十、框架详解
目录
-
-
- 1. 什么是IOC和AOP
- 2. Spring Bean的生命周期
- 3. Spring中Bean
- 4. Spring事务的基本实现
- 5. Spring中使用了哪些设计模式
- 6. Spring循环依赖
- 7. Sping、SpringMVC、SpringBoot的区别
- 8. 注解@Autowired和@Resource有什么区别
- 9. Mybatis怎么通过xml绑定到接口上,具体流程
- 10. 介绍下Spring MVC的执行流程
- 11 介绍一下Spring MVC的拦截器
- 12. 介绍一下 MyBatis,它的优点是什么
- 13. MyBatis中的${}和#{}有什么区别
- 14. MyBatis缓存
- 15. 谈谈MyBatis原理
- 16. MyBatis输入输出支持的类型有哪些?
- 17. MyBatis里如何实现一对多关联查询?
- 18. SpringBoot启动流程
- 19. Spring Boot Starter有什么用?
- 19. Spring Cloud详解
-
1. 什么是IOC和AOP
IOC:
IOC就是控制反转,指将创建对象的控制权转移给Spring框架来进行管理,如果自己创建的话,需要维护对象与对象之间的依赖关系,很容易造成对象之间的耦合度过高。IOC可以帮助我们维护对象与对象之间的依赖关系,降低对象之间的耦合度。
IOC是通过依赖注入(DI)来实现的,Spring容器负责创建应用程序中的Bean,并通过依赖注入协调这些对象之间的关系。
依赖注入的方法有3种:setter()方法注入、构造方法注入、接口注入
SpringIOC容器的设计主要基于BeanFactory和ApplicationContext两个接口 来创建Bean。
AOP
AOP就是面向切面编程,AOP采用横向抽取机制,将分散在各个方法中的重复代码提取出来,然后在程序编译或运行时,再将这些提取出来的代码织入到需要执行的地方。
AOP实现的关键在于代理模式,AOP代理主要分为静态代理和动态代理。静态代理的代表为AspectJ;动态代理则以Spring AOP为代表。
1.AspectJ是静态代理,也称为编译时增强,AOP框架会在编译阶段生成AOP代理类,并将AspectJ(切面)织入到Java字节码中,运行的时候就是增强之后的AOP对象。
2.Spring AOP使用的动态代理,所谓的动态代理就是说AOP框架不会去修改字节码,而是每次运行时在内存中临时为方法生成一个AOP对象,这个AOP对象包含了目标对象的全部方法,并且在特定的切点做了增强处理,并回调原对象的方法。
JDK动态代理:这是Java提供的动态代理技术,可以在运行时创建接口的代理实例。Spring AOP默认采用这种方式,在接口的代理实例中织入代码。
CGLib动态代理 :采用底层的字节码技术,在运行时创建子类代理的实例。当目标对象不存在接口时,Spring AOP就会采用这种方式,在子类实例中织入代码。
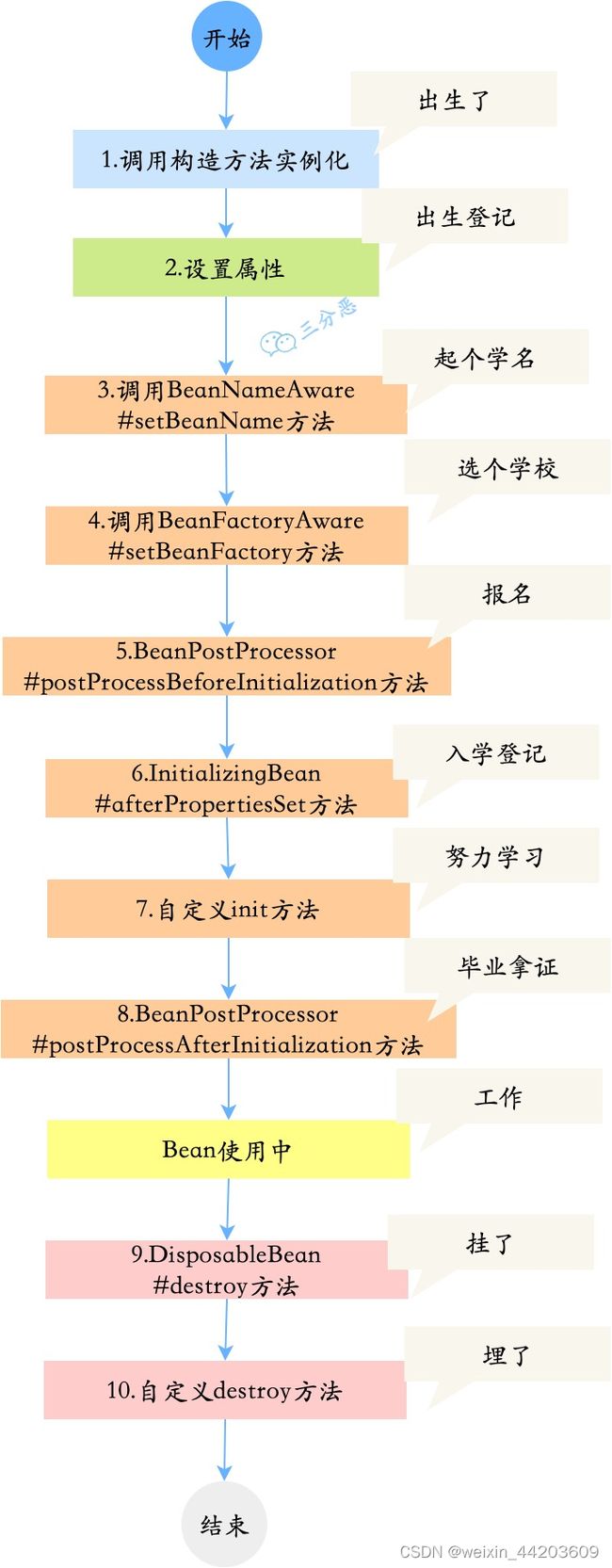
2. Spring Bean的生命周期
1.Spring对bean进行实例化,默认bean是单例;
2.Spring对bean进行依赖注入;
3.如果bean实现了BeanNameAware接口,spring将bean的id传给setBeanName()方法;
4.如果bean实现了BeanFactoryAware接口,spring将调用setBeanFactory()方法,将BeanFactory实例传进来;
5.如果bean实现了ApplicationContextAware接口,它的setApplicationContext()方法将被调用,将应用上下文的引用传入到 bean中;
6.如果bean实现了BeanPostProcessor接口,它的postProcessBeforeInitialization()方法**(预初始化方法**)将被调用;
7.如果bean实现了InitializingBean接口,spring将调用它的afterPropertiesSet()方法,类似的如果bean使用了init-method属性声明了初始化方法,该方法也会被调用;
8.如果bean实现了BeanPostProcessor接口,它的postProcessAfterInitialization()方法(后初始化方法)将被调用;
9.此时bean已经准备就绪,可以被应用程序使用了,他们将一直驻留在应用上下文中,直到该应用上下文被销毁;
10.若bean实现了DisposableBean接口,spring将调用它的distroy()接口方法。同样的,如果bean使用了destroy-method属性声明了销毁方法,则该方法被调用;
3. Spring中Bean
作用域: 默认情况下,Bean在Spring容器中是单例的(singleton),可以通过@Scope注解或者配置文件中的scope属性设置Bean的作用域
①singleton:在Spring容器中仅存在一个这个Bean的实例,即一个Bean定义对应一个对象实例。
②prototype:一个bean定义对应多个对象实例。每次调用getBean()时,都会执行new操作,返回一个新的Bean实例。
③request:每次Http请求都会创建一个新的Bean,该作用域仅在当前HTTP Request内有效。
④session:同一个Http Session共享一个Bean,不同Http Session使用不同的Bean。该作用域仅在当前 HTTP Session 内有效。
⑤ global session :在一个全局的 HTTP Session 中,容器会返回该 Bean 的同一个实例。该作用域仅在使用 portlet context 时有效。
Bean状态
** 有状态对象(Stateful Bean) **就是有实例变量的对象,可以保存数据,是非线程安全的。每个用户有自己特有的一个实例,在用户的生存期内,bean保持了用户的信息,即“有状态”;一旦用户灭亡(调用结束或实例结束),bean的生命期也告结束。即每个用户最初都会得到一个初始的bean。
**无状态对象(Stateless Bean):**就是没有实例变量的对象,不能保存数据,是不变类,是线程安全的。bean一旦实例化就被加进会话池中,各个用户都可以共用。即使用户已经消亡,bean 的生命期也不一定结束,它可能依然存在于会话池中,供其他用户调用。由于没有特定的用户,那么也就不能保持某一用户的状态,所以叫无状态bean。但无状态会话bean 并非没有状态,如果它有自己的属性(变量),那么这些变量就会受到所有调用它的用户的影响,这是在实际应用中必须注意的。
安全性
Spring中的Bean是否线程安全,其实跟Spring容器本身没有关系。Spring框架中没有提供线程安全的策略,因此,Spring容器中存在的Bean本身也不具备线程安全的特性。
解决办法
1、将 Bean 的作用域由 “singleton” 单例改为 “prototype” 多例;
2、在 Bean 对象中避免定义可变的成员变量;
3、在类中定义 ThreadLocal 的成员变量,并将需要的可变成员变量保存在 ThreadLocal 中,ThreadLocal 本身就具备线程隔离的特性,这就相当于为每个线程提供了一个独立的变量副本,每个线程只需要操作自己的线程副本变量,从而解决线程安全问题。
4. Spring事务的基本实现
Spring事务管理基于AOP
事务管理类DataSourceTransactionManager本质就是一个切面类Aspect
切点就是service层里的方法。
当service里的事务发生异常没有完全执行时,DataSourceTransactionManager的异常增强对事务进行了回滚rollback。
当事务完全执行完毕,DataSourceTransactionManager的后置增强对事物进行了提交commit。
Spring支持两种事务编程模型:
1. 编程式事务
Spring提供了TransactionTemplate模板,利用该模板我们可以通过编程的方式实现事务管理,而无需关注资源获取、复用、释放、事务同步及异常处理等操作。相对于声明式事务来说,这种方式相对麻烦一些,但是好在更为灵活,我们可以将事务管理的范围控制的更为精确。
2. 声明式事务
Spring事务管理的亮点在于声明式事务管理,它允许我们通过声明的方式,在IoC配置中指定事务的边界和事务属性,Spring会自动在指定的事务边界上应用事务属性。相对于编程式事务来说,这种方式十分的方便,只需要在需要做事务管理的方法上,增@Transactional注解,以声明事务特征即可。
或者通过XML的方式声明式事务管理。
4、事务通知中Propagation设置为7中传播行为的情况如下(单方法):
-
required(默认属性)
如果存在一个事务,则支持当前事务。如果没有事务则开启一个新的事务。
被设置成这个级别时,会为每一个被调用的方法创建一个逻辑事务域。如果前面的方法已经创建了事务,那么后面的方法支持当前的事务,如果当前没有事务会重新建立事务。 -
Mandatory
支持当前事务,如果当前没有事务,就抛出异常。 -
Never
以非事务方式执行,如果当前存在事务,则抛出异常。 -
Not_supports
以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。 -
requires_new
新建事务,如果当前存在事务,把当前事务挂起。 -
Supports
支持当前事务,如果当前没有事务,就以非事务方式执行。 -
Nested
支持当前事务,新增Savepoint点,与当前事务同步提交或回滚。
嵌套事务一个非常重要的概念就是内层事务依赖于外层事务。外层事务失败时,会回滚内层事务所做的动作。而内层事务操作失败并不会引起外层事务的回滚。
5. Spring中使用了哪些设计模式
①工厂模式:Spring通过BeanFactory、ApplicationContext创建Bean对象。
③单例模式:Spring中Bean默认都是单例的。
②代理模式:Spring AOP 功能的实现
④模板方法模式:Spring中jdbcTemplate等以Template结尾的对数据库操作的类,它们就使用到了模板模式。
⑤观察者模式:Spring 事件驱动模型就是观察者模式很经典的一个应用。
⑥适配器模式:Spring AOP 的增强或通知(Advice)使用到了适配器模式,Spring中的AOP中AdvisorAdapter类。Spring MVC中的HandlerAdapter使用了适配器模式。
⑦装饰者模式:Spring中配置DataSource的时候,DataSource可能是不同的数据库和数据源。我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
⑧策略模式:Spring中的资源访问接口Resource接口就是基于策略设计模式实现的。
6. Spring循环依赖
参考答案
首先,需要明确的是spring对循环依赖的处理有三种情况:
- 构造器的循环依赖:这种依赖spring是处理不了的,直接抛出BeanCurrentlylnCreationException异常。
- 单例模式下的setter循环依赖:通过“三级缓存”处理循环依赖。
- 非单例循环依赖:无法处理。
接下来,我们具体看看spring是如何处理第二种循环依赖的。
Spring单例对象的初始化大略分为三步:
- createBeanInstance:实例化,其实也就是调用对象的构造方法实例化对象;
- populateBean:填充属性,这一步主要是多bean的依赖属性进行填充;
- initializeBean:调用spring xml中的init 方法。
从上面讲述的单例bean初始化步骤我们可以知道,循环依赖主要发生在第一步、第二步。也就是构造器循环依赖和field循环依赖。 Spring为了解决单例的循环依赖问题,使用了三级缓存。
/** Cache of singleton objects: bean name –> bean instance */ private final Map singletonObjects = new ConcurrentHashMap(256); /** Cache of singleton factories: bean name –> ObjectFactory */ private final Map> singletonFactories = new HashMap>(16); /** Cache of early singleton objects: bean name –> bean instance */ private final Map earlySingletonObjects = new HashMap(16);
这三级缓存的作用分别是:
- singletonFactories : 进入实例化阶段的单例对象工厂的cache (三级缓存);
- earlySingletonObjects :完成实例化但是尚未初始化的,提前暴光的单例对象的Cache (二级缓存);
- singletonObjects:完成初始化的单例对象的cache(一级缓存)。
我们在创建bean的时候,会首先从cache中获取这个bean,这个缓存就是sigletonObjects。主要的调用方法是:
protected Object getSingleton(String beanName, boolean allowEarlyReference) { Object singletonObject = this.singletonObjects.get(beanName); //isSingletonCurrentlyInCreation()判断当前单例bean是否正在创建中 if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) { synchronized (this.singletonObjects) { singletonObject = this.earlySingletonObjects.get(beanName); //allowEarlyReference 是否允许从singletonFactories中通过getObject拿到对象 if (singletonObject == null && allowEarlyReference) { ObjectFactory singletonFactory = this.singletonFactories.get(beanName); if (singletonFactory != null) { singletonObject = singletonFactory.getObject(); //从singletonFactories中移除,并放入earlySingletonObjects中。 //其实也就是从三级缓存移动到了二级缓存 this.earlySingletonObjects.put(beanName, singletonObject); this.singletonFactories.remove(beanName); } } } } return (singletonObject != NULL_OBJECT ? singletonObject : null); }
从上面三级缓存的分析,我们可以知道,Spring解决循环依赖的诀窍就在于singletonFactories这个三级cache。这个cache的类型是ObjectFactory,定义如下:
public interface ObjectFactory { T getObject() throws BeansException; }
这个接口在AbstractBeanFactory里实现,并在核心方法doCreateBean()引用下面的方法:
protected void addSingletonFactory(String beanName, ObjectFactory singletonFactory) { Assert.notNull(singletonFactory, "Singleton factory must not be null"); synchronized (this.singletonObjects) { if (!this.singletonObjects.containsKey(beanName)) { this.singletonFactories.put(beanName, singletonFactory); this.earlySingletonObjects.remove(beanName); this.registeredSingletons.add(beanName); } } }
这段代码发生在createBeanInstance之后,populateBean()之前,也就是说单例对象此时已经被创建出来(调用了构造器)。这个对象已经被生产出来了,此时将这个对象提前曝光出来,让大家使用。
这样做有什么好处呢?让我们来分析一下“A的某个field或者setter依赖了B的实例对象,同时B的某个field或者setter依赖了A的实例对象”这种循环依赖的情况。A首先完成了初始化的第一步,并且将自己提前曝光到singletonFactories中,此时进行初始化的第二步,发现自己依赖对象B,此时就尝试去get(B),发现B还没有被create,所以走create流程,B在初始化第一步的时候发现自己依赖了对象A,于是尝试get(A),尝试一级缓存singletonObjects(肯定没有,因为A还没初始化完全),尝试二级缓存earlySingletonObjects(也没有),尝试三级缓存singletonFactories,由于A通过ObjectFactory将自己提前曝光了,所以B能够通过ObjectFactory.getObject拿到A对象(虽然A还没有初始化完全,但是总比没有好呀),B拿到A对象后顺利完成了初始化阶段1、2、3,完全初始化之后将自己放入到一级缓存singletonObjects中。此时返回A中,A此时能拿到B的对象顺利完成自己的初始化阶段2、3,最终A也完成了初始化,进去了一级缓存singletonObjects中,而且更加幸运的是,由于B拿到了A的对象引用,所以B现在hold住的A对象完成了初始化。
7. Sping、SpringMVC、SpringBoot的区别
Spring框架就像一个家族,有众多衍生产品例如boot、security、jpa等等;但他们的基础都是Spring 的ioc和 aop,ioc提供了依赖注入的容器,aop解决了面向切面编程,然后在此两者的基础上实现了其他延伸产品的高级功能。
Spring MVC提供了一种轻度耦合的方式来开发web应用;它是Spring的一个模块,是一个web框架;通过DispatcherServlet,ModelAndView和View Resolver,开发web应用变得很容易;解决的问题领域是网站应用程序或者服务开发——URL路由、Session、模板引擎、静态Web资源等等。
Spring Boot实现了auto-configuration自动配置(另外三大神器actuator监控,cli命令行接口,starter依赖),降低了项目搭建的复杂度。它主要是为了解决使用Spring框架需要进行大量的配置太麻烦的问题,所以它并不是用来替代Spring的解决方案,而是和Spring框架紧密结合用于提升Spring开发者体验的工具;同时它集成了大量常用的第三方库配置(例如Jackson, JDBC, Mongo, Redis, Mail等等),Spring Boot应用中这些第三方库几乎可以零配置的开箱即用(out-of-the-box)。
8. 注解@Autowired和@Resource有什么区别
1.@Autowired是Spring提供的注解,@Resource是JDK提供的注解。
2.@Autowired是只能按类型注入,@Resource默认按名称注入,也支持按类型注入。
3.@Autowired按类型装配依赖对象,默认情况下它要求依赖对象必须存在,如果允许null值,可以设置它required属性为false,
如果我们想使用按名称装配,可以结合@Qualifier注解一起使用。
4.@Resource有两个中重要的属性:name和type。
name属性指定byName,
如果没有指定name属性,
当注解标注在字段上,即默认取字段的名称作为bean名称寻找依赖对象,
当注解标注在属性的setter方法上,即默认取属性名作为bean名称寻找依赖对象。
需要注意的是,@Resource如果没有指定name属性,并且按照默认的名称仍然找不到依赖对象时,
@Resource注解会回退到按类型装配。但一旦指定了name属性,就只能按名称装配了。
9. Mybatis怎么通过xml绑定到接口上,具体流程
是通过xml文件中, 根标签的namespace属性和具体的查询语句中的id进行绑定的,
即namespace属性的值需要配置成接口的全限定名称,id指向具体的方法
MyBatis内部就会通过这个值将这个接口与这个xml关联起来。
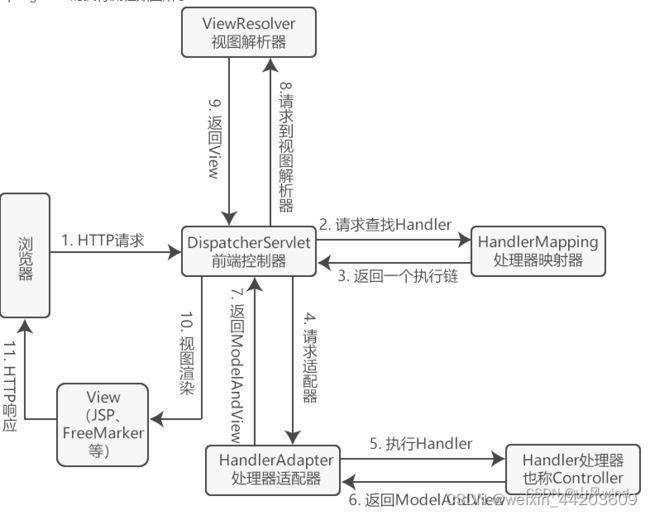
10. 介绍下Spring MVC的执行流程
1.用户通过客户端向服务端发起一个request请求,此请求会被前端控制器(DispatcherServlet)所拦截。
2.前端控制器(DispatcherServlet)请求处理映射器(HandlerMapping)去查找Handler,可以依据XML配置或注解去查找。
3.处理映射器(HandlerMapping)根据请求URL找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成),并返回给前端控制器。
4.前端控制器(DispatcherServlet)请求处理器适配器(HandlerAdapter)去执行相应的Handler(常称为Controller)。
5.处理器适配器(HandlerAdapter)会调用并执行Handler处理器,这里的处理器指的是程序中编写的Controller类,也被称为后端控制 器。
6.Controller执行完毕后会返回给处理器适配器(HandlerAdapter)一个ModelAndView对象,该对象中会包含View视图信息或包含 Model数据模型和View视图信息。
7.处理器适配器(HandlerAdapter)接收到Controller返回的ModelAndView后,将其返回给前端控制器。
8.前端控制器(DispatcherServlet)接收到ModelAndView后,选择一个合适的视图解析器(ViewReslover)对视图进行解析。
9.视图解析器(ViewReslover)解析后,会根据View视图信息匹配到相应的视图结果,反馈给前端控制器。
10.前端控制器收到View视图后,进行视图渲染,将模型数据(在ModelAndView对象中)填充到request域。
11.前端控制器向用户响应结果。
11 介绍一下Spring MVC的拦截器
参考答案
拦截器会对处理器进行拦截,这样通过拦截器就可以增强处理器的功能。Spring MVC中,所有的拦截器都需要实现HandlerInterceptor接口,该接口包含如下三个方法:preHandle()、postHandle()、afterCompletion()。
这些方法的执行流程如下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8lupEub6-1656781053044)(https://uploadfiles.nowcoder.com/images/20220224/4107856_1645694469544/31C010B3F63CB1CC1ADC5481E9E77BDB)]
通过上图可以看出,Spring MVC拦截器的执行流程如下:
- 执行preHandle方法,它会返回一个布尔值。如果为false,则结束所有流程,如果为true,则执行下一步。
- 执行处理器逻辑,它包含控制器的功能。
- 执行postHandle方法。
- 执行视图解析和视图渲染。
- 执行afterCompletion方法。
Spring MVC拦截器的开发步骤如下:
-
开发拦截器:
实现handlerInterceptor接口,从三个方法中选择合适的方法,实现拦截时要执行的具体业务逻辑。
-
注册拦截器:
定义配置类,并让它实现WebMvcConfigurer接口,在接口的addInterceptors方法中,注册拦截器,并定义该拦截器匹配哪些请求路径。
12. 介绍一下 MyBatis,它的优点是什么
MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。
MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。
MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
MyBatis的优点:
1.sql语句与代码分离,存放于xml配置文件中,解除SQL和程序代码的耦合,便于统一管理和优化,并可重用。
2.支持编写动态SQL语句
3.支持对象与数据库的ORM字段关系映射 【ORM:对象关系映射(Object Relational Mapping,简称 ORM)】
13. MyBatis中的${}和#{}有什么区别
#{}:在预编译时,会把参数部分用一个占位符?代替,传入的内容会被作为字符串,被加上引号,安全性高,可以防止sql注入。
${}: 传入的内容会直接拼接,不会加上引号,可能存在sql注入的安全隐患。
所以能用#{}的地方就用#{}, 但是诸如传入表名,需要排序的时候order by 字段 的 “字段名”的时候可以用${}.
什么是SQL注入?
所谓SQL注入式攻击,就是攻击者把SQL命令插入到Web表单的输入域或页面请求的查询字符串,欺骗服务器执行恶意的SQL命令。
SQL注入是将Web页面的原 URL 、表单域或数据包输入的参数,修改拼接成SQL语句,传递给Web服务器,进而传给 数据库服务器 以执行数据库命令。如Web应用程序的开发人员对用户所输入的数据或cookie等内容不进行过滤或验证(即存在注入点)就直接传输给数据库,就可能导致拼接的SQL被执行,获取对数据库的信息以及提权,发生 SQL注入攻击 。
14. MyBatis缓存
MyBatis的缓存分为一级缓存和二级缓存
①MyBatis的一级缓存是SqlSession级别的缓存,当在同一个SqlSession中执行两次相同的SQL语句时,会将第一次执行查询的数据存入一级缓存中,第二次查询时会从缓存中获取数据,而不用再去数据库中查询,从而提高了查询性能。但如果SqlSession执行insert、delete和update操作,并提交到数据库或者SqlSession结束后,这个SqlSession中的一级缓存就不存在了。
②MyBatis的二级缓存是SqlSessionFactory级别的缓存,由同一个SqlSessionFactory对象创建的sqlsession共享其缓存。
MyBatis提供了一级缓存和二级缓存:
一级缓存:也称为本地缓存,用于保存用户在一次会话过程中查询的结果,用户一次会话中只能使用一个sqlSession,一级缓存是自动开启的,不允许关闭。
二级缓存:也称为全局缓存,是mapper级别的缓存,是针对一个表的查结果的存储,可以共享给所有针对这张表的查询的用户。也就是说对于mapper级别的缓存不同的sqlsession是可以共享的。
15. 谈谈MyBatis原理
参考答案
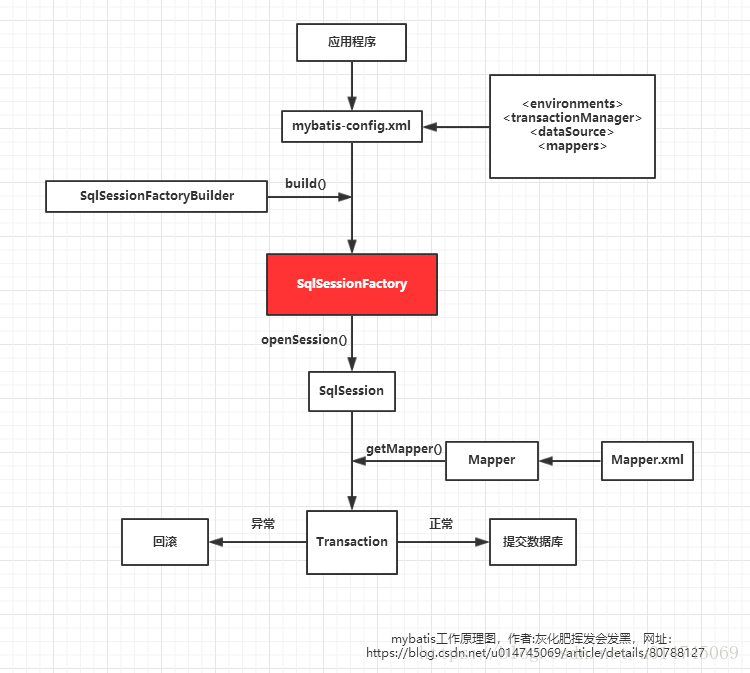
1、mybatis应用程序通过SqlSessionFactoryBuilder从mybatis-config.xml配置文件(也可以用Java文件配置的方式,需要添加@Configuration)来构建SqlSessionFactory(SqlSessionFactory是线程安全的);
2、然后,SqlSessionFactory的实例直接开启一个SqlSession,再通过SqlSession实例获得Mapper对象并运行Mapper映射的SQL语句,完成对数据库的CRUD和事务提交,之后关闭SqlSession。
详细流程如下:
1、加载mybatis全局配置文件(mybatis-config.xml),解析配置文件,MyBatis基于XML配置文件生成Configuration,和一个个MappedStatement(包括了参数映射配置、动态SQL语句、结果映射配置),其对应着
2、SqlSessionFactoryBuilder通过Configuration对象生成SqlSessionFactory,用来开启SqlSession。
3、SqlSession对象完成和数据库的交互:
a、用户程序调用mybatis接口层api(即Mapper接口中的方法)
b、SqlSession通过调用api的Statement ID找到对应的MappedStatement对象
c、通过Executor(负责动态SQL的生成和查询缓存的维护)将MappedStatement对象进行解析,sql参数转化、动态sql拼接,生成jdbc Statement对象
d、JDBC执行sql。
e、借助MappedStatement中的结果映射关系,将返回结果转化成HashMap、JavaBean等存储结构ResultSet并返回。
16. MyBatis输入输出支持的类型有哪些?
参考答案
parameterType:
MyBatis支持多种输入输出类型,包括:
- 简单的类型,如整数、小数、字符串等;
- 集合类型,如Map等;
- 自定义的JavaBean。
其中,简单的类型,其数值直接映射到参数上。对于Map或JavaBean则将其属性按照名称映射到参数上。
17. MyBatis里如何实现一对多关联查询?
参考答案
一对多映射有两种配置方式,都是使用collection标签实现的。在此之前,为了能够存储一对多的数据,需要在主表对应的实体类中增加集合属性,用于封装子表对应的实体类。
嵌套查询:
- 通过select标签定义查询主表的SQL,返回结果通过reusltMap进行映射。
- 在resultMap中,除了映射主表属性,还要通过collection标签映射子表属性,该标签需包含如下内容:
- 通过property属性指定子表属性名;
- 通过javaType属性指定封装子表属性的集合类型;
- 通过ofType属性指定子表的实体类型;
- 通过select属性指定查询子表所依赖的SQL,这个SQL需单独定义,内部包含查询子表的语句。
嵌套结果:
- 通过select标签定义关联查询主表和子表的SQL,返回结果通过resultMap进行映射。
- 在resultMap中,除了映射主表属性,还要通过collection标签映射子表属性,该标签需包含如下内容:
- 通过property属性指定子表属性名;
- 通过ofType属性指定子表的实体类型;
- 通过result子标签定义子表字段和属性的映射关系。
18. SpringBoot启动流程
SpringBoot在启动的时候会调用run()方法,run()方法会刷新容器,刷新容器的时候,会扫描classpath下面的的包中META-INF/spring.factories文件,在这个文件中记录了好多的自动配置类,在刷新容器的时候会将这些自动配置类加载到容器中,然后在根据这些配置类中的条件注解,来判断是否将这些配置类在容器中进行实例化,这些条件主要是判断项目是否有相关jar包或是否引入了相关的bean。这样springboot就帮助我们完成了自动装配。
19. Spring Boot Starter有什么用?
参考答案
Spring Boot通过提供众多起步依赖(Starter)降低项目依赖的复杂度。起步依赖本质上是一个Maven项目对象模型(Project Object Model, POM),定义了对其他库的传递依赖,这些东西加在一起即支持某项功能。很多起步依赖的命名都暗示了它们提供的某种或某类功能。
举例来说,你打算把这个阅读列表应用程序做成一个Web应用程序。与其向项目的构建文件里添加一堆单独的库依赖,还不如声明这是一个Web应用程序来得简单。你只要添加Spring Boot的Web起步依赖就好了。
19. Spring Cloud详解
链接: Spring Cloud