YOLOv8改进——引入可变形卷积DCNv3
YOLOv8 详解
✨✨✨YOLOv8详解 【网络结构+代码+实操】
可变形卷积DCNv1 & DCNv2
✨✨✨论文及代码详解——可变形卷积(DCNv1)
✨✨✨论文及代码详解——可变形卷积(DCNv2)
DCNv3 是InternImage中提出的,DCNv3在DCNv2版本上进行了改进。
✨✨✨论文详解——《InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions》
✨✨✨ 代码详解——可变形卷积(DCNv3)
本文只讲解在YOLOv8的代码中添加DCNv3的操作流程, 具体的原理参见上述的链接~
1. 下载ops_dcnv3
如下图,首先下载InterImage官方代码,然后在segmentation、detection、classification文件夹下均可以找到ops_dcnv3文件夹,该文件夹下的内容就是实现DCNv3算子的核心代码。
modules
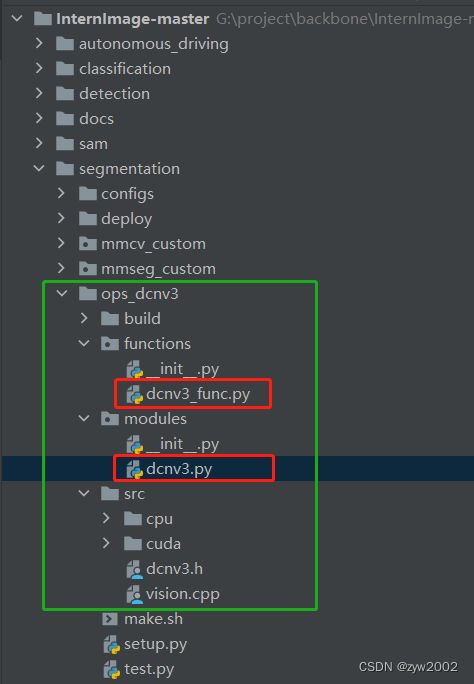
如下图所示,modules文件夹中的dcnv3.py文件主要定义了DCNv3模块。
其中DCNv3_pytorch是DCNv3的pytorch实现版本,DCNv3是DCNv3的C++实现版本。

functions
如下图所示,function文件夹中的dcnv3_func.py文件定义了DCNv3的一些核心操作。
其中黄色部分的DCNv3Function类被c++版本的DCNv3调用。
其中红色部分的dcnv3_core_pytorch方法被pytorch版本的DCNv3_pytorch调用。
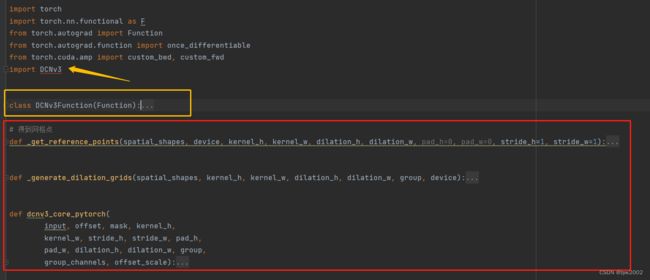
src
src下的代码是用C++来实现DCNv3中核心操作,其下的cpu和cuda分别表示cpu和cuda编程两种实现版本。c++实现的版本需要去编译,否则如上图所示,黄色箭头指向的import DCNv3有红色波浪线,无法正常导入。
如果想import DCNv3成功,有两种解决办法:
(1)需要编译:DCNv3具体编译方法是直接运行make.sh文件(但是这种方法很容易编译失败,对于pytorch,cuda的版本以及c++编译器的配置都有要求)
(2)不需要编译:去官网上下载轮子https://github.com/OpenGVLab/InternImage/releases/tag/whl_files (更推荐这种方法,但是也需要注意cuda和pytorch的版本)

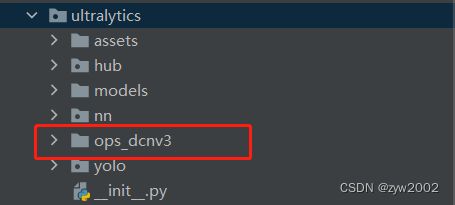
然后将ops_dcnv3复制到ultralutics文件夹下。
2. 添加DCNv3模块
打开modules.py文件。

首先从ops_dcnv3 中导入DCNv3 和DCNv3_pytorch。
其中DCNv3是C++实现版本,必须先在上一步编译成功,或者安装好了轮子,否则会报错。
DCNv3_pytorch 是pytorch实现的版本,只要基础的pytorch环境安装正确就不会出错。
但是在实际的训练过程中,C++版本的运行速度更快,推荐使用C++版本。
from ..ops_dcnv3.modules import DCNv3,DCNv3_pytorch
- DCNv3_YOLO
然后在modules.py文件中添加DCNv3_YOLO模块。其中self.dcnv3即可以使用c++版本的DCNv3,也可以使用pytorch版本实现的DCNv3_pytorch。
class DCNV3_YoLo(nn.Module):
def __init__(self, inc, ouc, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
self.conv = Conv(inc, ouc, k=1)
self.dcnv3 = DCNv3(ouc, kernel_size=k, stride=s, group=g, dilation=d) # c++版本
# self.dcnv3 = DCNv3_pytorch(ouc, kernel_size=k, stride=s, group=g, dilation=d) # pytorch版本
self.bn = nn.BatchNorm2d(ouc)
self.act = Conv.default_act
def forward(self, x):
x = self.conv(x)
x = x.permute(0, 2, 3, 1)
x = self.dcnv3(x)
x = x.permute(0, 3, 1, 2)
x = self.act(self.bn(x))
return x
- Bottleneck_DCNV3
把原始的Bottleneck中的self.cv2的Conv换成DCNV3_YOLO。

具体代码如下:
class Bottleneck_DCNV3(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expand
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = DCNV3_YoLo(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
- C2f_DCNV3
把原始C2f中的Bottleneck换成Bottleneck_DCNv3

具体代码如下:
class C2f_DCNV3(nn.Module):
# CSP Bottleneck with 2 convolutions
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck_DCNV3(self.c, self.c, shortcut, g, k=(3, 3), e=1.0) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
3. 补充声明
在nn/tasks.py中,下图中的列表里添加DCNv3_YOLO,Bottleneck_DCNV3,C2f_DCNV3


4. 修改Yaml文件
把yolov8s.yaml文件中的C2f修改成C2f_DCNV3, Conv修改成DCNv3_YOLO (具体怎么修改,都可以自己决定,然后通过实验看看效果如何)
