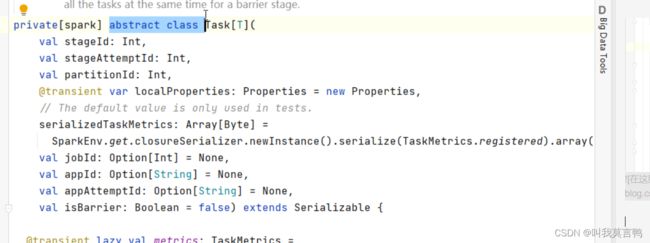
spark第四课
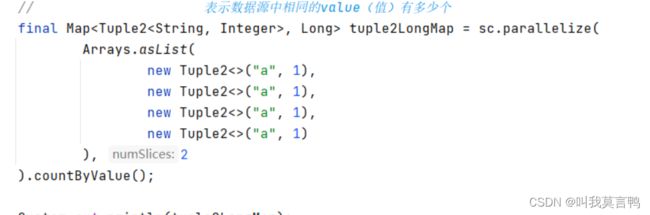
countByValue
数据源中相同的值有多少个,也就是WordCount
countByKey
表的是键值对中的key出现了几次,与Value的值无关
不推荐collect,因为他是将数据放入内存,但是内存不够大的话,就容易崩,所以使用saveAsTextFile更好,直接放入磁盘.
保存成对象文件,需要序列化
启动了2个
Job数量: 只要执行一个行动算子,就会产生一个作业.(不考虑前面,例如sortby也会产生一个作业)
算子的外部代码 在Driver执行 ,内部在Executor执行
压栈也需要消耗的
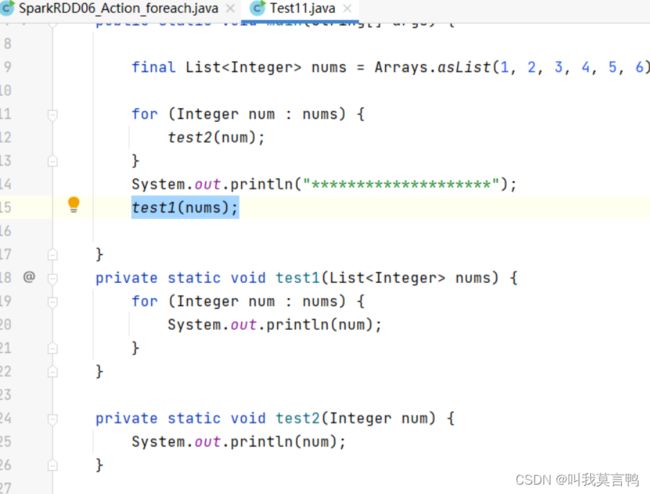
forEachPartition
forEach
2个的效率比较
分区的大于foreach,因为foreach是一个一个压栈,而Partition是一个区一个区压栈
// 一次处理一个分区的数据
// 一次处理一个分区的数据


IO
计算机互相传的是ASCII(0-255),
JAVA byte -128-127 所以,网络传输可以使用字节流
所以网络传输必须序列化
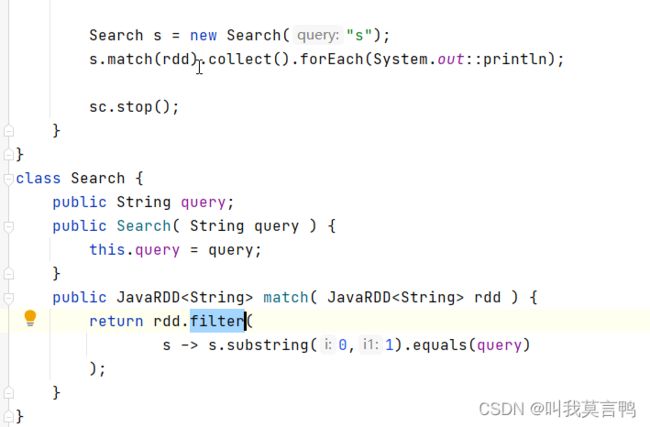
这里还是序列化错误
可是为什么???
因为query是this,query 所以必须传Search,所以这里就需要序列化

这样改就不需要序列化了.
String q = this.query是在Driver中执行
而q是临时变量,不需要对象

为什么上面报错?
使用lambda 传的是方法,但是对象是在Driver端的
Sysout.out这个对象是在Driver中,但是方法在Executor执行
序列化与反序列化
反序列化通过序列码重新创建对象,而不是使用序列化的对象

对象输出流实现
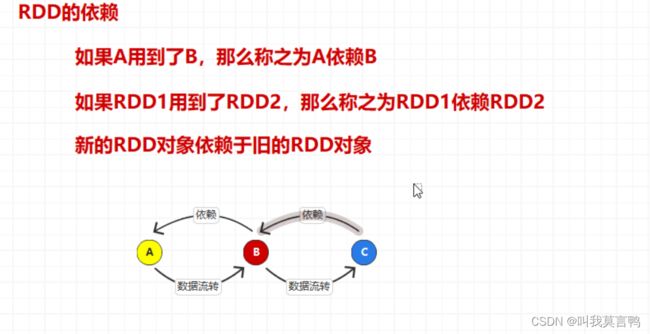
装饰者设计模式就是层层依赖的
A-B B-C 直接依赖
A和C间接依赖
ABC(血缘关系)
RDD的依赖关系:
1.窄依赖 NarrowDependency OneToOneDependency
2.宽依赖 不是窄,就是宽
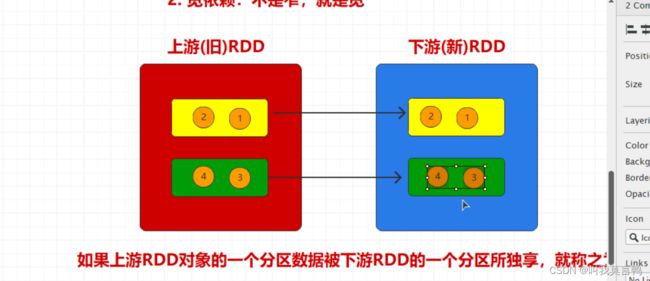
一对一

宽依赖 shuffle依赖 数据被打乱重新组合
依赖是在创建时就已经确定了,而shuffle是在创建后运行时才使用的.
Application数量(应用程序数量)
按照当前环境来算的,创建几个JavaSparkContext对象,就有几个Application对象.


Stage数量(一个job至少一个阶段,1个shuffle就是一个阶段)
一个stage数量 = 1(job基本数量)+宽依赖的数量
Task任务数量
最近分区的最大数量
当前RDD最后的分区数量
Result
基于Shuffle
Task数量 : 基于Stage = 分区数量
Task任务数 = 当前阶段中最后一个RDD的分区数量=-
