5f2c993062cd580ce5b213fd 172.21.0.164:6379@16379 slave f7aef53b45415f54aefca34a3d1f66fe875f175f 0 1657004455000 31 connected
725e267685d4ad18fe92d686c917294f4e972295 172.21.0.90:6379@16379 master - 0 1657004456507 29 connected 0-5460
c43bf83866789ce61af36781054c5a68ddb0da39 172.21.0.255:6379@16379 slave 725e267685d4ad18fe92d686c917294f4e972295 0 1657004455505 29 connected
e46663ae4a145083e48a499071d26062a7ed7b4d 172.21.0.86:6379@16379 master - 0 1657004455000 30 connected 5461-10922
f7aef53b45415f54aefca34a3d1f66fe875f175f 172.21.0.114:6379@16379 myself,master - 0 1657004452000 31 connected 10923-16383
bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 172.21.0.7:6379@16379 slave e46663ae4a145083e48a499071d26062a7ed7b4d 0 1657004453501 30 connected
172.21.0.164:6379: e46663ae4a145083e48a499071d26062a7ed7b4d 172.21.0.86:6379@16379 master - 0 1657004455118 30 connected 5461-10922
f7aef53b45415f54aefca34a3d1f66fe875f175f 172.21.0.114:6379@16379 master - 0 1657004456120 31 connected 10923-16383
c43bf83866789ce61af36781054c5a68ddb0da39 172.21.0.255:6379@16379 slave 725e267685d4ad18fe92d686c917294f4e972295 0 1657004455000 29 connected
b1d2ac39655e91ef5f2c993062cd580ce5b213fd 172.21.0.164:6379@16379 myself,slave f7aef53b45415f54aefca34a3d1f66fe875f175f 0 1657004452000 28 connected
bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 172.21.0.7:6379@16379 slave e46663ae4a145083e48a499071d26062a7ed7b4d 0 1657004453000 30 connected
725e267685d4ad18fe92d686c917294f4e972295 172.21.0.90:6379@16379 master - 0 1657004453114 29 connected 0-5460
172.21.0.90:6379: b1d2ac39655e91ef5f2c993062cd580ce5b213fd 172.21.0.164:6379@16379 slave f7aef53b45415f54aefca34a3d1f66fe875f175f 0 1657004455000 31 connected
e46663ae4a145083e48a499071d26062a7ed7b4d 172.21.0.86:6379@16379 master - 0 1657004455000 30 connected 5461-10922
f7aef53b45415f54aefca34a3d1f66fe875f175f 172.21.0.114:6379@16379 master - 0 1657004456000 31 connected 10923-16383
725e267685d4ad18fe92d686c917294f4e972295 172.21.0.90:6379@16379 myself,master - 0 1657004454000 29 connected 0-5460
c43bf83866789ce61af36781054c5a68ddb0da39 172.21.0.255:6379@16379 slave 725e267685d4ad18fe92d686c917294f4e972295 0 1657004455657 29 connected
bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 172.21.0.7:6379@16379 slave e46663ae4a145083e48a499071d26062a7ed7b4d 0 1657004456659 30 connected
172.21.0.255:6379: f7aef53b45415f54aefca34a3d1f66fe875f175f 172.21.0.114:6379@16379 master - 0 1657004456517 31 connected 10923-16383
725e267685d4ad18fe92d686c917294f4e972295 172.21.0.90:6379@16379 master - 0 1657004454514 29 connected 0-5460
c43bf83866789ce61af36781054c5a68ddb0da39 172.21.0.255:6379@16379 myself,slave 725e267685d4ad18fe92d686c917294f4e972295 0 1657004455000 24 connected
bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 172.21.0.7:6379@16379 slave e46663ae4a145083e48a499071d26062a7ed7b4d 0 1657004453512 30 connected
b1d2ac39655e91ef5f2c993062cd580ce5b213fd 172.21.0.164:6379@16379 slave f7aef53b45415f54aefca34a3d1f66fe875f175f 0 1657004455516 31 connected
e46663ae4a145083e48a499071d26062a7ed7b4d 172.21.0.86:6379@16379 master - 0 1657004455000 30 connected 5461-10922
172.21.0.86:6379: bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 172.21.0.7:6379@16379 slave e46663ae4a145083e48a499071d26062a7ed7b4d 0 1657004456664 30 connected
f7aef53b45415f54aefca34a3d1f66fe875f175f 172.21.0.114:6379@16379 master - 0 1657004456000 31 connected 10923-16383
725e267685d4ad18fe92d686c917294f4e972295 172.21.0.90:6379@16379 master - 0 1657004453658 29 connected 0-5460
b1d2ac39655e91ef5f2c993062cd580ce5b213fd 172.21.0.164:6379@16379 slave f7aef53b45415f54aefca34a3d1f66fe875f175f 0 1657004455000 31 connected
c43bf83866789ce61af36781054c5a68ddb0da39 172.21.0.255:6379@16379 slave 725e267685d4ad18fe92d686c917294f4e972295 0 1657004455000 29 connected
e46663ae4a145083e48a499071d26062a7ed7b4d 172.21.0.86:6379@16379 myself,master - 0 1657004454000 30 connected 5461-10922
172.21.0.7:6379: e46663ae4a145083e48a499071d26062a7ed7b4d 172.21.0.86:6379@16379 master - 0 1657004455000 30 connected 5461-10922
b1d2ac39655e91ef5f2c993062cd580ce5b213fd 172.21.0.164:6379@16379 slave f7aef53b45415f54aefca34a3d1f66fe875f175f 0 1657004455000 31 connected
bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 172.21.0.7:6379@16379 myself,slave e46663ae4a145083e48a499071d26062a7ed7b4d 0 1657004453000 27 connected
f7aef53b45415f54aefca34a3d1f66fe875f175f 172.21.0.114:6379@16379 master - 0 1657004456215 31 connected 10923-16383
c43bf83866789ce61af36781054c5a68ddb0da39 172.21.0.255:6379@16379 slave 725e267685d4ad18fe92d686c917294f4e972295 0 1657004455213 29 connected
725e267685d4ad18fe92d686c917294f4e972295 172.21.0.90:6379@16379 master - 0 1657004454000 29 connected 0-5460
可以看到bcfe13a0763cc503ce1f7bd89cdc74174b13acc3这个节点的ip由之前的172.21.0.29变为了172.21.0.7
查看该节点的master节点日志
[root@172 ~]# kubectl get pod -n redis -o wide |grep 172.21.0.86
drc-redis-1jndu3-2-0 2/2 Running 0 3d20h 172.21.0.86 172.29.64.103
[root@172 ~]#
kubectl logs drc-redis-1jndu3-2-0 -n redis -c redis
1:M 05 Jul 2022 14:53:30.057 * FAIL message received from f7aef53b45415f54aefca34a3d1f66fe875f175f about bcfe13a0763cc503ce1f7bd89cdc74174b13acc3
1:M 05 Jul 2022 15:00:14.177 # Address updated for node bcfe13a0763cc503ce1f7bd89cdc74174b13acc3, now 172.21.0.7:6379
1:M 05 Jul 2022 15:00:14.311 * Clear FAIL state for node bcfe13a0763cc503ce1f7bd89cdc74174b13acc3: replica is reachable again.
1:M 05 Jul 2022 15:00:15.180 * Replica 172.21.0.7:6379 asks for synchronization
1:M 05 Jul 2022 15:00:15.180 * Unable to partial resync with replica 172.21.0.7:6379 for lack of backlog (Replica request was: 9731).
1:M 05 Jul 2022 15:00:15.180 * Starting BGSAVE for SYNC with target: disk
1:M 05 Jul 2022 15:00:15.180 * Background saving started by pid 9737
9737:C 05 Jul 2022 15:00:16.396 * DB saved on disk
9737:C 05 Jul 2022 15:00:16.396 * RDB: 0 MB of memory used by copy-on-write
1:M 05 Jul 2022 15:00:16.477 * Background saving terminated with success
1:M 05 Jul 2022 15:00:16.477 * Synchronization with replica 172.21.0.7:6379 succeeded
master已自动刷新replica的节点ip
接下来看,如果重启的redis pod是master的情况,正好使用刚才看的master节点drc-redis-1jndu3-2-0所在的172.29.64.103来测试
前面的步骤和现象基本一致,差异在于:执行完kubectl delete node之后,master节点重新创建pod,节点处于ContainerCreating时,replica发起复制请求,连接拒绝,几个重试周期之后,replica执行failover
1:S 05 Jul 2022 15:45:16.336 * MASTER <-> REPLICA sync started
1:S 05 Jul 2022 15:45:16.338 # Error condition on socket for SYNC: Connection refused
1:S 05 Jul 2022 15:45:17.341 * Connecting to MASTER 172.21.0.86:6379
1:S 05 Jul 2022 15:45:17.341 * MASTER <-> REPLICA sync started
1:S 05 Jul 2022 15:45:17.341 # Error condition on socket for SYNC: Connection refused
1:S 05 Jul 2022 15:45:18.345 * Connecting to MASTER 172.21.0.86:6379
1:S 05 Jul 2022 15:45:18.345 * MASTER <-> REPLICA sync started
1:S 05 Jul 2022 15:45:18.346 # Error condition on socket for SYNC: Connection refused
1:S 05 Jul 2022 15:45:18.846 # Start of election delayed for 936 milliseconds (rank #0, offset 466760).
1:S 05 Jul 2022 15:45:18.946 # Currently unable to failover: Waiting the delay before I can start a new failover.
1:S 05 Jul 2022 15:45:19.347 * Connecting to MASTER 172.21.0.86:6379
1:S 05 Jul 2022 15:45:19.347 * MASTER <-> REPLICA sync started
1:S 05 Jul 2022 15:45:19.348 # Error condition on socket for SYNC: Connection refused
1:S 05 Jul 2022 15:45:19.849 # Starting a failover election for epoch 33.
1:S 05 Jul 2022 15:45:19.946 # Currently unable to failover: Waiting for votes, but majority still not reached.
1:S 05 Jul 2022 15:45:19.949 # Failover election won: I'm the new master.
1:S 05 Jul 2022 15:45:19.949 # configEpoch set to 33 after successful failover
1:M 05 Jul 2022 15:45:19.949 # Setting secondary replication ID to 6789a5a7e12916e0919aacad98a9f6a976baff68, valid up to offset: 466761. New replication ID is 0cd8ea1beec717117ba7d707b39a5c0c023af7a2
1:M 05 Jul 2022 15:45:19.949 * Discarding previously cached master state.
1:M 05 Jul 2022 15:45:19.949 # Cluster state changed: ok
待pod重建完成后,会重新加入到集群,成为当前master的replica
1:M 05 Jul 2022 15:50:58.250 # Address updated for node e46663ae4a145083e48a499071d26062a7ed7b4d, now 172.21.0.225:6379
1:M 05 Jul 2022 15:50:58.380 * Clear FAIL state for node e46663ae4a145083e48a499071d26062a7ed7b4d: master without slots is reachable again.
1:M 05 Jul 2022 15:50:59.285 * Replica 172.21.0.225:6379 asks for synchronization
1:M 05 Jul 2022 15:50:59.285 * Partial resynchronization not accepted: Replication ID mismatch (Replica asked for 'f16cc5c63b5bb54f8a5a2fd2ab2bd8eb45fdf910', my replication IDs are '0cd8ea1beec717117ba7d707b39a5c0c023af7a2' and '6789a5a7e12916e0919aacad98a9f6a976baff68')
1:M 05 Jul 2022 15:50:59.285 * Starting BGSAVE for SYNC with target: disk
1:M 05 Jul 2022 15:50:59.285 * Background saving started by pid 3677
3677:C 05 Jul 2022 15:50:59.408 * DB saved on disk
3677:C 05 Jul 2022 15:50:59.409 * RDB: 0 MB of memory used by copy-on-write
1:M 05 Jul 2022 15:50:59.468 * Background saving terminated with success
1:M 05 Jul 2022 15:50:59.468 * Synchronization with replica 172.21.0.225:6379 succeeded
172.21.0.7:6379: e46663ae4a145083e48a499071d26062a7ed7b4d 172.21.0.225:6379@16379 slave bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 0 1657007691000 33 connected
b1d2ac39655e91ef5f2c993062cd580ce5b213fd 172.21.0.164:6379@16379 slave f7aef53b45415f54aefca34a3d1f66fe875f175f 0 1657007692000 31 connected
bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 172.21.0.7:6379@16379 myself,master - 0 1657007690000 33 connected 5461-10922
f7aef53b45415f54aefca34a3d1f66fe875f175f 172.21.0.114:6379@16379 master - 0 1657007689000 31 connected 10923-16383
c43bf83866789ce61af36781054c5a68ddb0da39 172.21.0.255:6379@16379 slave 725e267685d4ad18fe92d686c917294f4e972295 0 1657007692000 29 connected
725e267685d4ad18fe92d686c917294f4e972295 172.21.0.90:6379@16379 master - 0 1657007692981 29 connected 0-5460
172.21.0.225:6379: c43bf83866789ce61af36781054c5a68ddb0da39 172.21.0.255:6379@16379 slave 725e267685d4ad18fe92d686c917294f4e972295 0 1657007690633 29 connected
e46663ae4a145083e48a499071d26062a7ed7b4d 172.21.0.225:6379@16379 myself,slave bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 0 1657007689000 30 connected
f7aef53b45415f54aefca34a3d1f66fe875f175f 172.21.0.114:6379@16379 master - 0 1657007689000 31 connected 10923-16383
725e267685d4ad18fe92d686c917294f4e972295 172.21.0.90:6379@16379 master - 0 1657007692639 29 connected 0-5460
bcfe13a0763cc503ce1f7bd89cdc74174b13acc3 172.21.0.7:6379@16379 master - 0 1657007691636 33 connected 5461-10922
b1d2ac39655e91ef5f2c993062cd580ce5b213fd 172.21.0.164:6379@16379 slave f7aef53b45415f54aefca34a3d1f66fe875f175f 0 1657007691000 31 connected
可以看到,之前的172.21.0.7变成了master,之前的172.21.0.86在pod重建完成之后,ip变为172.21.0.225,并成为172.21.0.7的replica
使用命令kubectl drain 172.29.64.53 --ignore-daemonsets --delete-local-data驱逐node上的pod,结论也同上。
遇到的问题
在operator启用的条件下,经过反复测试,遇到一个问题,复现问题的步骤为:
- 在k8s nodeA(ip:172.29.64.102)上执行systemctl stop kubelet,停掉kubelet之后,再执行kubectl delete node 172.29.64.102;
- 删除nodeA之后,nodeA上的所有pod会飘到其他node上,等所有pod重建完成;
- 将nodeA的kubelet启动:systemctl start kubelet,nodeA会重新加入到k8s集群(当前node上的redis pod容器会自动销毁);
- 在另一台nodeB(ip:172.29.64.53)上执行步骤1的操作;
- 将nodeB删除之后,nodeB上的pod会根据分配策略,大部分分配到空的nodeA上,此时会出现集群拓扑异常的情况
记录下nodeA上的pod:
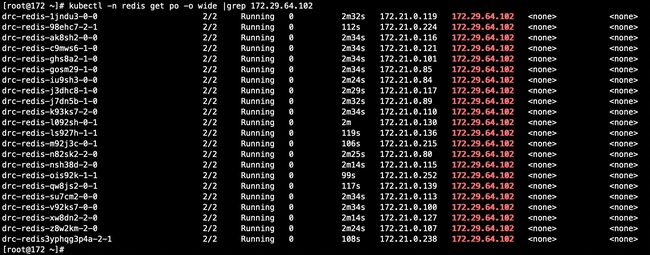
删除nodeA:

nodeA上的pod被分配到其他node上:

大概等了五六分钟,所有pod重建完成,所有集群状态也正常,此时将nodeA重新加入k8s集群:systemctl start kubelet

接下来删除nodeB:

nodeB上的pod开始重建,可以看到基本都重建到了空的nodeA上了:
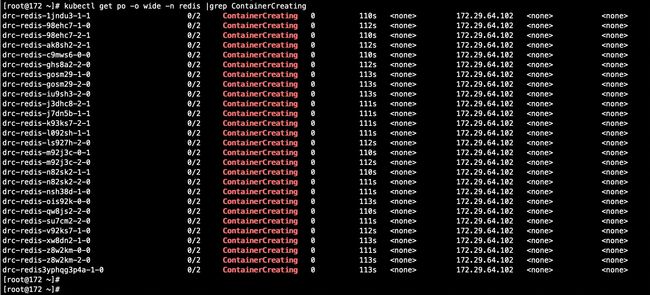
pod重建完成:

异常集群:

异常集群1:

异常集群2:

经过观察发现,异常的这两个集群,公享了6个节点,也就是有6个节点,既在集群1的拓扑里,也在集群2的拓扑里,找到其中一个观察:

172.21.0.213这个ip对应的pod,并不应该加到集群nsh38d的拓扑里,出现这种情况之后,使用命令kubectl delete pod -n redis --all删除全部redis节点也无法恢复。
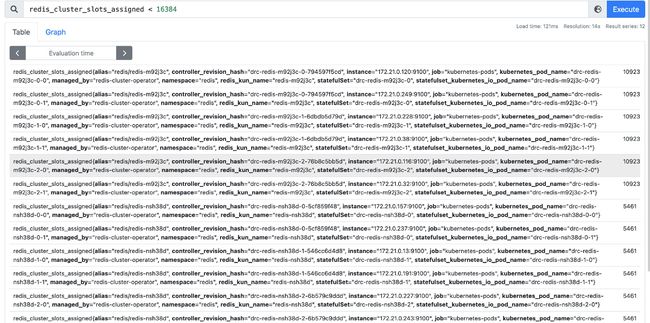

还有一种情况是集群的节点数小于6,下图结果为其他次测试出现的:

解决方法
每次删除node之前,先把该node上的docker停止,保证node上的容器都停掉。
operator停止
先将operator进行缩容:
[root@172 ~]# kubectl scale -n redis deployment/redis-cluster-operator --replicas=0
deployment.apps/redis-cluster-operator scaled
[root@172 ~]# kubectl -n redis get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
redis-cluster-operator 0/0 0 0 20d
[root@172 ~]#
[root@172 ~]#
删除其中一个node

pod开始飘走
所有pod正常重建,无异常告警产生,所有redis集群状态正常。
下面测试一下是否会出现上节中的问题。
将之前的node重新加入k8s集群
[root@172 ~]# systemctl start kubelet
[root@172 ~]#
[root@172 ~]#
[root@172 ~]# kubectl get no
NAME STATUS ROLES AGE VERSION
172.29.64.102 Ready <none> 12s v1.18.14
172.29.64.103 Ready <none> 2d16h v1.18.14
172.29.64.53 Ready <none> 43h v1.18.14
172.29.64.54 Ready <none> 6d16h v1.18.14
172.29.64.61 Ready <none> 2d20h v1.18.14
172.29.64.62 Ready <none> 45h v1.18.14
[root@172 ~]#
删除另一个node:
[root@172 ~]# systemctl stop kubelet
[root@172 ~]#
[root@172 ~]# kubectl get no
NAME STATUS ROLES AGE VERSION
172.29.64.102 Ready 107m v1.18.14
172.29.64.103 NotReady 2d18h v1.18.14
172.29.64.53 Ready 45h v1.18.14
172.29.64.54 Ready 6d17h v1.18.14
172.29.64.61 Ready 2d22h v1.18.14
172.29.64.62 Ready 46h v1.18.14
[root@172 ~]#
[root@172 ~]#
[root@172 ~]# kubectl delete node 172.29.64.103
node "172.29.64.103" deleted
[root@172 ~]#
[root@172 ~]#
[root@172 ~]#
[root@172 ~]# kubectl get no
NAME STATUS ROLES AGE VERSION
172.29.64.102 Ready 108m v1.18.14
172.29.64.53 Ready 45h v1.18.14
172.29.64.54 Ready 6d17h v1.18.14
172.29.64.61 Ready 2d22h v1.18.14
172.29.64.62 Ready 47h v1.18.14
[root@172 ~]#
[root@172 ~]#
pod开始飘走:

待所有pod重建完成之后,并没有出现拓扑异常的redis集群。
结论
整个测试过程中,可以发现ucloud/redis-cluster-operator对于常见的故障,有较好的支持,对于一些较为暴力的测试,也能保证redis集群的正常,对于一些极端情况,导致出现redis集群拓扑异常的情况,可以通过严谨的运维步骤来规避,总体来说,如果需要选择一款redis集群的operator,ucloud/redis-cluster-operator可以作为一个很好的选择,当然,这个项目目前处于非活跃状态,涉及到需求变更或者问题只能自己来完成。