Kubernetes kubelet 状态上报/节点资源的管理
节点资源管理
NUMA
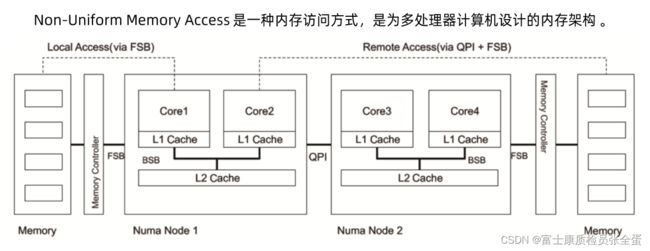
针对多核的计算机架构,一个计算机上面会有多个CPU的插槽,它也会有多个内存的插槽,这样从硬件体系来看,不同的CPU和内存联动的关系就不一样的,可以看到每个numa node有独立的cpu和内存。
所以的话cpu在访问内存的时候,如果这些内存在不同的numa节点上面,它们的访问效率是不一样的。
节点资源管理

状态上报
kubelet 是部署在每个Kubernetes 节点上、负责Pod 生命周期及节点状态上报的组件。 它周期性地向 API Server 进行汇报,并更新节点的相关健康和资源使用信息,以供Kubernetes 的控制平面模块对节点和节点上的Pod 进行管理和决策。上报信息如下:
- 节点基础信息,包括IP 地址、操作系统、内核、运行时、kubelet、kube-proxy 版本信息。部分信息直接从节点获取,而部分信息需要调用云提供商的API 获取。
- 节点资源信息包括CPU、内存、Hugepage、临时存储、GPU 等注册设备,以及这些资源中可以分配给容器使用的部分。
- 调度器在为Pod 选择节点时会将机器的状态信息作为依据。表2-6 展示了节点状态 及其代表的意义。比如Ready 状态反映了节点是否就绪,True 表示节点健康;False 表示节点不健康;Unknown 表示节点控制器在最近40s 内没有收到节点的消息。调度器在调度Pod 时会过滤掉所有Ready 状态为非True 的节点。

以下三个参数可以控制kubelet 更新节点状态频率:
- NodeStatusUpdateFrequency
- NodeStatusReportFrequency
- NodeLeaseDurationSeconds
状态上报

kubelet最重要的职责是去监听APIServer,然后有任何pod清单的变更,它要来处理这个pod的生命周期,另外就是间歇性的汇报节点的状态,往apiserver去上报。
上报有两部分内容,一部分是节点的健康信息,也就是这个节点是不是还活着,第二个就是节点的资源使用情况。
这个资源使用情况更多的是及时的汇报给集群,让apiserver知道从资源使用情况来说资源承载的压力是怎么样的。
如果有内存压力或者磁盘压力,那么调度器就不应该将pod再调度过去了。
Lease

状态如何上报的,在早期kubelet的版本里面,通常健康状况和资源使用情况是一起上报的,那么每次上报第一要确保时效性,因为你周期太长的话,节点坏了,APIserver看你还不知道,那么就需要保持时效性,汇报的频度就比较快,汇报频度快,每次都带着详细信息,那么就意味着数据传输量比较大,节点层面信息量不一定大,但是集群很大的时候,那么apiserver承受的并发压力还是不小的。
后期资源上报和健康状态的上报都被拆离开来了,健康状态的上报就是通过lease对象去上报的,默认上报会以40s为周期不断的向上汇报,资源使用情况是使用更加慢的频率去上报的。
kubectl describe node xx所看的这些信息都会统一上报,这些信息是按照资源信息去去上报的。
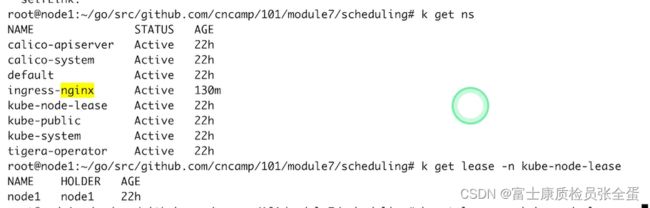
可以看到每个节点都有lease对象, 这个lease对象里面存的是,之前说controller manager的时候说过,当多个节点要去持有,想去开启leader election模式的时候,当有多个控制器,那么就需要一个人去抢锁,抢到锁之后就需要不停的renew,其他人抢不到这个锁,它就要一直监听,直到leader没有renew及时renew,它的任期过期了,那么后面的人就可以获取锁继续指向。
所以都会有个任期的概念,所以为了支持这种模式,后期k8s就将任期变为了一个对象叫做lease这样一个对象,这个对象就适用于leader election场景,对于新版本的k8s的leader election不用去创建configmap或者secret或者endpoint,你应该依赖的对象就是lease对象,所以lease对象的spec就是将我们之前看到的configmap里面的或者endpoint里面的annotation变为标准化了。
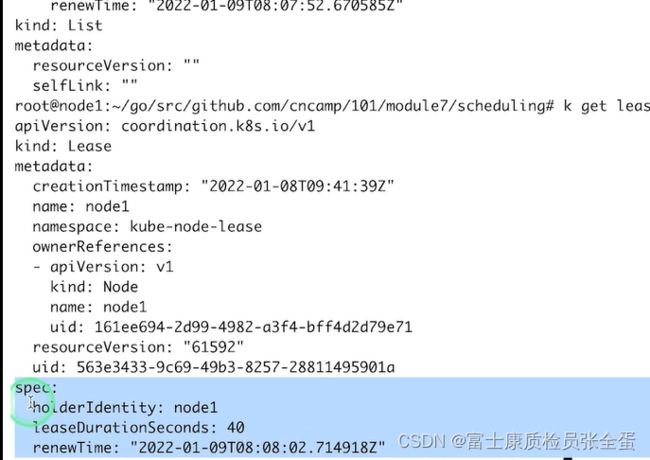
这里面定义了holderidentity是谁,也就是lease是谁持有的,然后租约是多久40s,renew是多久去更新它的。
也就是k8s会不停的更新去更新这个renew time,来确保节点的租约一直有效,通过这种方式,虽然没有人和它抢锁,但是它自己可以来renew这个lease对象来代表自己是活着的,通过维护有效租期来达到这个目的。
所以renewtime是不停的变化的,所以kubelet会一直每隔40s会去续约。
资源预留

任何计算节点,除了用户的容器之外,还有支撑系统运行的基础服务,这些服务不是通过kuberenetes拉起来的,这些服务是有资源开销的,有资源开销就需要为其预留一些,否则不为这些服务预留,通常配置k8s的时候都会去定义一下要为这个系统预留多少资源,然后剩下的才是可以分配的资源。
Capacity和Allocated
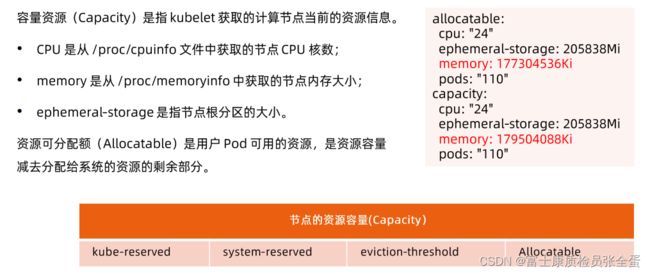
capacity更多的是我这个节点的能力是多少,这些信息是从/proc/cpuinfo中去取的,你真正的预留的资源是capacity - allocated资源。
节点磁盘管理

节点磁盘管理通常可以分为nodefs和imagefs,nodefs是保存了工作目录,就是保存了datadir和logdir容器日志的目录。(比如empty dir和它日志这些数据目录所在的地方)
imagefs就是当我这个容器镜像层层加载的时候,它所解压文件所在的目录。
上面两个是可以独立管控的,分别为这两个文件系统配置容量,当然你也可以不设置imagefs统一的纳管起来。
驱逐管理
kubelet在资源不够的情况下要终止容器进程,使得这些资源可以释放,保证节点不死。

Kubelet发起的驱逐,它需要留下一些痕迹, 不能只将pod删除掉,从用户的角度都看不到发生了什么事件,发生驱逐的时候是通过evict命令将pod驱逐掉,它并不会删除pod,这个pod的实体还在,但是会将其状态置为evicted。
这个目的是为了你做审计的时候,无论作为管理员还是用户,只要查看evict的message就可以知道它之前发生了什么事情。
资源可以额监控
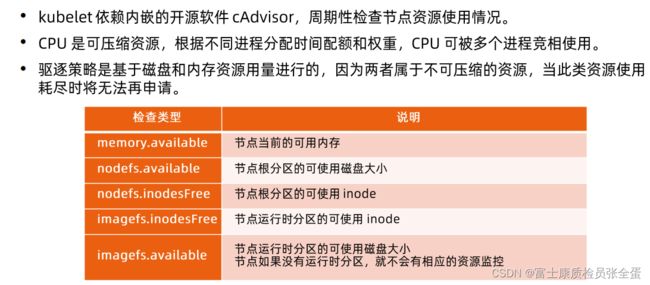
驱逐策略
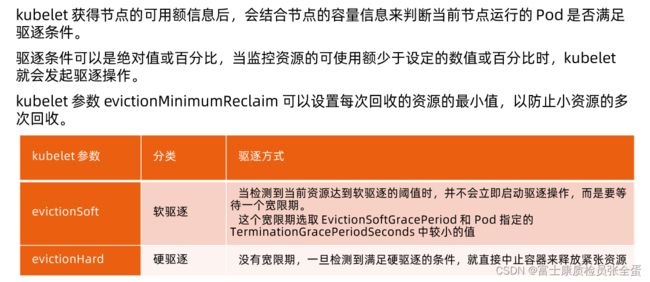 可以设置回收的最小值,什么情况下发起驱逐,每次驱逐的时候最少要驱逐多少,通过这种方式防止小资源多次回收,就一次性回收,若不是回收一点再看是不是承压,这样效果就慢。通过这个参数设置最少一次要驱逐多少。
可以设置回收的最小值,什么情况下发起驱逐,每次驱逐的时候最少要驱逐多少,通过这种方式防止小资源多次回收,就一次性回收,若不是回收一点再看是不是承压,这样效果就慢。通过这个参数设置最少一次要驱逐多少。

硬驱逐:设定当低于这个值的时候,我就要去做硬驱逐。然后下面是定义,定义每次至少要驱逐多少资源。

nodefs和imagefs区别,nodefs就是容器的数据目录和日志所在的目录,无论是contained还是docker存放的目录都是在/var/lib/kubelet下面,这个数据和日志都在这下面。
imagesfs, 当overyfs去加载一个容器镜像的时候,存在的路径为/var/lib/container /var/lib/docker。
所以可以分别针对这两个文件路径去设置驱逐阈值,也可以将其合并,一起去设置。
基于内存压力的驱逐

besteffort是不申请任何的资源,节点都扛不住压力了,肯定不认你过来。
针对grantee类型pod,它一定不会超过的,大部分情况下pod可以通过burtest超售方式去增加部署密度,总量超出了request,超出request的pod会成为被选目标。
还有就是超过的越多,越容易被驱逐。通过这种策略层层筛选,选择出驱逐的pod进行驱逐。
基于磁盘压力驱逐

nodefs上可用的磁盘空间,以及索引inde可用的值,达到的驱逐条件,或者imagefs达到的驱逐条件,它一样的会将节点的DiskPressure设置为true。

删除了已经退出的容器和未使用的镜像,这个节点的磁盘还有可能承压,这个时候kubelet会继续的去释放空间要去驱逐正在运行的pod。
容器和资源配置
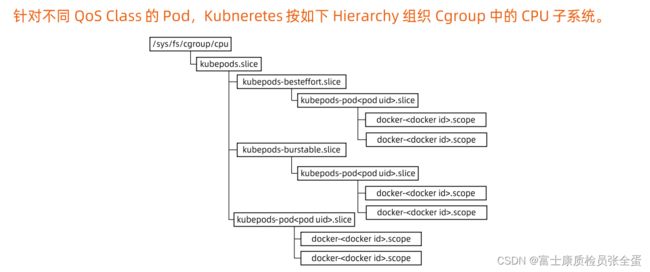
针对于任何的pod都会落在不同的qos class。
Cgroup配置

OOM Killer行为
